

Parte 2 - Utilizzo di AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) come origine dati per l'addestramento del modello in SageMaker
 Suggerisci modifiche
Suggerisci modifiche
Questo articolo è un tutorial sull'utilizzo di Amazon FSx for NetApp ONTAP (FSx ONTAP) per l'addestramento di modelli PyTorch in SageMaker, in particolare per un progetto di classificazione della qualità degli pneumatici.
Introduzione
Questo tutorial offre un esempio pratico di un progetto di classificazione della visione artificiale, fornendo un'esperienza pratica nella creazione di modelli di apprendimento automatico che utilizzano FSx ONTAP come origine dati all'interno dell'ambiente SageMaker. Il progetto si concentra sull'utilizzo di PyTorch, un framework di deep learning, per classificare la qualità degli pneumatici in base alle immagini degli stessi. Si concentra sullo sviluppo di modelli di apprendimento automatico utilizzando FSx ONTAP come origine dati in Amazon SageMaker.
Che cos'è FSx ONTAP
Amazon FSx ONTAP è effettivamente una soluzione di storage completamente gestita offerta da AWS. Sfrutta il file system ONTAP di NetApp per fornire uno storage affidabile e ad alte prestazioni. Grazie al supporto di protocolli come NFS, SMB e iSCSI, consente un accesso senza interruzioni da diverse istanze di elaborazione e container. Il servizio è progettato per offrire prestazioni eccezionali, garantendo operazioni sui dati rapide ed efficienti. Offre inoltre elevata disponibilità e durabilità, garantendo che i tuoi dati rimangano accessibili e protetti. Inoltre, la capacità di archiviazione di Amazon FSx ONTAP è scalabile, consentendoti di adattarla facilmente in base alle tue esigenze.
Prerequisito
Ambiente di rete
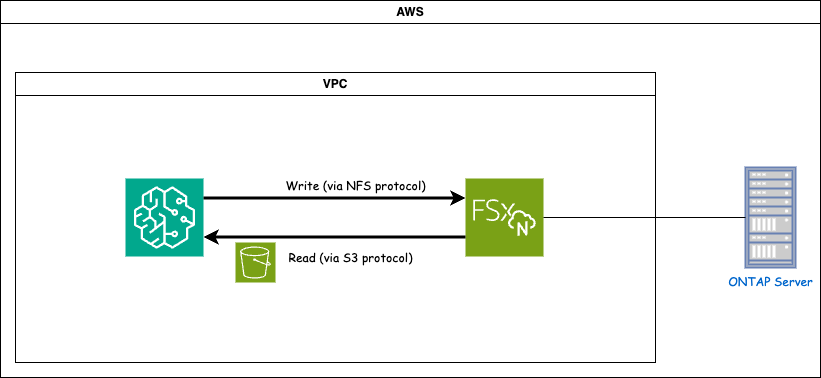
FSx ONTAP (Amazon FSx ONTAP) è un servizio di archiviazione AWS. Include un file system in esecuzione sul sistema NetApp ONTAP e una macchina virtuale (SVM) gestita da AWS che si connette ad esso. Nel diagramma fornito, il server NetApp ONTAP gestito da AWS si trova all'esterno della VPC. L'SVM funge da intermediario tra SageMaker e il sistema NetApp ONTAP , ricevendo le richieste operative da SageMaker e inoltrandole allo storage sottostante. Per accedere a FSx ONTAP, SageMaker deve essere posizionato nella stessa VPC della distribuzione FSx ONTAP . Questa configurazione garantisce la comunicazione e l'accesso ai dati tra SageMaker e FSx ONTAP.
Accesso ai dati
In scenari reali, gli scienziati dei dati in genere utilizzano i dati esistenti archiviati in FSx ONTAP per creare i loro modelli di apprendimento automatico. Tuttavia, a scopo dimostrativo, poiché il file system FSx ONTAP è inizialmente vuoto dopo la creazione, è necessario caricare manualmente i dati di addestramento. Ciò può essere ottenuto montando FSx ONTAP come volume su SageMaker. Una volta montato correttamente il file system, puoi caricare il tuo set di dati nella posizione montata, rendendolo accessibile per l'addestramento dei tuoi modelli nell'ambiente SageMaker. Questo approccio consente di sfruttare la capacità di archiviazione e le funzionalità di FSx ONTAP mentre si lavora con SageMaker per lo sviluppo e la formazione dei modelli.
Il processo di lettura dei dati prevede la configurazione di FSx ONTAP come bucket S3 privato. Per apprendere le istruzioni di configurazione dettagliate, fare riferimento a"Parte 1 - Integrazione di Amazon FSx for NetApp ONTAP (FSx ONTAP)) come bucket S3 privato in AWS SageMaker"
Panoramica sull'integrazione
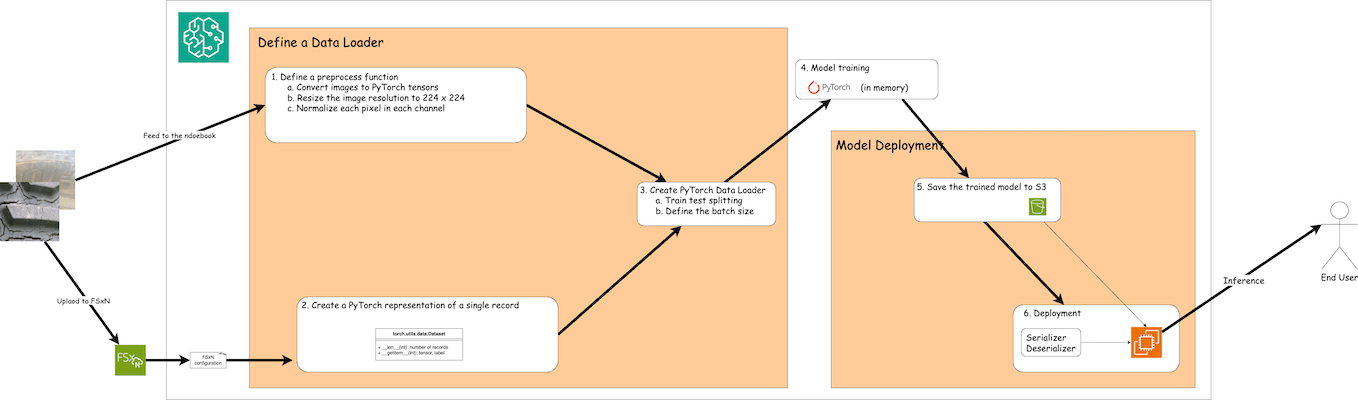
Il flusso di lavoro per l'utilizzo dei dati di training in FSx ONTAP per creare un modello di deep learning in SageMaker può essere riassunto in tre passaggi principali: definizione del caricatore dati, training del modello e distribuzione. Ad alto livello, questi passaggi costituiscono la base di una pipeline MLOps. Tuttavia, ogni fase prevede diversi sotto-fasi dettagliati per un'implementazione completa. Questi sotto-passaggi comprendono varie attività, quali la pre-elaborazione dei dati, la suddivisione del set di dati, la configurazione del modello, l'ottimizzazione degli iperparametri, la valutazione del modello e l'implementazione del modello. Questi passaggi garantiscono un processo completo ed efficace per la creazione e l'implementazione di modelli di deep learning utilizzando i dati di training di FSx ONTAP all'interno dell'ambiente SageMaker.
Integrazione passo dopo passo
Loader dati
Per addestrare una rete di deep learning PyTorch con i dati, viene creato un caricatore di dati per facilitare l'alimentazione dei dati. Il caricatore dati non solo definisce la dimensione del batch, ma determina anche la procedura per la lettura e la preelaborazione di ciascun record all'interno del batch. Configurando il caricatore di dati, possiamo gestire l'elaborazione dei dati in batch, consentendo l'addestramento della rete di deep learning.
Il caricatore dati è composto da 3 parti.
Funzione di pre-elaborazione
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])Il frammento di codice sopra riportato illustra la definizione delle trasformazioni di pre-elaborazione delle immagini utilizzando il modulo torchvision.transforms. In questo tutorial, l'oggetto preprocess viene creato per applicare una serie di trasformazioni. Innanzitutto, la trasformazione ToTensor() converte l'immagine in una rappresentazione tensoriale. Successivamente, la trasformazione Resize224,224 ridimensiona l'immagine a una dimensione fissa di 224x224 pixel. Infine, la trasformazione Normalize() normalizza i valori del tensore sottraendo la media e dividendo per la deviazione standard lungo ciascun canale. I valori di media e deviazione standard utilizzati per la normalizzazione sono comunemente impiegati nei modelli di reti neurali pre-addestrati. Nel complesso, questo codice prepara i dati dell'immagine per un'ulteriore elaborazione o per l'inserimento in un modello pre-addestrato, convertendoli in un tensore, ridimensionandoli e normalizzando i valori dei pixel.
La classe del set di dati PyTorch
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelQuesta classe fornisce funzionalità per ottenere il numero totale di record nel set di dati e definisce il metodo per leggere i dati per ciascun record. All'interno della funzione getitem, il codice utilizza l'oggetto bucket S3 boto3 per recuperare i dati binari da FSx ONTAP. Lo stile del codice per l'accesso ai dati da FSx ONTAP è simile a quello per la lettura dei dati da Amazon S3. La spiegazione successiva approfondisce il processo di creazione dell'oggetto S3 privato bucket.
FSx ONTAP come repository S3 privato
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---Per leggere i dati da FSx ONTAP in SageMaker, viene creato un gestore che punta allo storage FSx ONTAP utilizzando il protocollo S3. Ciò consente di trattare FSx ONTAP come un bucket S3 privato. La configurazione del gestore include la specifica dell'indirizzo IP dell'SVM FSx ONTAP , del nome del bucket e delle credenziali necessarie. Per una spiegazione completa su come ottenere questi elementi di configurazione, fare riferimento al documento all'indirizzo"Parte 1 - Integrazione di Amazon FSx for NetApp ONTAP (FSx ONTAP) come bucket S3 privato in AWS SageMaker" .
Nell'esempio menzionato sopra, l'oggetto bucket viene utilizzato per istanziare l'oggetto dataset PyTorch. L'oggetto dataset verrà spiegato più dettagliatamente nella sezione successiva.
Il Loader dati PyTorch
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)Nell'esempio fornito, viene specificata una dimensione batch pari a 64, a indicare che ogni batch conterrà 64 record. Combinando la classe PyTorch Dataset, la funzione di pre-elaborazione e la dimensione del batch di addestramento, otteniamo il caricatore di dati per l'addestramento. Questo caricatore di dati semplifica il processo di iterazione del set di dati in batch durante la fase di addestramento.
Formazione del modello
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')Questo codice implementa un processo di addestramento PyTorch standard. Definisce un modello di rete neurale denominato TyreQualityClassifier che utilizza livelli convoluzionali e un livello lineare per classificare la qualità degli pneumatici. Il ciclo di addestramento esegue iterazioni su batch di dati, calcola la perdita e aggiorna i parametri del modello utilizzando la backpropagation e l'ottimizzazione. Inoltre, stampa l'ora corrente, l'epoca, il lotto e la perdita a scopo di monitoraggio.
Distribuzione del modello
Distribuzione
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())Il codice salva il modello PyTorch su Amazon S3 perché SageMaker richiede che il modello venga archiviato in S3 per la distribuzione. Caricando il modello su Amazon S3, questo diventa accessibile a SageMaker, consentendo la distribuzione e l'inferenza sul modello distribuito.
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)Questo codice facilita l'implementazione di un modello PyTorch su SageMaker. Definisce un serializzatore personalizzato, TyreQualitySerializer, che preelabora e serializza i dati di input come un tensore PyTorch. La classe TyreQualityPredictor è un predittore personalizzato che utilizza il serializzatore definito e un JSONDeserializer. Il codice crea anche un oggetto PyTorchModel per specificare la posizione S3 del modello, il ruolo IAM, la versione del framework e il punto di ingresso per l'inferenza. Il codice genera un timestamp e costruisce un nome di endpoint basato sul modello e sul timestamp. Infine, il modello viene distribuito utilizzando il metodo deploy, specificando il conteggio delle istanze, il tipo di istanza e il nome dell'endpoint generato. Ciò consente di distribuire il modello PyTorch e di renderlo accessibile per l'inferenza su SageMaker.
Inferenza
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)Questo è un esempio di utilizzo dell'endpoint distribuito per eseguire l'inferenza.