

Remonter et reformater les volumes de stockage de l'appareil (« étapes manuelles »)
 Suggérer des modifications
Suggérer des modifications
Vous devez exécuter manuellement deux scripts pour remonter les volumes de stockage conservés et reformater les volumes de stockage défaillants. Le premier script monte les volumes au format approprié en tant que volumes de stockage StorageGRID. Le deuxième script reformate tous les volumes démontés, reconstruit la base de données Cassandra si nécessaire et démarre les services.
-
Vous avez déjà remplacé le matériel de tous les volumes de stockage défectueux que vous savez avoir besoin d'être remplacé.
Exécution du
sn-remount-volumesun script peut vous aider à identifier d'autres volumes de stockage ayant échoué. -
Vous avez vérifié qu'une mise hors service du nœud de stockage n'est pas en cours ou que vous avez interrompu la procédure de mise hors service du nœud. (Dans le Gestionnaire de grille, sélectionnez MAINTENANCE tâches mise hors service.)
-
Vous avez vérifié qu'une extension n'est pas en cours. (Dans le Gestionnaire de grille, sélectionnez MAINTENANCE tâches extension.)

|
Si plus d'un nœud de stockage est hors ligne ou si un nœud de stockage de cette grille a été reconstruit au cours des 15 derniers jours, contactez le support technique. N'exécutez pas le sn-recovery-postinstall.sh script. Reconstruire Cassandra sur deux nœuds de stockage ou plus dans les 15 jours suivant l'arrêt du service peut entraîner une perte de données.
|
Pour effectuer cette procédure, vous devez effectuer les tâches de haut niveau suivantes :
-
Connectez-vous au nœud de stockage récupéré.
-
Exécutez le
sn-remount-volumesscript pour remonter les volumes de stockage correctement formatés. Lorsque ce script s'exécute, il effectue les opérations suivantes :-
Monte et démonte chaque volume de stockage pour relire le journal XFS.
-
Effectue une vérification de cohérence de fichier XFS.
-
Si le système de fichiers est cohérent, détermine si le volume de stockage est un volume de stockage StorageGRID correctement formaté.
-
Si le volume de stockage est correctement formaté, remonter le volume de stockage. Toutes les données existantes du volume restent intactes.
-
-
Examinez la sortie du script et résolvez tout problème.
-
Exécutez le
sn-recovery-postinstall.shscript. Lorsque ce script s'exécute, il effectue les opérations suivantes :
Ne redémarrez pas un nœud de stockage pendant la restauration avant de l'exécuter sn-recovery-postinstall.sh(étape 4) pour reformater les volumes de stockage défaillants et restaurer les métadonnées de l'objet. Redémarrage du nœud de stockage avantsn-recovery-postinstall.shLa solution complète provoque des erreurs sur les services qui tentent de démarrer et entraîne la sortie des nœuds d'appliance StorageGRID en mode de maintenance.-
Reformate tous les volumes de stockage du
sn-remount-volumesle script n'a pas pu être monté ou a été mal formaté.
Lorsqu'un volume de stockage est reformaté, toutes les données de ce volume sont perdues. Vous devez effectuer une procédure supplémentaire pour restaurer les données d'objet à partir d'autres emplacements de la grille, en supposant que les règles ILM ont été configurées pour stocker plusieurs copies d'objet. -
Reconstruit la base de données Cassandra sur le nœud, si nécessaire.
-
Démarre les services sur le nœud de stockage.
-
-
Connectez-vous au nœud de stockage récupéré :
-
Saisissez la commande suivante :
ssh admin@grid_node_IP -
Entrez le mot de passe indiqué dans le
Passwords.txtfichier. -
Entrez la commande suivante pour passer à la racine :
su - -
Entrez le mot de passe indiqué dans le
Passwords.txtfichier.
Lorsque vous êtes connecté en tant que root, l'invite passe de
$à#. -
-
Exécutez le premier script pour remonter tous les volumes de stockage correctement formatés.
Si tous les volumes de stockage sont nouveaux et doivent être formatés, ou si tous les volumes de stockage ont échoué, vous pouvez ignorer cette étape et exécuter le deuxième script pour reformater tous les volumes de stockage démontés. -
Exécutez le script :
sn-remount-volumesCe script peut prendre des heures sur les volumes de stockage qui contiennent des données.
-
Au fur et à mesure de l'exécution du script, vérifiez le résultat et répondez aux invites.
Si nécessaire, vous pouvez utiliser le tail -fcommande permettant de contrôler le contenu du fichier journal du script (/var/local/log/sn-remount-volumes.log) . Le fichier journal contient des informations plus détaillées que la sortie de la ligne de commande.root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Dans l'exemple de sortie, un volume de stockage a été remonté avec succès et trois volumes de stockage ont rencontré des erreurs.
-
/dev/sdbLa vérification de cohérence du système de fichiers XFS a été effectuée et une structure de volume valide a été correctement remontée. Les données sur les périphériques remontés par le script sont conservées. -
/dev/sdcEchec de la vérification de cohérence du système de fichiers XFS car le volume de stockage était nouveau ou corrompu. -
/dev/sddimpossible de monter, car le disque n'a pas été initialisé ou le superbloc du disque a été corrompu. Lorsque le script ne peut pas monter un volume de stockage, vous êtes invité à exécuter la vérification de cohérence du système de fichiers.-
Si le volume de stockage est relié à un nouveau disque, répondez N à l'invite. Vous n'avez pas besoin de vérifier le système de fichiers sur un nouveau disque.
-
Si le volume de stockage est relié à un disque existant, répondez y à l'invite. Vous pouvez utiliser les résultats de la vérification du système de fichiers pour déterminer la source de la corruption. Les résultats sont enregistrés dans le
/var/local/log/sn-remount-volumes.logfichier journal.
-
-
/dev/sdeA réussi la vérification de cohérence du système de fichiers XFS et avait une structure de volume valide ; cependant, l'ID de nœud LDR dans levolIDLe fichier ne correspond pas à l'ID de ce noeud de stockage (l'configured LDR noidaffiché en haut). Ce message indique que ce volume appartient à un autre noeud de stockage.
-
-
-
Examinez la sortie du script et résolvez tout problème.
Si un volume de stockage a échoué au contrôle de cohérence du système de fichiers XFS ou ne peut pas être monté, vérifiez attentivement les messages d'erreur dans la sortie. Vous devez comprendre les implications de l'exécution du sn-recovery-postinstall.shcréer des scripts sur ces volumes.-
Vérifiez que les résultats incluent une entrée pour tous les volumes attendus. Si des volumes ne sont pas répertoriés, relancez le script.
-
Consultez les messages de tous les périphériques montés. Assurez-vous qu'il n'y a pas d'erreur indiquant qu'un volume de stockage n'appartient pas à ce noeud de stockage.
Dans l'exemple, la sortie de /dev/sde inclut le message d'erreur suivant :
Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Si un volume de stockage est signalé comme appartenant à un autre nœud de stockage, contactez le support technique. Si vous exécutez le sn-recovery-postinstall.shscript, le volume de stockage sera reformaté, ce qui peut entraîner une perte de données. -
Si aucun périphérique de stockage n'a pu être monté, notez le nom du périphérique et réparez ou remplacez le périphérique.
Vous devez réparer ou remplacer tout périphérique de stockage qui n'a pas pu être monté. Vous utiliserez le nom de l'appareil pour rechercher l'ID de volume, qui est obligatoire lorsque vous exécutez le
repair-datascript permettant de restaurer les données d'objet sur le volume (procédure suivante). -
Après avoir réparé ou remplacé tous les dispositifs unmountable, exécutez le
sn-remount-volumesscript une nouvelle fois pour confirmer que tous les volumes de stockage pouvant être remontés ont été remontés.
Si un volume de stockage ne peut pas être monté ou est mal formaté et que vous passez à l'étape suivante, le volume et toutes les données du volume seront supprimés. Si vous aviez deux copies de vos données d'objet, vous n'aurez qu'une seule copie jusqu'à la fin de la procédure suivante (restauration des données d'objet).
N'exécutez pas le sn-recovery-postinstall.shScript si vous pensez que les données restantes d'un volume de stockage défaillant ne peuvent pas être reconstruites à partir d'un autre emplacement de la grille (par exemple, si votre stratégie ILM utilise une seule copie ou si des volumes ont échoué sur plusieurs nœuds). Contactez plutôt le support technique pour savoir comment récupérer vos données. -
-
Exécutez le
sn-recovery-postinstall.shscript :sn-recovery-postinstall.shCe script reformate tous les volumes de stockage qui n'ont pas pu être montés ou qui n'ont pas été correctement formatés. Reconstruit la base de données Cassandra sur le nœud, si nécessaire, et démarre les services sur le nœud de stockage.
Gardez à l'esprit les points suivants :
-
L'exécution du script peut prendre des heures.
-
En général, vous devez laisser la session SSH seule pendant que le script est en cours d'exécution.
-
N'appuyez pas sur Ctrl+C lorsque la session SSH est active.
-
Le script s'exécute en arrière-plan en cas d'interruption du réseau et met fin à la session SSH, mais vous pouvez afficher la progression à partir de la page récupération.
-
Si le nœud de stockage utilise le service RSM, le script peut sembler bloqué pendant 5 minutes au redémarrage des services de nœud. Ce délai de 5 minutes est prévu lorsque l'entretien du RSM démarre pour la première fois.
Le service RSM est présent sur les nœuds de stockage qui incluent le service ADC.
Certaines procédures de restauration StorageGRID utilisent Reaper pour traiter les réparations Cassandra. Les réparations sont effectuées automatiquement dès que les services connexes ou requis ont commencé. Vous remarquerez peut-être des résultats de script mentionnant « couche » ou « réparation Cassandra ». Si un message d'erreur indiquant que la réparation a échoué, exécutez la commande indiquée dans le message d'erreur. -
-
Comme le
sn-recovery-postinstall.shExécution du script, surveillez la page récupération dans le Gestionnaire de grille.La barre de progression et la colonne Etape de la page récupération fournissent un état de haut niveau du
sn-recovery-postinstall.shscript.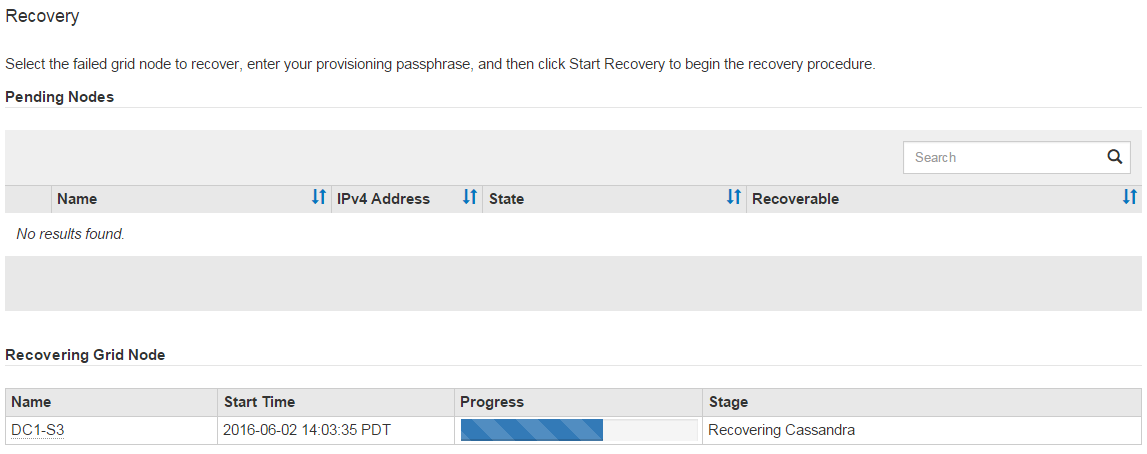
Après le sn-recovery-postinstall.sh script a démarré les services sur le nœud. vous pouvez restaurer les données d'objet sur tous les volumes de stockage formatés par le script, comme décrit dans la procédure suivante.