

Analisi di un evento di performance dinamica su un cluster in una configurazione MetroCluster
 Suggerisci modifiche
Suggerisci modifiche
È possibile utilizzare Unified Manager per analizzare il cluster in una configurazione MetroCluster in cui è stato rilevato un evento di performance. È possibile identificare il nome del cluster, il tempo di rilevamento degli eventi e i carichi di lavoro bully e vittima coinvolti.
Prima di iniziare
-
È necessario disporre del ruolo di operatore, amministratore dell'applicazione o amministratore dello storage.
-
Per una configurazione MetroCluster devono essere presenti eventi di performance nuovi, riconosciuti o obsoleti.
-
Entrambi i cluster nella configurazione di MetroCluster devono essere monitorati dalla stessa istanza di Unified Manager.
Fasi
-
Visualizzare la pagina Dettagli evento per visualizzare le informazioni relative all'evento.
-
Esaminare la descrizione dell'evento per visualizzare i nomi dei carichi di lavoro coinvolti e il numero di carichi di lavoro coinvolti.
In questo esempio, l'icona risorse MetroCluster è rossa, a indicare che le risorse MetroCluster sono in conflitto. Posizionare il cursore sull'icona per visualizzare una descrizione dell'icona.

-
Prendere nota del nome del cluster e del tempo di rilevamento degli eventi, che è possibile utilizzare per analizzare gli eventi delle performance sul cluster del partner.
-
Nei grafici, esaminare i carichi di lavoro delle vittime per confermare che i tempi di risposta sono superiori alla soglia di performance.
In questo esempio, il carico di lavoro della vittima viene visualizzato nel testo del passaggio del mouse. I grafici di latenza mostrano, ad alto livello, un modello di latenza coerente per i carichi di lavoro delle vittime coinvolti. Anche se la latenza anomala dei carichi di lavoro delle vittime ha attivato l'evento, un modello di latenza coerente potrebbe indicare che le prestazioni dei carichi di lavoro rientrano nell'intervallo previsto, ma che un picco di i/o ha aumentato la latenza e attivato l'evento.
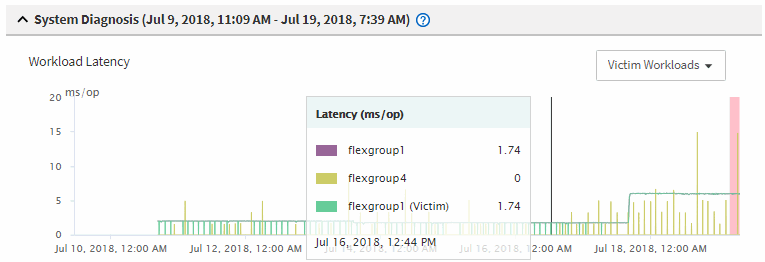
Se di recente hai installato un'applicazione su un client che accede a questi workload di volume e tale applicazione invia loro una quantità elevata di i/o, potresti prevedere un aumento delle latenze. Se la latenza per i carichi di lavoro rientra nell'intervallo previsto, lo stato dell'evento diventa obsoleto e rimane in questo stato per più di 30 minuti, probabilmente è possibile ignorare l'evento. Se l'evento è in corso e rimane nel nuovo stato, è possibile esaminarlo ulteriormente per determinare se altri problemi hanno causato l'evento.
-
Nel grafico workload throughput, selezionare Bully workload per visualizzare i carichi di lavoro ingombrante.
La presenza di carichi di lavoro ingombranti indica che l'evento potrebbe essere stato causato da uno o più carichi di lavoro nel cluster locale che utilizzano in maniera eccessiva le risorse MetroCluster. I carichi di lavoro ingombranti presentano un'elevata deviazione nel throughput di scrittura (MB/s).
Questo grafico mostra, ad alto livello, lo schema di throughput in scrittura (MB/s) per i carichi di lavoro. È possibile rivedere il modello di scrittura MB/s per identificare un throughput anomalo, che potrebbe indicare che un carico di lavoro sta utilizzando in modo eccessivo le risorse MetroCluster.
Se l'evento non coinvolge carichi di lavoro ingombranti, l'evento potrebbe essere stato causato da un problema di integrità del collegamento tra i cluster o da un problema di performance sul cluster partner. È possibile utilizzare Unified Manager per controllare lo stato di entrambi i cluster in una configurazione MetroCluster. È inoltre possibile utilizzare Unified Manager per controllare e analizzare gli eventi relativi alle performance nel cluster dei partner.