

Verifica confluente
 Suggerisci modifiche
Suggerisci modifiche
Abbiamo eseguito la verifica con Confluent Platform 6.2 Tiered Storage in NetApp StorageGRID. I team NetApp e Confluent hanno lavorato insieme a questa verifica ed eseguito i casi di test richiesti per la verifica.
Configurazione della piattaforma Confluent
Per la verifica abbiamo utilizzato la seguente configurazione.
Per la verifica, abbiamo utilizzato tre guardiani dello zoo, cinque broker, cinque server di esecuzione di script di test, server di strumenti denominati con 256 GB di RAM e 16 CPU. Per l'archiviazione NetApp , abbiamo utilizzato StorageGRID con un bilanciatore di carico SG1000 con quattro SGF6024. Lo storage e i broker erano collegati tramite connessioni 100GbE.
La figura seguente mostra la topologia di rete della configurazione utilizzata per la verifica Confluent.
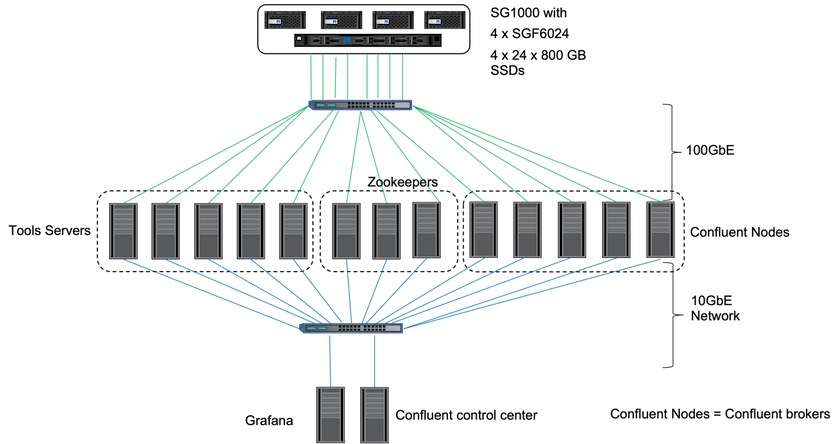
I server degli strumenti agiscono come client applicativi che inviano richieste ai nodi Confluent.
Configurazione di archiviazione a livelli confluenti
La configurazione dell'archiviazione a livelli richiede i seguenti parametri in Kafka:
Confluent.tier.archiver.num.threads=16 confluent.tier.fetcher.num.threads=32 confluent.tier.enable=true confluent.tier.feature=true confluent.tier.backend=S3 confluent.tier.s3.bucket=kafkasgdbucket1-2 confluent.tier.s3.region=us-west-2 confluent.tier.s3.cred.file.path=/data/kafka/.ssh/credentials confluent.tier.s3.aws.endpoint.override=http://kafkasgd.rtpppe.netapp.com:10444/ confluent.tier.s3.force.path.style.access=true
Per la verifica abbiamo utilizzato StorageGRID con il protocollo HTTP, ma funziona anche HTTPS. La chiave di accesso e la chiave segreta sono memorizzate nel nome del file fornito nel confluent.tier.s3.cred.file.path parametro.
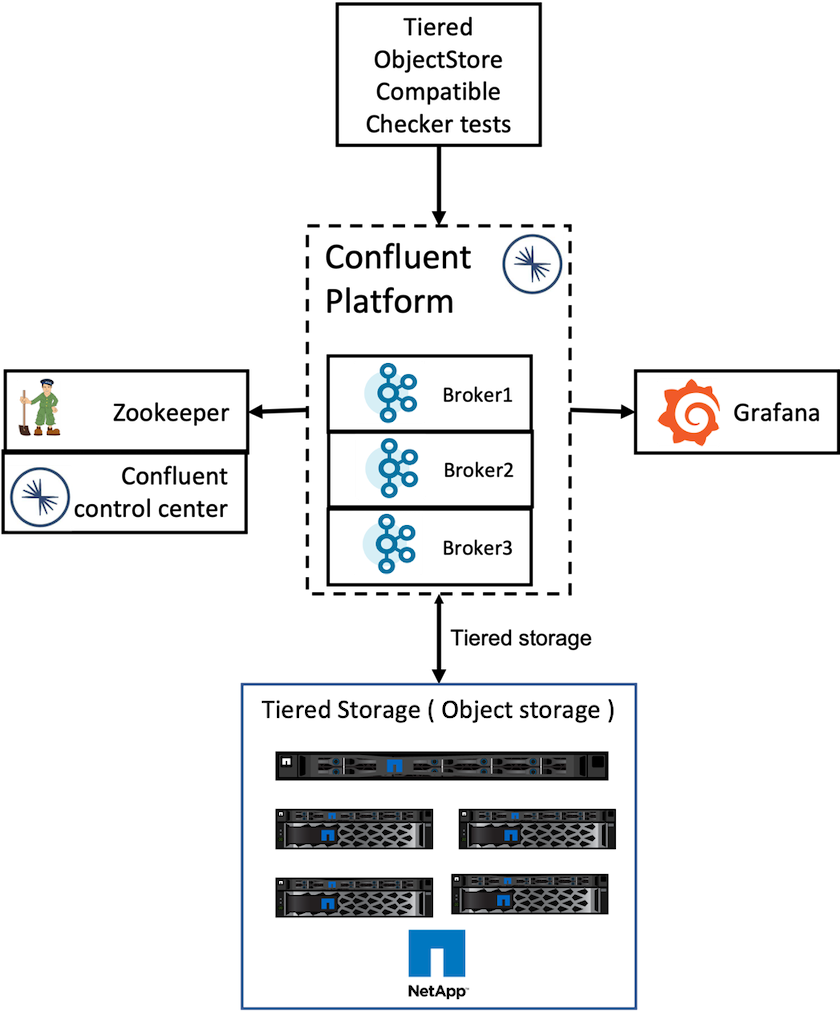
Archiviazione di oggetti NetApp - StorageGRID
Abbiamo configurato la configurazione a sito singolo in StorageGRID per la verifica.
Test di verifica
Per la verifica abbiamo completato i seguenti cinque casi di test. Questi test vengono eseguiti sul framework Trogdor. I primi due erano test di funzionalità, mentre i restanti tre erano test di prestazioni.
Test di correttezza dell'archivio oggetti
Questo test determina se tutte le operazioni di base (ad esempio, get/put/delete) sull'API dell'archivio oggetti funzionano bene in base alle esigenze dell'archiviazione a livelli. Si tratta di un test di base che ogni servizio di archiviazione di oggetti dovrebbe aspettarsi di superare prima dei test successivi. È un test assertivo che può essere superato o fallito.
Test di correttezza della funzionalità di tiering
Questo test determina se la funzionalità di archiviazione a livelli end-to-end funziona bene con un test assertivo che può avere esito positivo o negativo. Il test crea un argomento di prova che per impostazione predefinita è configurato con il tiering abilitato e una dimensione dell'hotset molto ridotta. Produce un flusso di eventi per l'argomento di test appena creato, attende che i broker archivino i segmenti nell'archivio oggetti, quindi consuma il flusso di eventi e convalida che il flusso consumato corrisponda al flusso prodotto. Il numero di messaggi prodotti nel flusso di eventi è configurabile, il che consente all'utente di generare un carico di lavoro sufficientemente ampio in base alle esigenze di test. La dimensione ridotta dell'hotset garantisce che i recuperi dei consumatori al di fuori del segmento attivo vengano serviti solo dall'archivio oggetti; ciò aiuta a verificare la correttezza dell'archivio oggetti per le letture. Abbiamo eseguito questo test con e senza un'iniezione di errore nell'archivio oggetti. Abbiamo simulato un guasto del nodo arrestando il servizio di gestione dei servizi in uno dei nodi in StorageGRID e verificando che la funzionalità end-to-end funzioni con l'archiviazione di oggetti.
Benchmark di recupero dei livelli
Questo test ha convalidato le prestazioni di lettura dell'archiviazione di oggetti a livelli e ha controllato le richieste di lettura di recupero dell'intervallo sotto carico pesante dai segmenti generati dal benchmark. In questo benchmark, Confluent ha sviluppato client personalizzati per soddisfare le richieste di recupero dei livelli.
Benchmark del carico di lavoro produzione-consumo
Questo test ha generato indirettamente un carico di lavoro di scrittura sull'archivio oggetti tramite l'archiviazione dei segmenti. Il carico di lavoro di lettura (segmenti letti) è stato generato dall'archiviazione degli oggetti quando i gruppi di consumatori hanno recuperato i segmenti. Questo carico di lavoro è stato generato dallo script di test. Questo test ha verificato le prestazioni di lettura e scrittura sull'archiviazione di oggetti in thread paralleli. Abbiamo eseguito i test con e senza l'inserimento di errori nell'archivio oggetti, come abbiamo fatto per il test di correttezza della funzionalità di tiering.
Benchmark del carico di lavoro di conservazione
Questo test ha verificato le prestazioni di eliminazione di un archivio oggetti in presenza di un carico di lavoro di conservazione degli argomenti elevato. Il carico di lavoro di conservazione è stato generato utilizzando uno script di test che produce molti messaggi in parallelo a un argomento di test. L'argomento del test era la configurazione con un'impostazione di conservazione aggressiva basata sulle dimensioni e sul tempo, che causava la continua eliminazione del flusso di eventi dall'archivio oggetti. I segmenti vennero poi archiviati. Ciò ha portato a un gran numero di eliminazioni nell'archivio oggetti da parte del broker e alla raccolta delle prestazioni delle operazioni di eliminazione dell'archivio oggetti.