

Panoramica e convalida delle prestazioni con AFF A900 in locale
 Suggerisci modifiche
Suggerisci modifiche
In locale, abbiamo utilizzato il controller di storage NetApp AFF A900 con ONTAP 9.12.1RC1 per convalidare le prestazioni e la scalabilità di un cluster Kafka. Abbiamo utilizzato lo stesso banco di prova delle nostre precedenti best practice di archiviazione a livelli con ONTAP e AFF.
Abbiamo utilizzato Confluent Kafka 6.2.0 per valutare l' AFF A900. Il cluster è composto da otto nodi broker e tre nodi zookeeper. Per i test delle prestazioni abbiamo utilizzato cinque nodi worker OMB.
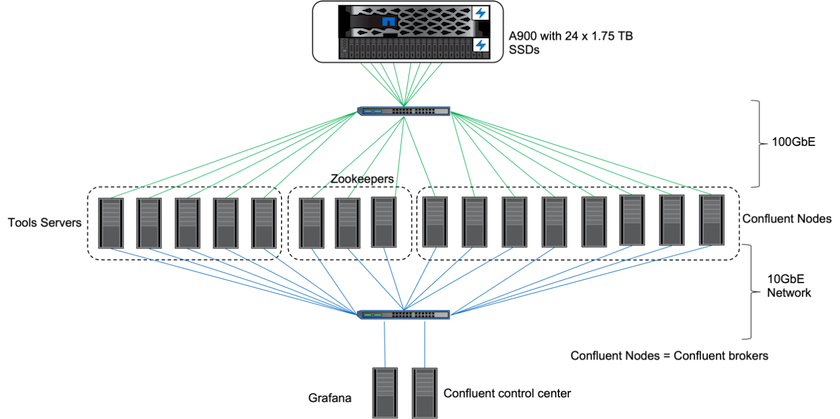
Configurazione di archiviazione
Abbiamo utilizzato istanze NetApp FlexGroups per fornire un singolo namespace per le directory di registro, semplificando il ripristino e la configurazione. Abbiamo utilizzato NFSv4.1 e pNFS per fornire un accesso diretto al percorso dei dati del segmento di registro.
Ottimizzazione del cliente
Ogni client ha montato l'istanza FlexGroup con il seguente comando.
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
Inoltre, abbiamo aumentato il max_session_slots` dal valore predefinito 64 A 180 . Corrisponde al limite predefinito dello slot di sessione in ONTAP.
Ottimizzazione del broker Kafka
Per massimizzare la produttività nel sistema sottoposto a test, abbiamo aumentato significativamente i parametri predefiniti per alcuni pool di thread chiave. Consigliamo di seguire le best practice di Confluent Kafka per la maggior parte delle configurazioni. Questa ottimizzazione è stata utilizzata per massimizzare la concorrenza di I/O in sospeso sullo storage. Questi parametri possono essere modificati in base alle risorse di calcolo e agli attributi di archiviazione del tuo broker.
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
Metodologia di test del generatore di carico di lavoro
Abbiamo utilizzato le stesse configurazioni OMB utilizzate per i test cloud per la configurazione del driver Throughput e dell'argomento.
-
Un'istanza FlexGroup è stata fornita tramite Ansible su un cluster AFF .
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
pNFS è stato abilitato ONTAP SVM.
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
Il carico di lavoro è stato attivato con il driver Throughput utilizzando la stessa configurazione del carico di lavoro di Cloud Volumes ONTAP. Vedi la sezione "Prestazioni in stato stazionario " sotto. Il carico di lavoro utilizzava un fattore di replicazione pari a 3, il che significa che tre copie dei segmenti di registro venivano mantenute in NFS.
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Infine, abbiamo completato le misurazioni utilizzando un backlog per misurare la capacità dei consumatori di tenersi aggiornati sui messaggi più recenti. L'OMB crea un backlog mettendo in pausa i consumatori all'inizio di una misurazione. Ciò produce tre fasi distinte: creazione del backlog (traffico riservato ai soli produttori), svuotamento del backlog (una fase in cui i consumatori recuperano gli eventi persi in un argomento) e stato stazionario. Vedi la sezione "Prestazioni estreme ed esplorazione dei limiti di archiviazione " per maggiori informazioni.
Prestazioni in stato stazionario
Abbiamo valutato l' AFF A900 utilizzando OpenMessaging Benchmark per fornire un confronto simile a quello tra Cloud Volumes ONTAP in AWS e DAS in AWS. Tutti i valori delle prestazioni rappresentano la produttività del cluster Kafka a livello di produttore e consumatore.
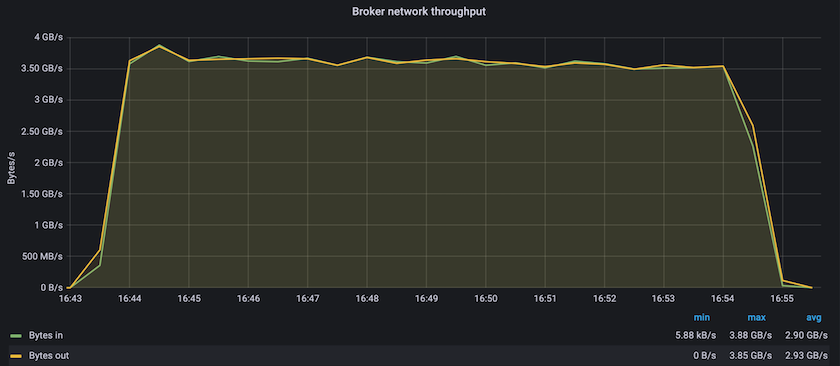
Le prestazioni in stato stazionario con Confluent Kafka e AFF A900 hanno raggiunto una velocità di trasmissione media di oltre 3,4 GBps sia per il produttore che per i consumatori. Si tratta di oltre 3,4 milioni di messaggi nel cluster Kafka. Visualizzando la produttività sostenuta in byte al secondo per BrokerTopicMetrics, vediamo le eccellenti prestazioni in stato stazionario e il traffico supportato dall'AFF AFF A900.
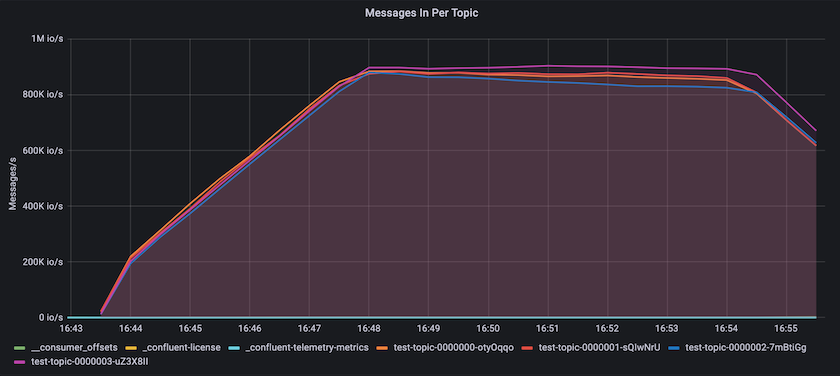
Ciò si allinea bene con la visione dei messaggi inviati per argomento. Il grafico seguente fornisce una ripartizione per argomento. Nella configurazione testata abbiamo visto quasi 900.000 messaggi per argomento, suddivisi in quattro argomenti.
Prestazioni estreme ed esplorazione dei limiti di archiviazione
Per AFF, abbiamo anche effettuato test con OMB utilizzando la funzionalità backlog. La funzionalità di backlog sospende gli abbonamenti dei consumatori mentre viene creato un backlog di eventi nel cluster Kafka. Durante questa fase si verifica solo il traffico del produttore, che genera eventi che vengono salvati nei log. Questa emula più fedelmente i flussi di lavoro di elaborazione batch o di analisi offline; in questi flussi di lavoro, gli abbonamenti dei consumatori vengono avviati e devono leggere i dati storici che sono già stati rimossi dalla cache del broker.
Per comprendere i limiti di archiviazione sulla capacità di elaborazione del consumatore in questa configurazione, abbiamo misurato la fase solo del produttore per capire quanto traffico di scrittura poteva assorbire l'A900. Vedi la sezione successiva "Guida alle taglie " per capire come sfruttare questi dati.
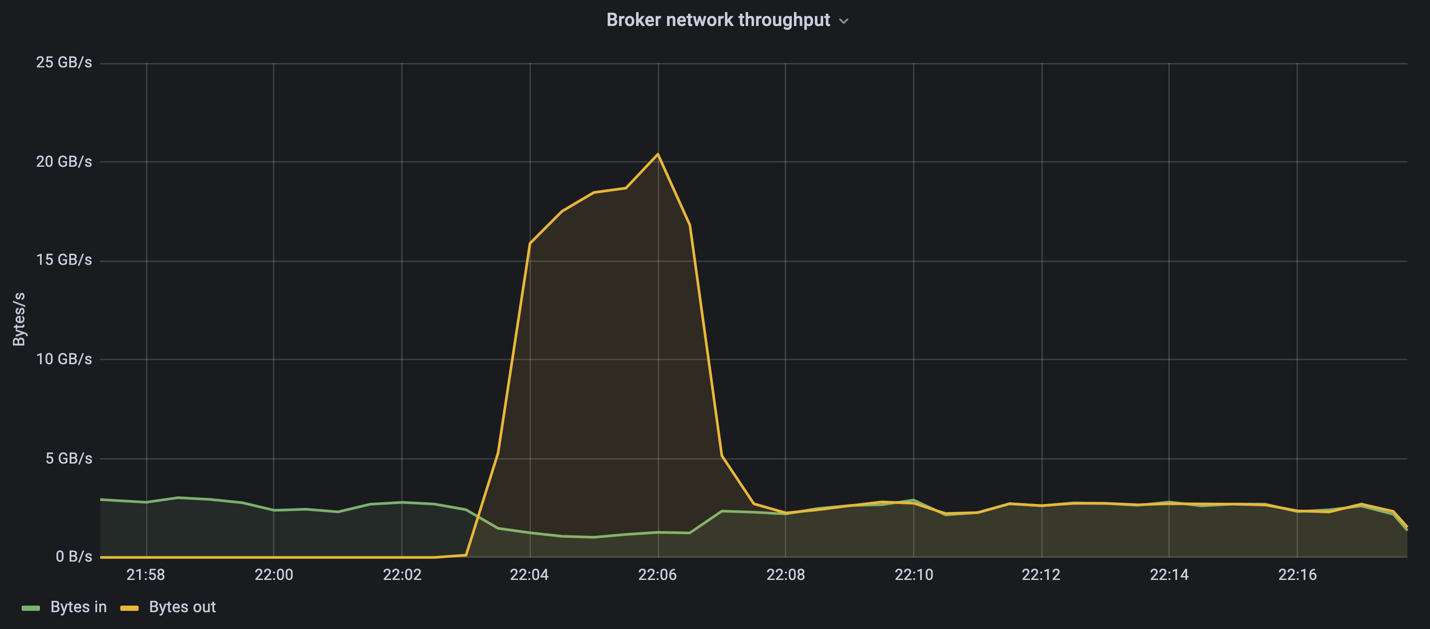
Durante la parte di questa misurazione riservata al solo produttore, abbiamo riscontrato un throughput di picco elevato che ha spinto al limite le prestazioni dell'A900 (quando le altre risorse del broker non erano sature e servivano il traffico del produttore e del consumatore).

|
Abbiamo aumentato la dimensione del messaggio a 16k per questa misurazione, per limitare i sovraccarichi per messaggio e massimizzare la capacità di archiviazione sui punti di montaggio NFS. |
messageSize: 16384 consumerBacklogSizeGB: 4096
Il cluster Confluent Kafka ha raggiunto un throughput di produzione massimo di 4,03 GBps.
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
Dopo che OMB ha completato il popolamento dell'eventbacklog, il traffico dei consumatori è stato riavviato. Durante le misurazioni con drenaggio del backlog, abbiamo osservato un throughput di picco dei consumatori di oltre 20 GBps su tutti gli argomenti. La velocità effettiva combinata del volume NFS che memorizzava i dati del registro OMB si avvicinava a circa 30 GBps.
Guida alle taglie
Amazon Web Services offre un "guida alle taglie" per il dimensionamento e la scalabilità dei cluster Kafka.
Questo dimensionamento fornisce una formula utile per determinare i requisiti di capacità di archiviazione per il cluster Kafka:
Per una produttività aggregata prodotta nel cluster di tcluster con un fattore di replicazione di r, la produttività ricevuta dallo storage del broker è la seguente:
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
La cosa può essere ulteriormente semplificata:
max(t[cluster]) <= max(t[storage]) * #brokers/r
Utilizzando questa formula è possibile selezionare la piattaforma ONTAP più adatta alle proprie esigenze di livello caldo Kafka.
La tabella seguente illustra la produttività prevista del produttore per l'A900 con diversi fattori di replicazione:
| Fattore di replicazione | Produzione del produttore (GPps) |
|---|---|
3 (misurato) |
3,4 |
2 |
5,1 |
1 |
10,2 |