

Remplacez la batterie NVMEM - AFF A300
 Suggérer des modifications
Suggérer des modifications
Pour remplacer une batterie NVMEM du système, vous devez retirer le module de contrôleur du système, l'ouvrir, remplacer la batterie, puis fermer et remplacer le module de contrôleur.
Tous les autres composants du système doivent fonctionner correctement ; si ce n'est pas le cas, vous devez contacter le support technique.
Étape 1 : arrêtez le contrôleur défaillant
Vous pouvez arrêter ou reprendre le contrôleur défaillant en suivant différentes procédures, en fonction de la configuration matérielle du système de stockage.
Prenez le contrôle et arrêtez le contrôleur défaillant afin que le contrôleur fonctionnel continue de fournir les données provenant du stockage du contrôleur défaillant. Pour ce faire, vous supprimez la création automatique de cas dans AutoSupport, désactivez la restitution automatique et amenez le contrôleur défaillant à l'invite LOADER. L'invite LOADER correspond à l'état d'arrêt sécurisé à partir duquel vous pouvez remplacer la FRU.
-
Si vous disposez d'un système SAN, vous devez avoir vérifié les messages d'événement
cluster kernel-service show) pour le serveur lame SCSI du contrôleur défectueux. `cluster kernel-service show`La commande (from priv mode Advanced) affiche le nom du nœud, son état de disponibilité et "état du quorum"son état de fonctionnement.Chaque processus SCSI-Blade doit se trouver au quorum avec les autres nœuds du cluster. Tout problème doit être résolu avant de procéder au remplacement.
-
Si vous avez un cluster avec plus de deux nœuds, il doit être dans le quorum. Si le cluster n'est pas au quorum ou si un contrôleur en bonne santé affiche la valeur false pour l'éligibilité et la santé, vous devez corriger le problème avant de désactiver le contrôleur défaillant ; voir "Synchroniser un nœud avec le cluster".
-
Si AutoSupport est activé, supprimez la création automatique de dossier en invoquant un message AutoSupport :
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hCela empêche l'ouverture automatique de tickets d'assistance pendant votre fenêtre de maintenance planifiée. La durée maximale de suspension est de 72 heures. Si votre maintenance se termine plus tôt, vous pouvez réactiver la création de tickets en envoyant un AutoSupport message avec
MAINT=END. Pour plus d'informations, consultez "Comment désactiver la création automatique de tickets pendant les fenêtres de maintenance planifiées".Le message AutoSupport suivant supprime la création automatique de dossiers pendant deux heures :
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Désactiver le retour automatique :
-
Entrez la commande suivante depuis la console du contrôleur sain :
storage failover modify -node impaired_node_name -auto-giveback false -
Entrer
ylorsque vous voyez l'invite Voulez-vous désactiver le retour automatique ?
-
-
Faites passer le contrôleur douteux à l'invite DU CHARGEUR :
Si le contrôleur en état de fonctionnement s'affiche… Alors… Invite DU CHARGEUR
Passez à l'étape suivante.
Attente du retour…
Appuyez sur Ctrl-C, puis répondez
ylorsque vous y êtes invité.Invite système ou invite de mot de passe
Prendre le contrôle défectueux ou l'arrêter à partir du contrôleur en bon état :
storage failover takeover -ofnode impaired_node_name -halt trueLe paramètre -halt true vous amène à l'invite Loader.
Pour arrêter le contrôleur défaillant, vous devez déterminer l'état du contrôleur et, si nécessaire, basculer le contrôleur de sorte que ce dernier continue de transmettre des données depuis le stockage défaillant du contrôleur.
-
Vous devez laisser les alimentations allumées à l'issue de cette procédure pour fournir une alimentation au contrôleur en état.
-
Vérifiez l'état du contrôleur MetroCluster pour déterminer si le contrôleur défectueux a automatiquement basculé sur le contrôleur en bon état :
metrocluster show -
Selon qu'un basculement automatique s'est produit, suivre le tableau suivant :
En cas de dysfonctionnement du contrôleur… Alors… A automatiquement basculé
Passez à l'étape suivante.
N'a pas été automatiquement commutée
Effectuer un basculement planifié à partir du contrôleur en bon état :
metrocluster switchoverN'a pas été automatiquement commutée, vous avez tenté de basculer avec le
metrocluster switchoverla commande, et le basculement a été vetotéExaminez les messages de veto et, si possible, résolvez le problème et réessayez. Si vous ne parvenez pas à résoudre le problème, contactez le support technique.
-
Resynchroniser les agrégats de données en exécutant le
metrocluster heal -phase aggregatescommande provenant du cluster survivant.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Si la guérison est vetotée, vous avez la possibilité de réémettre le
metrocluster healcommande avec-override-vetoesparamètre. Si vous utilisez ce paramètre facultatif, le système remplace tout veto logiciel qui empêche l'opération de correction. -
Vérifiez que l'opération a été terminée à l'aide de la commande MetroCluster Operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Vérifier l'état des agrégats à l'aide de
storage aggregate showcommande.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Réparez les agrégats racine à l'aide de
metrocluster heal -phase root-aggregatescommande.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Si la guérison est vetotée, vous avez la possibilité de réémettre le
metrocluster healcommande avec le paramètre -override-vetos. Si vous utilisez ce paramètre facultatif, le système remplace tout veto logiciel qui empêche l'opération de correction. -
Vérifier que l'opération de correction est terminée en utilisant le
metrocluster operation showcommande sur le cluster destination :mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Sur le module de contrôleur défaillant, débranchez les blocs d'alimentation.
Étape 2 : ouvrir le module de contrôleur
Pour accéder aux composants à l'intérieur du contrôleur, vous devez d'abord retirer le module de contrôleur du système, puis retirer le capot du module de contrôleur.
-
Si vous n'êtes pas déjà mis à la terre, mettez-vous à la terre correctement.
-
Desserrez le crochet et la bride de boucle qui relient les câbles au périphérique de gestion des câbles, puis débranchez les câbles système et les SFP (si nécessaire) du module de contrôleur, en maintenant une trace de l'emplacement où les câbles ont été connectés.
Laissez les câbles dans le périphérique de gestion des câbles de sorte que lorsque vous réinstallez le périphérique de gestion des câbles, les câbles sont organisés.
-
Retirez et mettez de côté les dispositifs de gestion des câbles des côtés gauche et droit du module de contrôleur.
![Retrait des bras de gestion des câbles][](../media/drw_32xx_cbl_mgmt_arm.png)
-
Desserrez la vis moletée sur la poignée de came du module de contrôleur.
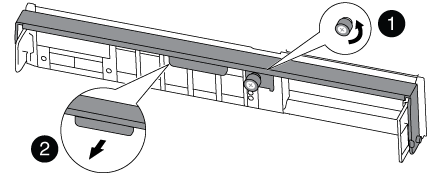

Vis moletée

Poignée de came
-
Tirez la poignée de came vers le bas et commencez à faire glisser le module de contrôleur hors du châssis.
Assurez-vous de prendre en charge la partie inférieure du module de contrôleur lorsque vous le faites glisser hors du châssis.
Étape 3 : remplacer la batterie NVMEM
Pour remplacer la batterie NVMEM de votre système, vous devez retirer la batterie NVMEM défectueuse du système, puis la remplacer par une nouvelle batterie NVMEM.
-
Si vous n'êtes pas déjà mis à la terre, mettez-vous à la terre correctement.
-
Vérifiez le voyant NVMEM :
-
Si votre système est dans une configuration haute disponibilité, passez à l'étape suivante.
-
Si votre système est dans une configuration autonome, arrêtez correctement le module de contrôleur, puis vérifiez le voyant NVRAM identifié par l'icône NV.


Le voyant NVRAM clignote lors de l'installation du contenu dans la mémoire flash lorsque vous arrêtez le système. Une fois le transfert terminé, le voyant s'éteint. -
Si l'alimentation est perdue sans arrêt correct, la LED NVMEM clignote jusqu'à ce que le transfert soit terminé, puis la LED s'éteint.
-
Si le voyant est allumé et que l'alimentation est allumée, les données non écrites sont stockées sur NVMEM.
Cela se produit généralement lors d'un arrêt non contrôlé après le démarrage du système ONTAP.
-
-
-
Ouvrez le conduit d'air de la CPU et localisez la batterie NVMEM.
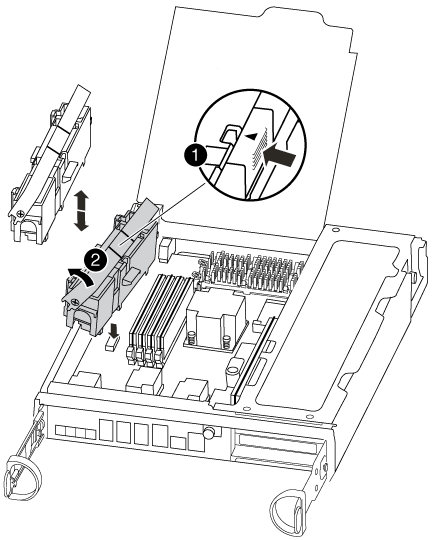
Languette de verrouillage de la batterie
Batterie NVMEM
-
Saisissez la batterie et appuyez sur la languette de verrouillage bleue indiquant « POUSSER », puis soulevez la batterie pour la sortir du support et du module de contrôleur.
-
Retirez la batterie de rechange de son emballage.
-
Alignez la languette ou les languettes du support de batterie avec les encoches du côté du module de contrôleur, puis appuyez doucement sur le boîtier de la batterie jusqu'à ce que le boîtier de la batterie s'enclenche.
-
Fermez le conduit d'air de l'UC.
Assurez-vous que la fiche mâle se verrouille sur la prise.
Étape 4 : réinstallez le contrôleur
Après avoir remplacé un composant dans le module de contrôleur, vous devez réinstaller le module de contrôleur dans le châssis du système et le démarrer.
-
Si vous n'êtes pas déjà mis à la terre, mettez-vous à la terre correctement.
-
Alignez l'extrémité du module de contrôleur avec l'ouverture du châssis, puis poussez doucement le module de contrôleur à mi-course dans le système.
N'insérez pas complètement le module de contrôleur dans le châssis tant qu'il n'y a pas été demandé. -
Recâblage du système, selon les besoins.
Si vous avez retiré les convertisseurs de support (QSFP ou SFP), n'oubliez pas de les réinstaller si vous utilisez des câbles à fibre optique.
-
Terminez la réinstallation du module de contrôleur :
Le module de contrôleur commence à démarrer dès qu'il est complètement inséré dans le châssis.
-
Avec la poignée de came en position ouverte, poussez fermement le module de contrôleur jusqu'à ce qu'il rencontre le fond de panier et soit bien en place, puis fermez la poignée de came en position verrouillée.
Ne forcez pas trop lorsque vous faites glisser le module de contrôleur dans le châssis pour éviter d'endommager les connecteurs. -
Serrez la vis moletée sur la poignée de came à l'arrière du module de contrôleur.
-
Si ce n'est déjà fait, réinstallez le périphérique de gestion des câbles.
-
Fixez les câbles au dispositif de gestion des câbles à l'aide du crochet et de la sangle de boucle.
-
Étape 5 : (MetroCluster à deux nœuds uniquement) : basculement des agrégats
Cette tâche s'applique uniquement aux configurations MetroCluster à deux nœuds.
-
Vérifiez que tous les nœuds sont dans le
enabledétat :metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Vérifier que la resynchronisation est terminée sur tous les SVM :
metrocluster vserver show -
Vérifier que toutes les migrations LIF automatiques effectuées par les opérations de correction ont été effectuées correctement :
metrocluster check lif show -
Effectuez le rétablissement en utilisant le
metrocluster switchbackutilisez une commande à partir d'un nœud du cluster survivant. -
Vérifiez que l'opération de rétablissement est terminée :
metrocluster showL'opération de rétablissement s'exécute toujours lorsqu'un cluster est dans
waiting-for-switchbackétat :cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
Le rétablissement est terminé une fois les clusters dans
normalétat :cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Si un rétablissement prend beaucoup de temps, vous pouvez vérifier l'état des lignes de base en cours en utilisant le
metrocluster config-replication resync-status showcommande. -
Rétablir toutes les configurations SnapMirror ou SnapVault.
Étape 6 : renvoyer la pièce défaillante à NetApp
Retournez la pièce défectueuse à NetApp, tel que décrit dans les instructions RMA (retour de matériel) fournies avec le kit. Voir la "Retour de pièces et remplacements" page pour plus d'informations.