

TR-4956 : Déploiement automatisé de haute disponibilité PostgreSQL et reprise après sinistre dans AWS FSx/EC2
 Suggérer des modifications
Suggérer des modifications
Allen Cao, Niyaz Mohamed, NetApp
Cette solution fournit un aperçu et des détails sur le déploiement de la base de données PostgreSQL et la configuration HA/DR, le basculement et la resynchronisation basés sur la technologie NetApp SnapMirror intégrée à l'offre de stockage FSx ONTAP et à la boîte à outils d'automatisation NetApp Ansible dans AWS.
But
PostgreSQL est une base de données open source largement utilisée qui est classée numéro quatre parmi les dix moteurs de base de données les plus populaires par"Moteurs DB" . D’une part, PostgreSQL tire sa popularité de son modèle open source et sans licence tout en possédant des fonctionnalités sophistiquées. D'autre part, étant donné son caractère open source, il existe un manque de conseils détaillés sur le déploiement de bases de données de niveau production dans le domaine de la haute disponibilité et de la reprise après sinistre (HA/DR), en particulier dans le cloud public. En général, il peut être difficile de configurer un système PostgreSQL HA/DR typique avec veille à chaud et à chaud, réplication en continu, etc. Tester l'environnement HA/DR en promouvant le site de secours, puis en revenant au site principal, peut perturber la production. Il existe des problèmes de performances bien documentés sur le primaire lorsque les charges de travail de lecture sont déployées sur un serveur de secours à chaud en streaming.
Dans cette documentation, nous démontrons comment vous pouvez vous débarrasser d'une solution HA/DR de streaming PostgreSQL au niveau de l'application et créer une solution HA/DR PostgreSQL basée sur le stockage AWS FSx ONTAP et les instances de calcul EC2 à l'aide de la réplication au niveau du stockage. La solution crée un système plus simple et comparable et fournit des résultats équivalents par rapport à la réplication en continu au niveau de l'application PostgreSQL traditionnelle pour HA/DR.
Cette solution s'appuie sur la technologie de réplication au niveau du stockage NetApp SnapMirror éprouvée et mature, disponible dans le stockage cloud FSX ONTAP natif AWS pour PostgreSQL HA/DR. Il est simple à mettre en œuvre avec une boîte à outils d’automatisation fournie par l’équipe NetApp Solutions. Il offre des fonctionnalités similaires tout en éliminant la complexité et la baisse des performances sur le site principal avec la solution HA/DR basée sur le streaming au niveau de l'application. La solution peut être facilement déployée et testée sans affecter le site principal actif.
Cette solution répond aux cas d’utilisation suivants :
-
Déploiement HA/DR de niveau production pour PostgreSQL dans le cloud public AWS
-
Tester et valider une charge de travail PostgreSQL dans le cloud public AWS
-
Test et validation d'une stratégie PostgreSQL HA/DR basée sur la technologie de réplication NetApp SnapMirror
Public
Cette solution est destinée aux personnes suivantes :
-
L'administrateur de base de données intéressé par le déploiement de PostgreSQL avec HA/DR dans le cloud public AWS.
-
L'architecte de solutions de base de données qui souhaite tester les charges de travail PostgreSQL dans le cloud public AWS.
-
L'administrateur de stockage intéressé par le déploiement et la gestion des instances PostgreSQL déployées sur le stockage AWS FSx.
-
Le propriétaire de l'application qui souhaite mettre en place un environnement PostgreSQL dans AWS FSx/EC2.
Environnement de test et de validation de solutions
Les tests et la validation de cette solution ont été effectués dans un environnement AWS FSx et EC2 qui pourrait ne pas correspondre à l'environnement de déploiement final. Pour plus d'informations, consultez la section Facteurs clés à prendre en compte lors du déploiement .
Architecture
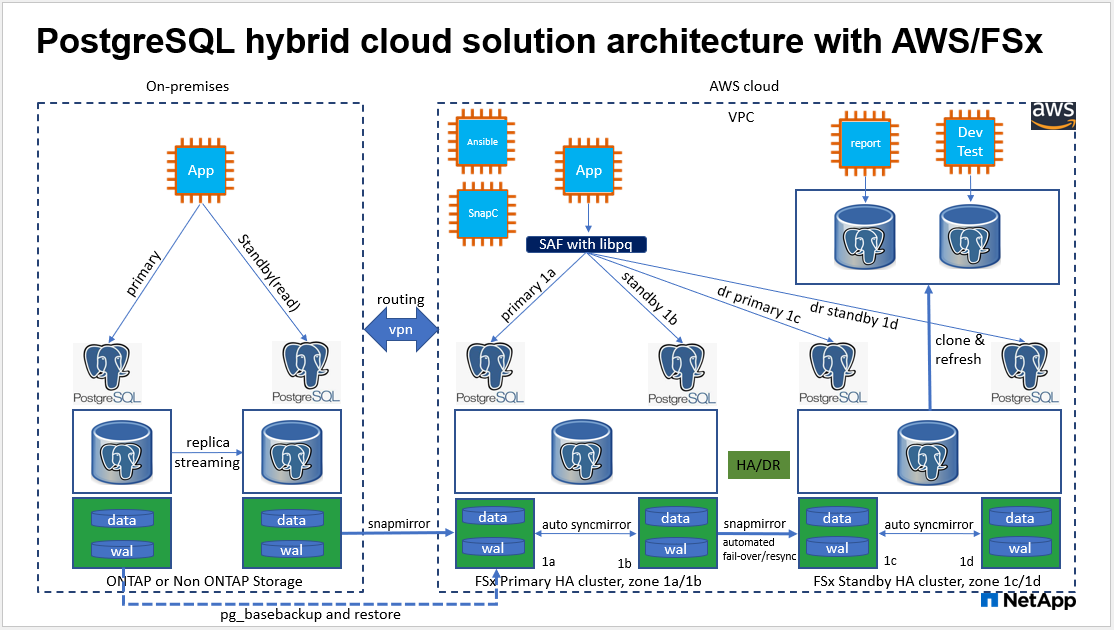
Composants matériels et logiciels
Matériel |
||
Stockage FSx ONTAP |
Version actuelle |
Deux paires FSx HA dans le même VPC et la même zone de disponibilité que les clusters HA principaux et de secours |
Instance EC2 pour le calcul |
t2.xlarge/4vCPU/16G |
Deux EC2 T2 xlarge comme instances de calcul principales et de secours |
Contrôleur Ansible |
VM Centos sur site/4vCPU/8G |
Une machine virtuelle pour héberger le contrôleur d'automatisation Ansible sur site ou dans le cloud |
Logiciel |
||
RedHat Linux |
RHEL-8.6.0_HVM-20220503-x86_64-2-Hourly2-GP2 |
Abonnement RedHat déployé pour les tests |
Centos Linux |
CentOS Linux version 8.2.2004 (Core) |
Hébergement du contrôleur Ansible déployé dans un laboratoire sur site |
PostgreSQL |
Version 14.5 |
L'automatisation extrait la dernière version disponible de PostgreSQL du dépôt yum postgresql.ora |
Ansible |
Version 2.10.3 |
Prérequis pour les collections et bibliothèques requises installées avec le manuel des exigences |
Facteurs clés à prendre en compte lors du déploiement
-
Sauvegarde, restauration et récupération de base de données PostgreSQL. Une base de données PostgreSQL prend en charge un certain nombre de méthodes de sauvegarde, telles qu'une sauvegarde logique à l'aide de pg_dump, une sauvegarde physique en ligne avec pg_basebackup ou une commande de sauvegarde du système d'exploitation de niveau inférieur, ainsi que des instantanés cohérents au niveau du stockage. Cette solution utilise des instantanés de groupe de cohérence NetApp pour la sauvegarde, la restauration et la récupération des données de base de données PostgreSQL et des volumes WAL sur le site de secours. Les instantanés de volume du groupe de cohérence NetApp séquencent les E/S au fur et à mesure de leur écriture dans le stockage et protègent l'intégrité des fichiers de données de la base de données.
-
Instances de calcul EC2. Dans ces tests et validations, nous avons utilisé le type d’instance AWS EC2 t2.xlarge pour l’instance de calcul de la base de données PostgreSQL. NetApp recommande d’utiliser une instance EC2 de type M5 comme instance de calcul pour PostgreSQL dans le déploiement, car elle est optimisée pour les charges de travail de base de données. L'instance de calcul de secours doit toujours être déployée dans la même zone que le système de fichiers passif (de secours) déployé pour le cluster FSx HA.
-
Déploiement de clusters de stockage HA FSx sur une ou plusieurs zones. Dans ces tests et validations, nous avons déployé un cluster FSx HA dans une seule zone de disponibilité AWS. Pour le déploiement en production, NetApp recommande de déployer une paire FSx HA dans deux zones de disponibilité différentes. Une paire HA de secours de reprise après sinistre pour la continuité des activités peut être configurée dans une région différente si une distance spécifique est requise entre le serveur principal et le serveur de secours. Un cluster FSx HA est toujours provisionné dans une paire HA synchronisée dans une paire de systèmes de fichiers actifs-passifs pour fournir une redondance au niveau du stockage.
-
Placement des données et des journaux PostgreSQL. Les déploiements PostgreSQL typiques partagent le même répertoire racine ou les mêmes volumes pour les fichiers de données et les fichiers journaux. Dans nos tests et validations, nous avons séparé les données et les journaux PostgreSQL en deux volumes distincts pour des raisons de performances. Un lien logiciel est utilisé dans le répertoire de données pour pointer vers le répertoire ou le volume de journaux qui héberge les journaux WAL PostgreSQL et les journaux WAL archivés.
-
Minuteur de délai de démarrage du service PostgreSQL. Cette solution utilise des volumes montés NFS pour stocker le fichier de base de données PostgreSQL et les fichiers journaux WAL. Lors du redémarrage d'un hôte de base de données, le service PostgreSQL peut essayer de démarrer alors que le volume n'est pas monté. Cela entraîne l’échec du démarrage du service de base de données. Un délai de 10 à 15 secondes est nécessaire pour que la base de données PostgreSQL démarre correctement.
-
RPO/RTO pour la continuité des activités. La réplication des données FSx du serveur principal vers le serveur de secours pour la reprise après sinistre est basée sur ASYNC, ce qui signifie que le RPO dépend de la fréquence des sauvegardes Snapshot et de la réplication SnapMirror . Une fréquence plus élevée de copie Snapshot et de réplication SnapMirror réduit le RPO. Il existe donc un équilibre entre la perte potentielle de données en cas de catastrophe et le coût de stockage supplémentaire. Nous avons déterminé que la copie Snapshot et la réplication SnapMirror peuvent être implémentées dans des intervalles de seulement 5 minutes pour le RPO, et PostgreSQL peut généralement être récupéré sur le site de secours DR en moins d'une minute pour le RTO.
-
Sauvegarde de la base de données. Une fois qu'une base de données PostgreSQL est implémentée ou migrée vers le stockage AWS FSx à partir d'un centre de données sur site, les données sont automatiquement synchronisées et mises en miroir dans la paire FSx HA pour plus de protection. Les données sont en outre protégées par un site de secours répliqué en cas de sinistre. Pour une conservation de sauvegarde ou une protection des données à plus long terme, NetApp recommande d'utiliser l'utilitaire PostgreSQL pg_basebackup intégré pour exécuter une sauvegarde complète de la base de données qui peut être portée vers le stockage blob S3.
Déploiement de la solution
Le déploiement de cette solution peut être effectué automatiquement à l’aide de la boîte à outils d’automatisation basée sur NetApp Ansible en suivant les instructions détaillées décrites ci-dessous.
-
Lisez les instructions dans la boîte à outils d'automatisation READme.md"na_postgresql_aws_deploy_hadr" .
-
Regardez la vidéo suivante.
-
Configurer les fichiers de paramètres requis(
hosts,host_vars/host_name.yml,fsx_vars.yml) en saisissant des paramètres spécifiques à l'utilisateur dans le modèle dans les sections correspondantes. Utilisez ensuite le bouton Copier pour copier les fichiers sur l’hôte du contrôleur Ansible.
Conditions préalables au déploiement automatisé
Le déploiement nécessite les prérequis suivants.
-
Un compte AWS a été configuré et les segments VPC et réseau nécessaires ont été créés dans votre compte AWS.
-
À partir de la console AWS EC2, vous devez déployer deux instances Linux EC2, une comme serveur de base de données PostgreSQL principal sur le site principal et une sur le site DR de secours. Pour la redondance de calcul sur les sites DR principal et de secours, déployez deux instances Linux EC2 supplémentaires en tant que serveurs de base de données PostgreSQL de secours. Consultez le diagramme d’architecture dans la section précédente pour plus de détails sur la configuration de l’environnement. Consultez également le"Guide de l'utilisateur pour les instances Linux" pour plus d'informations.
-
À partir de la console AWS EC2, déployez deux clusters de stockage HA FSx ONTAP pour héberger les volumes de base de données PostgreSQL. Si vous n'êtes pas familier avec le déploiement du stockage FSx, consultez la documentation"Création de systèmes de fichiers FSx ONTAP" pour des instructions étape par étape.
-
Créez une machine virtuelle Centos Linux pour héberger le contrôleur Ansible. Le contrôleur Ansible peut être situé sur site ou dans le cloud AWS. S'il est situé sur site, vous devez disposer d'une connectivité SSH au VPC, aux instances EC2 Linux et aux clusters de stockage FSx.
-
Configurez le contrôleur Ansible comme décrit dans la section « Configurer le nœud de contrôle Ansible pour les déploiements CLI sur RHEL/CentOS » de la ressource"Premiers pas avec l'automatisation des solutions NetApp" .
-
Clonez une copie de la boîte à outils d’automatisation à partir du site public NetApp GitHub.
git clone https://github.com/NetApp-Automation/na_postgresql_aws_deploy_hadr.git-
À partir du répertoire racine de la boîte à outils, exécutez les playbooks prérequis pour installer les collections et bibliothèques requises pour le contrôleur Ansible.
ansible-playbook -i hosts requirements.ymlansible-galaxy collection install -r collections/requirements.yml --force --force-with-deps-
Récupérer les paramètres d'instance EC2 FSx requis pour le fichier de variables d'hôte de la base de données
host_vars/*et le fichier de variables globalesfsx_vars.ymlconfiguration.
Configurer le fichier hosts
Saisissez l'adresse IP de gestion du cluster FSx ONTAP principal et les noms d'hôtes des instances EC2 dans le fichier hosts.
# Primary FSx cluster management IP address [fsx_ontap] 172.30.15.33
# Primary PostgreSQL DB server at primary site where database is initialized at deployment time [postgresql] psql_01p ansible_ssh_private_key_file=psql_01p.pem
# Primary PostgreSQL DB server at standby site where postgresql service is installed but disabled at deployment # Standby DB server at primary site, to setup this server comment out other servers in [dr_postgresql] # Standby DB server at standby site, to setup this server comment out other servers in [dr_postgresql] [dr_postgresql] -- psql_01s ansible_ssh_private_key_file=psql_01s.pem #psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
Configurez le fichier host_name.yml dans le dossier host_vars
# Add your AWS EC2 instance IP address for the respective PostgreSQL server host
ansible_host: "10.61.180.15"
# "{{groups.postgresql[0]}}" represents first PostgreSQL DB server as defined in PostgreSQL hosts group [postgresql]. For concurrent multiple PostgreSQL DB servers deployment, [0] will be incremented for each additional DB server. For example, "{{groups.posgresql[1]}}" represents DB server 2, "{{groups.posgresql[2]}}" represents DB server 3 ... As a good practice and the default, two volumes are allocated to a PostgreSQL DB server with corresponding /pgdata, /pglogs mount points, which store PostgreSQL data, and PostgreSQL log files respectively. The number and naming of DB volumes allocated to a DB server must match with what is defined in global fsx_vars.yml file by src_db_vols, src_archivelog_vols parameters, which dictates how many volumes are to be created for each DB server. aggr_name is aggr1 by default. Do not change. lif address is the NFS IP address for the SVM where PostgreSQL server is expected to mount its database volumes. Primary site servers from primary SVM and standby servers from standby SVM.
host_datastores_nfs:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
# Add swap space to EC2 instance, that is equal to size of RAM up to 16G max. Determine the number of blocks by dividing swap size in MB by 128.
swap_blocks: "128"
# Postgresql user configurable parameters
psql_port: "5432"
buffer_cache: "8192MB"
archive_mode: "on"
max_wal_size: "5GB"
client_address: "172.30.15.0/24"Configurer le fichier global fsx_vars.yml dans le dossier vars
########################################################################
###### PostgreSQL HADR global user configuration variables ######
###### Consolidate all variables from FSx, Linux, and postgresql ######
########################################################################
###########################################
### Ontap env specific config variables ###
###########################################
####################################################################################################
# Variables for SnapMirror Peering
####################################################################################################
#Passphrase for cluster peering authentication
passphrase: "xxxxxxx"
#Please enter destination or standby FSx cluster name
dst_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter destination or standby FSx cluster management IP
dst_cluster_ip: "172.30.15.90"
#Please enter destination or standby FSx cluster inter-cluster IP
dst_inter_ip: "172.30.15.13"
#Please enter destination or standby SVM name to create mirror relationship
dst_vserver: "dr"
#Please enter destination or standby SVM management IP
dst_vserver_mgmt_lif: "172.30.15.88"
#Please enter destination or standby SVM NFS lif
dst_nfs_lif: "172.30.15.88"
#Please enter source or primary FSx cluster name
src_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter source or primary FSx cluster management IP
src_cluster_ip: "172.30.15.20"
#Please enter source or primary FSx cluster inter-cluster IP
src_inter_ip: "172.30.15.5"
#Please enter source or primary SVM name to create mirror relationship
src_vserver: "prod"
#Please enter source or primary SVM management IP
src_vserver_mgmt_lif: "172.30.15.115"
#####################################################################################################
# Variable for PostgreSQL Volumes, lif - source or primary FSx NFS lif address
#####################################################################################################
src_db_vols:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
src_archivelog_vols:
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
#Names of the Nodes in the ONTAP Cluster
nfs_export_policy: "default"
#####################################################################################################
### Linux env specific config variables ###
#####################################################################################################
#NFS Mount points for PostgreSQL DB volumes
mount_points:
- "/pgdata"
- "/pglogs"
#RedHat subscription username and password
redhat_sub_username: "xxxxx"
redhat_sub_password: "xxxxx"
####################################################
### DB env specific install and config variables ###
####################################################
#The latest version of PostgreSQL RPM is pulled/installed and config file is deployed from a preconfigured template
#Recovery type and point: default as all logs and promote and leave all PITR parameters blankDéploiement de PostgreSQL et configuration HA/DR
Les tâches suivantes déploient le service de serveur de base de données PostgreSQL et initialisent la base de données sur le site principal sur l'hôte du serveur de base de données EC2 principal. Un hôte de serveur de base de données EC2 principal de secours est ensuite configuré sur le site de secours. Enfin, la réplication du volume de base de données est configurée à partir du cluster FSx du site principal vers le cluster FSx du site de secours pour la reprise après sinistre.
-
Créez des volumes de base de données sur le cluster FSx principal et configurez postgresql sur l'hôte d'instance EC2 principal.
ansible-playbook -i hosts postgresql_deploy.yml -u ec2-user --private-key psql_01p.pem -e @vars/fsx_vars.yml -
Configurez l’hôte d’instance DR EC2 de secours.
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml -
Configurez le peering de cluster FSx ONTAP et la réplication du volume de base de données.
ansible-playbook -i hosts fsx_replication_setup.yml -e @vars/fsx_vars.yml -
Consolidez les étapes précédentes dans un déploiement PostgreSQL et une configuration HA/DR en une seule étape.
ansible-playbook -i hosts postgresql_hadr_setup.yml -u ec2-user -e @vars/fsx_vars.yml -
Pour configurer un hôte de base de données PostgreSQL de secours sur le site principal ou de secours, commentez tous les autres serveurs dans la section du fichier hosts [dr_postgresql], puis exécutez le playbook postgresql_standby_setup.yml avec l'hôte cible respectif (tel que psql_01ps ou l'instance de calcul EC2 de secours sur le site principal). Assurez-vous qu'un fichier de paramètres d'hôte tel que
psql_01ps.ymlest configuré sous lehost_varsannuaire.[dr_postgresql] -- #psql_01s ansible_ssh_private_key_file=psql_01s.pem psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01ps.pem -e @vars/fsx_vars.ymlSauvegarde et réplication des snapshots de la base de données PostgreSQL vers le site de secours
La sauvegarde et la réplication des instantanés de la base de données PostgreSQL vers le site de secours peuvent être contrôlées et exécutées sur le contrôleur Ansible avec un intervalle défini par l'utilisateur. Nous avons validé que l’intervalle peut être aussi bas que 5 minutes. Par conséquent, en cas de panne sur le site principal, il existe 5 minutes de perte de données potentielle si la panne se produit juste avant la prochaine sauvegarde instantanée planifiée.
*/15 * * * * /home/admin/na_postgresql_aws_deploy_hadr/data_log_snap.shBasculement vers le site de secours pour la reprise après sinistre
Pour tester le système PostgreSQL HA/DR en tant qu'exercice DR, exécutez le basculement et la récupération de la base de données PostgreSQL sur l'instance de base de données EC2 de secours principale sur le site de secours en exécutant le playbook suivant. Dans un scénario de reprise après sinistre réel, exécutez la même chose pour un basculement réel vers un site de reprise après sinistre.
ansible-playbook -i hosts postgresql_failover.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlResynchroniser les volumes de base de données répliqués après le test de basculement
Exécutez la resynchronisation après le test de basculement pour rétablir la réplication SnapMirror du volume de base de données.
ansible-playbook -i hosts postgresql_standby_resync.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlBasculement du serveur de base de données EC2 principal vers le serveur de base de données EC2 de secours en raison d'une défaillance de l'instance de calcul EC2
NetApp recommande d'exécuter un basculement manuel ou d'utiliser un cluster de système d'exploitation bien établi qui peut nécessiter une licence.
Où trouver des informations supplémentaires
Pour en savoir plus sur les informations décrites dans ce document, consultez les documents et/ou sites Web suivants :
-
Amazon FSx ONTAP
-
Amazon EC2
-
Automatisation des solutions NetApp