

Protection des données
 Suggérer des modifications
Suggérer des modifications
Découvrez les options de protection des données et de restauration fournies par les plateformes de stockage NetApp. Astra Trident peut provisionner des volumes qui peuvent bénéficier de certaines de ces fonctionnalités. Vous devez disposer d'une stratégie de protection et de restauration des données pour chaque application ayant des exigences de persistance.
Sauvegardez le etcd données de cluster
Astra Trident stocke ses métadonnées dans le cluster Kubernetes etcd base de données. Sauvegarder régulièrement le etcd Les données en cluster sont importantes pour la restauration de clusters Kubernetes en cas d'incident.
-
Le
etcdctl snapshot savevous permet de créer un snapshot instantané de l'etcdcluster :sudo docker run --rm -v /backup:/backup \ --network host \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \ --env ETCDCTL_API=3 \ registry.k8s.io/etcd-amd64:3.2.18 \ etcdctl --endpoints=https://127.0.0.1:2379 \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \ --key=/etc/kubernetes/pki/etcd/healthcheck-client.key \ snapshot save /backup/etcd-snapshot.db
Cette commande crée un snapshot ETCD en faisant tourner un conteneur ETCD et le sauvegarde dans le
/backuprépertoire. -
En cas d'incident, vous pouvez activer un cluster Kubernetes à l'aide des snapshots ETCD. Utilisez le
etcdctl snapshot restorecommande permettant de restaurer un snapshot spécifique pris sur le/var/lib/etcddossier. Après la restauration, vérifiez si/var/lib/etcdle dossier a été rempli avec lememberdossier. Voici un exemple deetcdctl snapshot restorecommande :etcdctl snapshot restore '/backup/etcd-snapshot-latest.db' ; mv /default.etcd/member/ /var/lib/etcd/
-
Avant d'initialiser le cluster Kubernetes, copiez tous les certificats nécessaires.
-
Créez le cluster avec le
--ignore-preflight-errors=DirAvailable—var-lib-etcddrapeau. -
Une fois le cluster lancé, assurez-vous que les modules du système kube ont démarré.
-
Utilisez le
kubectl get crdCommande pour vérifier si les ressources personnalisées créées par Trident sont présentes et récupérer des objets Trident afin de s'assurer que toutes les données sont disponibles.
Récupérer les données à l'aide des snapshots ONTAP
Les snapshots jouent un rôle important en proposant des options de restauration ponctuelles pour les données d'application. Toutefois, les snapshots ne sont pas des sauvegardes en elles-mêmes, elles ne protègent pas contre les défaillances du système de stockage ou autres catastrophes. Cependant, ils constituent un moyen pratique, rapide et simple de restaurer des données dans la plupart des scénarios. Découvrez comment utiliser la technologie Snapshot de ONTAP pour sauvegarder les volumes et les restaurer.
-
Si la politique de snapshot n'a pas été définie dans le backend, elle utilise par défaut le
nonepolitique. Résultat : ONTAP ne prend pas de snapshots automatiques. Toutefois, l'administrateur du stockage peut effectuer manuellement des snapshots ou modifier la règle Snapshot via l'interface de gestion ONTAP. Cela n'affecte pas le fonctionnement de Trident. -
Le répertoire de snapshot est masqué par défaut. Cela facilite une compatibilité maximale des volumes provisionnés à l'aide de
ontap-nasetontap-nas-economypilotes. Activez le.snapshotrépertoire lors de l'utilisation duontap-nasetontap-nas-economypilotes permettant aux applications de récupérer directement les données à partir des snapshots. -
Restaurer un volume à un état enregistré dans un instantané précédent à l'aide du
volume snapshot restoreCommande CLI ONTAP. Lorsque vous restaurez une copie snapshot, l'opération de restauration écrase la configuration de volume existante. Toute modification apportée aux données du volume après la création de la copie Snapshot est perdue.
cluster1::*> volume snapshot restore -vserver vs0 -volume vol3 -snapshot vol3_snap_archive
Réplication des données à l'aide de ONTAP
La réplication des données peut jouer un rôle important dans la protection contre les pertes de données dues à une défaillance de la baie de stockage.

|
Pour en savoir plus sur les technologies de réplication ONTAP, consultez le "Documentation ONTAP". |
Réplication des machines virtuelles de stockage (SVM) SnapMirror
Vous pouvez utiliser "SnapMirror" pour répliquer un SVM complet, qui inclut ses paramètres de configuration et ses volumes. En cas d'incident, vous pouvez activer la SVM de destination SnapMirror pour démarrer le service des données. Vous pouvez revenir au primaire lorsque les systèmes sont restaurés.
Astra Trident ne peut pas configurer lui-même les relations de réplication. L'administrateur du stockage peut donc utiliser la fonctionnalité de réplication du SVM SnapMirror d'ONTAP pour répliquer automatiquement les volumes vers une destination de reprise après incident.
Envisagez la commande suivante si vous prévoyez d'utiliser la fonctionnalité de réplication SVM SnapMirror ou si vous utilisez actuellement la fonctionnalité :
-
Vous devez créer un système back-end distinct pour chaque SVM, sur lequel SVM-DR est activé.
-
Vous devez configurer les classes de stockage de manière à ne pas sélectionner les systèmes back-end répliqués, sauf lorsque cela est nécessaire. Cela est important pour éviter la mise en service des volumes qui ne nécessitent pas de protection de la relation de réplication sur les back-end compatibles avec SVM-DR.
-
Les administrateurs d'applications doivent comprendre les coûts et la complexité supplémentaires liés à la réplication des données, et un plan de restauration doit être déterminé avant d'exploiter la réplication des données.
-
Avant d'activer la SVM de destination SnapMirror, arrêter tous les transferts SnapMirror planifiés, abandonner tous les transferts SnapMirror en cours, interrompre la relation de réplication, arrêter la SVM source puis démarrer la SVM de destination SnapMirror.
-
Astra Trident ne détecte pas automatiquement les défaillances du SVM. Par conséquent, en cas d'échec, l'administrateur doit exécuter le
tridentctl backend updateCommande permettant de déclencher le basculement de Trident vers le nouveau back-end.
Voici une présentation des étapes de configuration des SVM :
-
Configurer le peering entre le cluster source et destination et SVM
-
Créer le SVM de destination à l'aide de l'
-subtype dp-destinationoption. -
Créez une planification de tâches de réplication afin de vous assurer que la réplication se déroule aux intervalles requis.
-
Créer une réplication SnapMirror depuis le SVM de destination vers le SVM source à l'aide de
-identity-preserve trueOption pour s'assurer que les configurations du SVM source et les interfaces du SVM source sont copiées vers la destination. Depuis le SVM de destination, initialiser la relation de réplication SVM SnapMirror
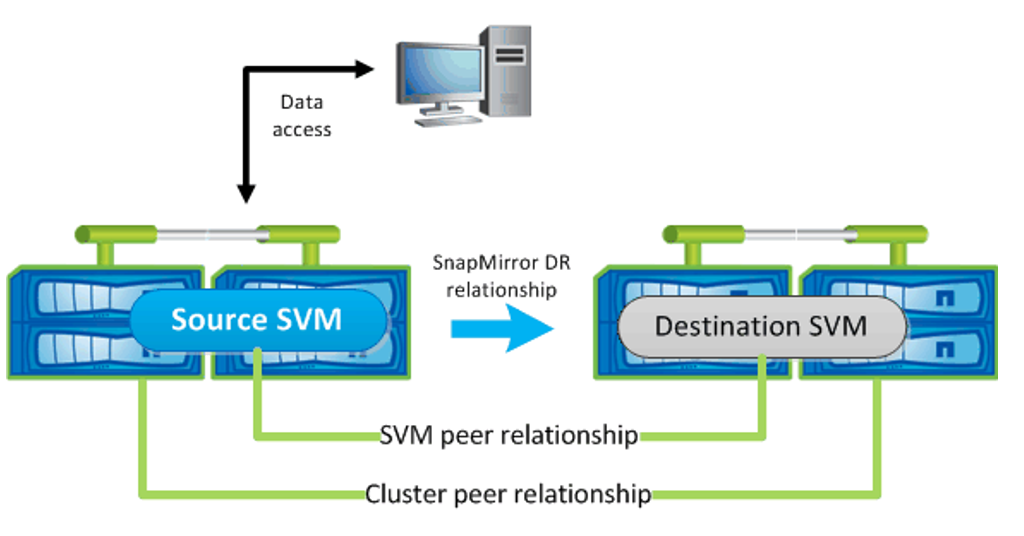
Workflow de reprise d'activité pour Trident
Astra Trident 19.07 et les versions ultérieures utilisent des CRD Kubernetes pour stocker et gérer son propre état. Elle utilise celle du cluster Kubernetes etcd pour stocker ses métadonnées. On suppose ici que Kubernetes etcd Les fichiers de données et les certificats sont stockés sur NetApp FlexVolume. Ce FlexVolume réside dans un SVM, qui dispose d'une relation SVM-DR SnapMirror avec un SVM de destination sur le site secondaire.
La procédure suivante décrit comment restaurer un cluster Kubernetes maître avec Astra Trident en cas d'incident :
-
En cas de défaillance du SVM source, activer le SVM de destination SnapMirror Pour cela, il faut arrêter des transferts SnapMirror planifiés, abandonner les transferts SnapMirror en cours, interrompre la relation de réplication, arrêter la SVM source et démarrer la SVM de destination.
-
Depuis le SVM de destination, montez le volume qui contient l'environnement Kubernetes
etcdfichiers de données et certificats sur l'hôte qui seront configurés en tant que nœud maître. -
Copiez tous les certificats requis se rapportant au cluster Kubernetes sous
/etc/kubernetes/pkiet le etcdmemberfichiers sous/var/lib/etcd. -
Créez un cluster Kubernetes en utilisant le
kubeadm initcommande avec--ignore-preflight-errors=DirAvailable—var-lib-etcddrapeau. Les noms d'hôte utilisés pour les nœuds Kubernetes doivent être identiques au cluster Kubernetes source. -
Exécutez le
kubectl get crdCommande pour vérifier si toutes les ressources personnalisées Trident ont été extraites et récupérer les objets Trident pour vérifier que toutes les données sont disponibles. -
Mise à jour de tous les systèmes back-end requis pour refléter le nouveau nom de SVM de destination en exécutant la
./tridentctl update backend <backend-name> -f <backend-json-file> -n <namespace>commande.
|
|
Lorsque le SVM de destination est activé pour les volumes persistants des applications, tous les volumes provisionnés par Trident commencent à transmettre les données. Une fois le cluster Kubernetes configuré sur le système de destination conformément aux étapes décrites ci-dessus, tous les déploiements et les pods sont démarrés et les applications conteneurisées doivent s'exécuter sans aucun problème. |
Réplication de volume SnapMirror
La réplication de volume ONTAP SnapMirror est une fonctionnalité de reprise d'activité qui permet le basculement vers le stockage de destination à partir d'un stockage primaire au niveau des volumes. SnapMirror crée une réplique de volume ou un miroir du stockage primaire sur le stockage secondaire en synchronisant les snapshots.
Voici une synthèse des étapes de configuration de la réplication de volume ONTAP SnapMirror :
-
Configurez le peering entre les clusters dans lesquels les volumes résident et les SVM qui fournissent les données des volumes.
-
Créer une règle SnapMirror, qui contrôle le comportement de la relation et spécifie les attributs de configuration pour cette relation.
-
Créez une relation SnapMirror entre le volume de destination et le volume source à l'aide de la[
snapmirror createcommande^] et attribuez la règle SnapMirror appropriée. -
Une fois la relation SnapMirror créée, initialisez la relation pour qu'un transfert de base du volume source vers le volume de destination soit terminé.
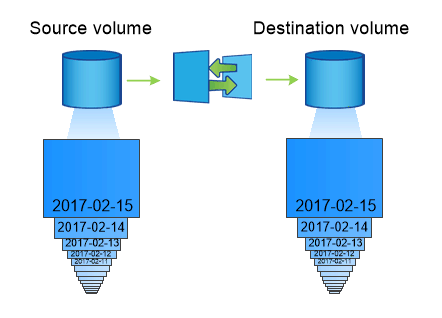
Workflow de reprise d'activité de volumes SnapMirror pour Trident
La procédure suivante décrit comment restaurer un cluster Kubernetes maître avec Astra Trident.
-
En cas d'incident, arrêter tous les transferts SnapMirror programmés et abandonner tous les transferts SnapMirror en cours. Rompez la relation de réplication entre les volumes de destination et source de sorte que le volume de destination soit lu/écrit.
-
Depuis le SVM de destination, montez le volume qui contient l'environnement Kubernetes
etcdfichiers de données et certificats sur l'hôte, qui sera configuré en tant que nœud maître. -
Copiez tous les certificats requis se rapportant au cluster Kubernetes sous
/etc/kubernetes/pkiet le etcdmemberfichiers sous/var/lib/etcd. -
Créez un cluster Kubernetes en exécutant le
kubeadm initcommande avec--ignore-preflight-errors=DirAvailable—var-lib-etcddrapeau. Les noms d'hôte doivent être identiques au cluster Kubernetes source. -
Exécutez le
kubectl get crdCommande pour vérifier si toutes les ressources personnalisées Trident ont été extraites et récupérer des objets Trident pour s'assurer que toutes les données sont disponibles. -
Nettoyez les systèmes back-end précédents et créez de nouveaux systèmes back-end sur Trident. Préciser la nouvelle LIF de management, le nouveau nom du SVM et le mot de passe du SVM de destination.
Workflow de reprise d'activité pour les volumes persistants des applications
Les étapes suivantes décrivent comment mettre à disposition les volumes de destination SnapMirror pour les workloads conteneurisés en cas d'incident :
-
Arrêt de tous les transferts SnapMirror programmés et abandon de tous les transferts SnapMirror en cours. Rompez la relation de réplication entre le volume de destination et le volume source pour que le volume de destination devienne read/write. Nettoyer les déploiements qui consomtaient du volume persistant lié aux volumes sur la SVM source.
-
Une fois le cluster Kubernetes configuré sur le côté destination, suivez les étapes décrites ci-dessus pour nettoyer les déploiements, les demandes de volume persistant et le volume persistant à partir du cluster Kubernetes.
-
Créer de nouveaux systèmes back-end sur Trident en spécifiant la nouvelle LIF de gestion et de données, un nouveau nom de SVM et un nouveau mot de passe du SVM de destination.
-
Importez les volumes requis en tant que volume persistant lié à une nouvelle demande de volume persistant à l'aide de la fonctionnalité d'importation Trident.
-
Redéployez les déploiements d'applications avec les demandes de volume nouvellement créées.
Restaurez les données à l'aide des snapshots Element
Sauvegardez les données sur un volume Element en définissant une planification Snapshot pour le volume. Vous pouvez ainsi vérifier que les snapshots sont effectués à intervalles réguliers. Vous devez définir la planification des snapshots à l'aide de l'interface utilisateur ou des API d'Element. Actuellement, il n'est pas possible de définir un planning de snapshots sur un volume via la solidfire-san conducteur.
En cas de corruption des données, vous pouvez choisir un snapshot en particulier et restaurer manuellement le volume vers le Snapshot à l'aide de l'interface utilisateur ou des API Element. Cette opération rétablit les modifications apportées au volume depuis la création du snapshot.