

Présentation
 Suggérer des modifications
Suggérer des modifications
Pour comprendre l'impact du Tiering FabricPool sur Oracle et d'autres bases de données, il est nécessaire de connaître l'architecture FabricPool de bas niveau.
Architecture
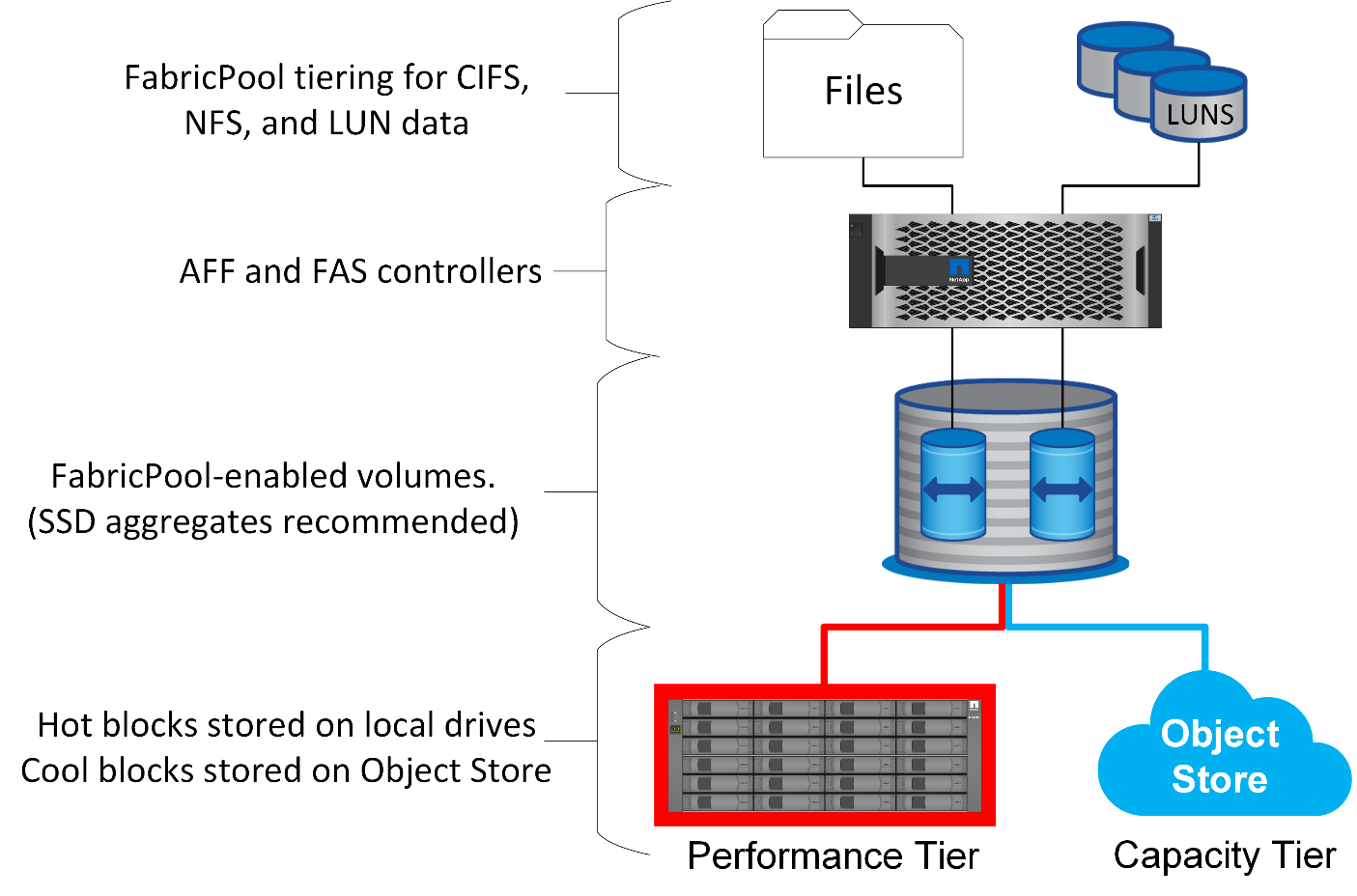
FabricPool est une technologie de hiérarchisation qui classe les blocs « actifs » ou « froids » et les place dans le Tier de stockage le plus approprié. Le Tier de performance se trouve le plus souvent sur un stockage SSD et héberge les blocs de données fortement sollicités. Le Tier de capacité se trouve dans un magasin d'objets et héberge les blocs de données utiles. Elle prend en charge le stockage objet, notamment NetApp StorageGRID, ONTAP S3, Microsoft Azure Blob Storage, le service de stockage objet Alibaba Cloud, IBM Cloud Object Storage, Google Cloud Storage et Amazon AWS S3.
Plusieurs règles de Tiering sont disponibles pour contrôler la façon dont les blocs sont classés comme actifs ou froids. Il est également possible de définir des règles par volume et de les modifier selon les besoins. Seuls les blocs de données sont déplacés entre les tiers de performance et de capacité. Les métadonnées qui définissent la structure des LUN et du système de fichiers restent toujours sur le Tier de performance. La gestion est ainsi centralisée sous ONTAP. Les fichiers et les LUN n'apparaissent pas différents des données stockées dans une autre configuration ONTAP. Le contrôleur NetApp AFF ou FAS applique les règles définies pour déplacer les données vers le Tier approprié.
Fournisseurs de magasins d'objets
Les protocoles de stockage objet utilisent de simples requêtes HTTP ou HTTPS pour stocker un grand nombre d'objets de données. L'accès au stockage objet doit être fiable, car l'accès aux données depuis ONTAP dépend du traitement rapide des demandes. Notamment Amazon S3 Standard et Infrequent Access, Microsoft Azure Hot Blob Storage, IBM Cloud et Google Cloud. Les options d'archivage telles qu'Amazon Glacier et Amazon Archive ne sont pas prises en charge, car le temps nécessaire à la récupération des données peut dépasser les tolérances des systèmes d'exploitation et des applications hôtes.
NetApp StorageGRID est également pris en charge et constitue une solution optimale. C'est un système de stockage objet haute performance, évolutif et hautement sécurisé qui assure une redondance géographique pour les données FabricPool ainsi que pour les autres applications de magasin d'objets qui font de plus en plus partie des environnements applicatifs d'entreprise.
StorageGRID peut également réduire les coûts en évitant les frais de sortie imposés par de nombreux fournisseurs de cloud public pour la lecture des données de leurs services.
Données et métadonnées
Notez que le terme « données » s'applique ici aux blocs de données réels, et non aux métadonnées. Seuls les blocs de données sont hiérarchisés, tandis que les métadonnées restent dans le Tier de performance. En outre, l'état d'un bloc en tant que bloc chaud ou froid n'est affecté que par la lecture du bloc de données réel. La simple lecture du nom, de l'horodatage ou des métadonnées de propriété d'un fichier n'affecte pas l'emplacement des blocs de données sous-jacents.
Sauvegardes
Même si FabricPool permet de réduire considérablement l'encombrement du stockage, il ne s'agit pas à lui seul d'une solution de sauvegarde. Les métadonnées NetApp WAFL restent toujours sur le Tier de performance. Si un incident catastrophique détruit le Tier de performance, il est impossible de créer un nouvel environnement à l'aide des données du Tier de capacité, car il ne contient pas de métadonnées WAFL.
FabricPool peut cependant faire partie d'une stratégie de sauvegarde. Par exemple, FabricPool peut être configuré avec la technologie de réplication NetApp SnapMirror. Chaque moitié du miroir peut avoir sa propre connexion à une cible de stockage objet. Vous obtenez ainsi deux copies indépendantes des données. La copie principale se compose des blocs du niveau de performance et des blocs associés du niveau de capacité, tandis que la réplique constitue un second ensemble de blocs de performance et de capacité.