

Gestisci l'archiviazione degli oggetti utilizzata per il tiering dei dati in NetApp Cloud Tiering
 Suggerisci modifiche
Suggerisci modifiche
Dopo aver configurato i cluster ONTAP locali per suddividere i dati in livelli in uno specifico storage di oggetti, è possibile eseguire ulteriori attività di storage di oggetti utilizzando NetApp Cloud Tiering. È possibile aggiungere un nuovo archivio di oggetti, eseguire il mirroring dei dati a livelli su un archivio di oggetti secondario, scambiare l'archivio di oggetti primario e mirror, rimuovere un archivio di oggetti mirror da un aggregato e molto altro.
Visualizza gli archivi di oggetti configurati per un cluster
È possibile visualizzare tutti gli archivi di oggetti configurati per ciascun cluster e a quali aggregati sono collegati.
-
Dalla pagina Cluster, seleziona l'icona del menu per un cluster e seleziona Informazioni sull'archivio oggetti.
-
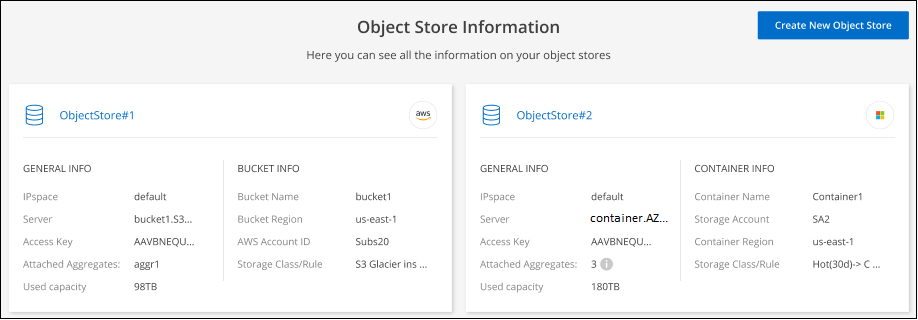
Esaminare i dettagli sugli archivi di oggetti.
Questo esempio mostra un archivio di oggetti Amazon S3 e Azure Blob collegati a diversi aggregati su un cluster.
Aggiungi un nuovo archivio oggetti
È possibile aggiungere un nuovo archivio oggetti per gli aggregati nel cluster. Dopo averlo creato, puoi allegarlo a un aggregato.
-
Dalla pagina Cluster, seleziona l'icona del menu per un cluster e seleziona Informazioni sull'archivio oggetti.
-
Dalla pagina Informazioni sull'archivio oggetti, seleziona Crea nuovo archivio oggetti.
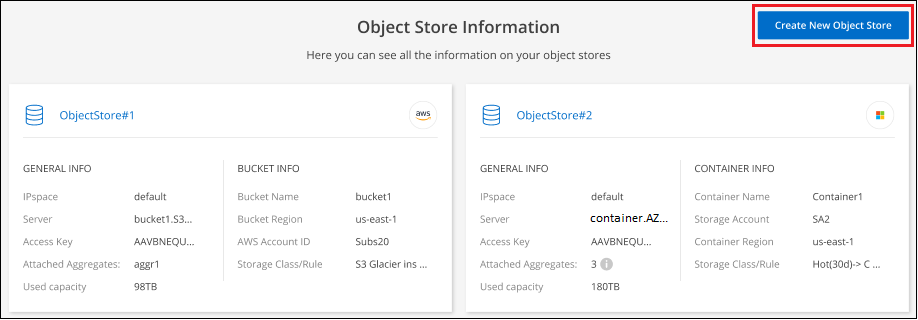
Viene avviata la procedura guidata per l'archiviazione degli oggetti. L'esempio seguente mostra come creare un archivio oggetti in Amazon S3.
-
Definisci nome archivio oggetti: inserisci un nome per questo archivio oggetti. Deve essere univoco rispetto a qualsiasi altro archivio di oggetti che potresti utilizzare con gli aggregati su questo cluster.
-
Seleziona fornitore: seleziona il fornitore, ad esempio Amazon Web Services, e seleziona Continua.
-
Completare i passaggi nelle pagine Crea archiviazione oggetti:
-
Bucket S3: aggiungi un nuovo bucket S3 o seleziona un bucket S3 esistente che inizia con il prefisso fabric-pool. Quindi inserisci l'ID dell'account AWS che fornisce l'accesso al bucket, seleziona la regione del bucket e seleziona Continua.
Il prefisso fabric-pool è obbligatorio perché il criterio IAM per l'agente Console consente all'istanza di eseguire azioni S3 sui bucket denominati con quel prefisso esatto. Ad esempio, è possibile denominare il bucket S3 fabric-pool-AFF1, dove AFF1 è il nome del cluster.
-
Ciclo di vita della classe di archiviazione: Cloud Tiering gestisce le transizioni del ciclo di vita dei dati suddivisi in livelli. I dati iniziano nella classe Standard, ma è possibile creare una regola per applicare una classe di archiviazione diversa ai dati dopo un certo numero di giorni.
Selezionare la classe di archiviazione S3 in cui si desidera trasferire i dati a livelli e il numero di giorni prima che i dati vengano assegnati a tale classe, quindi selezionare Continua. Ad esempio, lo screenshot seguente mostra che i dati a livelli vengono assegnati alla classe Standard-IA dalla classe Standard dopo 45 giorni nell'archiviazione degli oggetti.
Se si sceglie Mantieni i dati in questa classe di archiviazione, i dati rimangono nella classe di archiviazione Standard e non vengono applicate regole. "Visualizza le classi di archiviazione supportate".
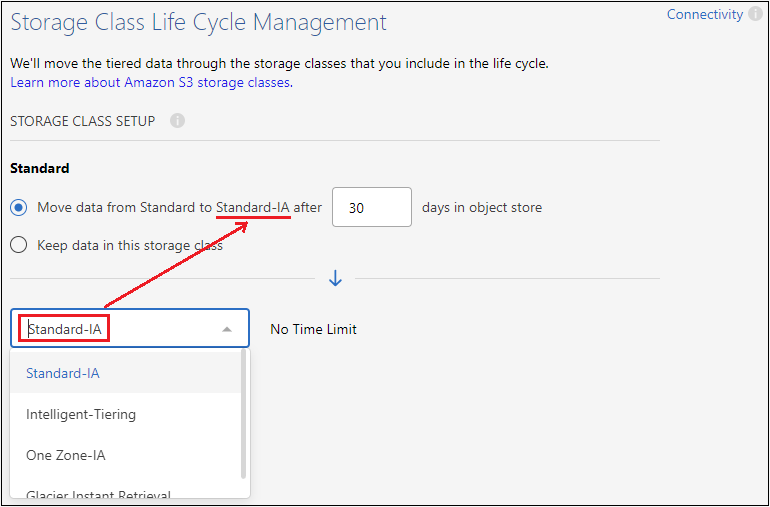
Si noti che la regola del ciclo di vita viene applicata a tutti gli oggetti nel bucket selezionato.
-
Credenziali: immettere l'ID della chiave di accesso e la chiave segreta per un utente IAM che dispone delle autorizzazioni S3 richieste e selezionare Continua.
L'utente IAM deve trovarsi nello stesso account AWS del bucket selezionato o creato nella pagina S3 Bucket. Consultare le autorizzazioni richieste nella sezione relativa all'attivazione della suddivisione in livelli.
-
Rete cluster: selezionare lo spazio IP che ONTAP deve utilizzare per connettersi all'archiviazione degli oggetti e selezionare Continua.
Selezionando lo spazio IP corretto si garantisce che Cloud Tiering possa impostare una connessione da ONTAP allo storage degli oggetti del provider cloud.
-
Viene creato l'archivio oggetti.
Ora puoi collegare l'archivio oggetti a un aggregato nel tuo cluster.
Collegare un secondo archivio oggetti a un aggregato per il mirroring
È possibile collegare un secondo archivio oggetti a un aggregato per creare un mirror FabricPool per suddividere in livelli sincroni i dati in due archivi oggetti. È necessario che un archivio oggetti sia già collegato all'aggregato. "Scopri di più sugli specchi FabricPool" .
Quando si utilizza una configurazione MetroCluster , è consigliabile utilizzare archivi di oggetti nel cloud pubblico che si trovano in zone di disponibilità diverse. "Per saperne di più sui requisiti MetroCluster, consulta la documentazione ONTAP" . All'interno di un MetroCluster, non è consigliabile utilizzare aggregati non speculari, poiché ciò causerebbe un messaggio di errore.
Quando si utilizza StorageGRID come archivio oggetti in una configurazione MetroCluster , entrambi i sistemi ONTAP possono eseguire il tiering FabricPool su un singolo sistema StorageGRID . Ogni sistema ONTAP deve suddividere i dati in diversi bucket.
-
Dalla pagina Cluster, seleziona Configurazione avanzata per il cluster selezionato.

-
Dalla pagina Configurazione avanzata, trascinare l'archivio oggetti che si desidera utilizzare nella posizione dell'archivio oggetti mirror.
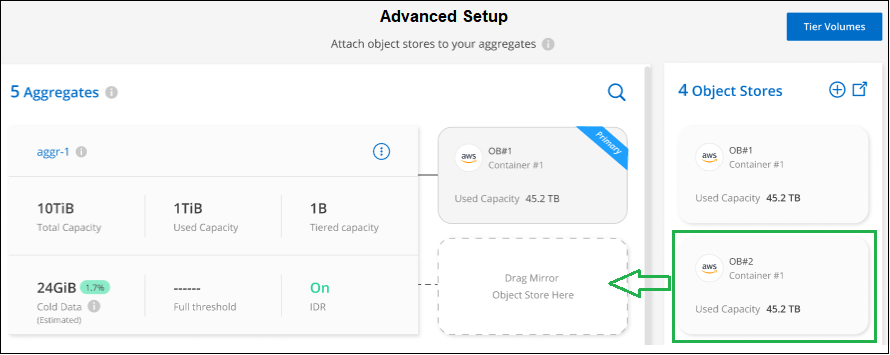
-
Nella finestra di dialogo Allega archivio oggetti, seleziona Allega e il secondo archivio oggetti verrà allegato all'aggregato.
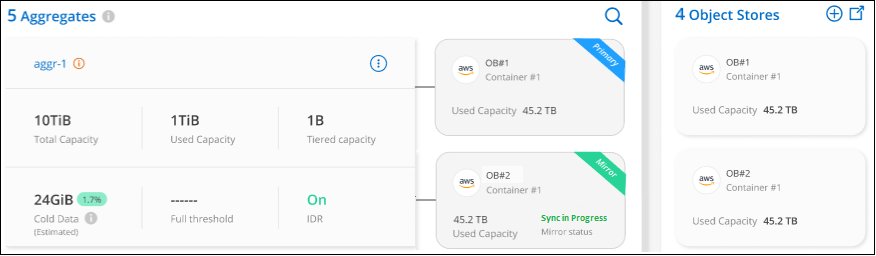
Lo stato Mirror apparirà come "Sincronizzazione in corso" mentre i 2 archivi di oggetti sono in fase di sincronizzazione. Una volta completata la sincronizzazione, lo stato cambierà in "Sincronizzato".
Scambia l'archivio oggetti primario e mirror
È possibile scambiare l'archivio oggetti primario e mirror con un aggregato. Lo specchio dell'archivio oggetti diventa primario e il primario originale diventa lo specchio.
-
Dalla pagina Cluster, seleziona Configurazione avanzata per il cluster selezionato.
-
Dalla pagina Configurazione avanzata, seleziona l'icona del menu per l'aggregato e seleziona Scambia destinazioni.
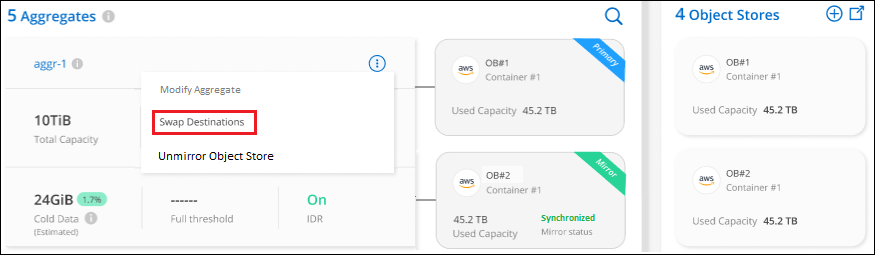
-
Approvare l'azione nella finestra di dialogo e gli archivi degli oggetti primari e mirror verranno scambiati.
Rimuovere un archivio di oggetti mirror da un aggregato
È possibile rimuovere un mirror FabricPool se non è più necessario replicare su un archivio oggetti aggiuntivo.
-
Dalla pagina Cluster, seleziona Configurazione avanzata per il cluster selezionato.
-
Dalla pagina Configurazione avanzata, seleziona l'icona del menu per l'aggregato e seleziona Annulla mirroring archivio oggetti.
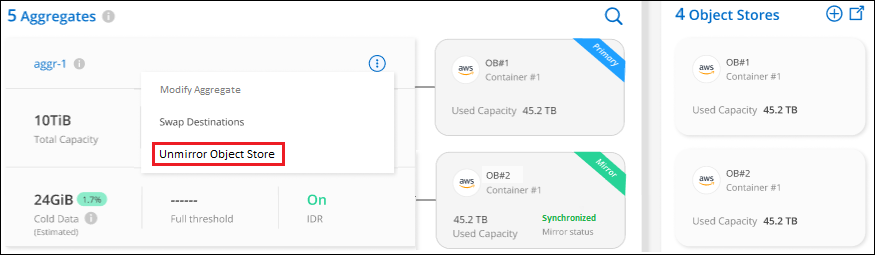
L'archivio oggetti mirror viene rimosso dall'aggregato e i dati a livelli non vengono più replicati.

|
Quando si rimuove l'archivio oggetti mirror da una configurazione MetroCluster , verrà chiesto se si desidera rimuovere anche l'archivio oggetti primario. È possibile scegliere di mantenere l'archivio oggetti primario collegato all'aggregato oppure di rimuoverlo. |
Migra i tuoi dati a livelli verso un diverso provider cloud
Cloud Tiering ti consente di migrare facilmente i tuoi dati suddivisi in livelli verso un diverso provider cloud. Ad esempio, se si desidera passare da Amazon S3 ad Azure Blob, è possibile seguire i passaggi elencati sopra in questo ordine:
-
Aggiungere un archivio oggetti BLOB di Azure.
-
Collegare questo nuovo archivio oggetti come mirror all'aggregato esistente.
-
Scambia gli archivi degli oggetti primari e mirror.
-
Annullare il mirroring dell'archivio oggetti Amazon S3.