

Traçabilité Dataset-to-model avec NetApp et MLflow
 Suggérer des modifications
Suggérer des modifications
L' "Kit NetApp DataOps pour Kubernetes" peut être utilisé conjointement avec les fonctionnalités de suivi d'expérience de MLflow afin d'implémenter la traçabilité code-à-dataset, jeu-à-modèle ou espace-à-modèle.
Les bibliothèques suivantes ont été utilisées dans l'exemple de bloc-notes :
Conditions préalables
Pour implémenter la traçabilité entre modèles de jeux de données ou espace de travail et modèle, créez simplement un instantané du volume de votre dataset ou de votre espace de travail à l'aide de DataOps Toolkit dans le cadre de votre entraînement, comme illustré ci-dessous. Ce code enregistre le nom du volume de données et le nom de l'instantané en tant que balises associées à l'exécution d'entraînement spécifique que vous êtes en train de connecter à votre serveur de suivi d'expérience MLflow.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")L'extrait de code ci-dessus consigne les ID de snapshot sur le serveur de suivi de l'expérience MLflow, qui peut être utilisé pour effectuer un suivi vers le dataset et le modèle spécifiques utilisés pour entraîner le modèle. Cela vous permettra de retracer le jeu de données et le modèle spécifiques qui ont été utilisés pour entraîner le modèle, ainsi que le code spécifique qui a été utilisé pour prétraiter les données, Tokenize le fichier d'entrée, charger le Tokenizer "NLTK"et le modèle, coder, générer et décoder le texte, enregistrer le modèle, finetunder le modèle, évaluer le modèle à l'aide des scores de perplexité et consigner les paramètres d'hyperflux MLFlow. Par exemple, la figure suivante montre l'erreur moyenne au carré (MSE) d'un modèle scikit-Learn pour différentes séquences d'expérience :

L'analyse des données, les responsables de secteur d'activité et les cadres dirigeants peuvent comprendre et déduire quel modèle est le plus performant dans vos contraintes, paramètres, délais et autres circonstances spécifiques. Pour plus de détails sur la manière de prétraiter, de définir des tokens, de charger, de coder, de générer, de décoder, d'enregistrer, de finetune et d'évaluer le modèle, reportez-vous à l' dotk-mlflow`exemple Python fourni dans `netapp_dataops.k8s le référentiel.
Pour plus d'informations sur la création de snapshots de votre dataset ou de votre espace de travail JupyterLab, reportez-vous au "Page du kit NetApp DataOps".
En ce qui concerne les modèles qui ont été entraînés, les modèles suivants ont été utilisés dans l'ordinateur portable dotk-mlflow :
Modèles
-
"GPT2LMHeadModel": Le transformateur modèle GPT2 avec une tête de modélisation de langage sur le dessus (couche linéaire avec poids liés aux embeddings d'entrée). Il s'agit d'un modèle de transformateur qui a été pré-entraîné sur un grand corpus de données texte et finetuned sur un dataset spécifique. Nous avons utilisé le modèle GPT2 par défaut "masque d'attention"pour créer un lot de séquences d'entrée avec le tokenizer correspondant au modèle de votre choix.
-
"Phi-2": Phi-2 est un transformateur avec 2.7 milliards de paramètres. Il a été entraîné à l'aide des mêmes sources de données que Phi-1.5, et a été complété par une nouvelle source de données composée de divers textes synthétiques NLP et de sites Web filtrés (pour la sécurité et la valeur éducative).
-
"XLNet (modèle de taille moyenne)": Modèle XLNet pré-formé en anglais. Il a été introduit dans le document "XLNet: Préformation généralisée à la dégressivité pour la compréhension du langage" par Yang et al. Et publié pour "référentiel"la première fois dans ce .
Le résultat "Registre de modèles dans MLflow"contiendra les modèles, versions et balises de forêt aléatoires suivants :
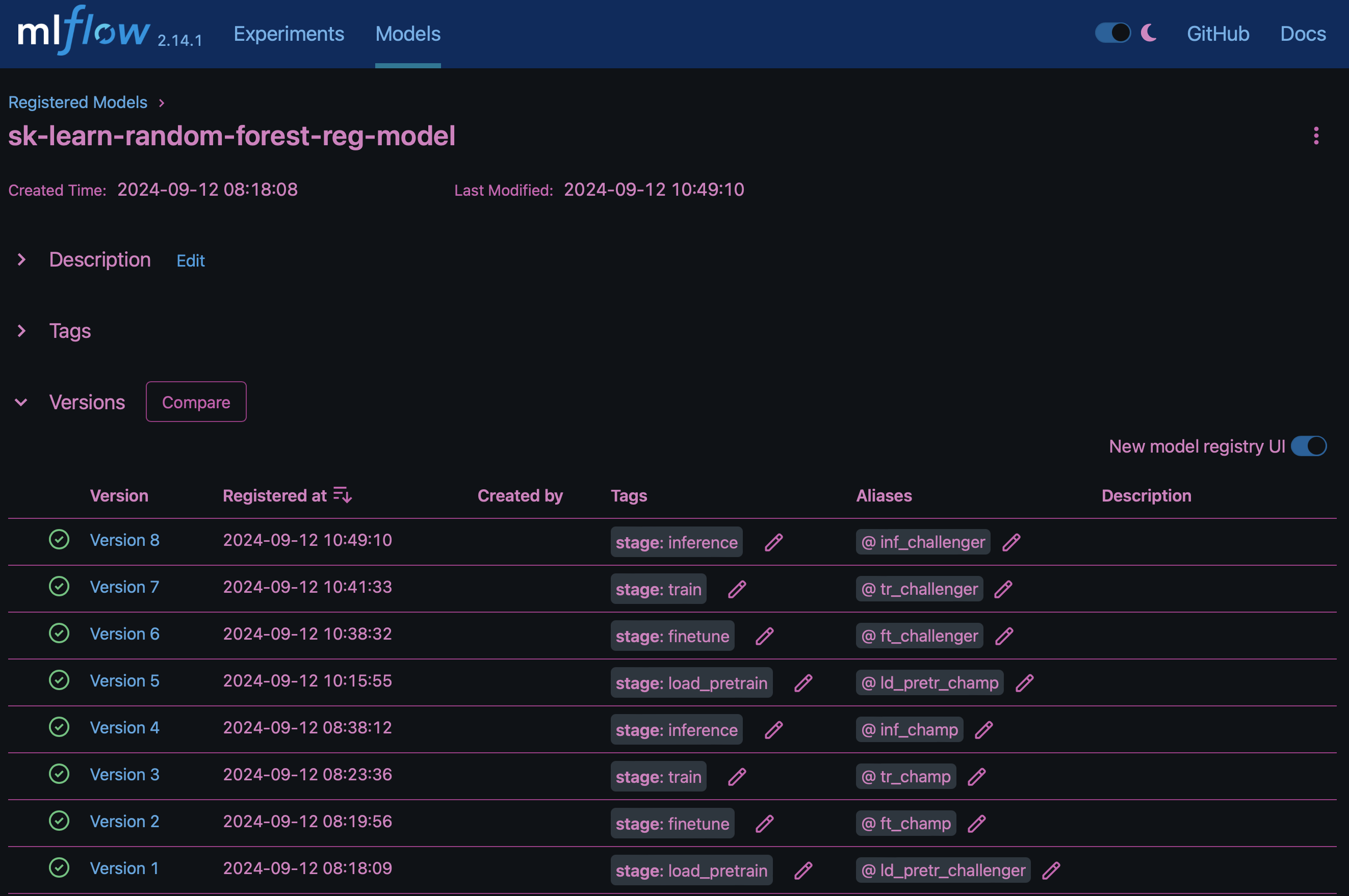
Pour déployer le modèle sur un serveur d'inférence via Kubernetes, il vous suffit d'exécuter l'ordinateur portable Jupyter suivant. Notez que dans cet exemple dotk-mlflow, au lieu d'utiliser le package, nous modifions l'architecture aléatoire du modèle de régression forestière afin de minimiser l'erreur moyenne au carré (MSE) dans le modèle initial, et donc de créer plusieurs versions de ce modèle dans notre registre de modèles.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Le résultat de l'exécution de votre cellule Jupyter Notebook doit être similaire à ce qui suit, le modèle étant enregistré comme version 3 dans le Model Registry :
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
Dans le Registre des modèles, après avoir enregistré les modèles, versions et balises de votre choix, il est possible de retracer vers le jeu de données, le modèle et le code spécifiques utilisés pour entraîner le modèle, ainsi que le code spécifique utilisé pour traiter les données, charger le tokenizer et le modèle, encoder, générer et décoder le texte, enregistrer le modèle, définir le modèle, utiliser les snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun onglets de fichier déroulant et évaluer les autres paramètres JupperyHub.
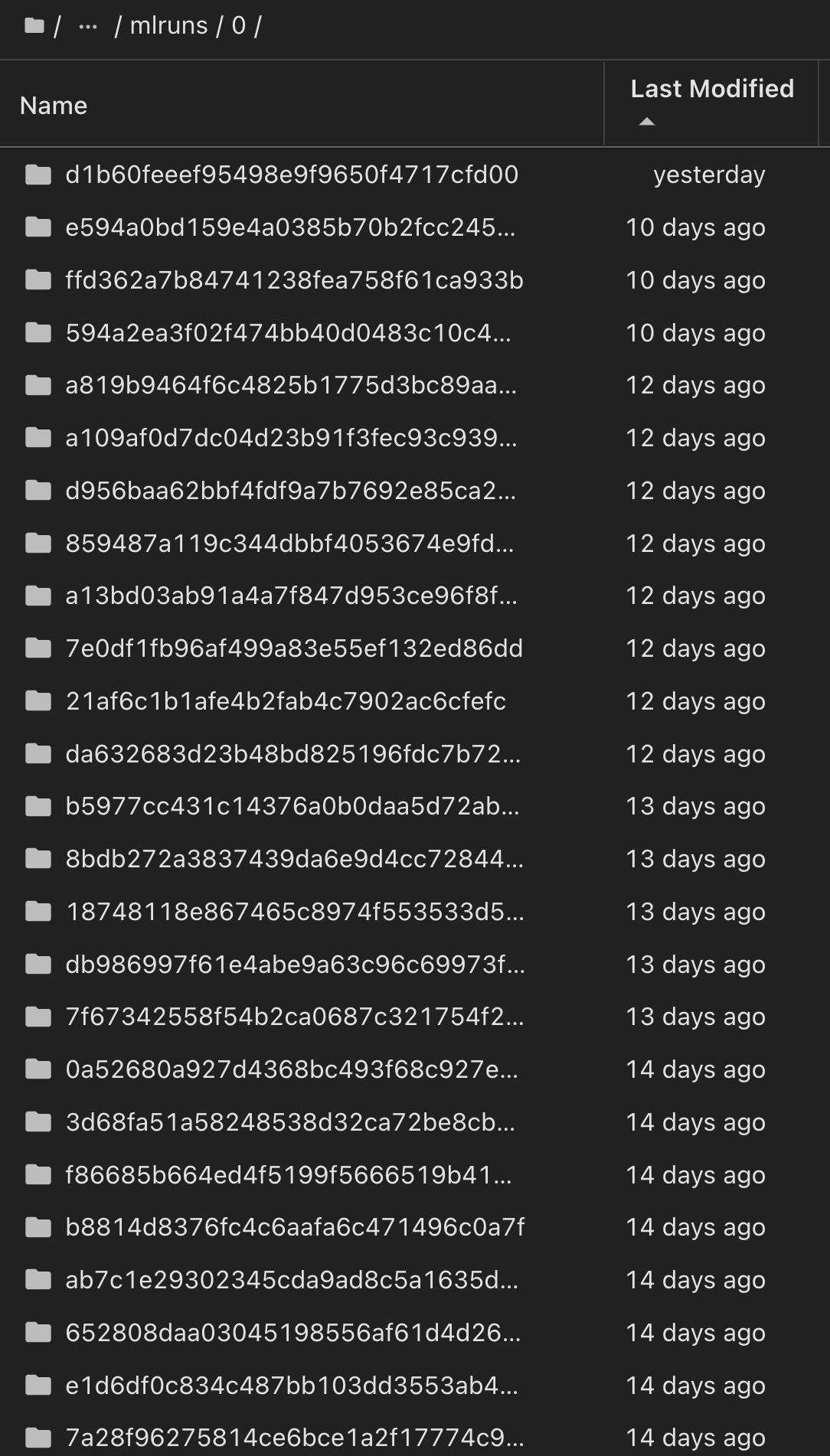
De même, pour nos phi-2_finetuned_model dont les pondérations quantifiées ont été calculées via GPU ou vGPU à l'aide de la torch bibliothèque, nous pouvons inspecter les artefacts intermédiaires suivants, ce qui permettrait l'optimisation des performances, l'évolutivité (débit/SLA gurantee) et la réduction des coûts de l'ensemble du flux de travail :
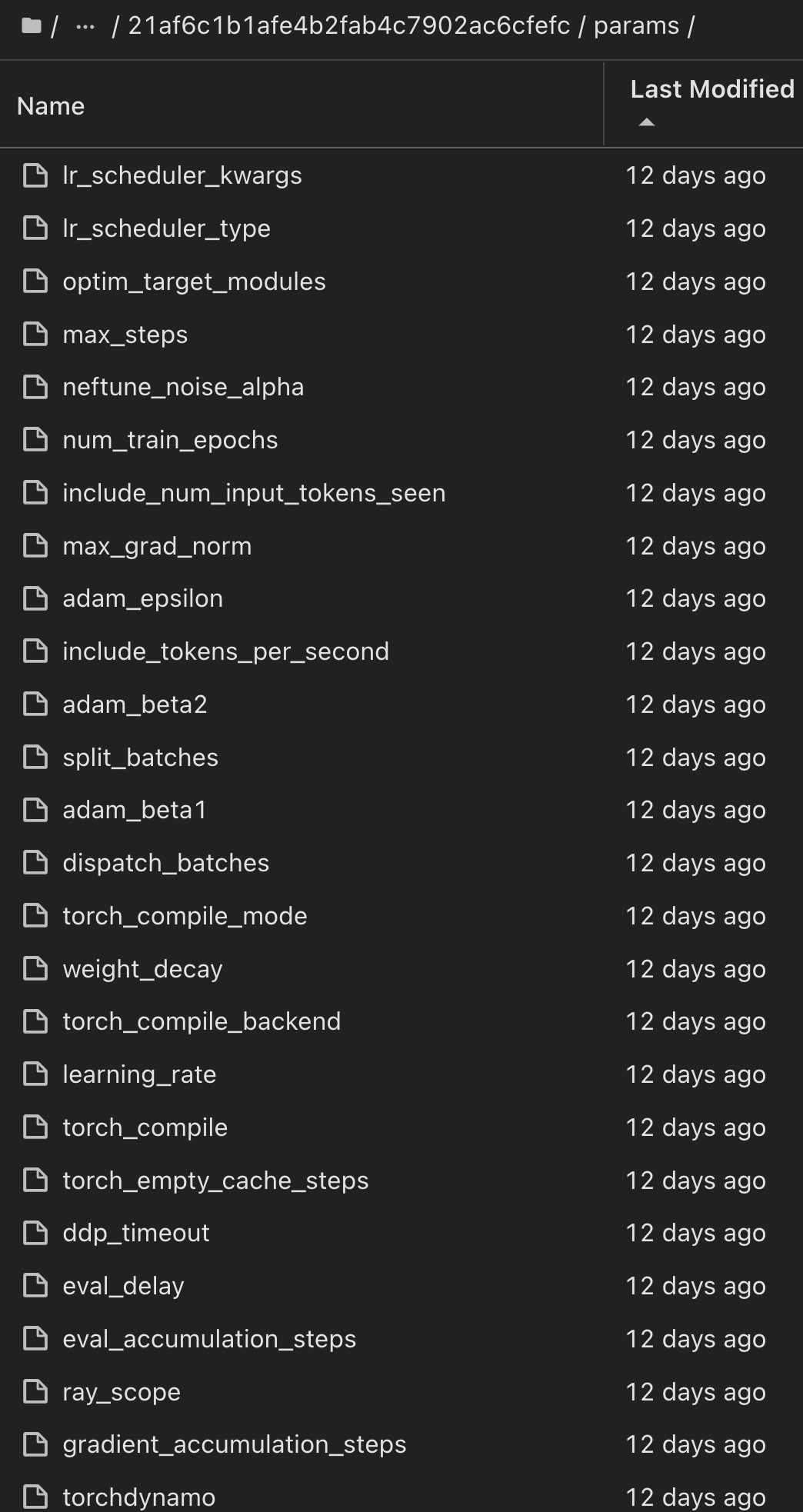
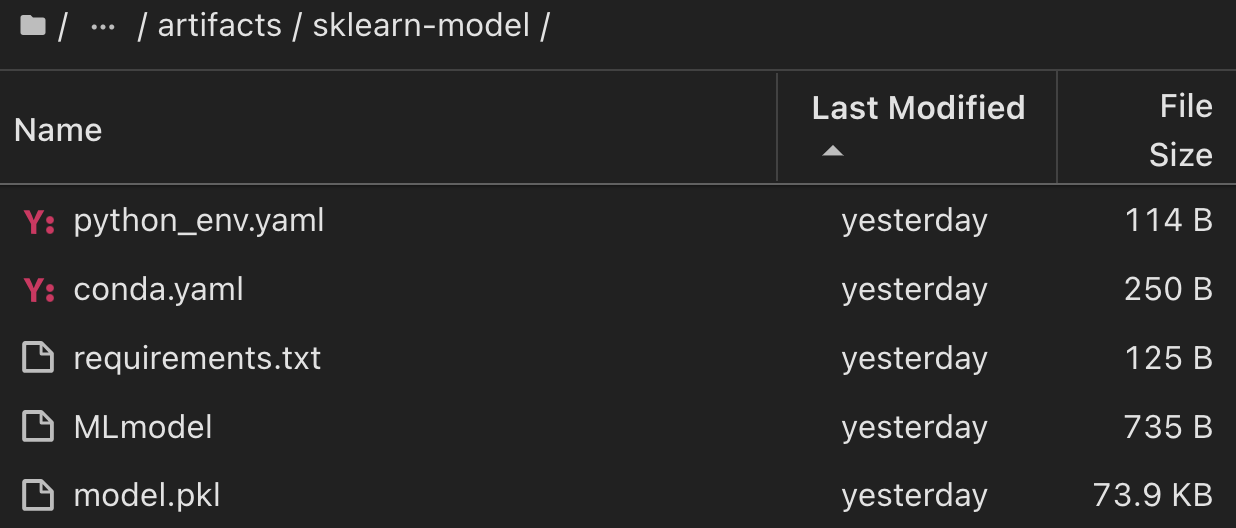
Pour une seule expérience exécutée à l'aide de Scikit-Learn et de MLflow, la figure suivante affiche les artefacts générés, conda l'environnement, MLmodel le fichier et le MLmodel répertoire :
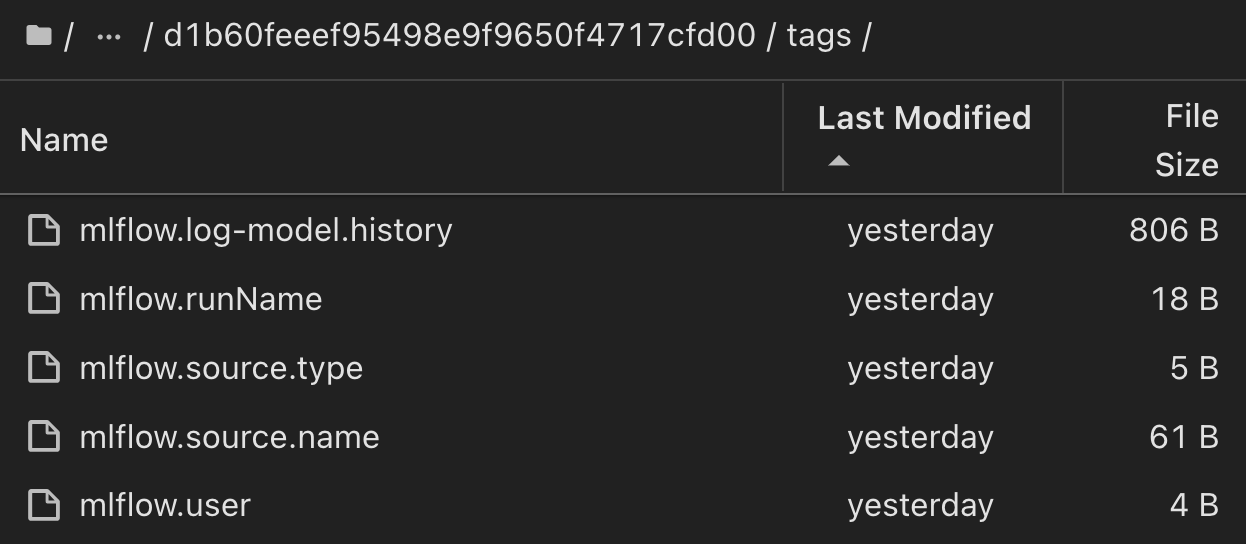
Les clients peuvent spécifier des balises, par exemple, « par défaut », « étape », « processus », « goulot d'étranglement » pour organiser les différentes charteristics de leurs workflows d'IA, noter les derniers résultats ou définir contributors un suivi des progrès des développeurs de l'équipe de data science. Si pour la balise par défaut " ", votre mlflow.log-model.history , mlflow.runName, mlflow.source.type, , mlflow.source.name et mlflow.user sous l'onglet navigateur de fichiers actuellement actif JupyterHub :
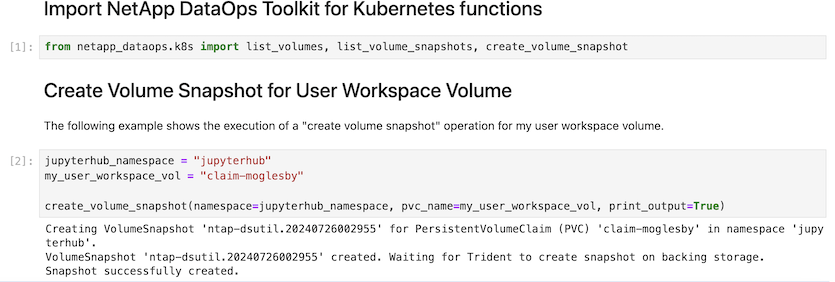
Enfin, les utilisateurs disposent de leur propre Jupyter Workspace, qui est versionné et stocké dans une demande de volume persistant dans le cluster Kubernetes. La figure suivante affiche l'espace de travail Jupyter, qui contient le netapp_dataops.k8s paquet Python, et les résultats d'un créé avec succès VolumeSnapshot :
Notre technologie éprouvée Snapshot® et d'autres technologies ont été utilisées pour assurer la protection, le déplacement et la compression efficaces des données au niveau de l'entreprise. Pour connaître les autres champs d'application de l'IA, reportez-vous à "Pod NetApp AIPod"la documentation.