

Come Unified Manager utilizza la latenza del carico di lavoro per identificare i problemi di prestazioni
 Suggerisci modifiche
Suggerisci modifiche
La latenza del carico di lavoro (tempo di risposta) è il tempo impiegato da un volume su un cluster per rispondere alle richieste di I/O provenienti dalle applicazioni client. Unified Manager utilizza la latenza per rilevare eventi relativi alle prestazioni e avvisarti.
Un'elevata latenza significa che le richieste dalle applicazioni a un volume su un cluster impiegano più tempo del solito. La causa dell'elevata latenza potrebbe risiedere nel cluster stesso, a causa di conflitti su uno o più componenti del cluster. Un'elevata latenza potrebbe essere causata anche da problemi esterni al cluster, come colli di bottiglia di rete, problemi con il client che ospita le applicazioni o problemi con le applicazioni stesse.

|
Unified Manager monitora solo l'attività del carico di lavoro sul cluster. Non monitora le applicazioni, i client o i percorsi tra le applicazioni e il cluster. |
Anche le operazioni sul cluster, come l'esecuzione di backup o la deduplicazione, che aumentano la richiesta di componenti del cluster condivisi da altri carichi di lavoro, possono contribuire a un'elevata latenza. Se la latenza effettiva supera la soglia di prestazioni dinamiche dell'intervallo previsto (previsione di latenza), Unified Manager analizza l'evento per determinare se si tratta di un evento di prestazioni che potrebbe essere necessario risolvere. La latenza viene misurata in millisecondi per operazione (ms/op).
Nel grafico Latenza totale nella pagina Analisi del carico di lavoro, è possibile visualizzare un'analisi delle statistiche di latenza per vedere come l'attività dei singoli processi, come le richieste di lettura e scrittura, si confronta con le statistiche di latenza complessive. Il confronto consente di determinare quali operazioni presentano l'attività più elevata o se specifiche operazioni presentano un'attività anomala che influisce sulla latenza di un volume. Quando si analizzano gli eventi relativi alle prestazioni, è possibile utilizzare le statistiche di latenza per determinare se un evento è stato causato da un problema nel cluster. È anche possibile identificare le attività specifiche del carico di lavoro o i componenti del cluster coinvolti nell'evento.
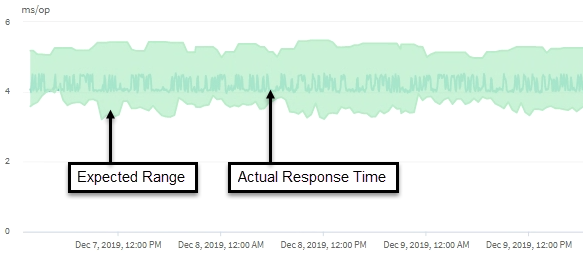
Questo esempio mostra il grafico della latenza. L'attività effettiva del tempo di risposta (latenza) è rappresentata da una linea blu, mentre la previsione della latenza (intervallo previsto) è rappresentata da una linea verde.
|
|
Potrebbero esserci delle lacune nella linea blu se Unified Manager non è riuscito a raccogliere i dati. Ciò può verificarsi perché il cluster o il volume non era raggiungibile, Unified Manager è stato disattivato durante quel periodo oppure la raccolta ha richiesto più tempo dei 5 minuti previsti. |