

Caso d'uso 1: backup dei dati Hadoop
 Suggerisci modifiche
Suggerisci modifiche
In questo scenario, il cliente dispone di un ampio repository Hadoop in sede e desidera eseguirne il backup per scopi di disaster recovery. Tuttavia, l'attuale soluzione di backup del cliente è costosa e presenta una finestra di backup lunga, superiore alle 24 ore.
Requisiti e sfide
I principali requisiti e sfide per questo caso d'uso includono:
-
Compatibilità con le versioni precedenti del software:
-
La soluzione di backup alternativa proposta dovrebbe essere compatibile con le attuali versioni software in esecuzione utilizzate nel cluster Hadoop di produzione.
-
-
Per rispettare gli SLA assunti, la soluzione alternativa proposta dovrebbe garantire RPO e RTO molto bassi.
-
Il backup creato dalla soluzione di backup NetApp può essere utilizzato nel cluster Hadoop creato localmente nel data center, nonché nel cluster Hadoop in esecuzione nella posizione di disaster recovery nel sito remoto.
-
La soluzione proposta deve essere conveniente.
-
La soluzione proposta deve ridurre l'impatto sulle prestazioni dei processi di analisi in produzione attualmente in esecuzione durante i tempi di backup.
Soluzione di backup esistente del clientex
La figura seguente mostra la soluzione di backup nativa originale di Hadoop.
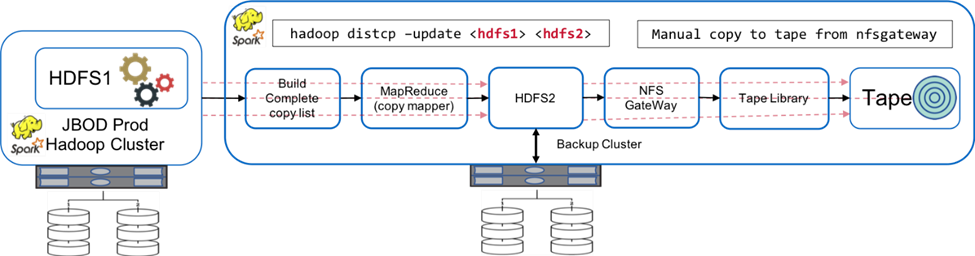
I dati di produzione sono protetti su nastro tramite il cluster di backup intermedio:
-
I dati HDFS1 vengono copiati in HDFS2 eseguendo il comando
hadoop distcp -update <hdfs1> <hdfs2>comando. -
Il cluster di backup funge da gateway NFS e i dati vengono copiati manualmente su nastro tramite Linux
cpcomando tramite la libreria a nastro.
I vantaggi della soluzione di backup nativa Hadoop originale includono:
-
La soluzione si basa sui comandi nativi di Hadoop, evitando all'utente di dover apprendere nuove procedure.
-
La soluzione sfrutta l'architettura e l'hardware standard del settore.
Gli svantaggi della soluzione di backup nativa Hadoop originale includono:
-
La finestra temporale di backup è lunga e supera le 24 ore, rendendo vulnerabili i dati di produzione.
-
Notevole degrado delle prestazioni del cluster durante i tempi di backup.
-
La copia su nastro è un processo manuale.
-
La soluzione di backup è costosa in termini di hardware richiesto e di ore di lavoro umano necessarie per i processi manuali.
Soluzioni di backup
Sulla base di queste sfide e requisiti, e tenendo in considerazione il sistema di backup esistente, sono state suggerite tre possibili soluzioni di backup. Le seguenti sottosezioni descrivono ciascuna di queste tre diverse soluzioni di backup, denominate dalla soluzione A alla soluzione C.
Soluzione A
Nella soluzione A, il cluster Hadoop di backup invia i backup secondari ai sistemi di archiviazione NFS NetApp , eliminando il requisito del nastro, come mostrato nella figura seguente.
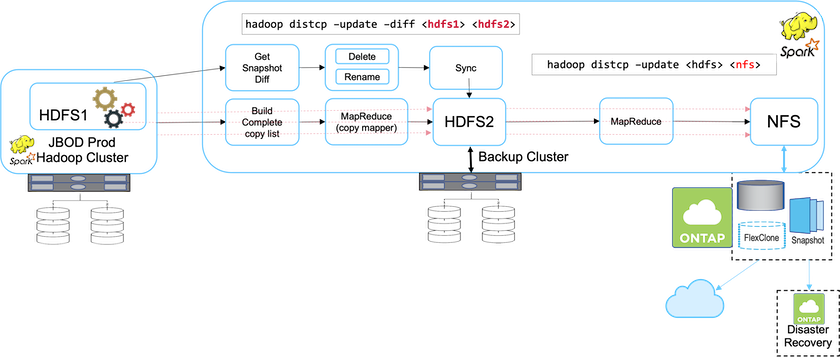
I compiti dettagliati per la soluzione A includono:
-
Il cluster Hadoop di produzione contiene i dati analitici del cliente nell'HDFS che necessitano di protezione.
-
Il cluster Hadoop di backup con HDFS funge da posizione intermedia per i dati. Just a bunch of disks (JBOD) fornisce lo storage per HDFS sia nei cluster Hadoop di produzione che di backup.
-
Proteggere i dati di produzione Hadoop dal cluster di produzione HDFS al cluster di backup HDFS eseguendo il
Hadoop distcp –update –diff <hdfs1> <hdfs2>comando.

|
Lo snapshot Hadoop viene utilizzato per proteggere i dati dalla produzione al cluster Hadoop di backup. |
-
Il controller di archiviazione NetApp ONTAP fornisce un volume esportato NFS, che viene fornito al cluster Hadoop di backup.
-
Eseguendo il
Hadoop distcpcomando che sfrutta MapReduce e più mapper, i dati analitici vengono protetti dal cluster Hadoop di backup su NFS.Dopo che i dati sono stati archiviati in NFS sul sistema di archiviazione NetApp , le tecnologie NetApp Snapshot, SnapRestore e FlexClone vengono utilizzate per eseguire il backup, il ripristino e la duplicazione dei dati Hadoop secondo necessità.
|
|
I dati Hadoop possono essere protetti sia nel cloud che in posizioni di disaster recovery utilizzando la tecnologia SnapMirror . |
I vantaggi della soluzione A includono:
-
I dati di produzione Hadoop sono protetti dal cluster di backup.
-
I dati HDFS sono protetti tramite NFS, consentendo la protezione verso posizioni cloud e di disaster recovery.
-
Migliora le prestazioni trasferendo le operazioni di backup al cluster di backup.
-
Elimina le operazioni manuali sul nastro
-
Consente funzioni di gestione aziendale tramite strumenti NetApp .
-
Richiede modifiche minime all'ambiente esistente.
-
È una soluzione conveniente.
Lo svantaggio di questa soluzione è che richiede un cluster di backup e mapper aggiuntivi per migliorare le prestazioni.
Il cliente ha recentemente implementato la soluzione A per la sua semplicità, il costo e le prestazioni complessive.
In questa soluzione è possibile utilizzare dischi SAN di ONTAP al posto di JBOD. Questa opzione scarica il carico di archiviazione del cluster di backup su ONTAP; tuttavia, lo svantaggio è che sono necessari switch fabric SAN.
Soluzione B
La soluzione B aggiunge un volume NFS al cluster Hadoop di produzione, eliminando la necessità del cluster Hadoop di backup, come mostrato nella figura seguente.
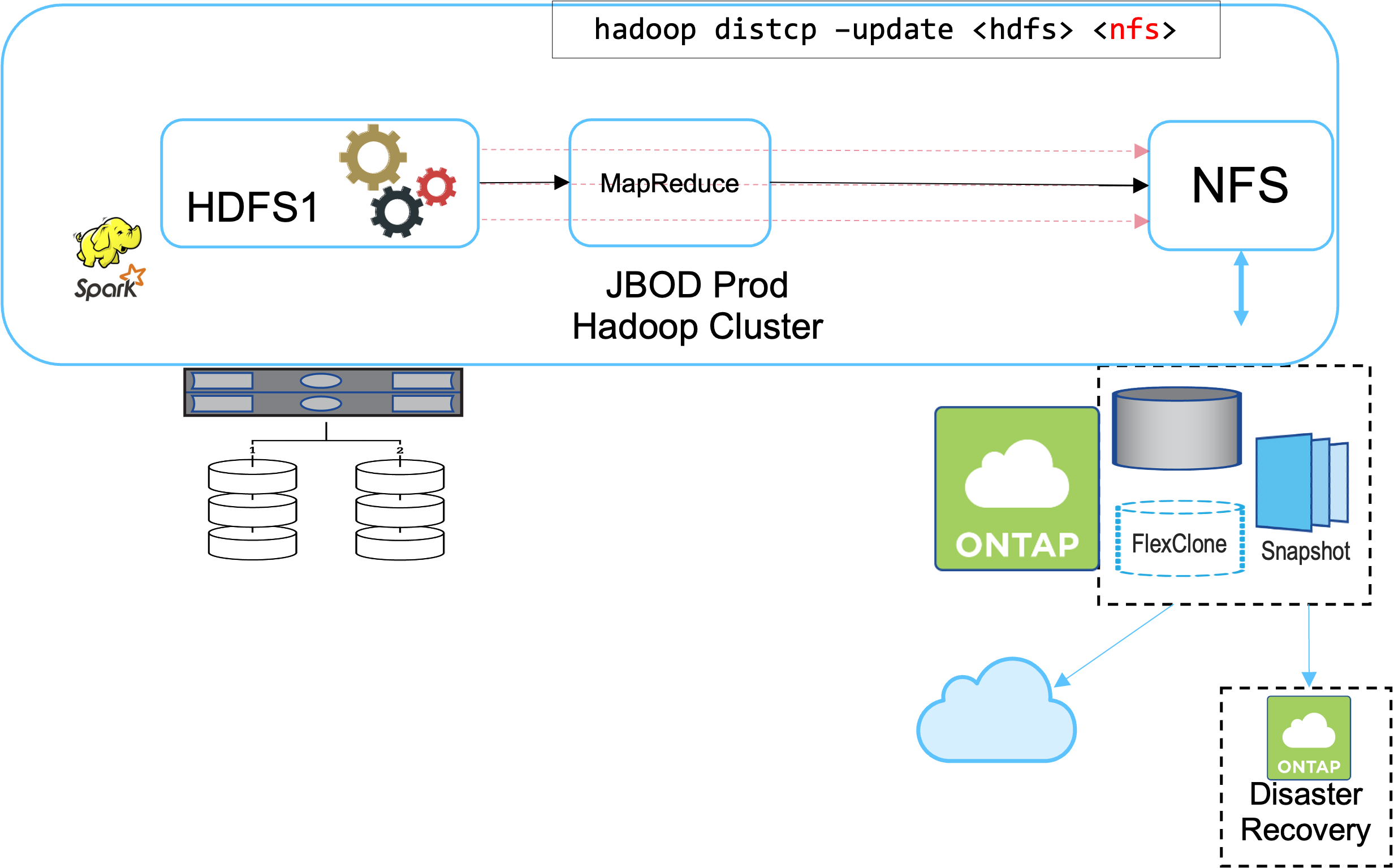
I compiti dettagliati per la soluzione B includono:
-
Il controller di archiviazione NetApp ONTAP esegue l'esportazione NFS nel cluster Hadoop di produzione.
Il nativo di Hadoop
hadoop distcpIl comando protegge i dati Hadoop dal cluster di produzione HDFS a NFS. -
Dopo che i dati sono stati archiviati in NFS sul sistema di archiviazione NetApp , le tecnologie Snapshot, SnapRestore e FlexClone vengono utilizzate per eseguire il backup, il ripristino e la duplicazione dei dati Hadoop secondo necessità.
I vantaggi della soluzione B includono:
-
Il cluster di produzione è leggermente modificato per la soluzione di backup, il che semplifica l'implementazione e riduce i costi aggiuntivi dell'infrastruttura.
-
Non è necessario un cluster di backup per l'operazione di backup.
-
I dati di produzione HDFS sono protetti durante la conversione in dati NFS.
-
La soluzione consente funzioni di gestione aziendale tramite gli strumenti NetApp .
Lo svantaggio di questa soluzione è che viene implementata nel cluster di produzione, il che può aggiungere ulteriori attività amministrative nel cluster di produzione.
Soluzione C
Nella soluzione C, i volumi SAN NetApp vengono forniti direttamente al cluster di produzione Hadoop per l'archiviazione HDFS, come mostrato nella figura seguente.
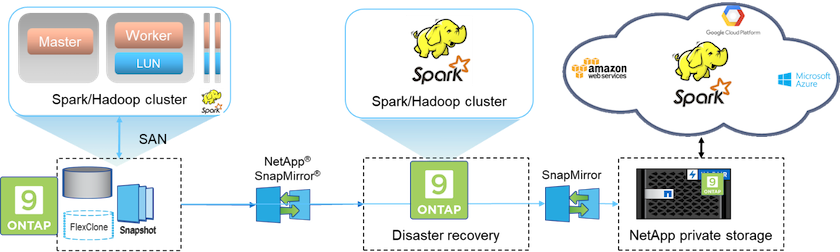
I passaggi dettagliati per la soluzione C includono:
-
Lo storage NetApp ONTAP SAN è predisposto nel cluster Hadoop di produzione per l'archiviazione dei dati HDFS.
-
Per eseguire il backup dei dati HDFS dal cluster Hadoop di produzione vengono utilizzate le tecnologie NetApp Snapshot e SnapMirror .
-
Non vi è alcun effetto sulle prestazioni di produzione per il cluster Hadoop/Spark durante il processo di backup della copia snapshot perché il backup avviene a livello di archiviazione.
|
|
La tecnologia snapshot fornisce backup che vengono completati in pochi secondi, indipendentemente dalle dimensioni dei dati. |
I vantaggi della soluzione C includono:
-
È possibile creare un backup efficiente in termini di spazio utilizzando la tecnologia Snapshot.
-
Consente funzioni di gestione aziendale tramite strumenti NetApp .