

Come funziona il processo di rilevamento del cluster
 Suggerisci modifiche
Suggerisci modifiche
Dopo aver aggiunto un cluster a Unified Manager, il server rileva gli oggetti del cluster e li aggiunge al database. La comprensione del funzionamento del processo di rilevamento consente di gestire i cluster dell'organizzazione e i relativi oggetti.
L'intervallo di monitoraggio per la raccolta delle informazioni di configurazione del cluster è di 15 minuti. Ad esempio, dopo aver aggiunto un cluster, sono necessari 15 minuti per visualizzare gli oggetti del cluster nell'interfaccia utente di Unified Manager. Questo intervallo di tempo è valido anche quando si apportano modifiche a un cluster. Ad esempio, se si aggiungono due nuovi volumi a una SVM in un cluster, i nuovi oggetti vengono visualizzati nell'interfaccia utente dopo il successivo intervallo di polling, che potrebbe arrivare fino a 15 minuti.
La seguente immagine illustra il processo di rilevamento:
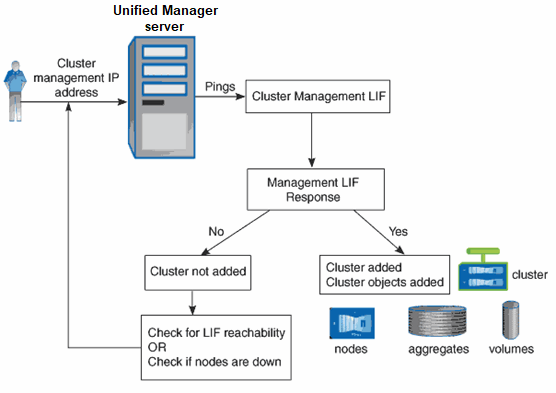
Una volta individuati tutti gli oggetti di un nuovo cluster, Unified Manager inizia a raccogliere dati storici sulle performance per i 15 giorni precedenti. Queste statistiche vengono raccolte utilizzando la funzionalità di raccolta della continuità dei dati. Questa funzionalità fornisce oltre due settimane di informazioni sulle performance per un cluster subito dopo l'aggiunta. Una volta completato il ciclo di raccolta della continuità dei dati, i dati delle performance del cluster in tempo reale vengono raccolti, per impostazione predefinita, ogni cinque minuti.

|
Dato che la raccolta di 15 giorni di dati sulle performance richiede un uso intensivo della CPU, si consiglia di eseguire l'aggiunta di nuovi cluster in modo che i sondaggi per la raccolta della continuità dei dati non vengano eseguiti su troppi cluster contemporaneamente. |