TR-4912: Linee guida sulle best practice per l'archiviazione a livelli Confluent Kafka con NetApp
 Suggerisci modifiche
Suggerisci modifiche
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluent
Apache Kafka è una piattaforma di streaming di eventi distribuita dalla comunità, in grado di gestire migliaia di miliardi di eventi al giorno. Inizialmente concepito come una coda di messaggistica, Kafka si basa su un'astrazione di un registro di commit distribuito. Da quando è stato creato e reso open source da LinkedIn nel 2011, Kafka si è evoluto da una coda di messaggi a una piattaforma di streaming di eventi a tutti gli effetti. Confluent fornisce la distribuzione di Apache Kafka tramite la piattaforma Confluent. La piattaforma Confluent integra Kafka con funzionalità aggiuntive per la comunità e commerciali, progettate per migliorare l'esperienza di streaming sia degli operatori che degli sviluppatori in produzione su larga scala.
Questo documento descrive le linee guida sulle best practice per l'utilizzo di Confluent Tiered Storage su un'offerta di storage a oggetti di NetApp, fornendo i seguenti contenuti:
-
Verifica confluente con NetApp Object Storage – NetApp StorageGRID
-
Test delle prestazioni di archiviazione a livelli
-
Linee guida sulle best practice per Confluent sui sistemi di storage NetApp
Perché Confluent Tiered Storage?
Confluent è diventata la piattaforma di streaming in tempo reale predefinita per molte applicazioni, in particolare per i carichi di lavoro di big data, analisi e streaming. Tiered Storage consente agli utenti di separare l'elaborazione dall'archiviazione nella piattaforma Confluent. Rende l'archiviazione dei dati più conveniente, consente di archiviare quantità di dati praticamente infinite e di aumentare (o diminuire) i carichi di lavoro su richiesta, semplificando inoltre le attività amministrative come il ribilanciamento dei dati e dei tenant. I sistemi di archiviazione compatibili con S3 possono sfruttare tutte queste funzionalità per democratizzare i dati con tutti gli eventi in un unico posto, eliminando la necessità di una complessa ingegneria dei dati. Per maggiori informazioni sul motivo per cui dovresti utilizzare l'archiviazione a livelli per Kafka, controlla"questo articolo di Confluent" .
NetApp instaclustr supporta anche Kafka con storage a livelli dalla versione 3.8.1. Per maggiori dettagli, consultare qui "instaclust utilizzando l'archiviazione a livelli Kafka"
Perché NetApp StorageGRID per l'archiviazione a livelli?
StorageGRID è una piattaforma di archiviazione di oggetti leader del settore di NetApp. StorageGRID è una soluzione di archiviazione basata su oggetti e definita dal software che supporta le API di oggetti standard del settore, tra cui l'API Amazon Simple Storage Service (S3). StorageGRID archivia e gestisce dati non strutturati su larga scala per fornire un archivio di oggetti sicuro e durevole. I contenuti vengono posizionati nel posto giusto, al momento giusto e sul livello di archiviazione corretto, ottimizzando i flussi di lavoro e riducendo i costi per i rich media distribuiti a livello globale.
Il principale elemento di differenziazione di StorageGRID è il suo motore di policy Information Lifecycle Management (ILM), che consente la gestione del ciclo di vita dei dati basata su policy. Il motore delle policy può utilizzare i metadati per gestire il modo in cui i dati vengono archiviati durante il loro ciclo di vita, ottimizzando inizialmente le prestazioni e ottimizzando automaticamente i costi e la durabilità man mano che i dati invecchiano.
Abilitazione dell'archiviazione a livelli confluenti
L'idea di base dell'archiviazione a livelli è quella di separare le attività di archiviazione dei dati da quelle di elaborazione degli stessi. Grazie a questa separazione, diventa molto più semplice per il livello di archiviazione dei dati e per il livello di elaborazione dei dati scalare in modo indipendente.
Una soluzione di archiviazione a livelli per Confluent deve tenere conto di due fattori. Innanzitutto, deve aggirare o evitare le proprietà comuni di coerenza e disponibilità dell'archivio oggetti, come incongruenze nelle operazioni LIST e occasionali indisponibilità degli oggetti. In secondo luogo, deve gestire correttamente l'interazione tra l'archiviazione a livelli e il modello di replicazione e tolleranza agli errori di Kafka, inclusa la possibilità che i leader zombie continuino a suddividere gli intervalli di offset. L'archiviazione di oggetti NetApp garantisce sia la disponibilità costante degli oggetti sia il modello HA che rende l'archiviazione obsoleta disponibile per intervalli di offset di livello. Lo storage di oggetti NetApp garantisce una disponibilità costante degli oggetti e un modello HA per rendere lo storage obsoleto disponibile per intervalli di offset di livello.
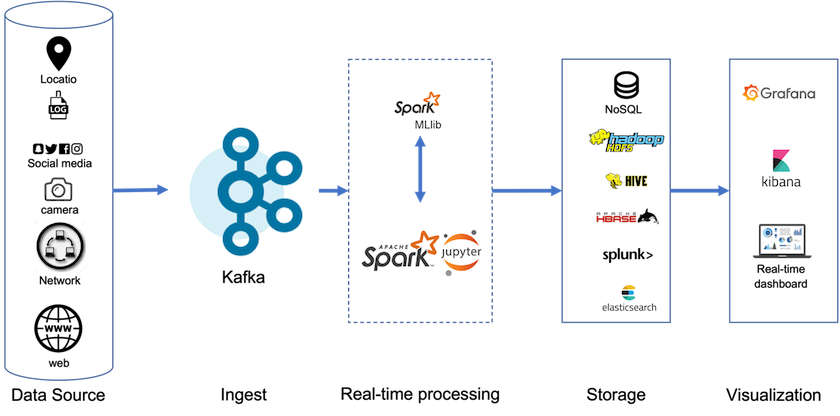
Con l'archiviazione a livelli, puoi utilizzare piattaforme ad alte prestazioni per letture e scritture a bassa latenza in prossimità della coda dei dati in streaming, e puoi anche utilizzare archivi di oggetti più economici e scalabili come NetApp StorageGRID per letture storiche ad alta velocità. Disponiamo anche di una soluzione tecnica per Spark con il controller di archiviazione NetApp; i dettagli sono disponibili qui. La figura seguente mostra come Kafka si inserisce in una pipeline di analisi in tempo reale.
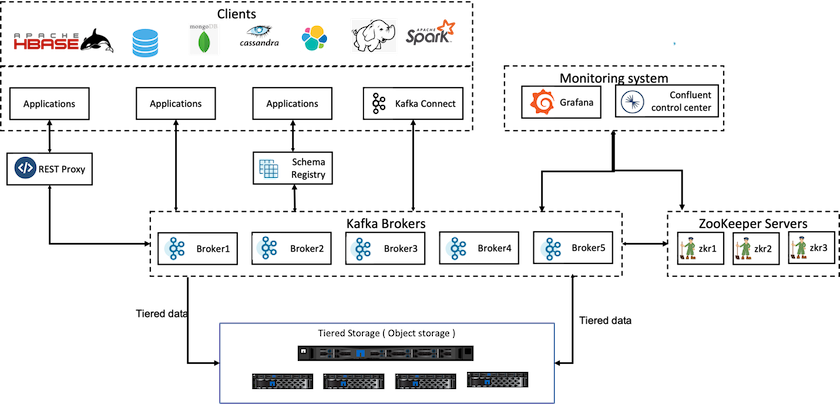
La figura seguente illustra come NetApp StorageGRID si inserisce come livello di archiviazione degli oggetti di Confluent Kafka.