

Soluzione di spostamento dati
 Suggerisci modifiche
Suggerisci modifiche
In un cluster Big Data, i dati vengono archiviati in HDFS o HCFS, come MapR-FS, Windows Azure Storage Blob, S3 o il file system di Google. Abbiamo eseguito test con HDFS, MapR-FS e S3 come origine per copiare i dati nell'esportazione NFS NetApp ONTAP con l'aiuto di NIPAM utilizzando hadoop distcp comando dalla sorgente.
Il diagramma seguente illustra il tipico spostamento dei dati da un cluster Spark in esecuzione con storage HDFS a un volume NetApp ONTAP NFS in modo che NVIDIA possa elaborare le operazioni di intelligenza artificiale.
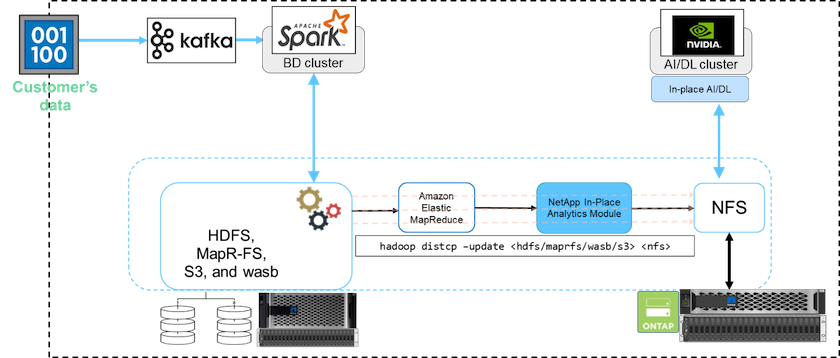
IL hadoop distcp Il comando utilizza il programma MapReduce per copiare i dati. NIPAM funziona con MapReduce per fungere da driver per il cluster Hadoop durante la copia dei dati. NIPAM può distribuire un carico su più interfacce di rete per una singola esportazione. Questo processo massimizza la produttività della rete distribuendo i dati su più interfacce di rete quando si copiano i dati da HDFS o HCFS a NFS.

|
NIPAM non è supportato né certificato con MapR. |