

TR-4570: Soluzioni di storage NetApp per Apache Spark: architettura, casi d'uso e risultati delle prestazioni
 Suggerisci modifiche
Suggerisci modifiche
Rick Huang, Karthikeyan Nagalingam, NetApp
Questo documento si concentra sull'architettura di Apache Spark, sui casi d'uso dei clienti e sul portafoglio di storage NetApp correlato all'analisi dei big data e all'intelligenza artificiale (IA). Presenta inoltre vari risultati di test effettuati utilizzando strumenti di intelligenza artificiale, apprendimento automatico (ML) e apprendimento profondo (DL) standard del settore su un tipico sistema Hadoop, in modo da poter scegliere la soluzione Spark più adatta. Per iniziare, hai bisogno di un'architettura Spark, di componenti appropriati e di due modalità di distribuzione (cluster e client).
Questo documento fornisce inoltre casi d'uso dei clienti per risolvere problemi di configurazione e fornisce una panoramica del portafoglio di storage NetApp rilevante per l'analisi dei big data e l'intelligenza artificiale, l'apprendimento automatico e il apprendimento automatico con Spark. Concludiamo quindi con i risultati dei test derivati dai casi d'uso specifici di Spark e dal portafoglio di soluzioni NetApp Spark.
Sfide dei clienti
Questa sezione si concentra sulle sfide dei clienti relative all'analisi dei big data e all'intelligenza artificiale, al machine learning e al digital learning nei settori in cui i dati crescono, come la vendita al dettaglio, il marketing digitale, il settore bancario, la produzione discreta, la produzione di processo, la pubblica amministrazione e i servizi professionali.
Prestazioni imprevedibili
Le distribuzioni Hadoop tradizionali utilizzano in genere hardware di base. Per migliorare le prestazioni, è necessario ottimizzare la rete, il sistema operativo, il cluster Hadoop, i componenti dell'ecosistema come Spark e l'hardware. Anche se si ottimizza ogni livello, può essere difficile raggiungere i livelli di prestazioni desiderati perché Hadoop viene eseguito su hardware di base che non è stato progettato per prestazioni elevate nel tuo ambiente.
Guasti dei media e dei nodi
Anche in condizioni normali, l'hardware di base è soggetto a guasti. Se un disco su un nodo dati si guasta, per impostazione predefinita il master Hadoop considera quel nodo non funzionante. Quindi copia dati specifici da quel nodo attraverso la rete dalle repliche a un nodo sano. Questo processo rallenta i pacchetti di rete per qualsiasi attività Hadoop. Il cluster deve quindi copiare nuovamente i dati e rimuovere i dati sovrareplicati quando il nodo non funzionante torna a uno stato funzionante.
Blocco del fornitore Hadoop
I distributori Hadoop dispongono di una propria distribuzione Hadoop con il proprio controllo delle versioni, che vincola il cliente a tali distribuzioni. Tuttavia, molti clienti necessitano di supporto per l'analisi in memoria che non vincoli il cliente a specifiche distribuzioni Hadoop. Hanno bisogno della libertà di modificare le distribuzioni e continuare a portare con sé le proprie analisi.
Mancanza di supporto per più di una lingua
Oltre ai programmi MapReduce Java, spesso i clienti necessitano del supporto per più lingue per eseguire i loro lavori. Opzioni come SQL e script offrono maggiore flessibilità per ottenere risposte, più possibilità per organizzare e recuperare i dati e modi più rapidi per spostare i dati in un framework di analisi.
Difficoltà d'uso
Da un po' di tempo le persone si lamentano della difficoltà di utilizzo di Hadoop. Sebbene Hadoop sia diventato più semplice e potente con ogni nuova versione, questa critica persiste. Hadoop richiede la conoscenza dei modelli di programmazione Java e MapReduce, una sfida per gli amministratori di database e per chi ha competenze di scripting tradizionali.
Framework e strumenti complicati
I team di intelligenza artificiale delle aziende devono affrontare molteplici sfide. Anche con conoscenze specialistiche in materia di data science, gli strumenti e i framework per diversi ecosistemi di distribuzione e applicazioni potrebbero non essere facilmente traducibili dall'uno all'altro. Una piattaforma di data science dovrebbe integrarsi perfettamente con le corrispondenti piattaforme big data basate su Spark, con facilità di spostamento dei dati, modelli riutilizzabili, codice pronto all'uso e strumenti che supportano le migliori pratiche per la prototipazione, la convalida, il controllo delle versioni, la condivisione, il riutilizzo e la rapida distribuzione dei modelli in produzione.
Perché scegliere NetApp?
NetApp può migliorare la tua esperienza Spark nei seguenti modi:
-
L'accesso diretto NFS NetApp (mostrato nella figura sottostante) consente ai clienti di eseguire attività di analisi di big data sui propri dati NFSv3 o NFSv4 nuovi o esistenti senza dover spostare o copiare i dati. Impedisce la creazione di copie multiple dei dati ed elimina la necessità di sincronizzare i dati con una fonte.
-
Archiviazione più efficiente e minore replicazione del server. Ad esempio, la soluzione NetApp E-Series Hadoop richiede due anziché tre repliche dei dati, mentre la soluzione FAS Hadoop richiede un'origine dati ma nessuna replica o copia dei dati. Le soluzioni di storage NetApp generano inoltre meno traffico tra server.
-
Miglioramento del lavoro Hadoop e del comportamento del cluster in caso di guasti di unità e nodi.
-
Migliori prestazioni di acquisizione dei dati.
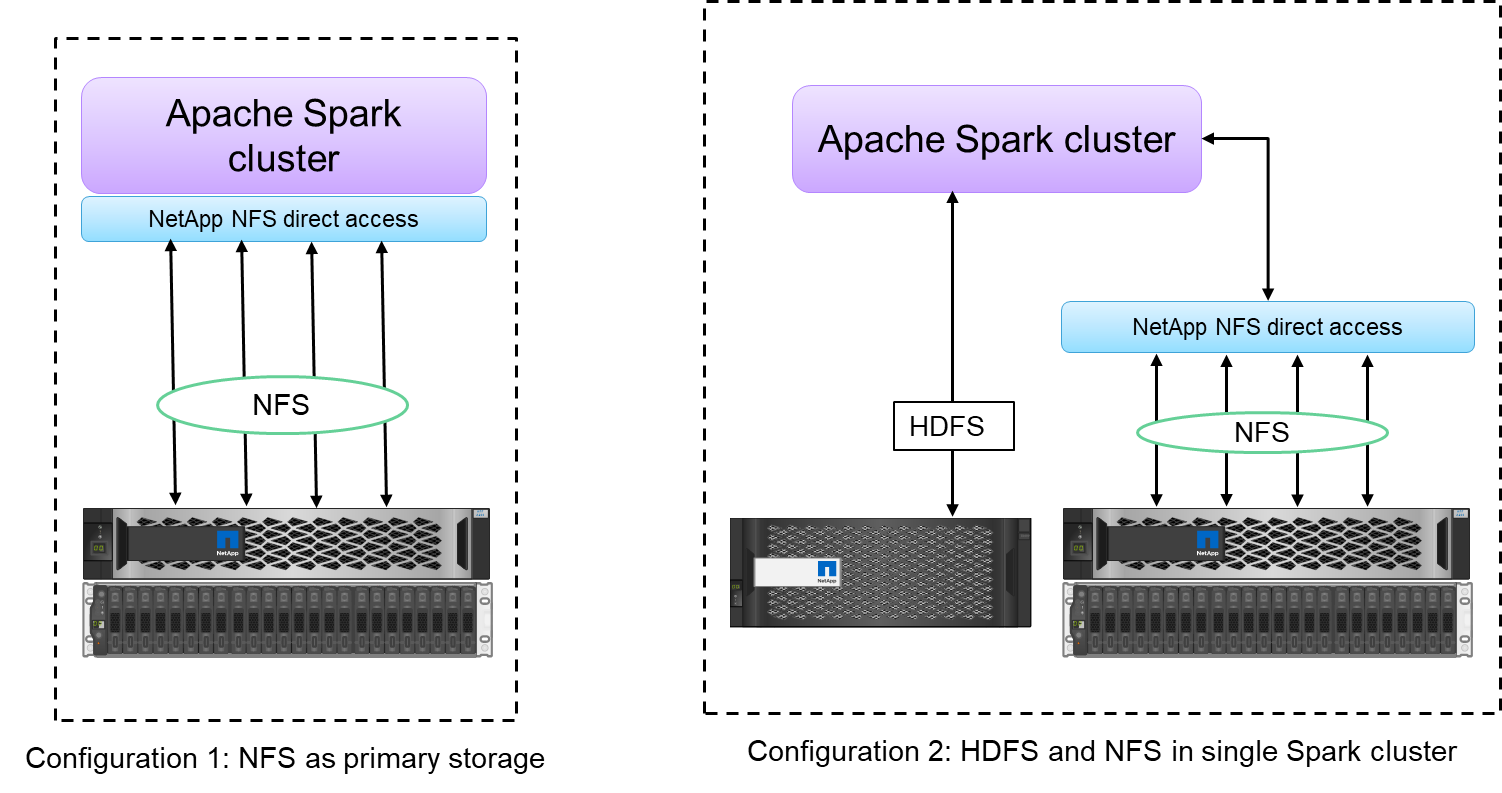
Ad esempio, nel settore finanziario e sanitario, lo spostamento dei dati da un luogo all'altro deve rispettare obblighi di legge, il che non è un compito facile. In questo scenario, l'accesso diretto NFS NetApp analizza i dati finanziari e sanitari dalla loro posizione originale. Un altro vantaggio fondamentale è che l'utilizzo dell'accesso diretto NFS NetApp semplifica la protezione dei dati Hadoop mediante l'utilizzo di comandi Hadoop nativi e l'abilitazione di flussi di lavoro di protezione dei dati con il ricco portafoglio di gestione dei dati di NetApp.
L'accesso diretto NFS NetApp offre due tipi di opzioni di distribuzione per i cluster Hadoop/Spark:
-
Per impostazione predefinita, i cluster Hadoop o Spark utilizzano Hadoop Distributed File System (HDFS) per l'archiviazione dei dati e il file system predefinito. L'accesso diretto a NFS NetApp può sostituire l'HDFS predefinito con l'archiviazione NFS come file system predefinito, consentendo l'analisi diretta sui dati NFS.
-
In un'altra opzione di distribuzione, l'accesso diretto a NetApp NFS supporta la configurazione di NFS come storage aggiuntivo insieme a HDFS in un singolo cluster Hadoop o Spark. In questo caso, il cliente può condividere i dati tramite esportazioni NFS e accedervi dallo stesso cluster insieme ai dati HDFS.
I principali vantaggi dell'utilizzo dell'accesso diretto NFS NetApp includono quanto segue:
-
Analizzando i dati dalla loro posizione attuale, si evita il compito, dispendioso in termini di tempo e prestazioni, di spostare i dati analitici su un'infrastruttura Hadoop come HDFS.
-
Riduzione del numero di repliche da tre a una.
-
Consentire agli utenti di disaccoppiare elaborazione e archiviazione per scalarli in modo indipendente.
-
Garantire la protezione dei dati aziendali sfruttando le avanzate funzionalità di gestione dei dati di ONTAP.
-
Certificazione con la piattaforma dati Hortonworks.
-
Abilitazione di implementazioni di analisi dei dati ibride.
-
Riduzione dei tempi di backup sfruttando la capacità multithread dinamica.
Vedere"TR-4657: Soluzioni dati cloud ibride NetApp - Spark e Hadoop basate sui casi d'uso dei clienti" per il backup dei dati Hadoop, il backup e il disaster recovery dal cloud all'ambiente locale, abilitando DevTest sui dati Hadoop esistenti, la protezione dei dati e la connettività multicloud e accelerando i carichi di lavoro di analisi.
Le sezioni seguenti descrivono le capacità di archiviazione importanti per i clienti Spark.
Livelli di archiviazione
Grazie alla suddivisione in livelli di archiviazione di Hadoop, è possibile archiviare i file con diversi tipi di archiviazione in base a una policy di archiviazione. I tipi di archiviazione includono hot , cold , warm , all_ssd , one_ssd , E lazy_persist .
Abbiamo eseguito la convalida della suddivisione in livelli di archiviazione Hadoop su un controller di archiviazione NetApp AFF e un controller di archiviazione E-Series con unità SSD e SAS con diverse policy di archiviazione. Il cluster Spark con AFF-A800 ha quattro nodi di elaborazione, mentre il cluster con E-Series ne ha otto. Lo scopo principale è confrontare le prestazioni delle unità a stato solido (SSD) rispetto ai dischi rigidi (HDD).
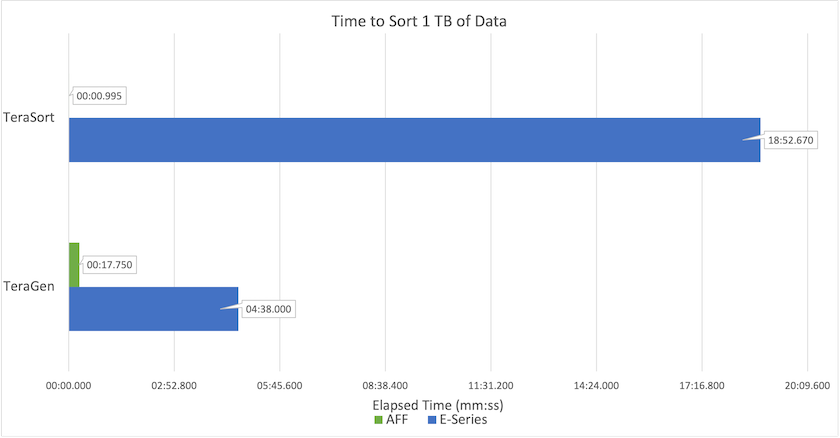
La figura seguente mostra le prestazioni delle soluzioni NetApp per un SSD Hadoop.
-
La configurazione NL-SAS di base utilizzava otto nodi di elaborazione e 96 unità NL-SAS. Questa configurazione ha generato 1 TB di dati in 4 minuti e 38 secondi. Vedere "TR-3969 Soluzione NetApp E-Series per Hadoop" per i dettagli sulla configurazione del cluster e dello storage.
-
Utilizzando TeraGen, la configurazione SSD ha generato 1 TB di dati 15,66 volte più velocemente rispetto alla configurazione NL-SAS. Inoltre, la configurazione SSD utilizzava la metà del numero di nodi di elaborazione e la metà del numero di unità disco (24 unità SSD in totale). In base al tempo di completamento del lavoro, è stato quasi il doppio più veloce della configurazione NL-SAS.
-
Utilizzando TeraSort, la configurazione SSD ha ordinato 1 TB di dati 1138,36 volte più velocemente rispetto alla configurazione NL-SAS. Inoltre, la configurazione SSD utilizzava la metà del numero di nodi di elaborazione e la metà del numero di unità disco (24 unità SSD in totale). Pertanto, per unità, era circa tre volte più veloce della configurazione NL-SAS.
-
La conclusione è che il passaggio dai dischi rotanti a quelli completamente flash migliora le prestazioni. Il collo di bottiglia non era il numero di nodi di elaborazione. Grazie allo storage all-flash di NetApp, le prestazioni di runtime sono ben scalabili.
-
Con NFS, i dati erano funzionalmente equivalenti a essere raggruppati tutti insieme, il che può ridurre il numero di nodi di elaborazione a seconda del carico di lavoro. Gli utenti del cluster Apache Spark non devono ribilanciare manualmente i dati quando cambiano il numero di nodi di elaborazione.
Scalabilità delle prestazioni - Scalabilità orizzontale
Quando è necessaria una maggiore potenza di calcolo da un cluster Hadoop in una soluzione AFF , è possibile aggiungere nodi dati con un numero appropriato di controller di archiviazione. NetApp consiglia di iniziare con quattro nodi dati per array di controller di storage e di aumentare il numero a otto nodi dati per controller di storage, a seconda delle caratteristiche del carico di lavoro.
AFF e FAS sono perfetti per l'analisi in loco. In base ai requisiti di calcolo, è possibile aggiungere gestori di nodi e le operazioni non disruptive consentono di aggiungere un controller di storage su richiesta senza tempi di inattività. Offriamo funzionalità avanzate con AFF e FAS, come supporto multimediale NVME, efficienza garantita, riduzione dei dati, QOS, analisi predittiva, cloud tiering, replicazione, distribuzione cloud e sicurezza. Per aiutare i clienti a soddisfare le loro esigenze, NetApp offre funzionalità quali analisi del file system, quote e bilanciamento del carico integrato, senza costi di licenza aggiuntivi. NetApp offre prestazioni migliori in termini di numero di processi contemporanei, latenza inferiore, operazioni più semplici e throughput di gigabyte al secondo più elevato rispetto ai nostri concorrenti. Inoltre, NetApp Cloud Volumes ONTAP è compatibile con tutti e tre i principali provider cloud.
Scalabilità delle prestazioni - Scalabilità verticale
Le funzionalità di scalabilità consentono di aggiungere unità disco ai sistemi AFF, FAS ed E-Series quando è necessaria ulteriore capacità di archiviazione. Con Cloud Volumes ONTAP, il ridimensionamento dello storage al livello PB è una combinazione di due fattori: il livellamento dei dati utilizzati raramente nello storage di oggetti dallo storage a blocchi e l'accumulo di licenze Cloud Volumes ONTAP senza elaborazione aggiuntiva.
Protocolli multipli
I sistemi NetApp supportano la maggior parte dei protocolli per le distribuzioni Hadoop, tra cui SAS, iSCSI, FCP, InfiniBand e NFS.
Soluzioni operative e supportate
Le soluzioni Hadoop descritte in questo documento sono supportate da NetApp. Queste soluzioni sono inoltre certificate dai principali distributori Hadoop. Per informazioni, vedere il "Hortonworks" sito e Cloudera "certificazione" E "partner" siti.