Risultati dei test
 Suggerisci modifiche
Suggerisci modifiche
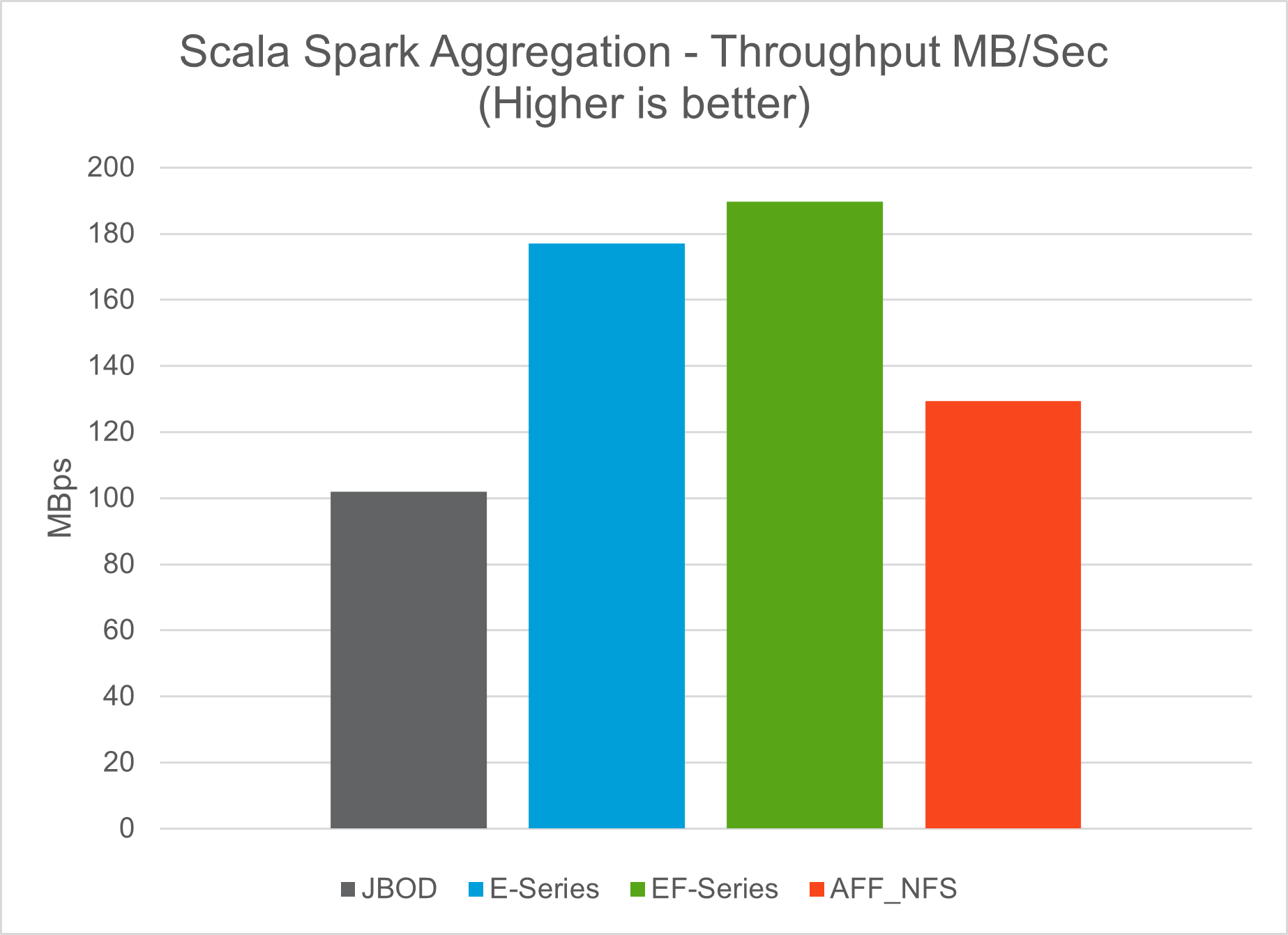
Abbiamo utilizzato gli script TeraSort e TeraValidate nello strumento di benchmarking TeraGen per misurare la convalida delle prestazioni di Spark con le configurazioni E5760, E5724 e AFF-A800. Sono stati inoltre testati tre principali casi d'uso: pipeline Spark NLP e formazione distribuita TensorFlow, formazione distribuita Horovod e apprendimento approfondito multi-worker mediante Keras per la previsione CTR con DeepFM.
Per la convalida di E-Series e StorageGRID , abbiamo utilizzato il fattore di replicazione Hadoop 2. Per la convalida AFF , abbiamo utilizzato una sola fonte di dati.
Nella tabella seguente è elencata la configurazione hardware per la convalida delle prestazioni di Spark.
| Tipo | Nodi worker Hadoop | Tipo di unità | Unità per nodo | Controllore di archiviazione |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
Singola coppia ad alta disponibilità (HA) |
E5760 |
4 |
SAS |
60 |
Singola coppia HA |
E5724 |
4 |
SAS |
24 |
Singola coppia HA |
AFF800 |
4 |
SSD |
6 |
Singola coppia HA |
Nella tabella seguente sono elencati i requisiti software.
| Software | Versione |
|---|---|
RHEL |
7,9 |
Ambiente di runtime OpenJDK |
1.8.0 |
Macchina virtuale server OpenJDK a 64 bit |
25,302 |
Git |
2.24.1 |
GCC/G++ |
11.2.1 |
Scintilla |
3.2.1 |
PySpark |
3.1.2 |
SparkNLP |
3.4.2 |
TensorFlow |
2.9.0 |
Keras |
2.9.0 |
Horovod |
0.24.3 |
Analisi del sentiment finanziario
Abbiamo pubblicato"TR-4910: Analisi del sentiment dalle comunicazioni con i clienti con NetApp AI" , in cui è stata costruita una pipeline di intelligenza artificiale conversazionale end-to-end utilizzando "Kit di strumenti NetApp DataOps" , archiviazione AFF e sistema NVIDIA DGX. La pipeline esegue l'elaborazione del segnale audio in batch, il riconoscimento vocale automatico (ASR), l'apprendimento del trasferimento e l'analisi del sentiment sfruttando il DataOps Toolkit, "NVIDIA Riva SDK" , e il "Quadro Tao" . Estendendo il caso d'uso dell'analisi del sentiment al settore dei servizi finanziari, abbiamo creato un flusso di lavoro SparkNLP, caricato tre modelli BERT per varie attività NLP, come il riconoscimento di entità denominate, e ottenuto il sentiment a livello di frase per le call sugli utili trimestrali delle 10 principali aziende del NASDAQ.
Il seguente script sentiment_analysis_spark. py utilizza il modello FinBERT per elaborare le trascrizioni in HDFS e produrre conteggi di sentiment positivi, neutri e negativi, come mostrato nella tabella seguente:
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
La tabella seguente elenca l'analisi del sentiment a livello di frase, nelle conference call sui risultati finanziari, per le 10 principali società del NASDAQ dal 2016 al 2020.
| Conteggi e percentuali del sentimento | Tutte le 10 aziende | AAPL | AMD | AMZN | CSCO | INTC | MSFT | NVDA | |
|---|---|---|---|---|---|---|---|---|---|
Conteggi positivi |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
Conteggi neutrali |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
Conteggi negativi |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
Conteggi non categorizzati |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(conteggi totali) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
In termini percentuali, la maggior parte delle frasi pronunciate dai CEO e dai CFO sono basate sui fatti e quindi trasmettono un sentimento neutrale. Durante una conference call sui risultati finanziari, gli analisti pongono domande che possono trasmettere un sentimento positivo o negativo. Vale la pena approfondire l'analisi quantitativa di come il sentiment negativo o positivo influenzi i prezzi delle azioni nello stesso giorno di negoziazione o in quello successivo.
Nella tabella seguente è riportata l'analisi del sentiment a livello di frase per le prime 10 aziende del NASDAQ, espressa in percentuale.
| Percentuale di sentimento | Tutte le 10 aziende | AAPL | AMD | AMZN | CSCO | INTC | MSFT | NVDA | |
|---|---|---|---|---|---|---|---|---|---|
Positivo |
10,13% |
18,06% |
8,69% |
5,24% |
9,07% |
12,08% |
11,44% |
13,25% |
6,23% |
Neutro |
87,17% |
79,02% |
88,82% |
91,87% |
88,42% |
86,50% |
84,65% |
83,77% |
92,44% |
Negativo |
2,43% |
2,92% |
2,49% |
1,52% |
2,51% |
1,42% |
3,91% |
2,96% |
1,33% |
Non categorizzato |
0,27% |
0% |
0% |
1,37% |
0% |
0% |
0% |
0,01% |
0% |
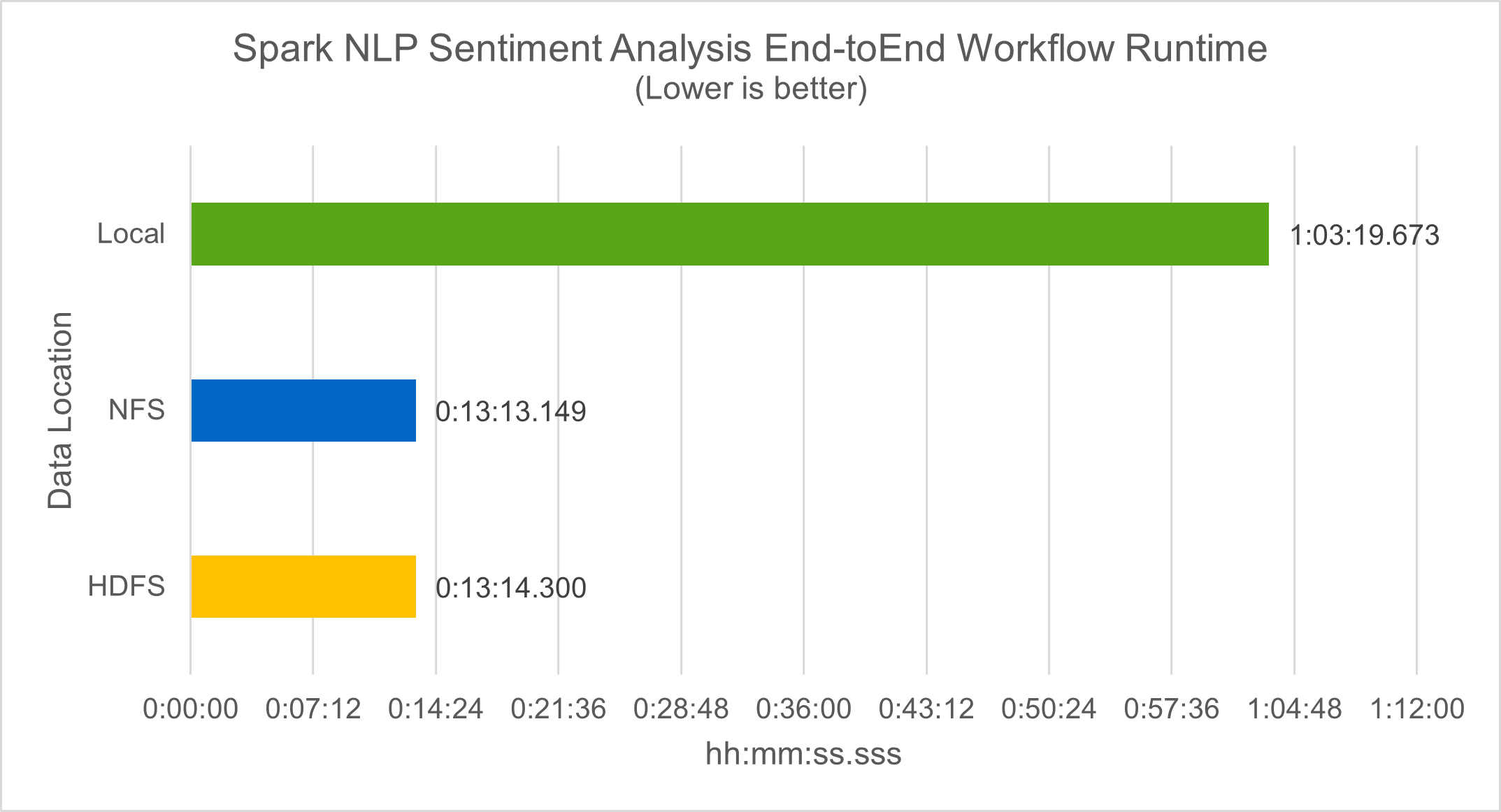
In termini di runtime del flusso di lavoro, abbiamo visto un miglioramento significativo di 4,78 volte rispetto local modalità a un ambiente distribuito in HDFS e un ulteriore miglioramento dello 0,14% sfruttando NFS.
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
Come mostra la figura seguente, il parallelismo dei dati e dei modelli ha migliorato la velocità di elaborazione dei dati e di inferenza del modello distribuito TensorFlow. L'ubicazione dei dati in NFS ha prodotto un tempo di esecuzione leggermente migliore perché il collo di bottiglia del flusso di lavoro è il download dei modelli pre-addestrati. Se aumentiamo la dimensione del dataset delle trascrizioni, il vantaggio di NFS diventa più evidente.
Formazione distribuita con prestazioni Horovod
Il seguente comando ha prodotto informazioni di runtime e un file di registro nel nostro cluster Spark utilizzando un singolo master nodo con 160 esecutori, ciascuno con un core. La memoria dell'esecutore è stata limitata a 5 GB per evitare errori di memoria insufficiente. Vedi la sezione"Script Python per ogni caso d'uso principale" per maggiori dettagli riguardanti l'elaborazione dei dati, l'addestramento del modello e il calcolo dell'accuratezza del modello in keras_spark_horovod_rossmann_estimator.py .
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
Il tempo di esecuzione risultante con dieci epoche di addestramento è stato il seguente:
real43m34.608s user12m22.057s sys2m30.127s
Ci sono voluti più di 43 minuti per elaborare i dati di input, addestrare un modello DNN, calcolare l'accuratezza e produrre i checkpoint TensorFlow e un file CSV per i risultati delle previsioni. Abbiamo limitato il numero di epoche di addestramento a 10, che nella pratica è spesso impostato su 100 per garantire una precisione soddisfacente del modello. Il tempo di addestramento in genere varia in modo lineare con il numero di epoche.
Successivamente abbiamo utilizzato i quattro nodi worker disponibili nel cluster ed eseguito lo stesso script in yarn modalità con dati in HDFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
Il tempo di esecuzione risultante è stato migliorato come segue:
real8m13.728s user7m48.421s sys1m26.063s
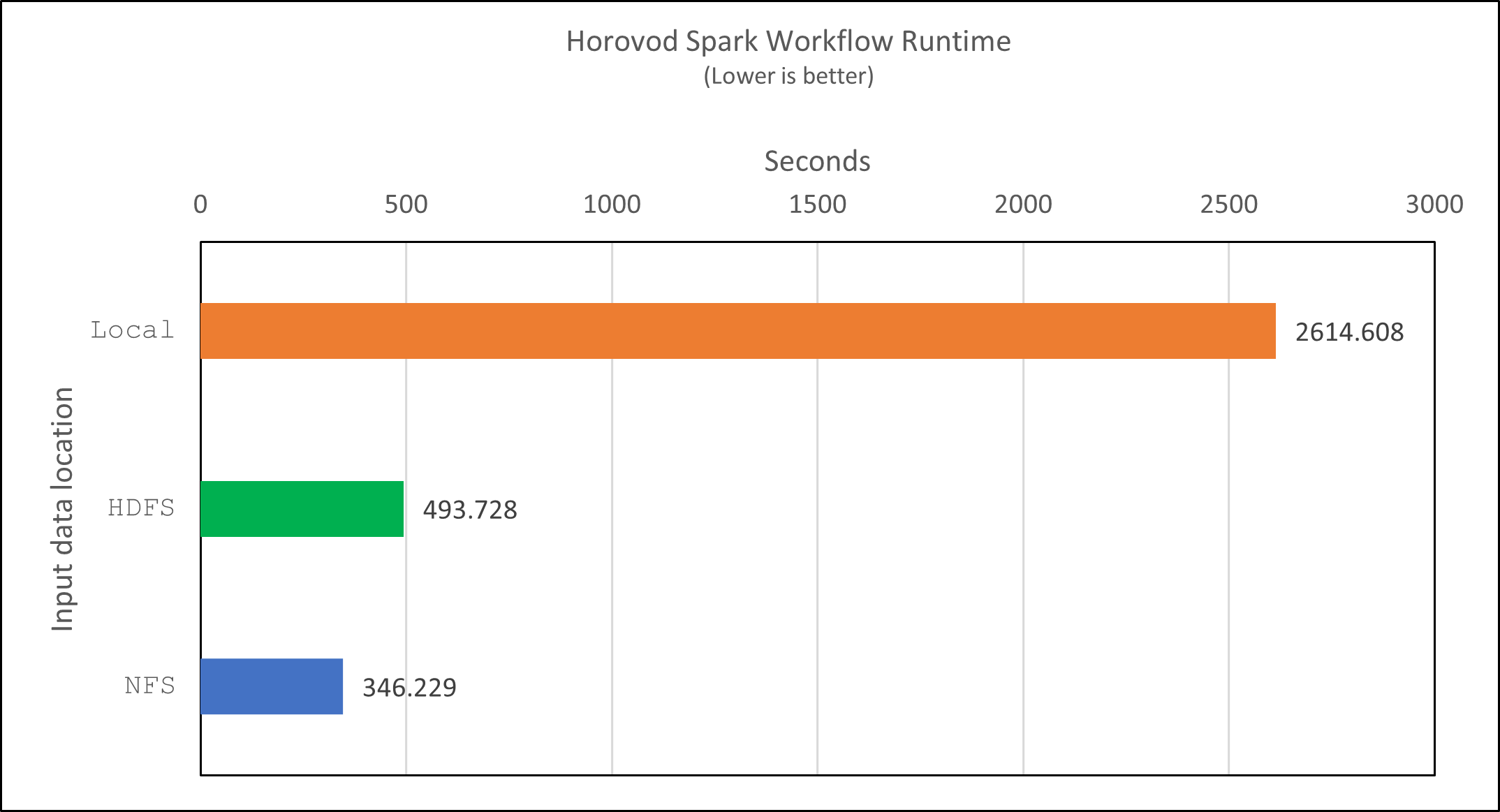
Con il modello di Horovod e il parallelismo dei dati in Spark, abbiamo visto un'accelerazione del runtime di 5,29 volte yarn contro local modalità con dieci epoche di allenamento. Ciò è mostrato nella figura seguente con le legende HDFS E Local . L'addestramento del modello DNN TensorFlow sottostante può essere ulteriormente accelerato con le GPU, se disponibili. Abbiamo intenzione di condurre questi test e di pubblicare i risultati in un futuro rapporto tecnico.
Il nostro test successivo ha confrontato i tempi di esecuzione con dati di input residenti in NFS rispetto a HDFS. Il volume NFS sull'AFF AFF A800 è stato montato su /sparkdemo/horovod attraverso i cinque nodi (un master, quattro worker) nel nostro cluster Spark. Abbiamo eseguito un comando simile a quello dei test precedenti, con il --data- dir parametro che ora punta al montaggio NFS:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
Il runtime risultante con NFS era il seguente:
real 5m46.229s user 5m35.693s sys 1m5.615s
Si è verificato un ulteriore aumento di velocità di 1,43 volte, come mostrato nella figura seguente. Pertanto, con uno storage all-flash NetApp connesso al proprio cluster, i clienti possono usufruire dei vantaggi di un rapido trasferimento e distribuzione dei dati per i flussi di lavoro di Horovod Spark, ottenendo una velocità 7,55 volte superiore rispetto all'esecuzione su un singolo nodo.
Modelli di apprendimento profondo per le prestazioni di previsione del CTR
Per i sistemi di raccomandazione progettati per massimizzare il CTR, è necessario apprendere le interazioni sofisticate delle funzionalità alla base dei comportamenti degli utenti, che possono essere calcolate matematicamente dal livello più basso a quello più alto. Per un buon modello di deep learning, sia le interazioni tra le caratteristiche di ordine basso che quelle di ordine alto dovrebbero essere ugualmente importanti, senza sbilanciarsi verso l'una o l'altra. Deep Factorization Machine (DeepFM), una rete neurale basata su macchine di fattorizzazione, combina macchine di fattorizzazione per la raccomandazione e apprendimento profondo per l'apprendimento delle caratteristiche in una nuova architettura di rete neurale.
Sebbene le macchine di fattorizzazione convenzionali modellino le interazioni delle caratteristiche a coppie come un prodotto interno di vettori latenti tra caratteristiche e possano teoricamente catturare informazioni di ordine elevato, in pratica, gli esperti di apprendimento automatico solitamente utilizzano solo interazioni delle caratteristiche di secondo ordine a causa dell'elevata complessità di calcolo e di archiviazione. Varianti di reti neurali profonde come quelle di Google "Modelli larghi e profondi" d'altro canto, apprende interazioni sofisticate tra le caratteristiche in una struttura di rete ibrida combinando un modello lineare ampio e un modello profondo.
Questo modello Wide & Deep prevede due input, uno per il modello wide sottostante e l'altro per quello deep; quest'ultima parte richiede ancora un'ingegneria delle funzionalità da parte di esperti e rende quindi la tecnica meno generalizzabile ad altri domini. A differenza del modello Wide & Deep, DeepFM può essere addestrato in modo efficiente con feature grezze senza alcuna progettazione delle feature, poiché la sua parte ampia e quella profonda condividono lo stesso input e lo stesso vettore di incorporamento.
Abbiamo prima elaborato il Criteo train.txt (11 GB) file in un file CSV denominato ctr_train.csv memorizzato in un mount NFS /sparkdemo/tr-4570-data usando run_classification_criteo_spark.py dalla sezione"Script Python per ogni caso d'uso principale." All'interno di questo script, la funzione process_input_file esegue diversi metodi stringa per rimuovere le tabulazioni e inserirle ',' come delimitatore e '\n' come nuova riga. Nota che devi elaborare solo l'originale train.txt una volta, in modo che il blocco di codice venga visualizzato come commento.
Per i seguenti test di diversi modelli DL, abbiamo utilizzato ctr_train.csv come file di input. Nelle successive esecuzioni di test, il file CSV di input è stato letto in uno Spark DataFrame con schema contenente un campo di 'label' , caratteristiche dense intere ['I1', 'I2', 'I3', …, 'I13'] e caratteristiche sparse ['C1', 'C2', 'C3', …, 'C26'] . Il seguente spark-submit il comando accetta un CSV di input, addestra i modelli DeepFM con una suddivisione del 20% per la convalida incrociata e sceglie il modello migliore dopo dieci epoche di addestramento per calcolare l'accuratezza della previsione sul set di test:
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
Si noti che poiché il file di dati ctr_train.csv è superiore a 11 GB, è necessario impostare un numero sufficiente spark.driver.maxResultSize maggiore della dimensione del set di dati per evitare errori.
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
In quanto sopra SparkSession.builder configurazione che abbiamo anche abilitato "Freccia Apache" , che converte uno Spark DataFrame in un Pandas DataFrame con df.toPandas() metodo.
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
Dopo la suddivisione casuale, ci sono oltre 36 milioni di righe nel set di dati di addestramento e 9 milioni di campioni nel set di test:
Training dataset size = 36672493 Testing dataset size = 9168124
Poiché questo report tecnico è incentrato sui test della CPU senza l'utilizzo di GPU, è fondamentale compilare TensorFlow con flag di compilazione appropriati. Questo passaggio evita di richiamare librerie accelerate dalla GPU e sfrutta appieno le Advanced Vector Extensions (AVX) e le istruzioni AVX2 di TensorFlow. Queste funzionalità sono progettate per calcoli algebrici lineari come l'addizione vettorizzata, le moltiplicazioni di matrici all'interno di un addestramento DNN feed-forward o back-propagation. L'istruzione Fused Multiply Add (FMA) disponibile con AVX2 che utilizza registri in virgola mobile (FP) a 256 bit è ideale per codice intero e tipi di dati, con un conseguente aumento della velocità fino a 2 volte. Per il codice FP e i tipi di dati, AVX2 raggiunge un aumento di velocità dell'8% rispetto ad AVX.
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Per creare TensorFlow dalla sorgente, NetApp consiglia di utilizzare "Bazel" . Per il nostro ambiente, abbiamo eseguito i seguenti comandi nel prompt della shell per installare dnf , dnf-plugins e Bazel.
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
È necessario abilitare GCC 5 o versioni successive per utilizzare le funzionalità C++17 durante il processo di compilazione, fornite da RHEL con Software Collections Library (SCL). I seguenti comandi installano devtoolset e GCC 11.2.1 sul nostro cluster RHEL 7.9:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
Nota che gli ultimi due comandi abilitano devtoolset-11 , che utilizza /opt/rh/devtoolset-11/root/usr/bin/gcc (GCC 11.2.1). Inoltre, assicurati che il tuo git la versione è successiva alla 1.8.3 (inclusa in RHEL 7.9). Fare riferimento a questo "articolo" per l'aggiornamento git a 2.24.1.
Supponiamo che tu abbia già clonato l'ultimo repository master di TensorFlow. Quindi crea un workspace directory con un WORKSPACE file per compilare TensorFlow dal codice sorgente con AVX, AVX2 e FMA. Esegui il configure file e specificare la posizione corretta del binario Python. "CUDA" è disabilitato per i nostri test perché non abbiamo utilizzato una GPU. UN .bazelrc il file viene generato in base alle tue impostazioni. Inoltre, abbiamo modificato il file e impostato build --define=no_hdfs_support=false per abilitare il supporto HDFS. Fare riferimento a .bazelrc nella sezione"Script Python per ogni caso d'uso principale," per un elenco completo delle impostazioni e dei flag.
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
Dopo aver creato TensorFlow con i flag corretti, esegui lo script seguente per elaborare il set di dati Criteo Display Ads, addestrare un modello DeepFM e calcolare l'area sotto la curva ROC (AUC) dai punteggi di previsione.
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
Dopo dieci epoche di addestramento, abbiamo ottenuto il punteggio AUC sul set di dati di test:
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
In modo simile ai casi d'uso precedenti, abbiamo confrontato il runtime del flusso di lavoro Spark con dati residenti in posizioni diverse. La figura seguente mostra un confronto della previsione CTR del deep learning per un runtime di flussi di lavoro Spark.