

TR-5000 : Sauvegarde, récupération et clonage de bases de données PostgreSQL sur ONTAP avec SnapCenter
 Suggérer des modifications
Suggérer des modifications
Allen Cao, Niyaz Mohamed, NetApp
La solution fournit une vue d'ensemble et des détails sur la sauvegarde, la récupération et le clonage de la base de données PostgreSQL sur le stockage ONTAP dans le cloud public ou sur site via l'outil d'interface utilisateur de gestion de base de données NetApp SnapCenter .
But
Le logiciel NetApp SnapCenter software est une plate-forme d'entreprise facile à utiliser pour coordonner et gérer en toute sécurité la protection des données entre les applications, les bases de données et les systèmes de fichiers. Il simplifie la gestion du cycle de vie de la sauvegarde, de la restauration et du clonage en déchargeant ces tâches sur les propriétaires d'applications sans sacrifier la capacité de superviser et de réguler l'activité sur les systèmes de stockage. En exploitant la gestion des données basée sur le stockage, elle permet d’augmenter les performances et la disponibilité, ainsi que de réduire les temps de test et de développement.
Dans cette documentation, nous présentons la protection et la gestion de la base de données PostgreSQL sur le stockage NetApp ONTAP dans le cloud public ou sur site avec un outil d'interface utilisateur SnapCenter très convivial.
Cette solution répond aux cas d’utilisation suivants :
-
Sauvegarde et récupération de la base de données PostgreSQL déployée sur le stockage NetApp ONTAP dans le cloud public ou sur site.
-
Gérez les instantanés de base de données PostgreSQL et les copies clonées pour accélérer le développement d'applications et améliorer la gestion du cycle de vie des données.
Public
Cette solution est destinée aux personnes suivantes :
-
Un administrateur de base de données qui souhaite déployer des bases de données PostgreSQL sur un stockage NetApp ONTAP .
-
Un architecte de solutions de base de données qui souhaite tester les charges de travail PostgreSQL sur le stockage NetApp ONTAP .
-
Un administrateur de stockage souhaitant déployer et gérer des bases de données PostgreSQL sur le stockage NetApp ONTAP .
-
Un propriétaire d’application qui souhaite mettre en place une base de données PostgreSQL sur un stockage NetApp ONTAP .
Environnement de test et de validation de solutions
Les tests et la validation de cette solution ont été réalisés dans un environnement de laboratoire qui pourrait ne pas correspondre à l’environnement de déploiement final. Voir la sectionFacteurs clés à prendre en compte lors du déploiement pour plus d'informations.
Architecture
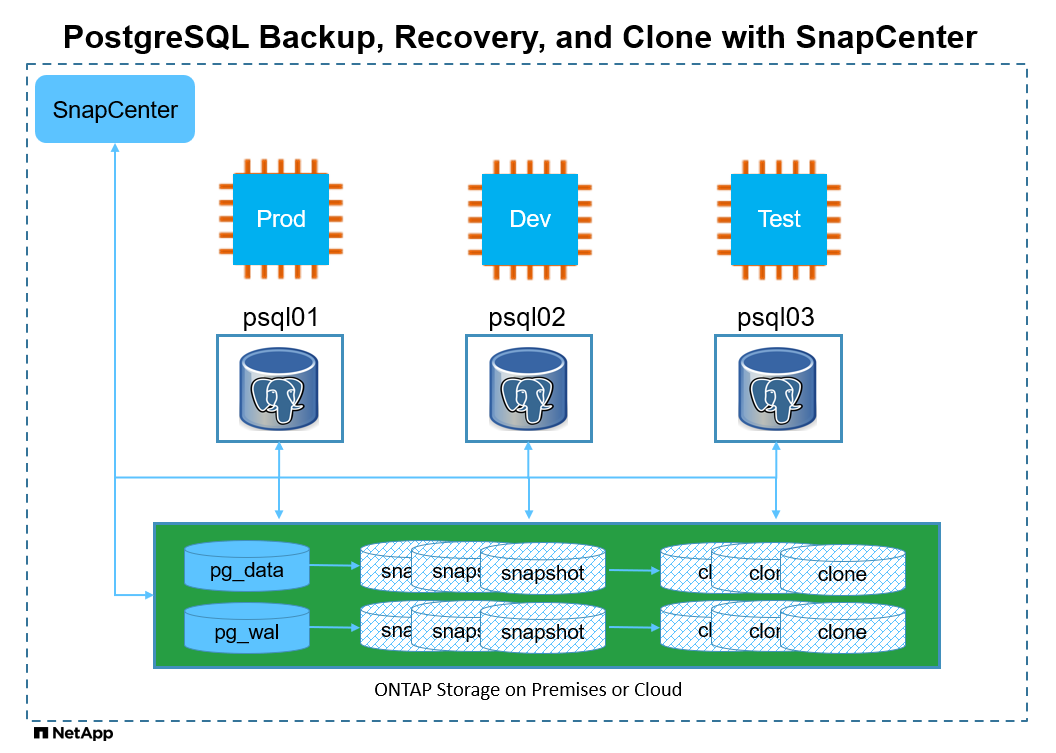
Composants matériels et logiciels
Matériel |
||
NetApp AFF A220 |
Version 9.12.1P2 |
Étagère à disques DS224-12, module IOM12E, capacité 24 disques / 12 Tio |
Cluster VMware vSphere |
Version 6.7 |
4 nœuds de calcul ESXi NetApp HCI H410C |
Logiciel |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Abonnement RedHat déployé pour les tests |
Windows Server |
Centre de données 2022 ; Hotpatch AE – x64 Gen2 |
Hébergement du serveur SnapCenter |
Base de données PostgreSQL |
Version 14.13 |
Cluster de bases de données PostgreSQL rempli avec le schéma HammerDB tpcc |
Serveur SnapCenter |
Version 6.0 |
Déploiement de groupe de travail |
Ouvrir le JDK |
Version java-11-openjdk |
Exigence du plug-in SnapCenter sur les machines virtuelles de base de données |
NFS |
Version 3.0 |
Séparez les données et enregistrez-les sur différents points de montage |
Ansible |
noyau 2.16.2 |
Python 3.6.8 |
Configuration de la base de données PostgreSQL dans l'environnement de laboratoire
Serveur |
Base de données |
Stockage de base de données |
psql01 |
Serveur de base de données principal |
/pgdata, /pglogs Montages de volumes NFS sur le stockage ONTAP |
psql02 |
Cloner le serveur de base de données |
/pgdata_clone, /pglogs_clone Le volume de clonage fin NFS est monté sur le stockage ONTAP |
Facteurs clés à prendre en compte lors du déploiement
-
* Déploiement de SnapCenter .* SnapCenter peut être déployé dans un domaine Windows ou un environnement de groupe de travail. Pour un déploiement basé sur un domaine, le compte d'utilisateur de domaine doit être un compte d'administrateur de domaine ou l'utilisateur de domaine doit appartenir au groupe de l'administrateur local sur le serveur d'hébergement SnapCenter .
-
Résolution de nom. Le serveur SnapCenter doit résoudre le nom en adresse IP pour chaque hôte de serveur de base de données cible géré. Chaque hôte de serveur de base de données cible doit résoudre le nom du serveur SnapCenter en adresse IP. Si un serveur DNS n'est pas disponible, ajoutez un nom aux fichiers hôtes locaux pour la résolution.
-
Configuration du groupe de ressources. Le groupe de ressources dans SnapCenter est un regroupement logique de ressources similaires qui peuvent être sauvegardées ensemble. Ainsi, cela simplifie et réduit le nombre de tâches de sauvegarde dans un environnement de base de données volumineux.
-
Sauvegarde complète séparée de la base de données et du journal d'archive. La sauvegarde complète de la base de données inclut des volumes de données et des instantanés de groupe cohérents avec les volumes de journaux. Un instantané complet et fréquent de la base de données entraîne une consommation de stockage plus élevée, mais améliore le RTO. Une alternative consiste à effectuer des instantanés de base de données complets moins fréquents et des sauvegardes de journaux d'archives plus fréquentes, ce qui consomme moins de stockage et améliore le RPO mais peut étendre le RTO. Tenez compte de vos objectifs RTO et RPO lors de la configuration du schéma de sauvegarde. Il existe également une limite (1023) du nombre de sauvegardes instantanées sur un volume.
-
* Délégation de Privileges .* Tirez parti du contrôle d'accès basé sur les rôles intégré à l'interface utilisateur de SnapCenter pour déléguer des privilèges aux équipes d'application et de base de données si vous le souhaitez.
Déploiement de la solution
Les sections suivantes fournissent des procédures étape par étape pour le déploiement, la configuration et la sauvegarde, la récupération et le clonage de la base de données PostgreSQL de SnapCenter sur le stockage NetApp ONTAP dans le cloud public ou sur site.
Prérequis pour le déploiement
Details
-
Le déploiement nécessite deux bases de données PostgreSQL existantes exécutées sur le stockage ONTAP , l'une comme serveur de base de données principal et l'autre comme serveur de base de données clone. Pour référence sur le déploiement de la base de données PostgreSQL sur ONTAP, reportez-vous à TR-4956 :"Déploiement automatisé de haute disponibilité PostgreSQL et reprise après sinistre dans AWS FSx/EC2" , à la recherche du playbook de déploiement automatisé PostgreSQL sur l'instance principale.
-
Provisionnez un serveur Windows pour exécuter l’outil d’interface utilisateur NetApp SnapCenter avec la dernière version. Consultez le lien suivant pour plus de détails :"Installer le serveur SnapCenter" .
Installation et configuration de SnapCenter
Details
Nous vous recommandons de passer par en ligne"Documentation du logiciel SnapCenter" avant de procéder à l'installation et à la configuration de SnapCenter : . Ce qui suit fournit un résumé de haut niveau des étapes d'installation et de configuration du SnapCenter software pour PostgreSQL sur ONTAP.
-
Depuis le serveur Windows SnapCenter , téléchargez et installez le dernier JDK Java à partir de"Obtenez Java pour les applications de bureau" . Désactiver le pare-feu Windows.
-
À partir du serveur Windows SnapCenter , téléchargez et installez ou mettez à jour les prérequis Windows SnapCenter 6.0 : PowerShell - PowerShell-7.4.3-win-x64.msi et package d'hébergement .Net - dotnet-hosting-8.0.6-win.
-
À partir du serveur Windows SnapCenter , téléchargez et installez la dernière version (actuellement 6.0) de l'exécutable d'installation de SnapCenter à partir du site de support NetApp :"NetApp | Assistance" .
-
À partir des machines virtuelles de base de données, activez l'authentification sans mot de passe SSH pour l'utilisateur administrateur
adminet ses privilèges sudo sans mot de passe. -
À partir des machines virtuelles de la base de données DB, arrêtez et désactivez le démon du pare-feu Linux. Installez java-11-openjdk.
-
À partir du serveur Windows SnapCenter , lancez le navigateur pour vous connecter à SnapCenter avec les informations d'identification de l'administrateur local Windows ou de l'utilisateur de domaine via le port 8146.
-
Revoir
Get Startedmenu en ligne.
-
Dans
Settings-Global Settings, vérifierHypervisor Settingset cliquez sur Mettre à jour.
-
Si nécessaire, ajustez
Session Timeoutpour l'interface utilisateur SnapCenter à l'intervalle souhaité.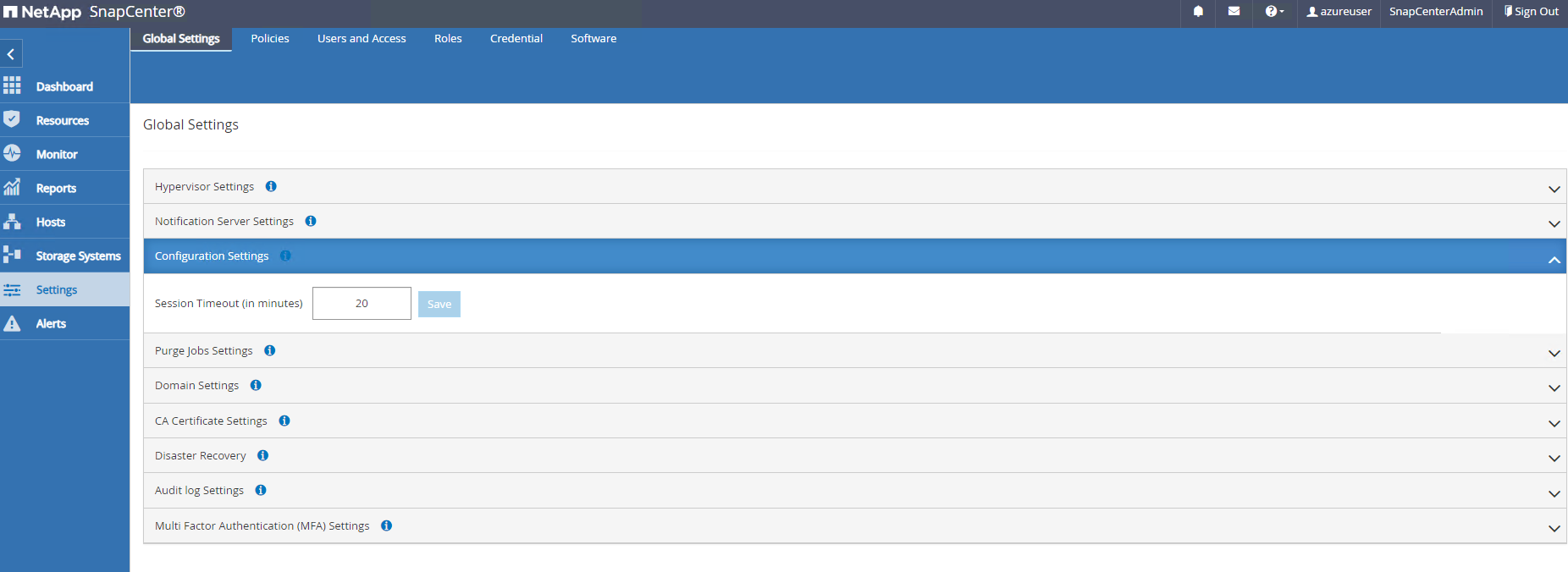
-
Ajoutez des utilisateurs supplémentaires à SnapCenter si nécessaire.
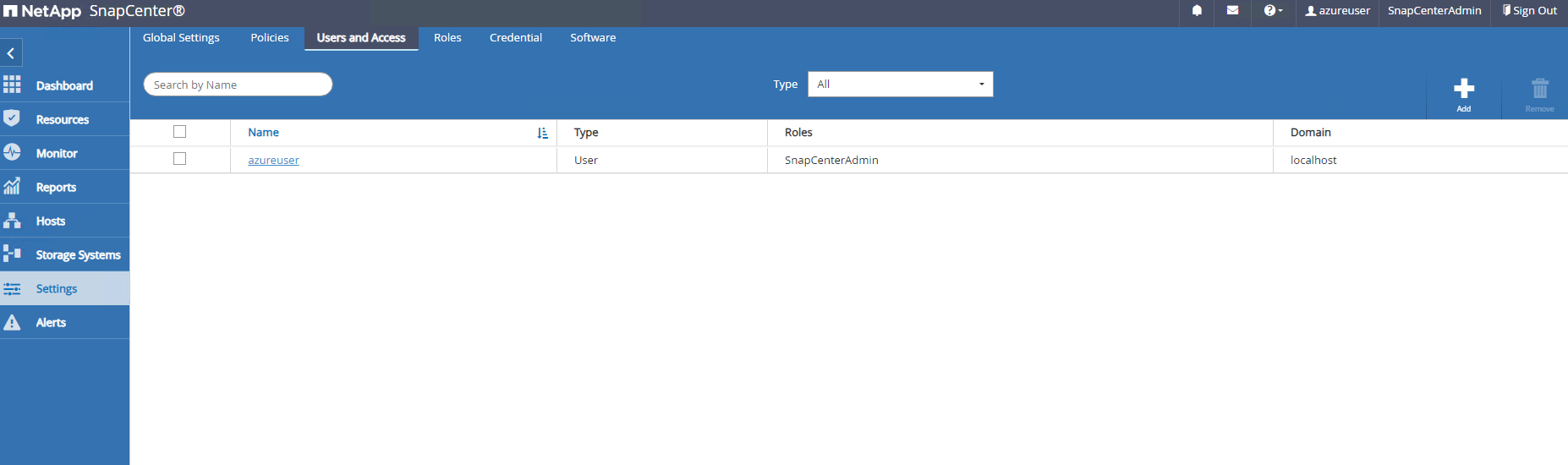
-
Le
RolesL'onglet répertorie les rôles intégrés qui peuvent être attribués à différents utilisateurs de SnapCenter . Des rôles personnalisés peuvent également être créés par l'utilisateur administrateur avec les privilèges souhaités.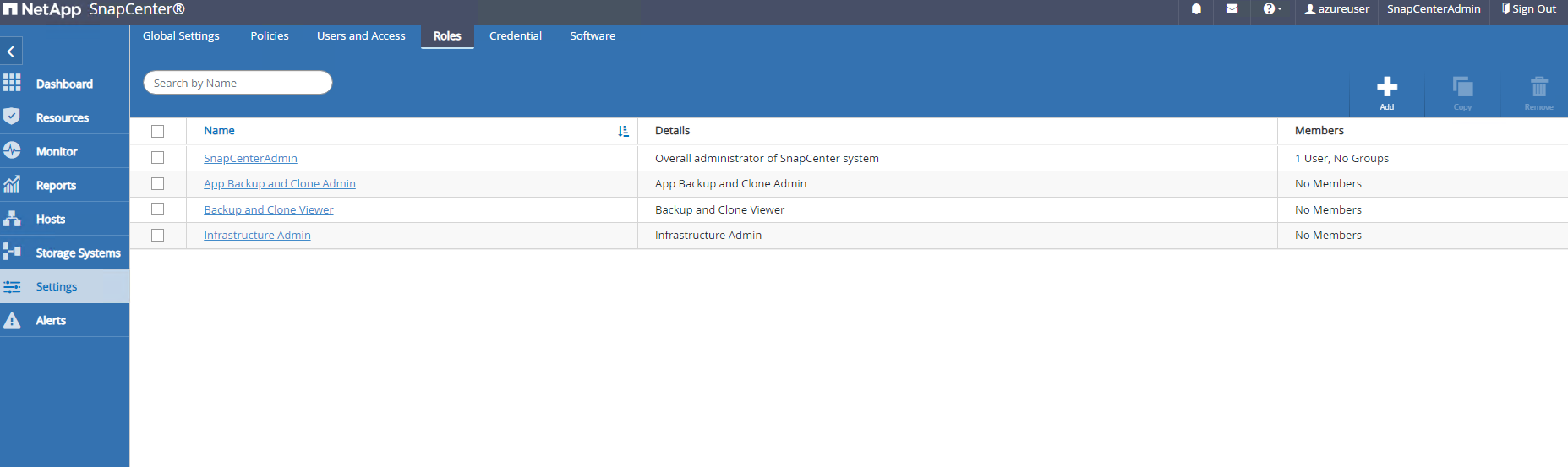
-
Depuis
Settings-Credential, créez des informations d'identification pour les cibles de gestion SnapCenter . Dans ce cas d'utilisation de démonstration, il s'agit d'un administrateur utilisateur Linux pour la connexion à la machine virtuelle du serveur de base de données et d'informations d'identification Postgres pour l'accès à PostgreSQL.

Réinitialisez le mot de passe de l'utilisateur PostgreSQL avant de créer les informations d'identification. -
Depuis
Storage Systemsonglet, ajouterONTAP clusteravec les informations d'identification d'administrateur de cluster ONTAP . Pour Azure NetApp Files, vous devrez créer des informations d’identification spécifiques pour l’accès au pool de capacité.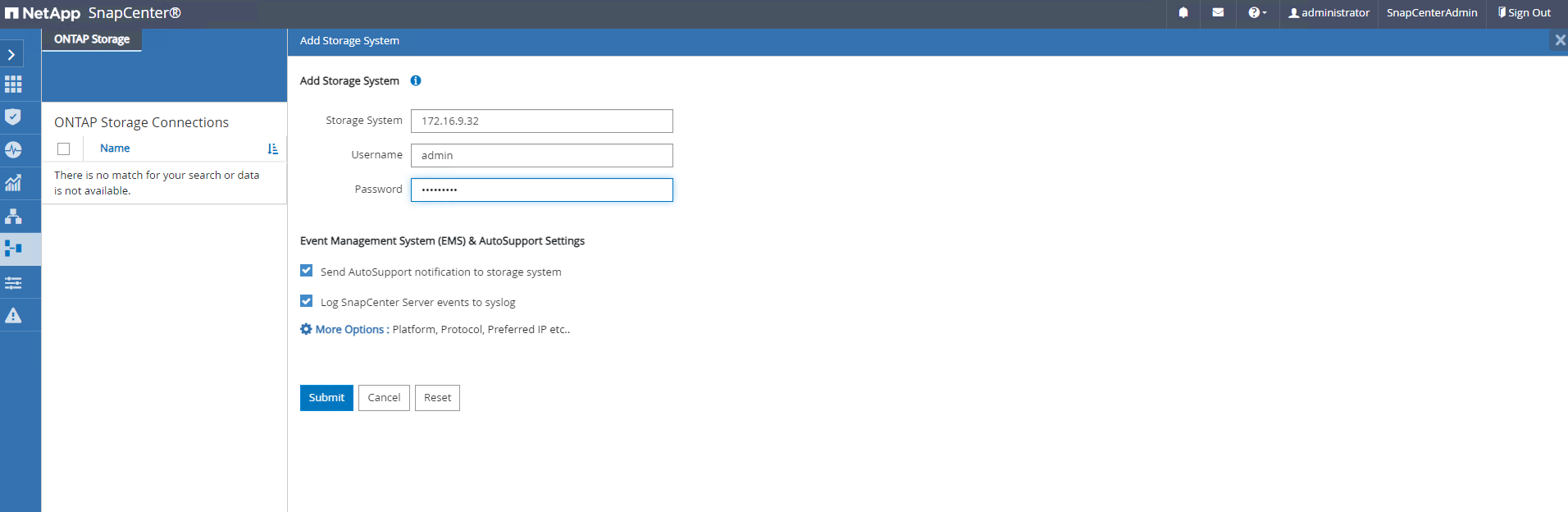
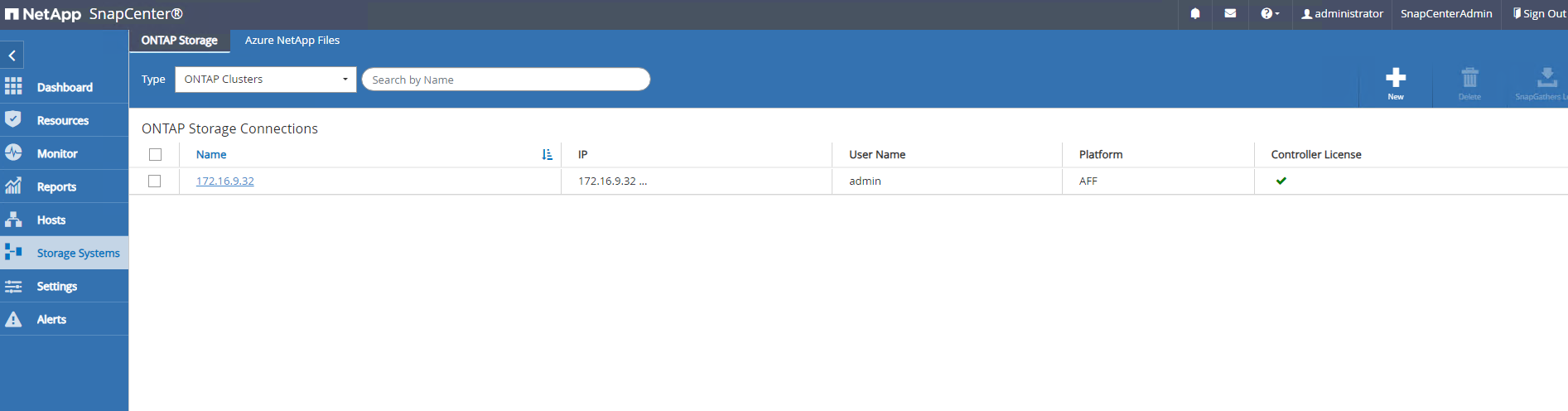
-
Depuis
Hostsonglet, ajoutez les machines virtuelles PostgreSQL DB, qui installent le plugin SnapCenter pour PostgreSQL sur Linux.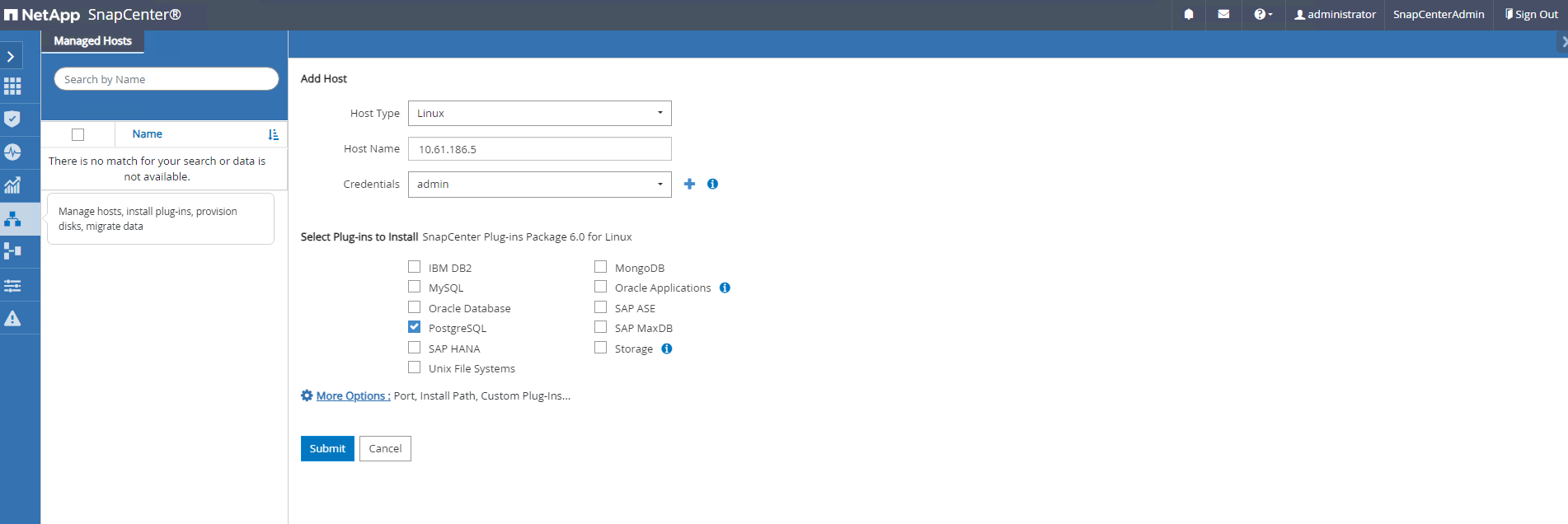
-
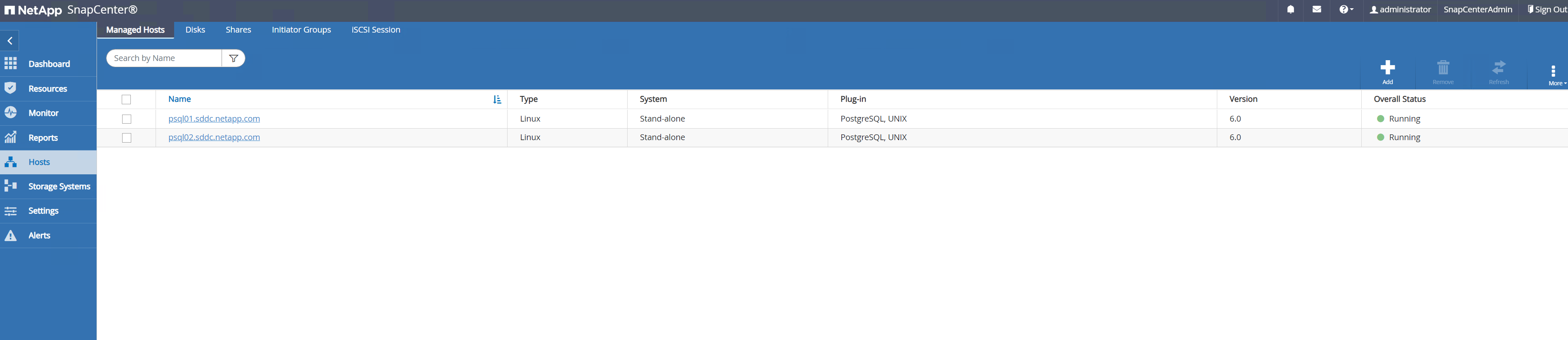
Une fois le plugin hôte installé sur la machine virtuelle du serveur de base de données, les bases de données sur l'hôte sont automatiquement découvertes et visibles dans
Resourceslanguette.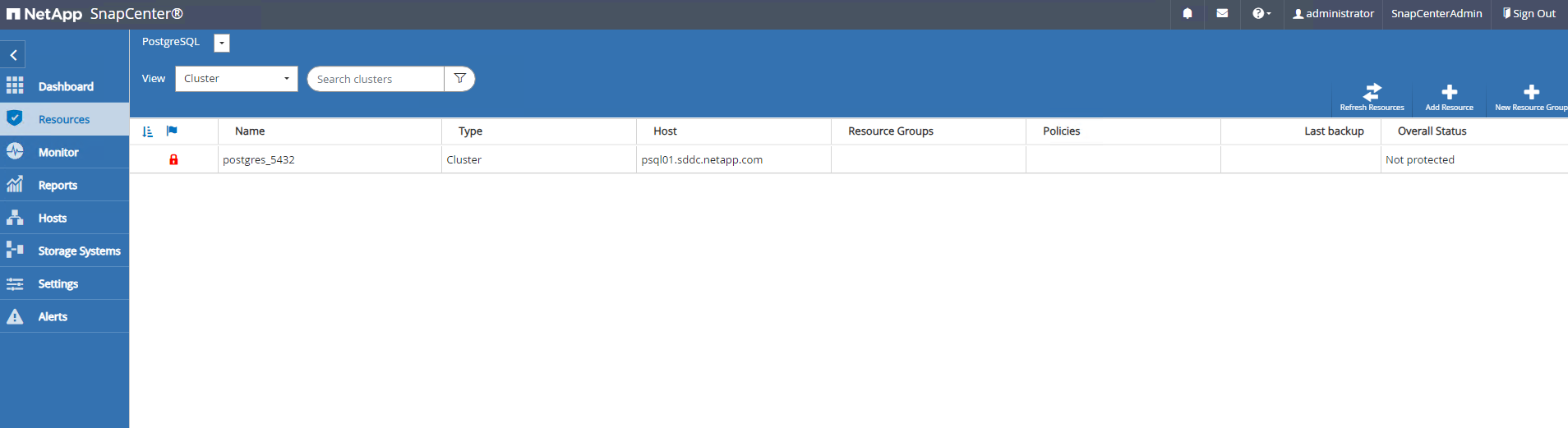
Sauvegarde de la base de données
Details
Le cluster PostgreSQL initial découvert automatiquement affiche un cadenas rouge à côté de son nom de cluster. Il doit être déverrouillé à l'aide des informations d'identification de la base de données PostgreSQL créées lors de la configuration de SnapCenter dans la section précédente. Ensuite, vous devez créer et appliquer une politique de sauvegarde pour protéger la base de données. Enfin, exécutez la sauvegarde manuellement ou à l’aide d’un planificateur pour créer une sauvegarde SnapShot. La section suivante présente les procédures étape par étape.
-
Déverrouiller le cluster PostgreSQL.
-
Navigation vers
Resourcesonglet, qui répertorie le cluster PostgreSQL découvert après l'installation du plugin SnapCenter sur la machine virtuelle de base de données. Au départ, il est verrouillé et leOverall Statusdu cluster de bases de données s'affiche commeNot protected. -
Cliquez sur le nom du cluster, puis,
Configure Credentialspour ouvrir la page de configuration des informations d'identification.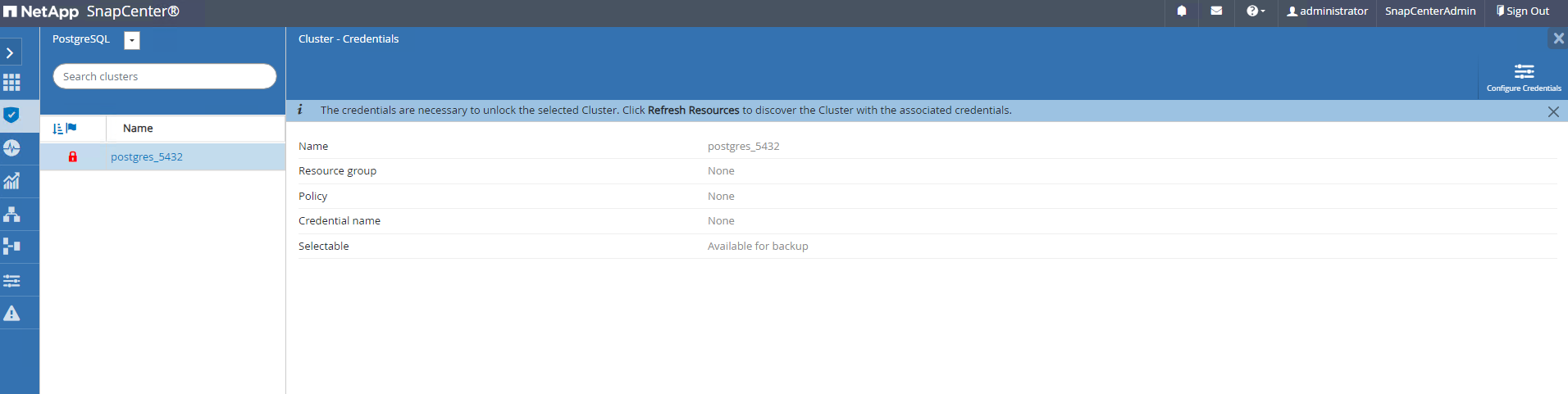
-
Choisir
postgresinformations d'identification créées lors de la configuration précédente de SnapCenter .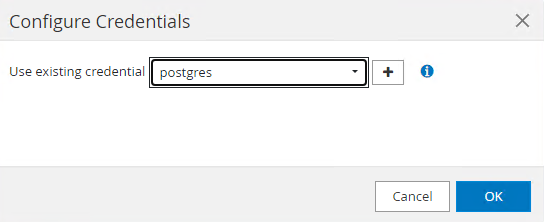
-
Une fois les informations d'identification appliquées, le cluster sera déverrouillé.

-
-
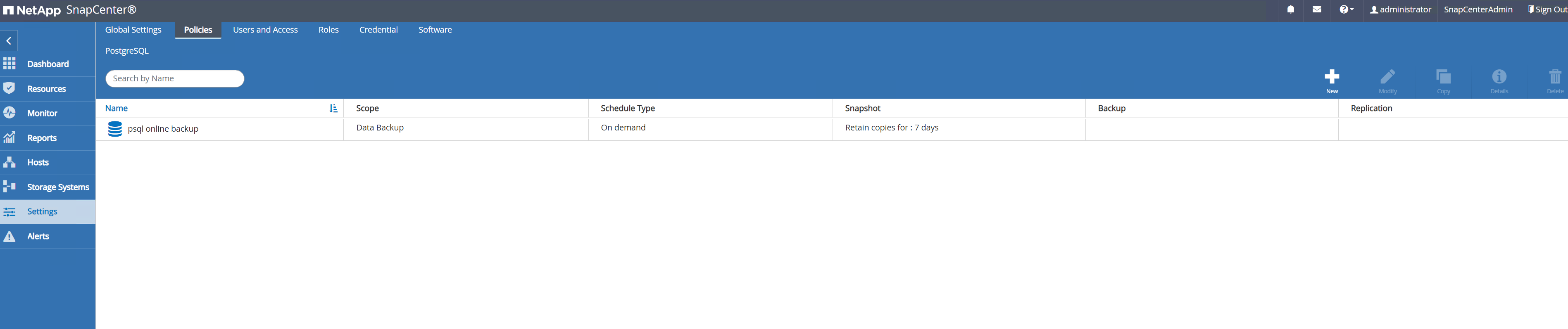
Créez une politique de sauvegarde PostgreSQL.
-
Accéder à
Setting-Policeset cliquez surNewpour créer une politique de sauvegarde.
-
Nommez la politique de sauvegarde.
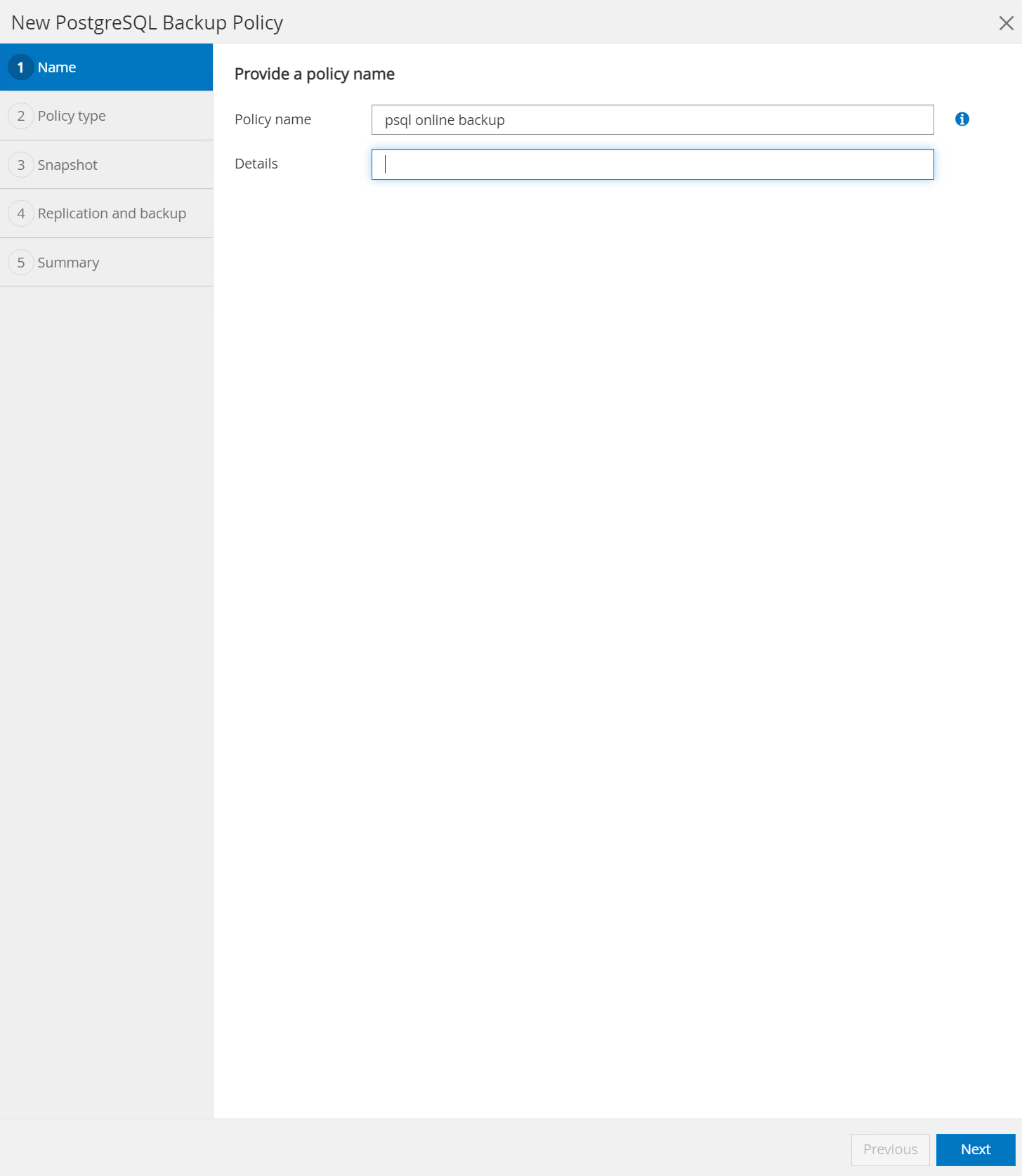
-
Choisissez le type de stockage. Le paramètre de sauvegarde par défaut devrait convenir à la plupart des scénarios.
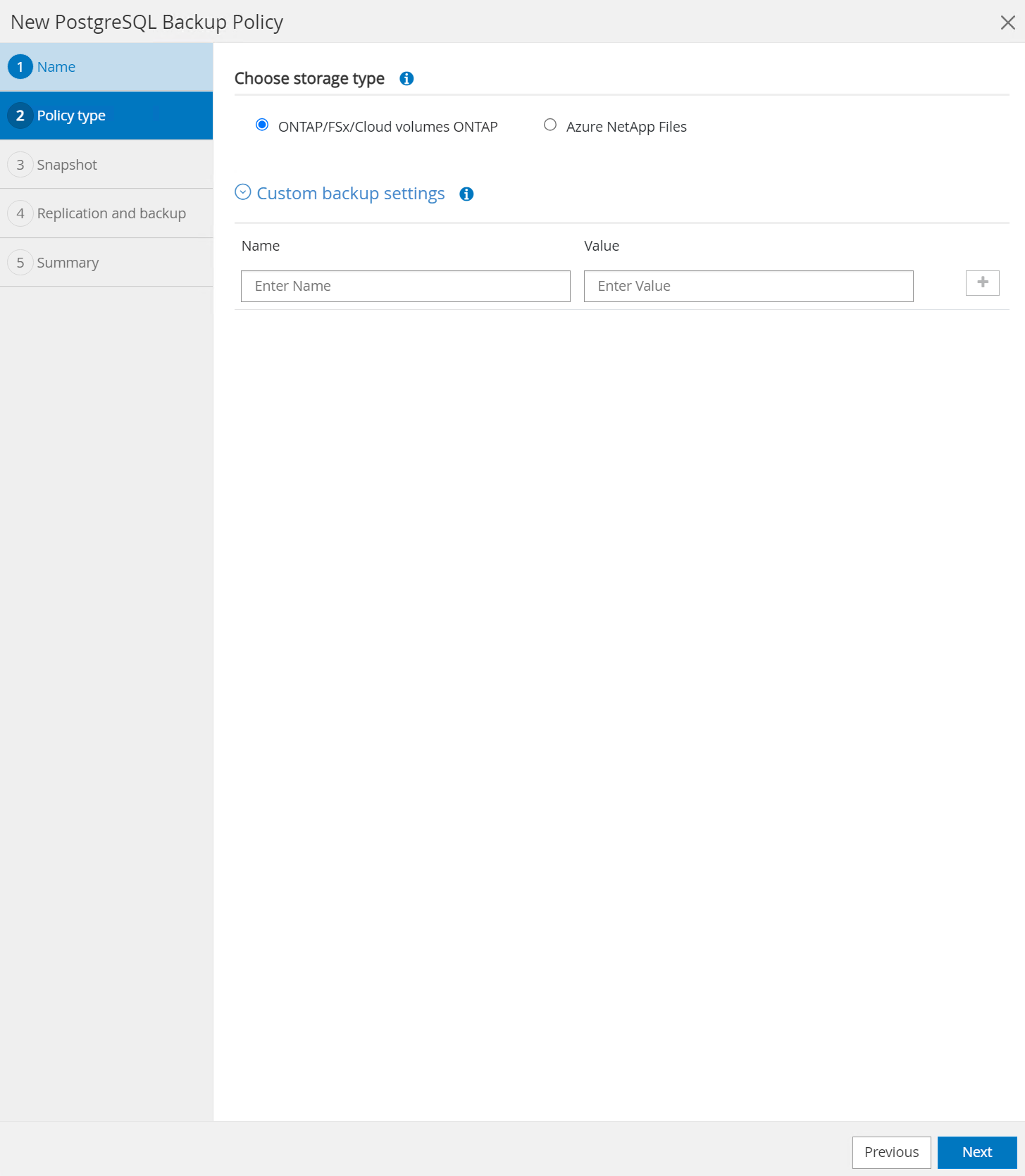
-
Définissez la fréquence de sauvegarde et la conservation des SnapShot.
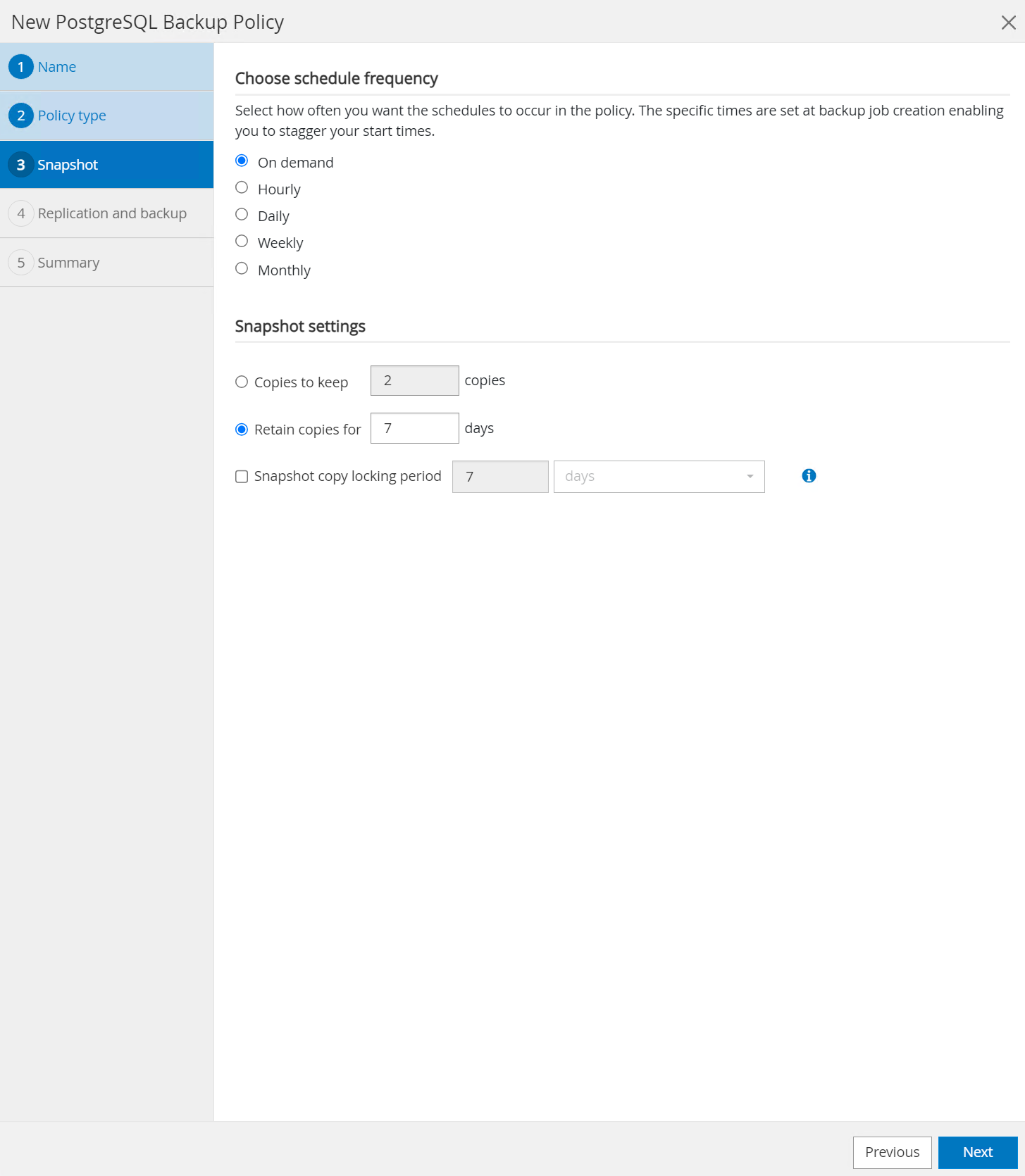
-
Option permettant de sélectionner la réplication secondaire si les volumes de base de données sont répliqués vers un emplacement secondaire.
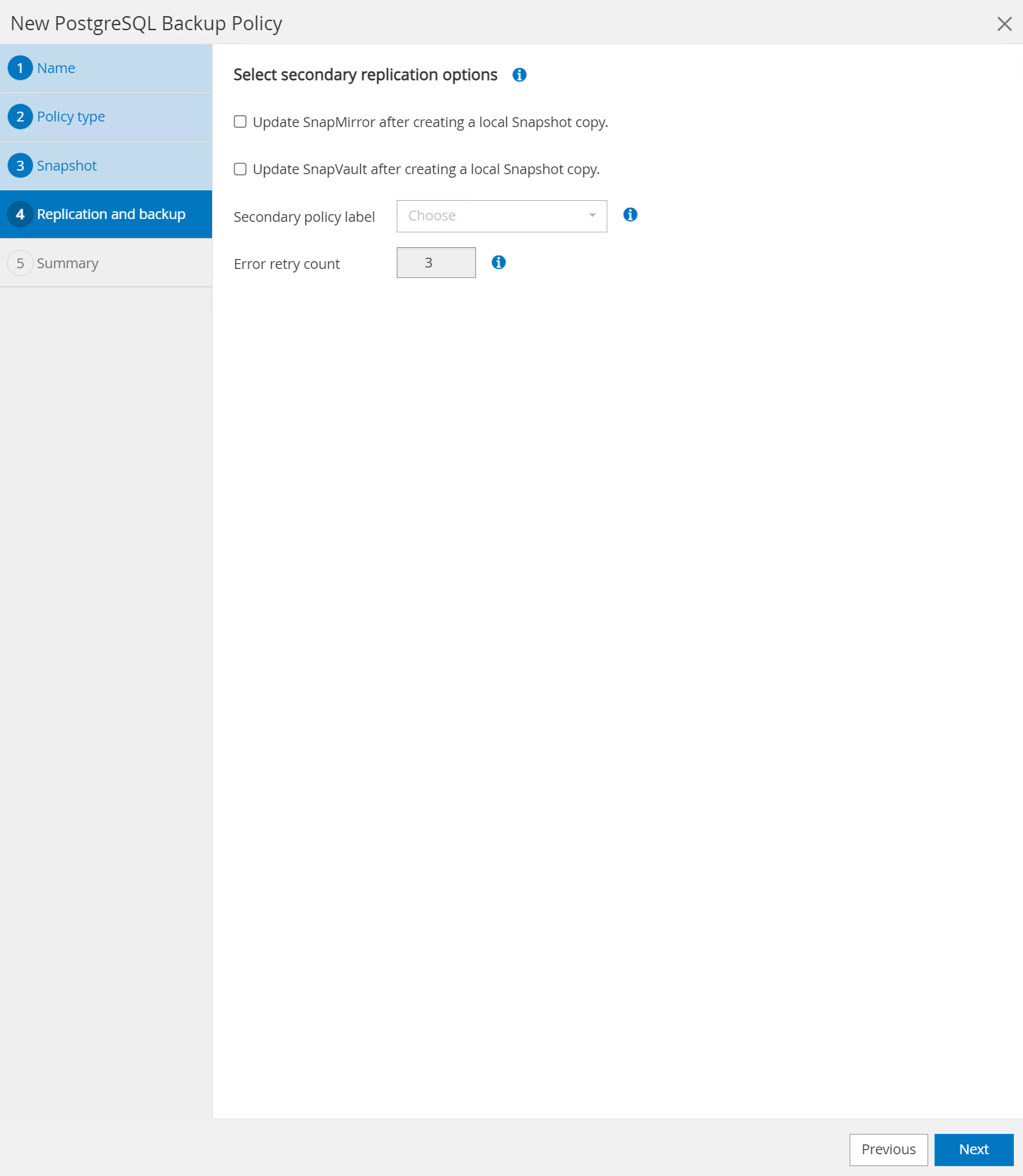
-
Consultez le résumé et
Finishpour créer la politique de sauvegarde.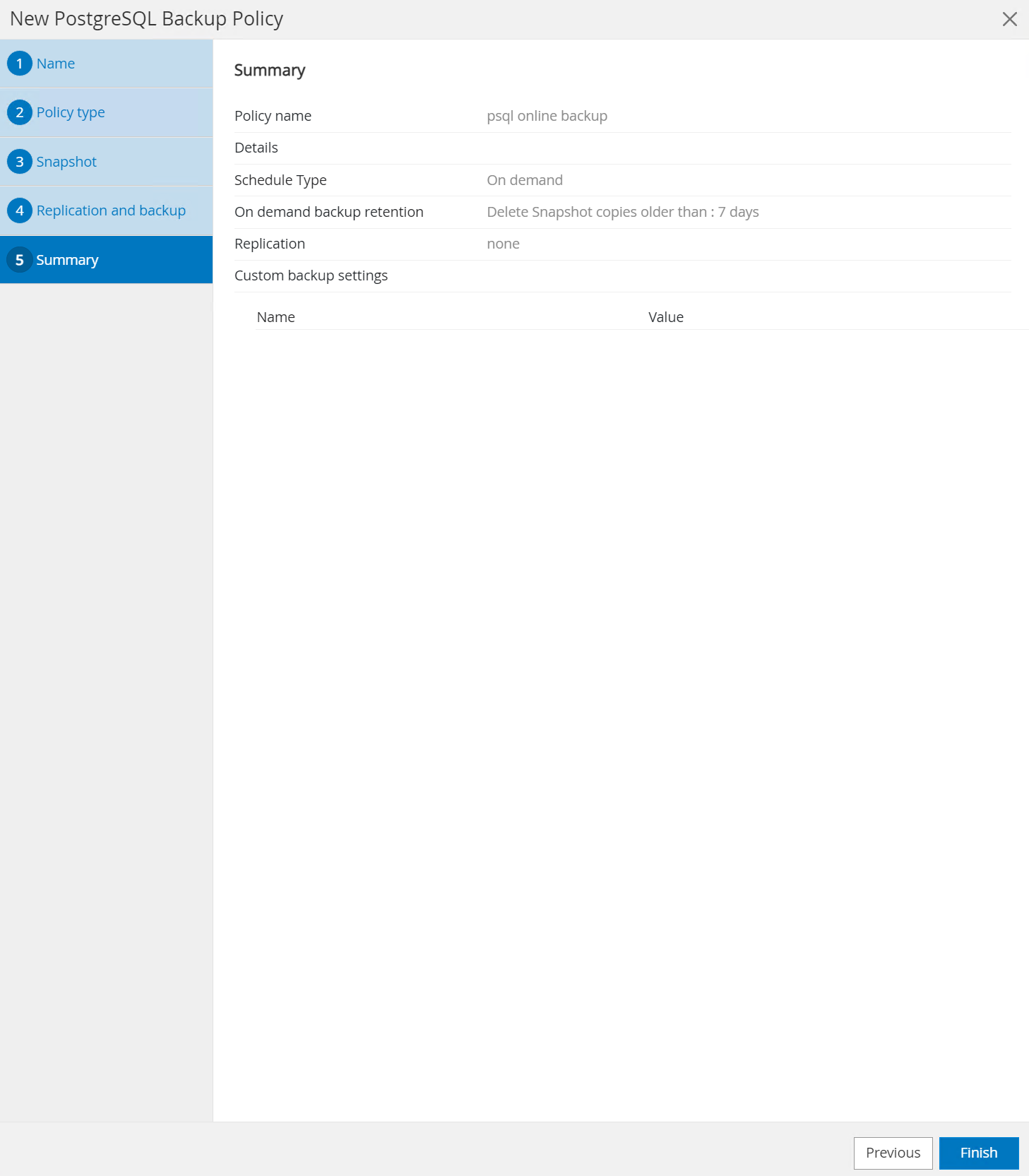
-
-
Appliquez une politique de sauvegarde pour protéger la base de données PostgreSQL.
-
Revenir à
Resourceonglet, cliquez sur le nom du cluster pour lancer le workflow de protection du cluster PostgreSQL.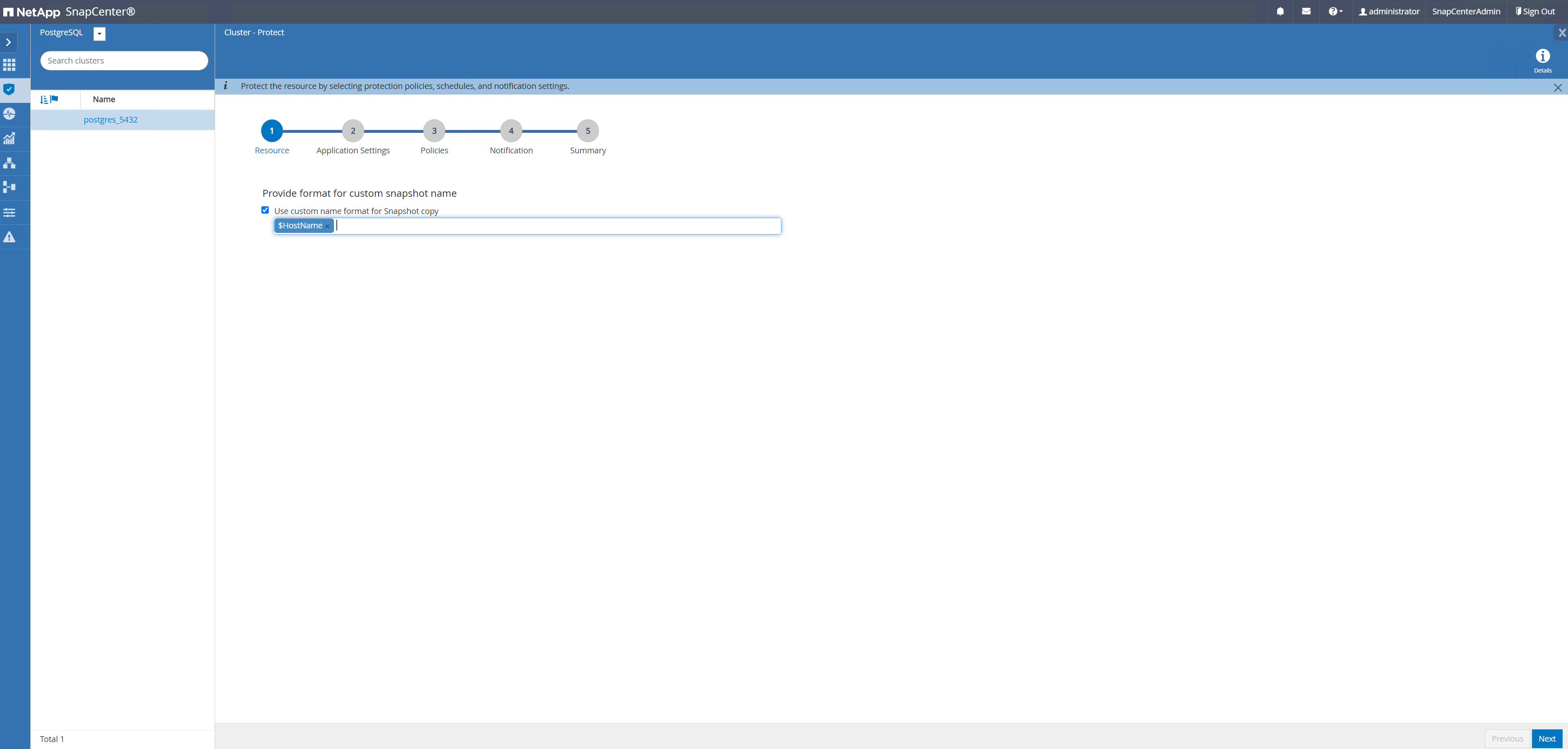
-
Accepter la valeur par défaut
Application Settings. De nombreuses options de cette page ne s'appliquent pas à la cible découverte automatiquement.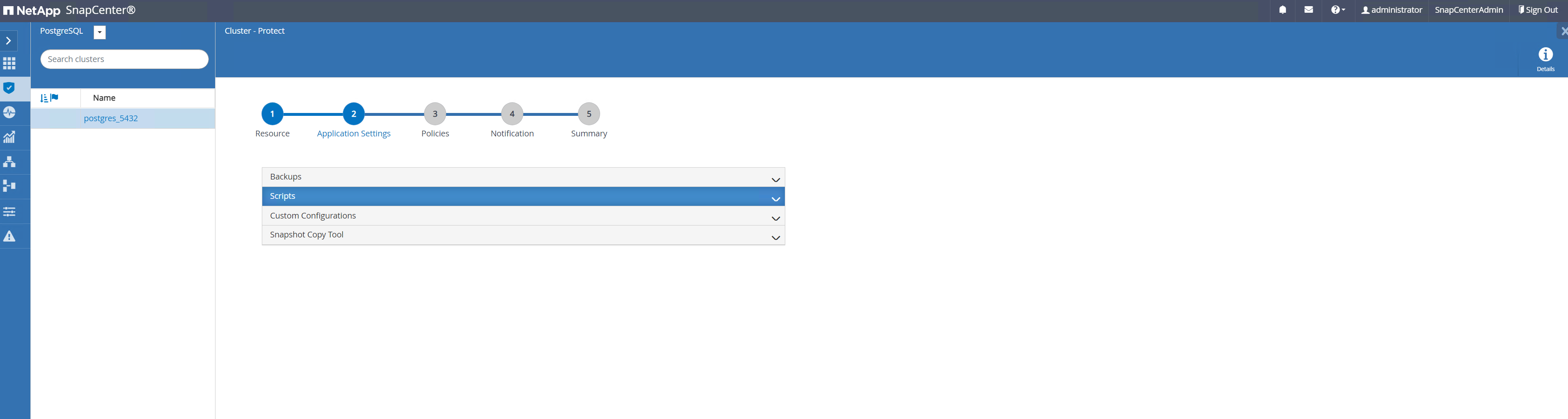
-
Appliquez la politique de sauvegarde qui vient d’être créée. Ajoutez un calendrier de sauvegarde si nécessaire.
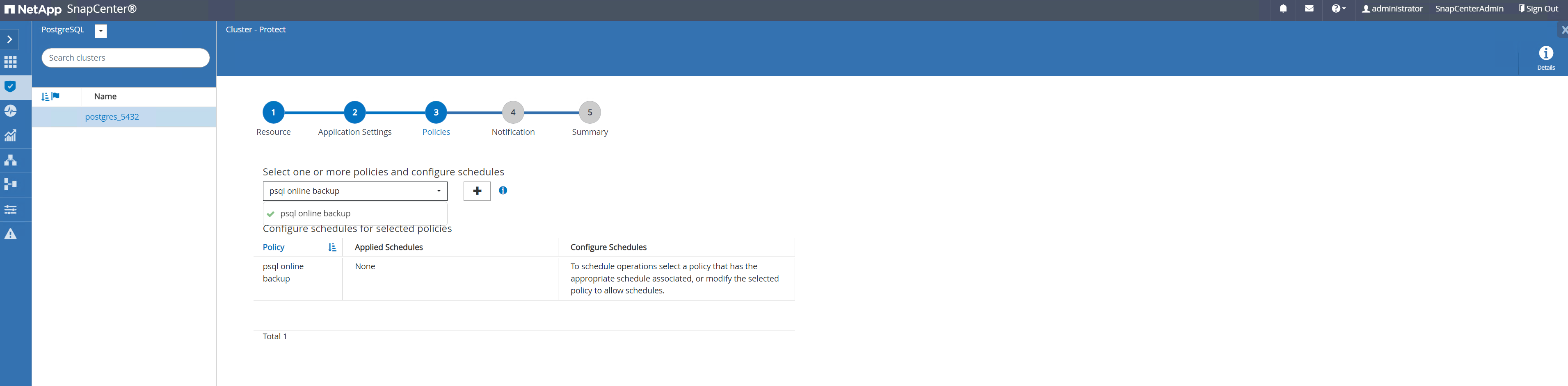
-
Fournissez un paramètre de courrier électronique si une notification de sauvegarde est requise.
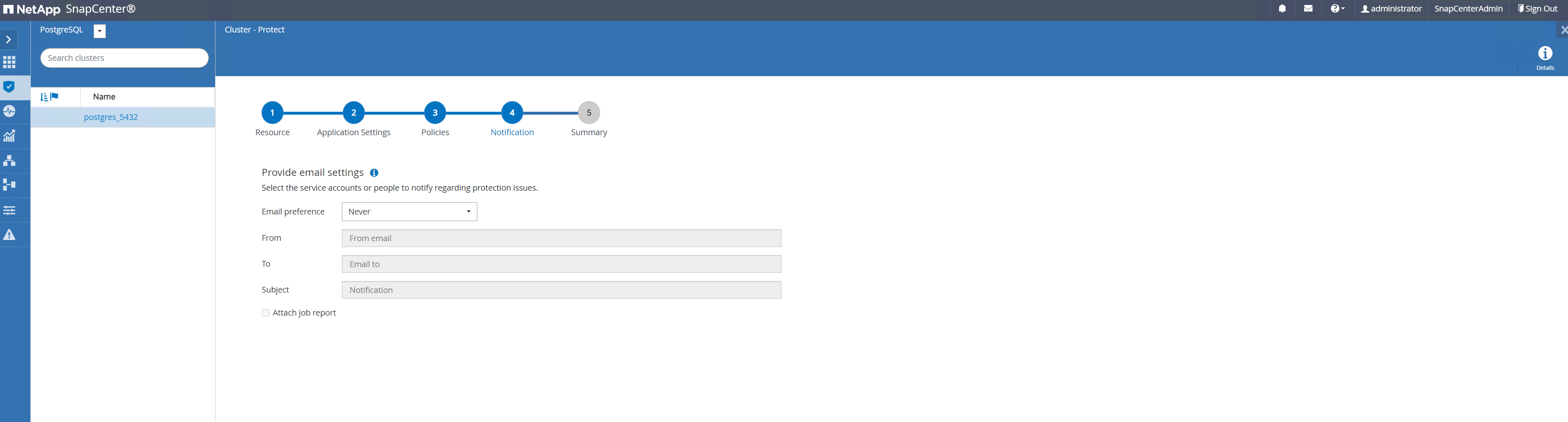
-
Résumé de l'examen et
Finishpour mettre en œuvre la politique de sauvegarde. Le cluster PostgreSQL est désormais protégé.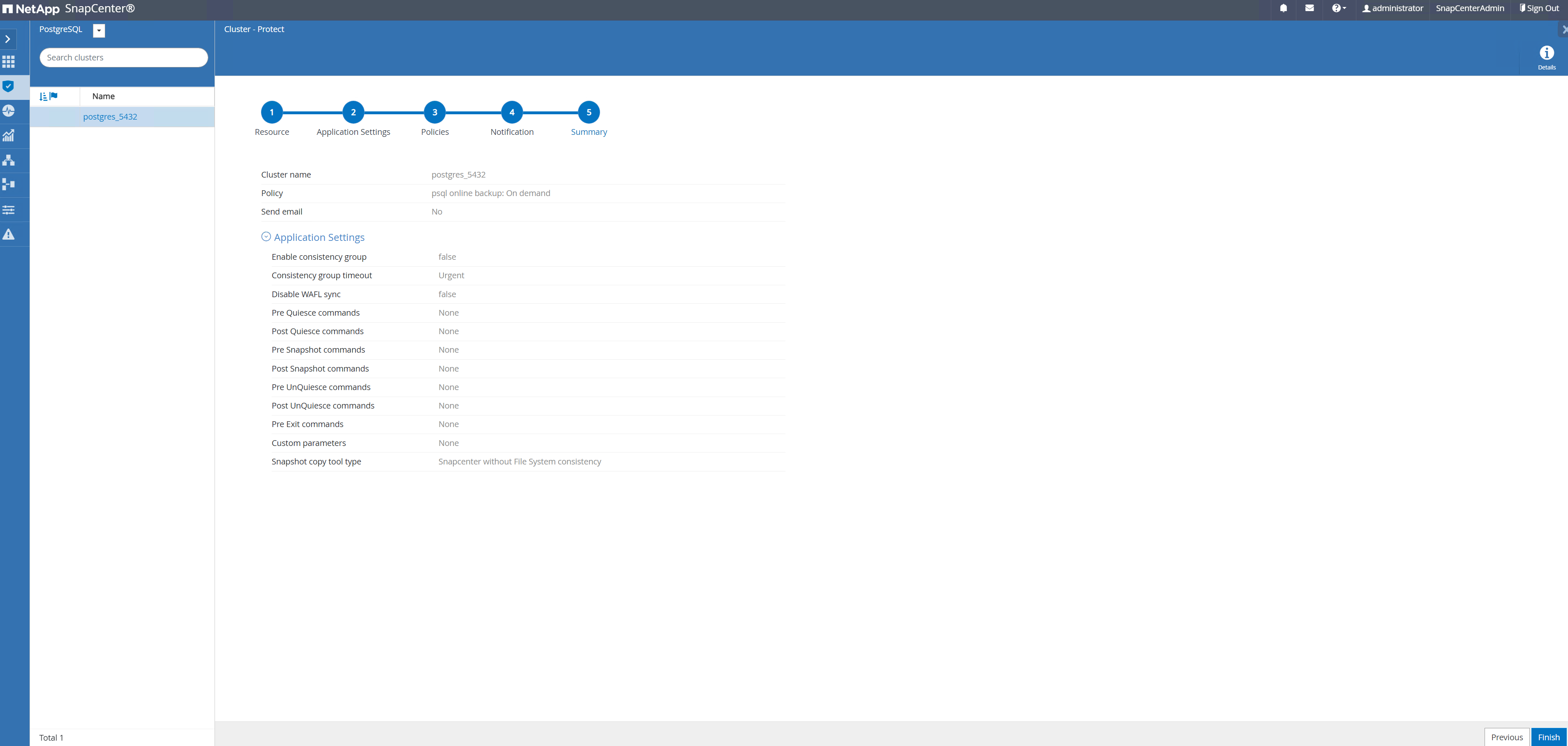
-
La sauvegarde est exécutée selon le calendrier de sauvegarde ou à partir de la topologie de sauvegarde du cluster, cliquez sur
Backup Nowpour déclencher une sauvegarde manuelle à la demande.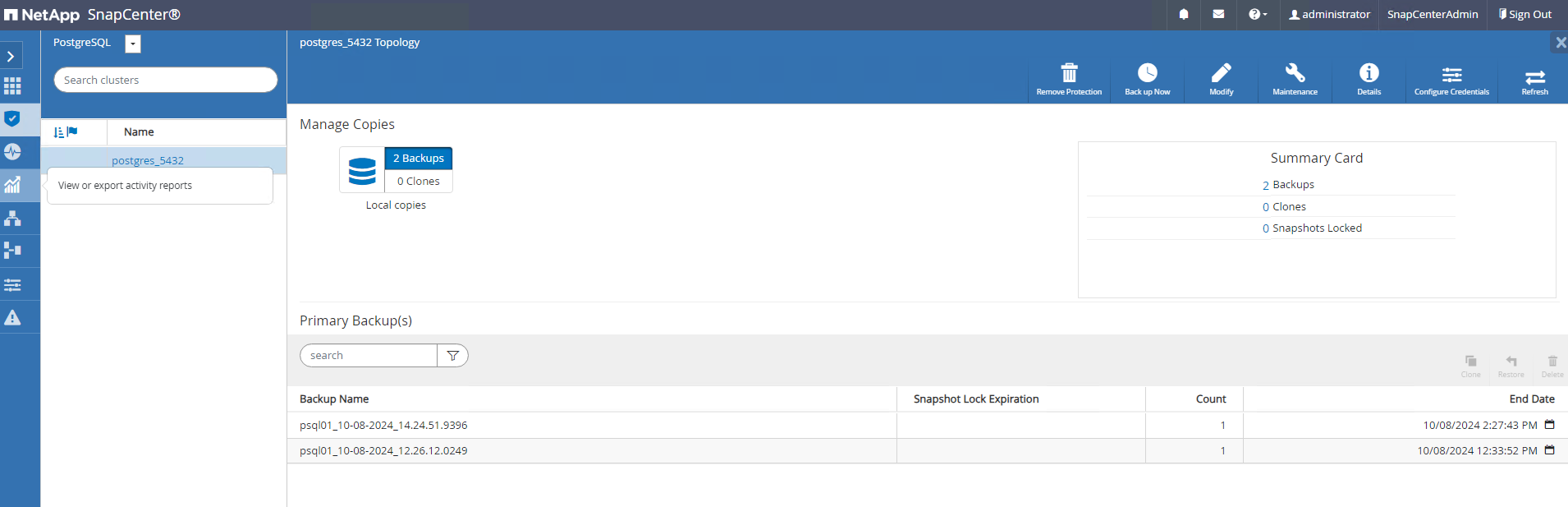
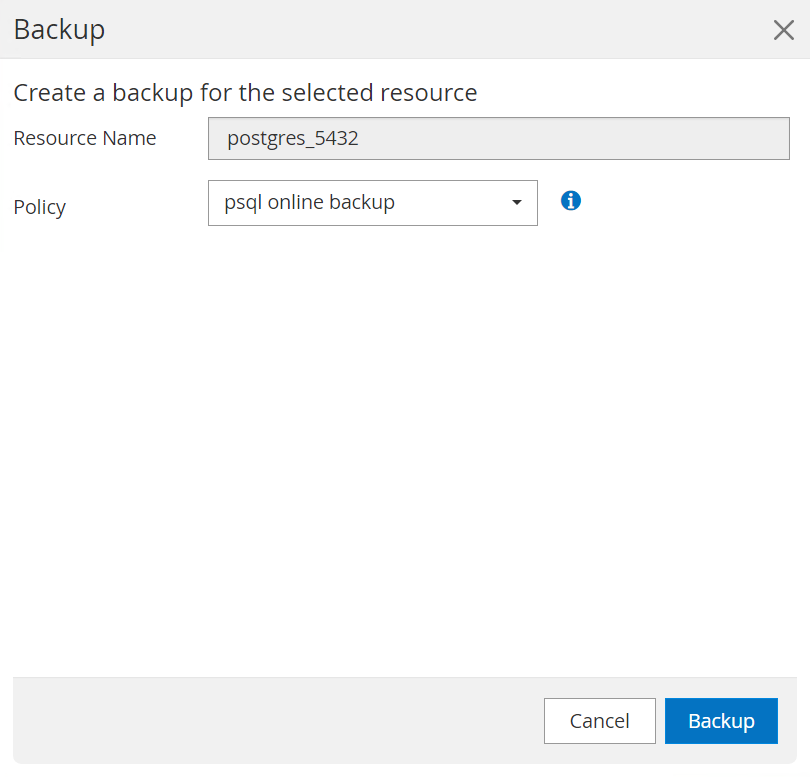
-
Surveiller le travail de sauvegarde à partir de
Monitorlanguette. Il faut généralement quelques minutes pour sauvegarder une grande base de données et dans notre cas de test, il a fallu environ 4 minutes pour sauvegarder des volumes de base de données proches de 1 To.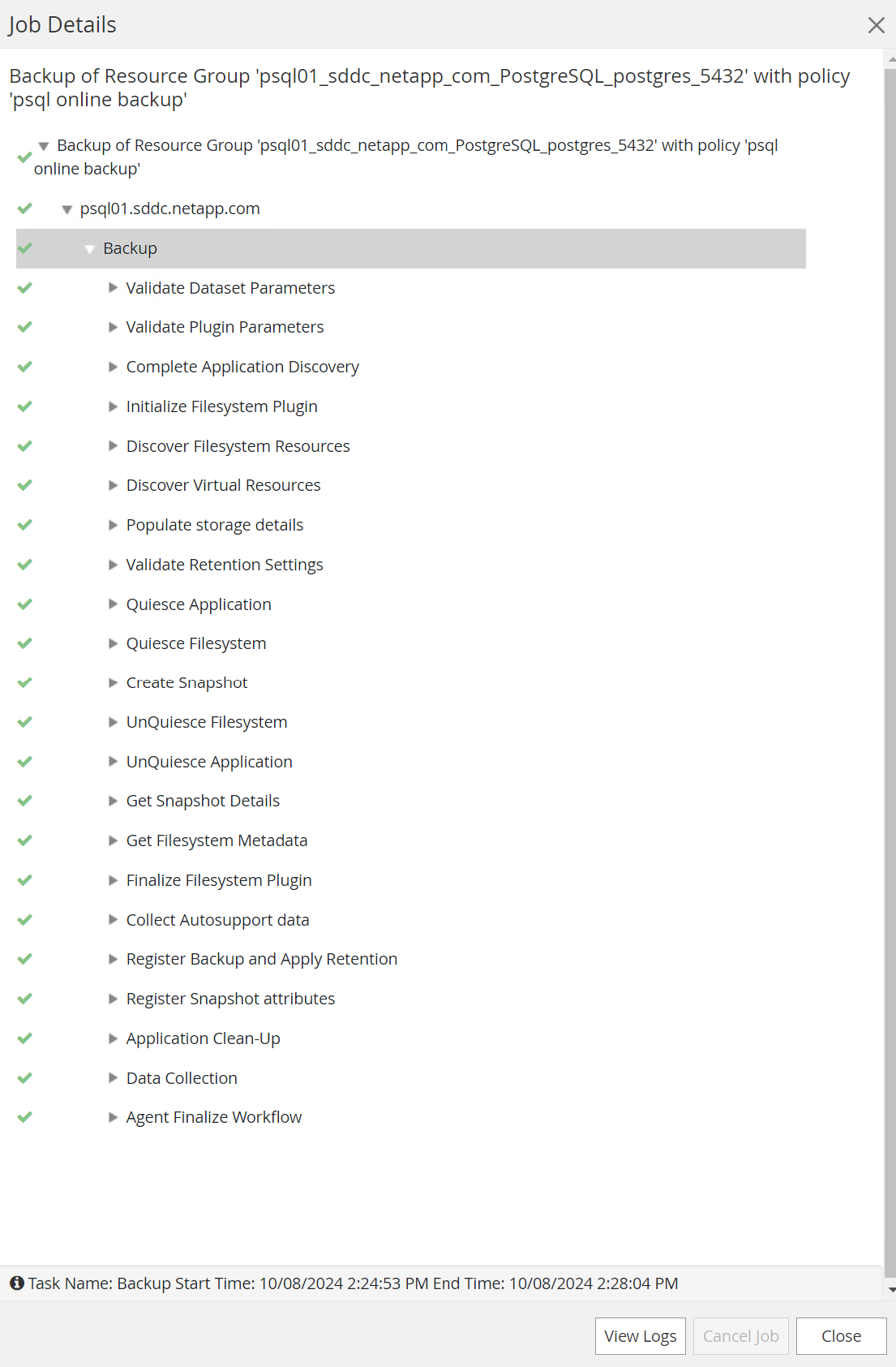
-
Récupération de base de données
Details
Dans cette démonstration de récupération de base de données, nous présentons une récupération ponctuelle du cluster de base de données PostgreSQL. Tout d’abord, créez une sauvegarde SnapShot du volume de base de données sur le stockage ONTAP à l’aide de SnapCenter. Ensuite, connectez-vous à la base de données, créez une table de test, notez l’horodatage et supprimez la table de test. Lancez maintenant une récupération à partir de la sauvegarde jusqu'à l'horodatage lorsque la table de test est créée pour récupérer la table supprimée. Ce qui suit capture les détails du flux de travail et de la validation de la récupération ponctuelle de la base de données PostgreSQL avec l'interface utilisateur SnapCenter .
-
Connectez-vous à PostgreSQL en tant que
postgresutilisateur. Créez, puis supprimez une table de test.postgres=# \dt Did not find any relations. postgres=# create table test (id integer, dt timestamp, event varchar(100)); CREATE TABLE postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# insert into test values (1, now(), 'test PostgreSQL point in time recovery with SnapCenter'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# drop table test; DROP TABLE postgres=# \dt Did not find any relations. postgres=# select current_time; current_time -------------------- 17:59:20.984144+00 -
Depuis
Resourcesonglet, ouvrez la page de sauvegarde de la base de données. Sélectionnez la sauvegarde SnapShot à restaurer. Ensuite, cliquez surRestorebouton pour lancer le flux de travail de récupération de la base de données. Notez l’horodatage de la sauvegarde lorsque vous effectuez une récupération à un instant donné.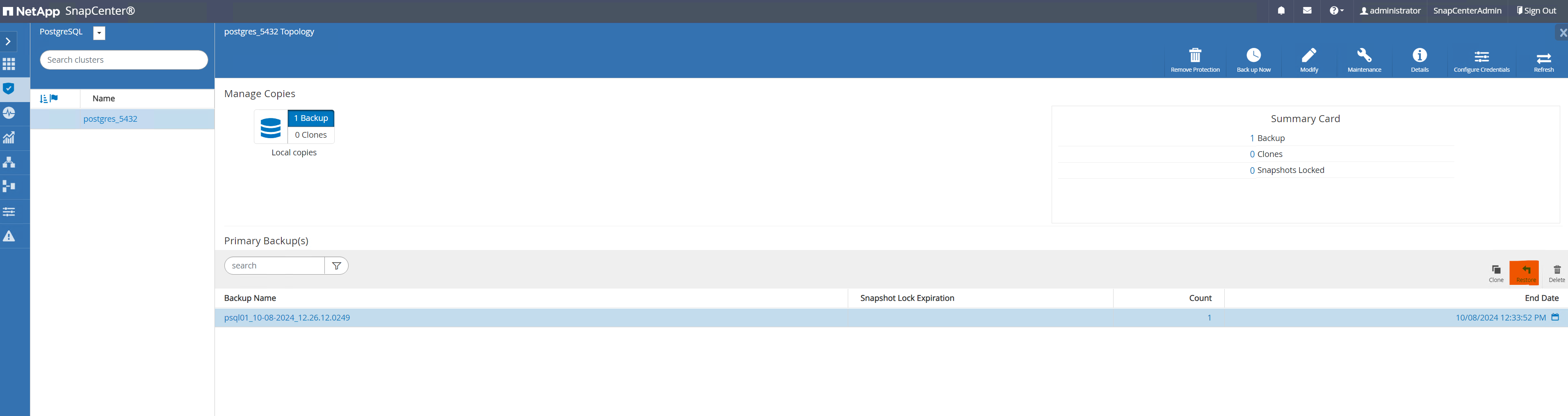
-
Sélectionner
Restore scope. À l’heure actuelle, une ressource complète est la seule option.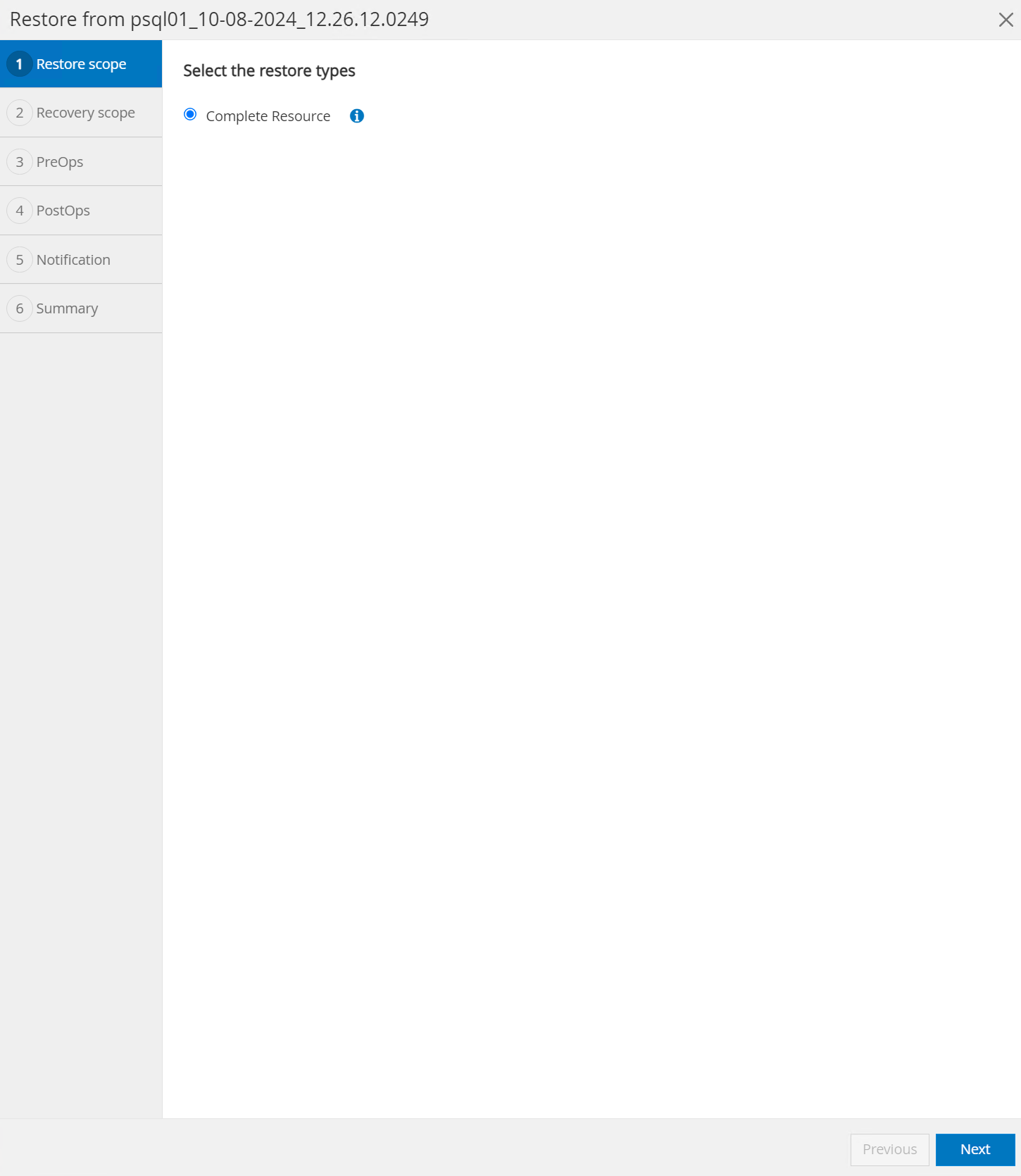
-
Pour
Recovery Scope, choisirRecover to point in timeet saisissez l'horodatage jusqu'auquel la récupération est reportée.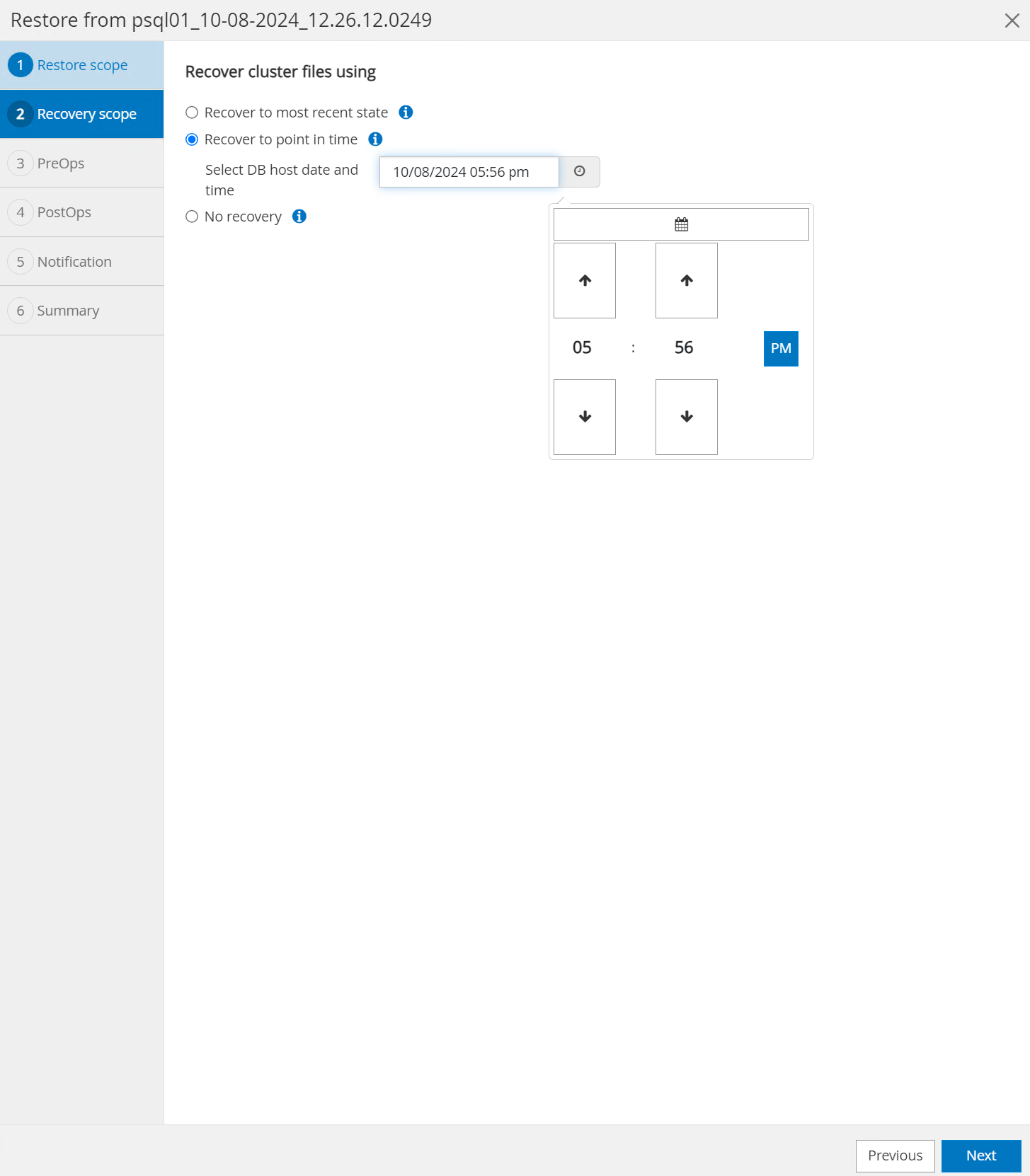
-
Le
PreOpspermet l'exécution de scripts sur la base de données avant l'opération de restauration/récupération ou simplement la laisser noire.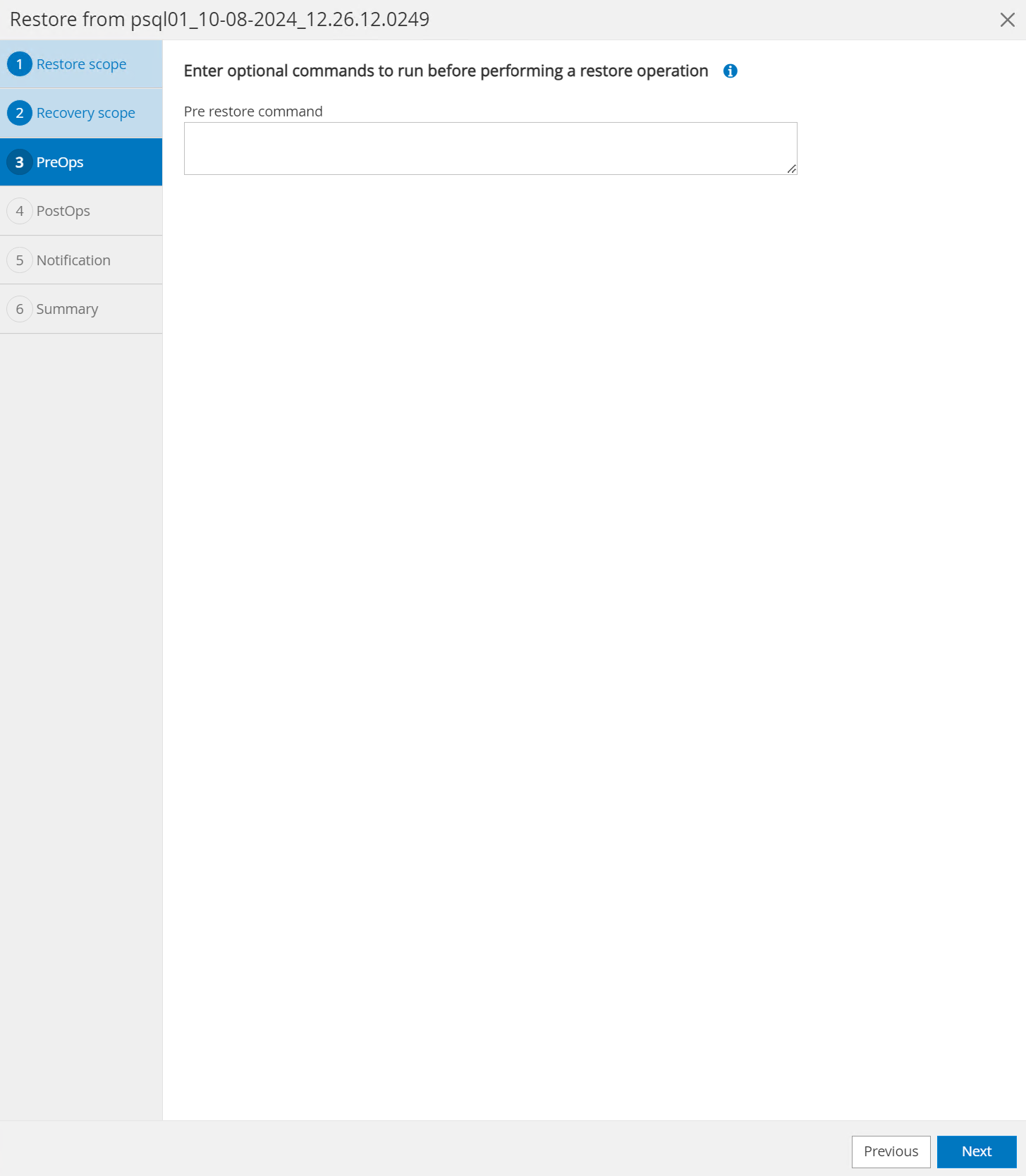
-
Le
PostOpspermet l'exécution de scripts sur la base de données après une opération de restauration/récupération ou simplement la laisser noire.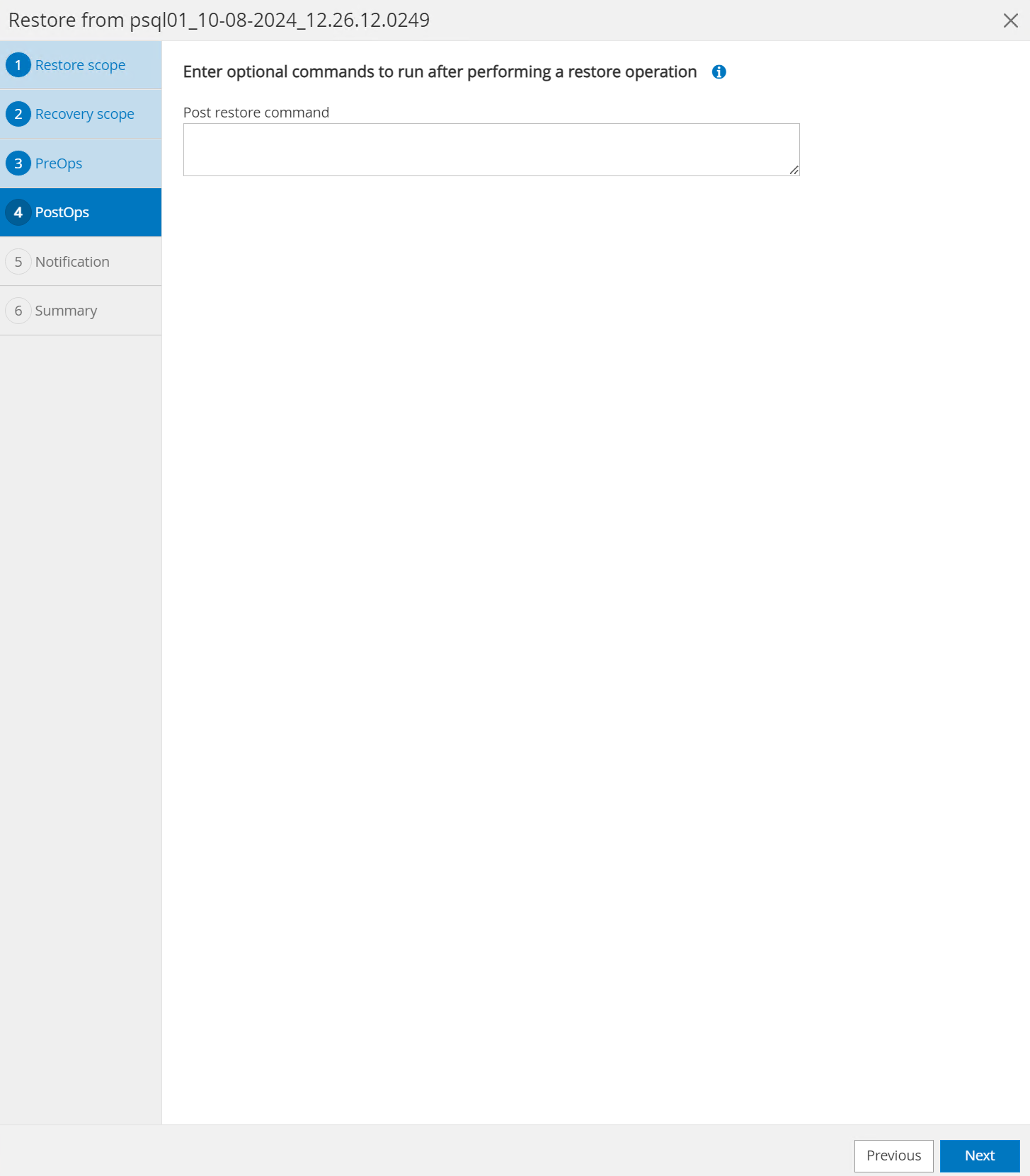
-
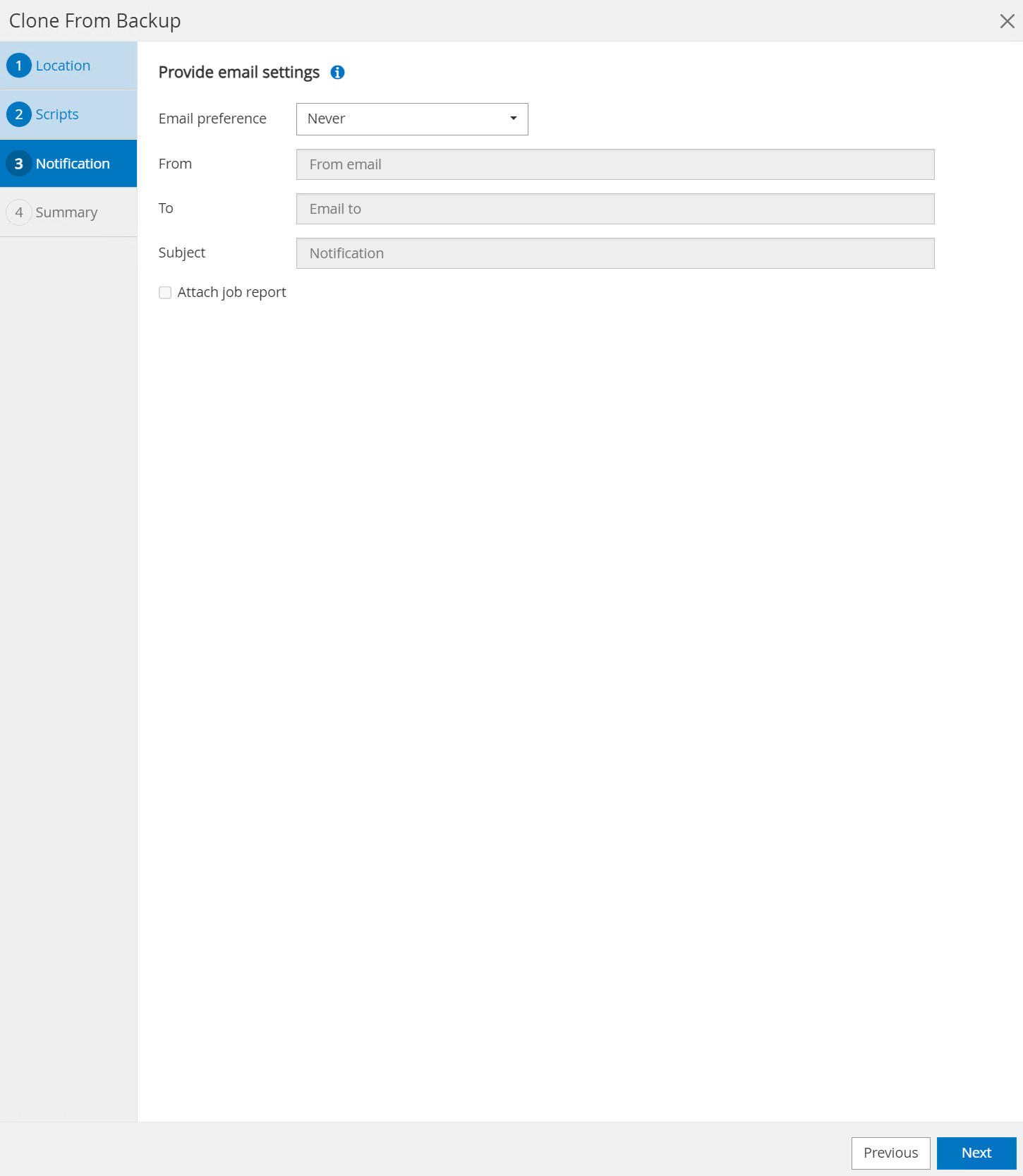
Notification par email si vous le souhaitez.
-
Consultez le résumé du poste et
Finishpour démarrer le travail de restauration.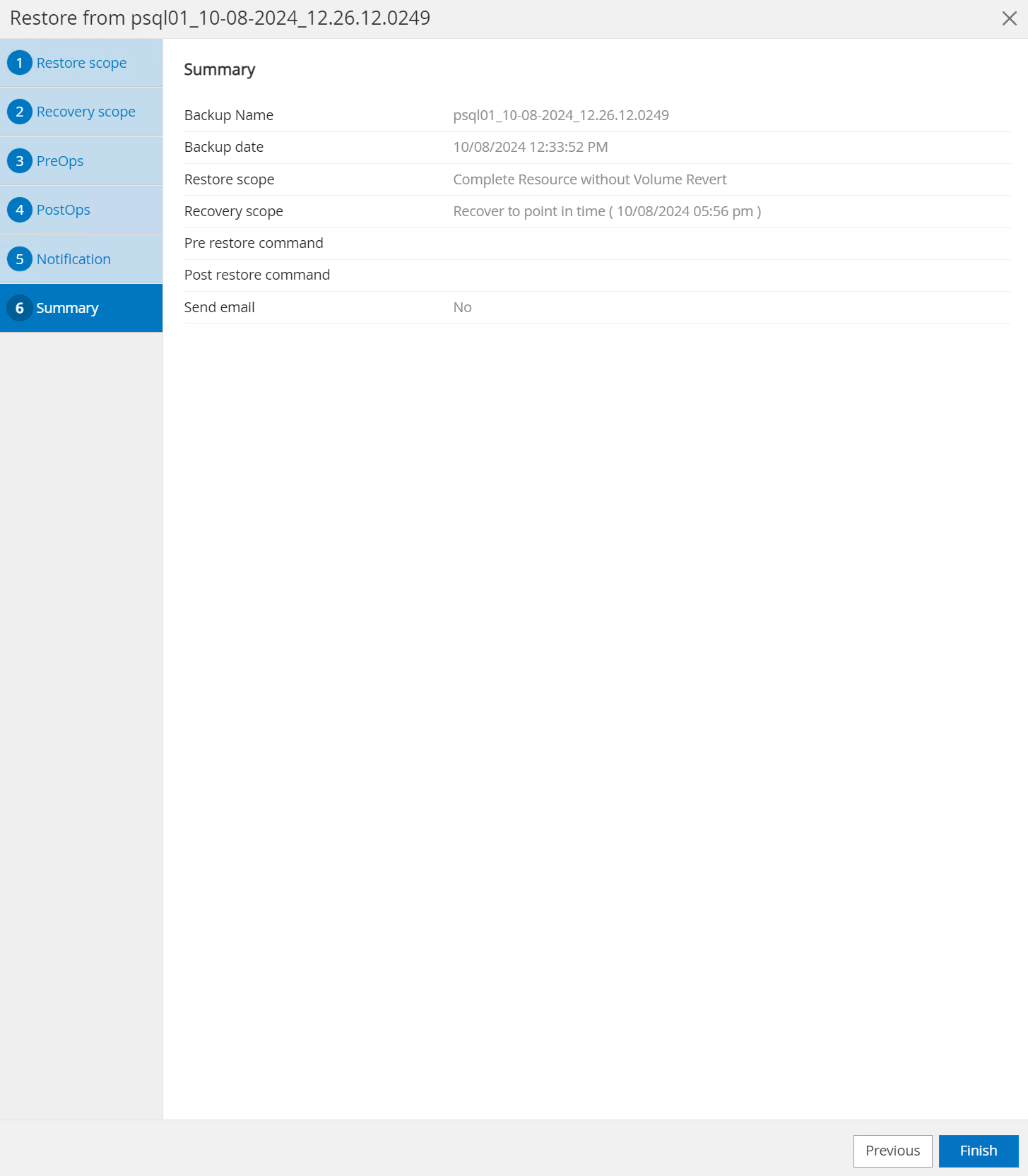
-
Cliquez sur la tâche en cours d'exécution pour l'ouvrir
Job Detailsfenêtre. Le statut du travail peut également être ouvert et visualisé à partir duMonitorlanguette.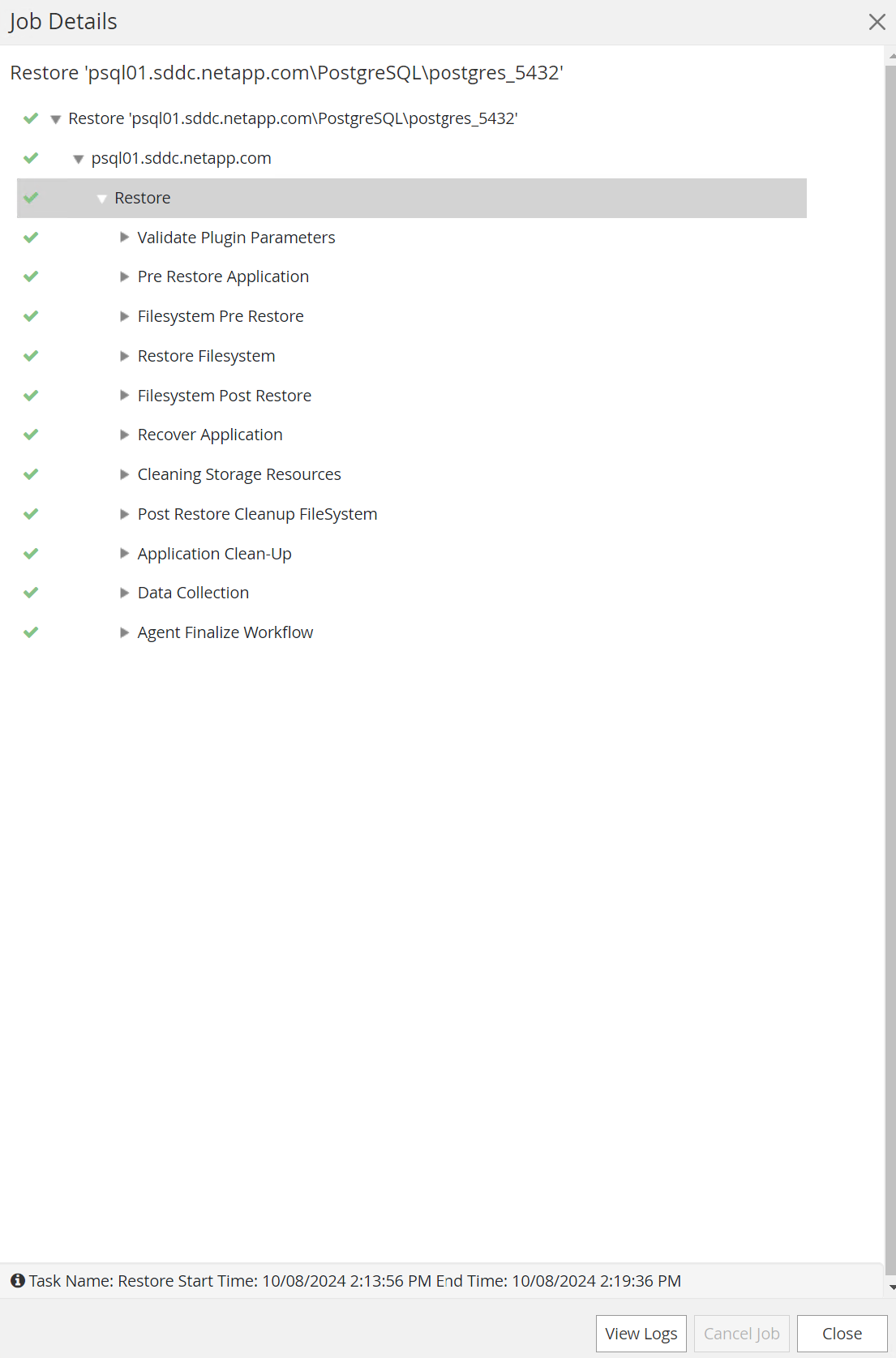
-
Connectez-vous à PostgreSQL en tant que
postgresutilisateur et valider que la table de test a été récupérée.[postgres@psql01 ~]$ psql psql (14.13) Type "help" for help. postgres=# \dt List of relations Schema | Name | Type | Owner --------+------+-------+---------- public | test | table | postgres (1 row) postgres=# select * from test; id | dt | event ----+----------------------------+-------------------------------------------------------- 1 | 2024-10-08 17:55:41.657728 | test PostgreSQL point in time recovery with SnapCenter (1 row) postgres=# select now(); now ------------------------------- 2024-10-08 18:22:33.767208+00 (1 row)
Clonage de base de données
Details
Le clonage d'un cluster de bases de données PostgreSQL via SnapCenter crée un nouveau volume cloné léger à partir d'une sauvegarde instantanée d'un volume de données de base de données source. Plus important encore, c'est rapide (quelques minutes) et efficace par rapport à d'autres méthodes pour créer une copie clonée de la base de données de production pour prendre en charge le développement ou les tests. Ainsi, il réduit considérablement les coûts de stockage et améliore la gestion du cycle de vie de votre application de base de données. La section suivante illustre le flux de travail du clone de base de données PostgreSQL avec l'interface utilisateur SnapCenter .
-
Pour valider le processus de clonage. Insérez à nouveau une ligne dans la table de test. Exécutez ensuite une sauvegarde pour capturer les données de test.
postgres=# insert into test values (2, now(), 'test PostgreSQL clone to a different DB server host'); INSERT 0 1 postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row)
-
Depuis
Resourcesonglet, ouvrez la page de sauvegarde du cluster de base de données. Choisissez l’instantané de la sauvegarde de la base de données qui contient les données de test. Ensuite, cliquez surclonebouton pour lancer le workflow de clonage de base de données.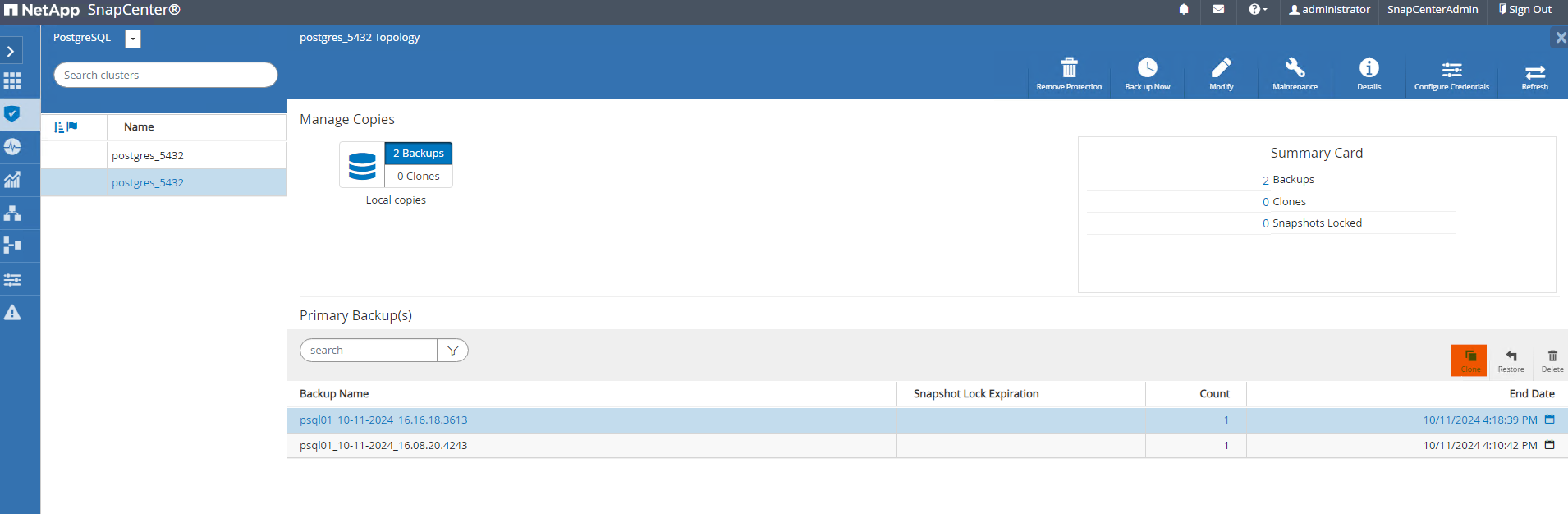
-
Sélectionnez un hôte de serveur de base de données différent du serveur de base de données source. Choisissez un port TCP 543x inutilisé sur l’hôte cible.
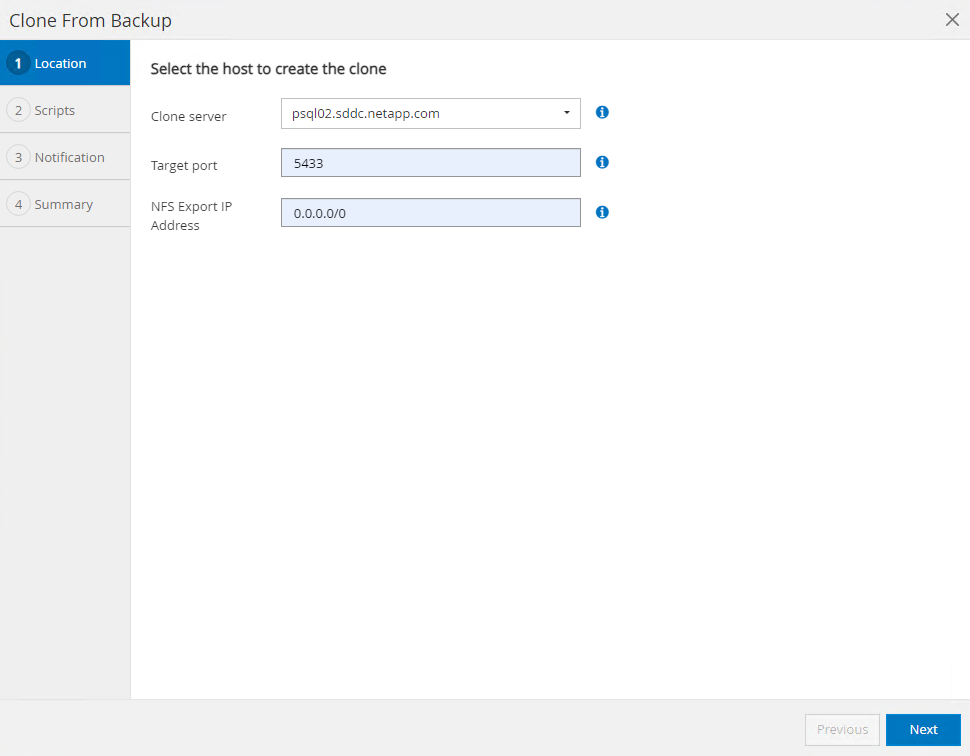
-
Saisissez tous les scripts à exécuter avant ou après l'opération de clonage.
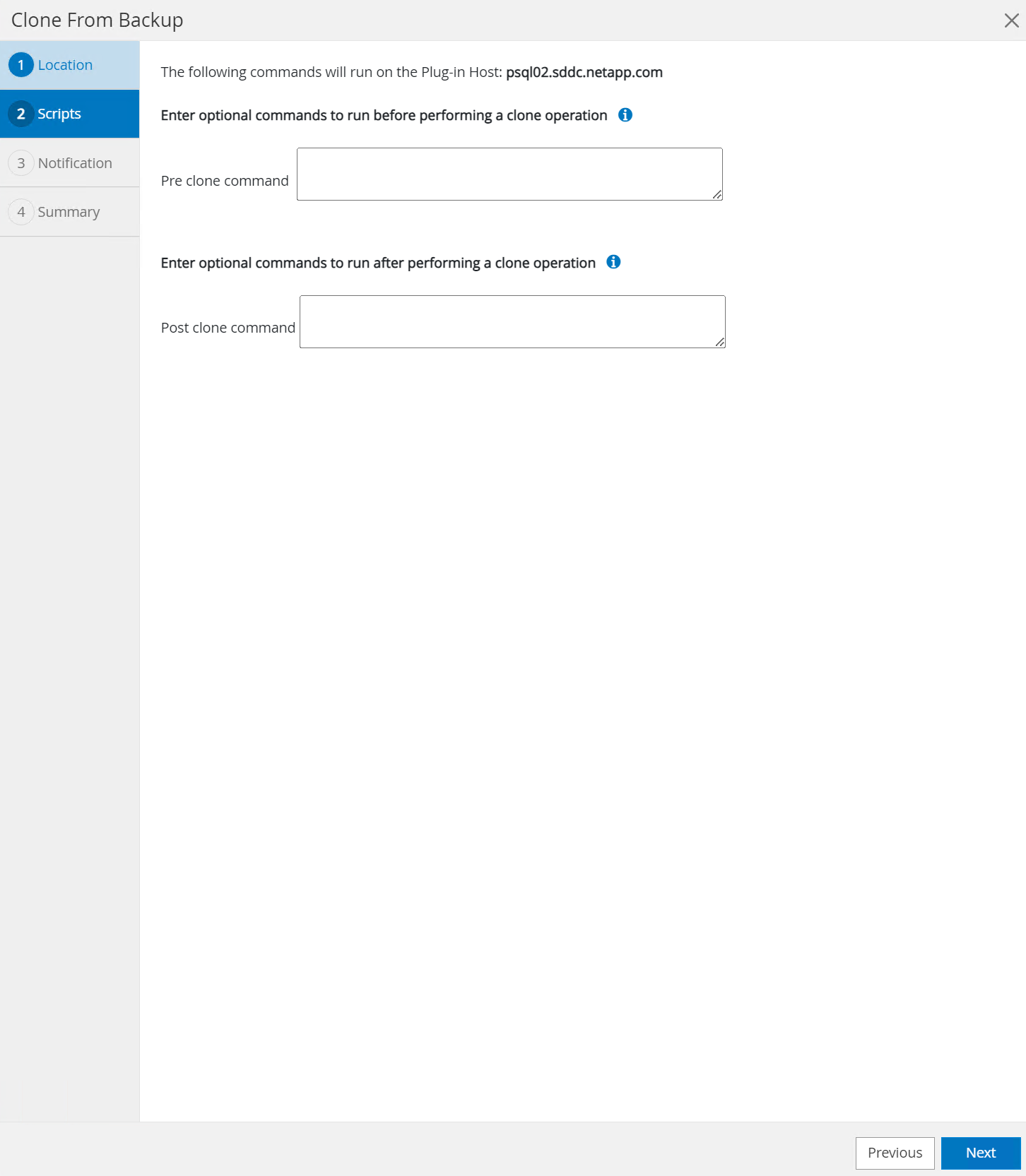
-
Notification par email si vous le souhaitez.
-
Résumé de l'examen et
Finishpour lancer le processus de clonage.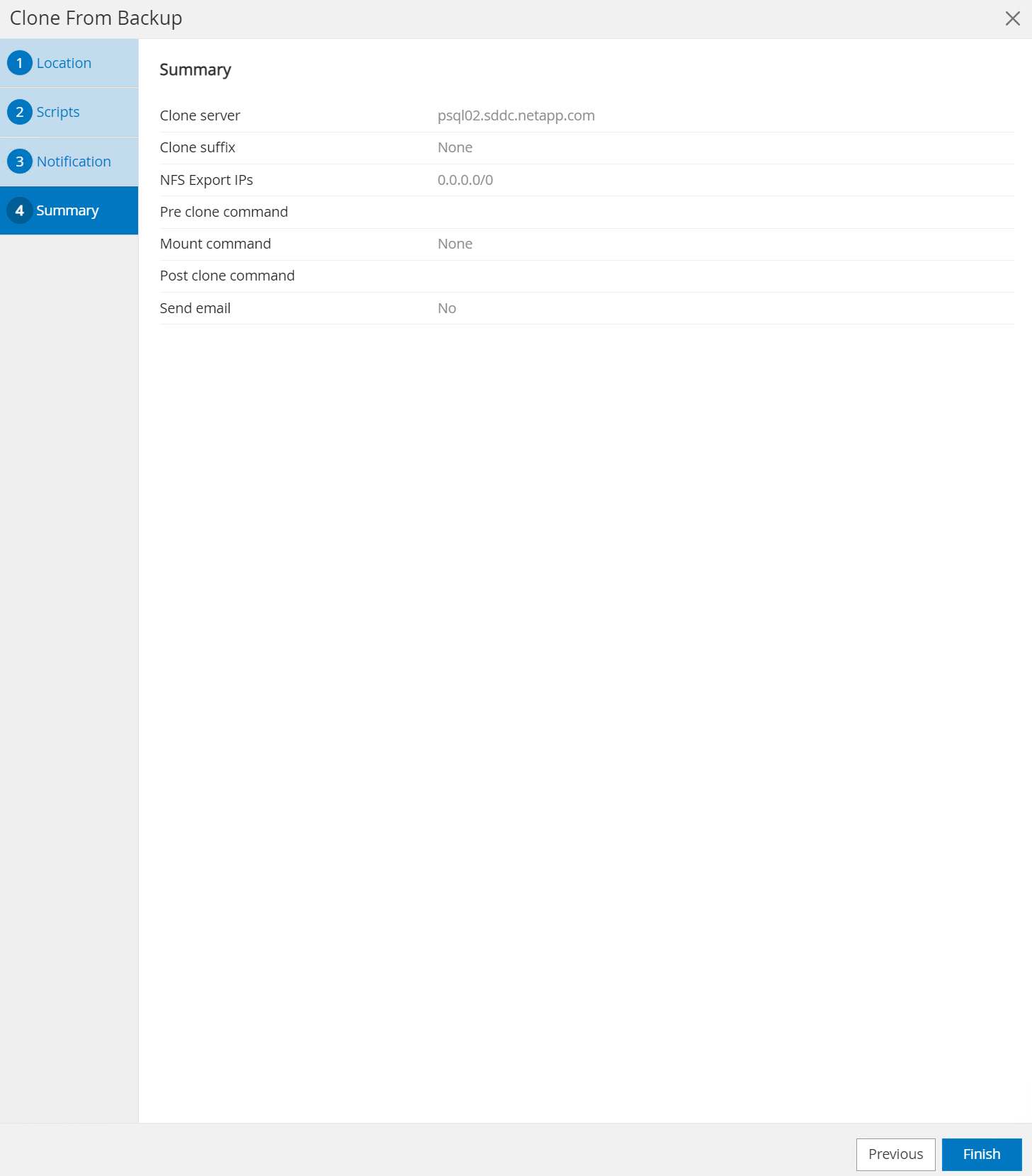
-
Cliquez sur la tâche en cours d'exécution pour l'ouvrir
Job Detailsfenêtre. Le statut du travail peut également être ouvert et visualisé à partir duMonitorlanguette.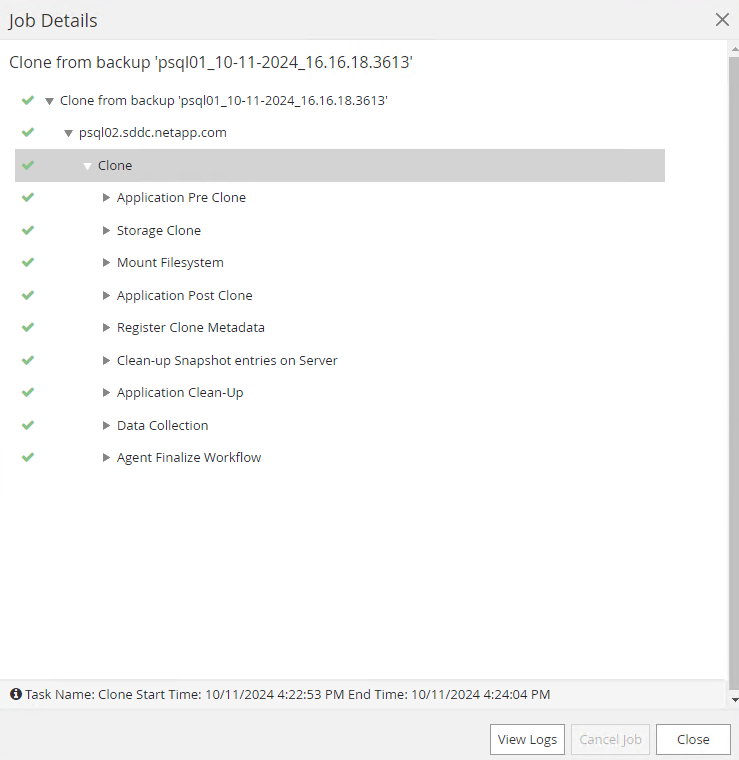
-
La base de données clonée s'enregistre immédiatement auprès de SnapCenter .
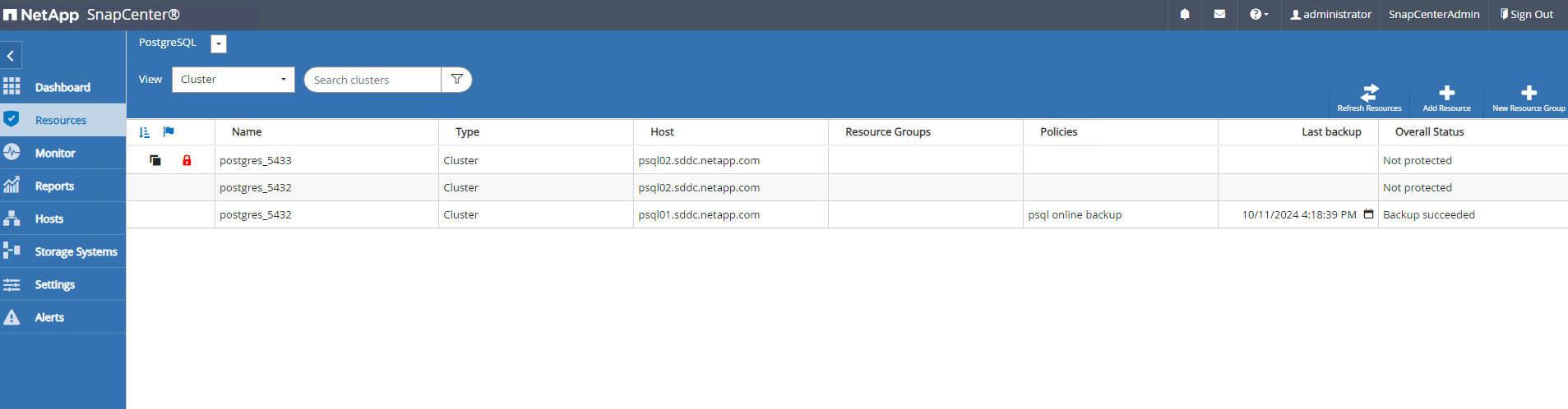
-
Valider le cluster de base de données cloné sur l'hôte du serveur de base de données cible.
[postgres@psql01 ~]$ psql -d postgres -h 10.61.186.7 -U postgres -p 5433 Password for user postgres: psql (14.13) Type "help" for help. postgres=# select * from test; id | dt | event ----+----------------------------+----------------------------------------------------- 2 | 2024-10-11 20:15:04.252868 | test PostgreSQL clone to a different DB server host (1 row) postgres=# select pg_read_file('/etc/hostname') as hostname; hostname ---------- psql02 + (1 row)
Où trouver des informations supplémentaires
Pour en savoir plus sur les informations décrites dans ce document, consultez les documents et/ou sites Web suivants :
-
Documentation du logiciel SnapCenter
-
TR-4956 : Déploiement automatisé de haute disponibilité PostgreSQL et reprise après sinistre dans AWS FSx/EC2