Panoramica e convalida delle prestazioni in AWS
 Suggerisci modifiche
Suggerisci modifiche
Un cluster Kafka con il livello di archiviazione montato su NetApp NFS è stato sottoposto a benchmark per le prestazioni nel cloud AWS. Gli esempi di benchmarking sono descritti nelle sezioni seguenti.
Kafka nel cloud AWS con NetApp Cloud Volumes ONTAP (coppia ad alta disponibilità e nodo singolo)
Un cluster Kafka con NetApp Cloud Volumes ONTAP (coppia HA) è stato sottoposto a benchmark per le prestazioni nel cloud AWS. Questo benchmarking è descritto nelle sezioni seguenti.
Configurazione architettonica
La tabella seguente mostra la configurazione ambientale per un cluster Kafka che utilizza NAS.
| Componente della piattaforma | Configurazione dell'ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo su tutti i nodi |
RHEL8.6 |
Istanza ONTAP di NetApp Cloud Volumes ONTAP |
Istanza di coppia HA – m5dn.12xLarge x 2 nodi Istanza di nodo singolo – m5dn.12xLarge x 1 nodo |
Configurazione ONTAP del volume del cluster NetApp
-
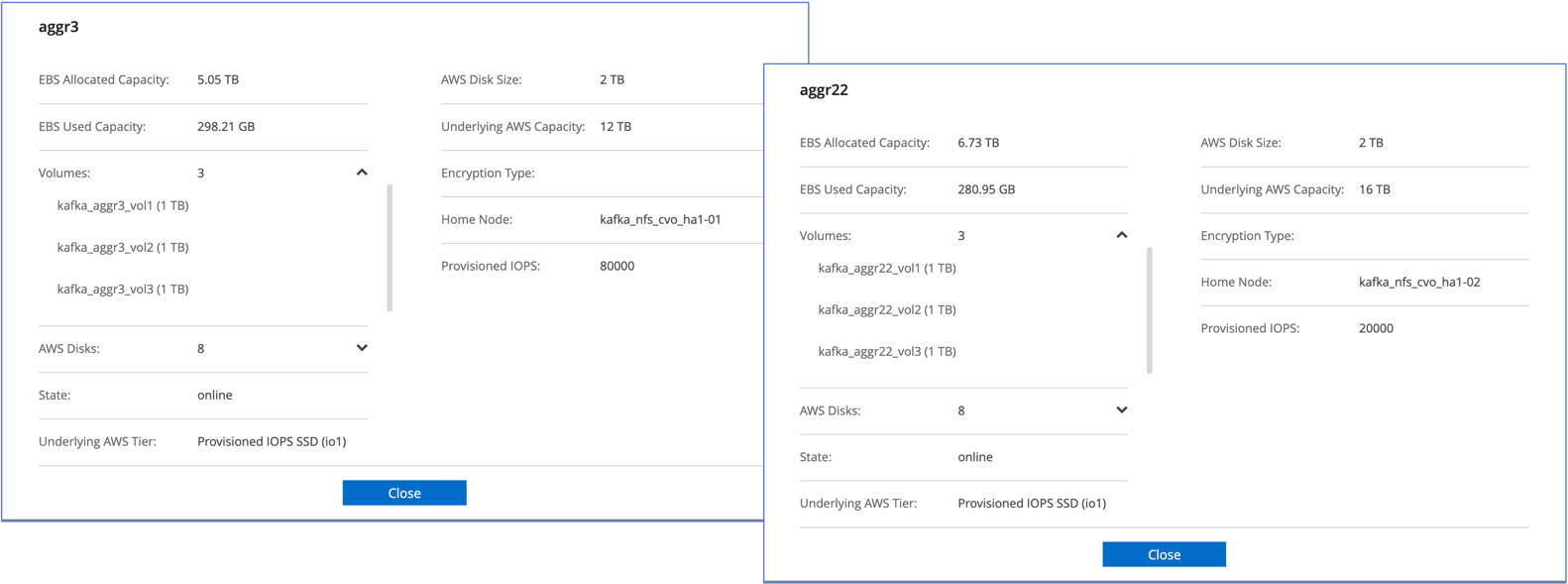
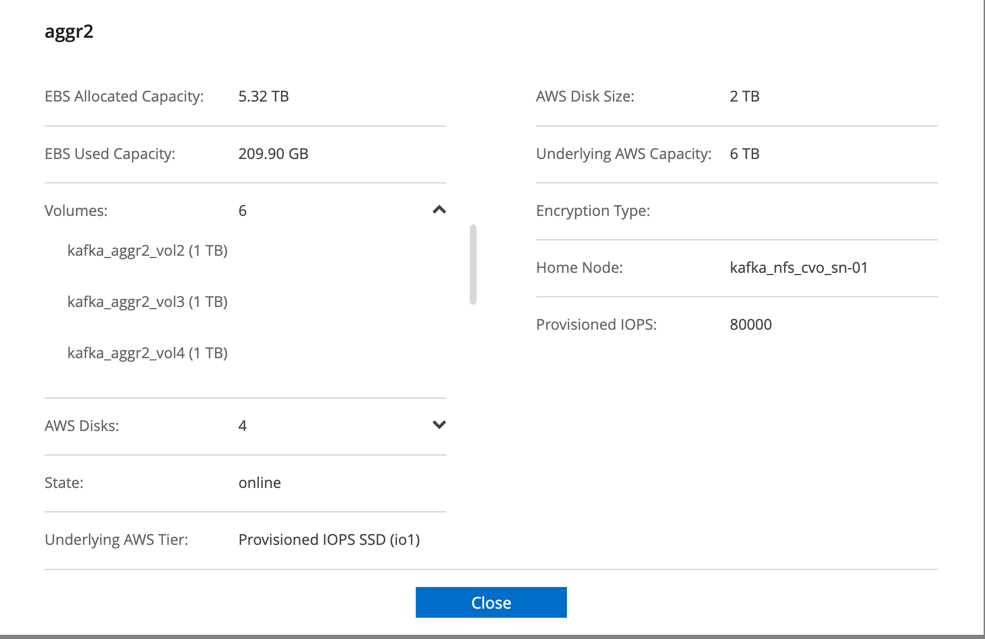
Per la coppia Cloud Volumes ONTAP HA, abbiamo creato due aggregati con tre volumi su ciascun aggregato su ciascun controller di storage. Per il singolo nodo Cloud Volumes ONTAP , creiamo sei volumi in un aggregato.
-
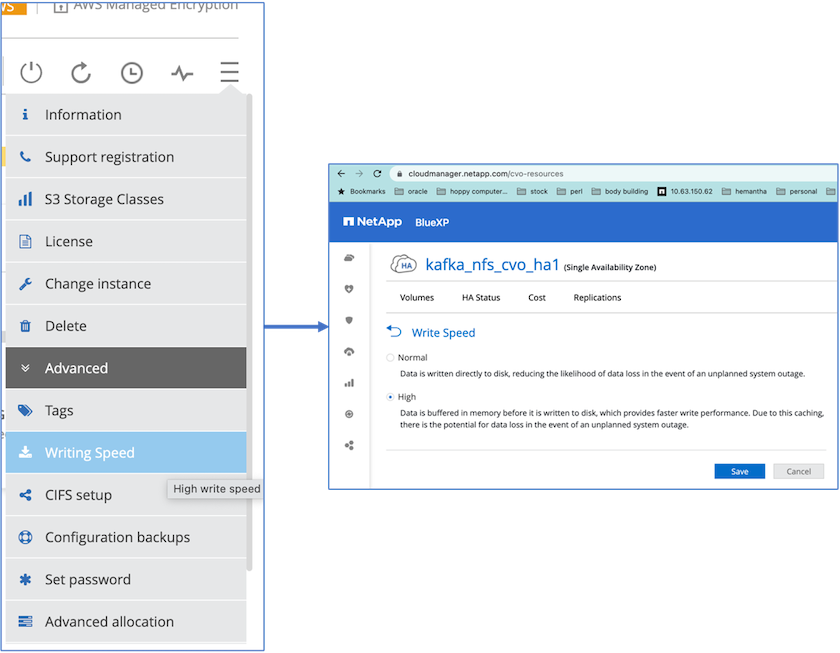
Per ottenere migliori prestazioni di rete, abbiamo abilitato la rete ad alta velocità sia per la coppia HA che per il singolo nodo.
-
Abbiamo notato che la NVRAM ONTAP aveva più IOPS, quindi abbiamo modificato gli IOPS a 2350 per il volume root Cloud Volumes ONTAP . Il disco del volume radice in Cloud Volumes ONTAP aveva una dimensione di 47 GB. Il seguente comando ONTAP è per la coppia HA e lo stesso passaggio è applicabile al singolo nodo.
statistics start -object vnvram -instance vnvram -counter backing_store_iops -sample-id sample_555 kafka_nfs_cvo_ha1::*> statistics show -sample-id sample_555 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-01 Counter Value -------------------------------- -------------------------------- backing_store_iops 1479 Object: vnvram Instance: vnvram Start-time: 1/18/2023 18:03:11 End-time: 1/18/2023 18:03:13 Elapsed-time: 2s Scope: kafka_nfs_cvo_ha1-02 Counter Value -------------------------------- -------------------------------- backing_store_iops 1210 2 entries were displayed. kafka_nfs_cvo_ha1::*>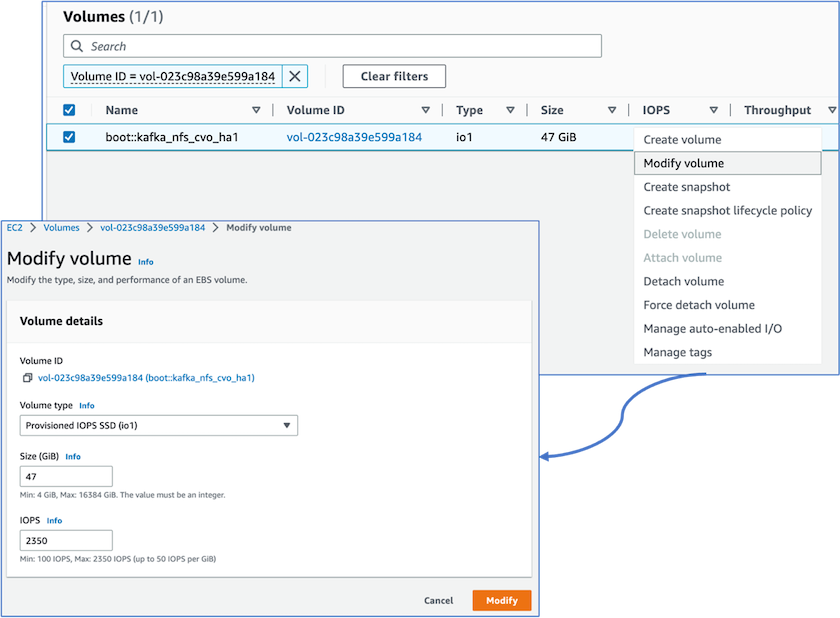
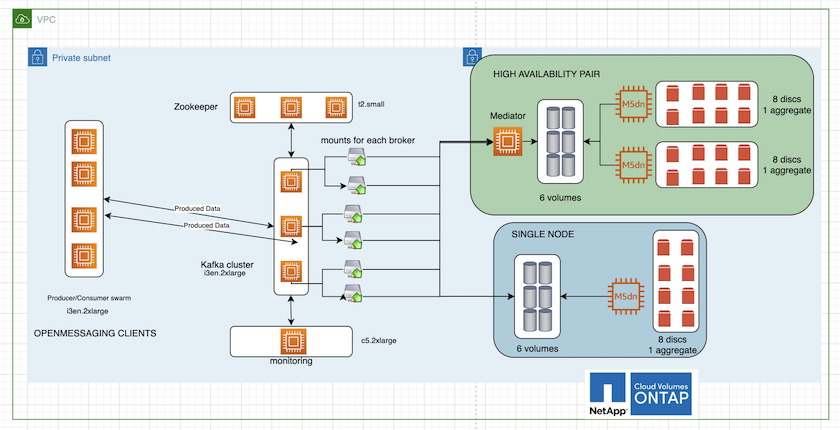
La figura seguente illustra l'architettura di un cluster Kafka basato su NAS.
-
Calcolare. Abbiamo utilizzato un cluster Kafka a tre nodi con un ensemble zookeeper a tre nodi in esecuzione su server dedicati. Ogni broker aveva due punti di montaggio NFS su un singolo volume sull'istanza Cloud Volumes ONTAP tramite un LIF dedicato.
-
Monitoraggio. Abbiamo utilizzato due nodi per una combinazione Prometheus-Grafana. Per generare i carichi di lavoro, abbiamo utilizzato un cluster separato a tre nodi in grado di produrre e consumare dati per questo cluster Kafka.
-
Magazzinaggio. Abbiamo utilizzato un'istanza ONTAP di volumi Cloud HA-pair con un volume GP3 AWS-EBS da 6 TB montato sull'istanza. Il volume è stato quindi esportato sul broker Kafka con un montaggio NFS.
Configurazioni di benchmarking di OpenMessage
-
Per migliorare le prestazioni NFS, abbiamo bisogno di più connessioni di rete tra il server NFS e il client NFS, che possono essere create utilizzando nconnect. Montare i volumi NFS sui nodi broker con l'opzione nconnect eseguendo il seguente comando:
[root@ip-172-30-0-121 ~]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38/xfsdefaults00 /dev/nvme1n1 /mnt/data-1 xfs defaults,noatime,nodiscard 0 0 /dev/nvme2n1 /mnt/data-2 xfs defaults,noatime,nodiscard 0 0 172.30.0.233:/kafka_aggr3_vol1 /kafka_aggr3_vol1 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol2 /kafka_aggr3_vol2 nfs defaults,nconnect=16 0 0 172.30.0.233:/kafka_aggr3_vol3 /kafka_aggr3_vol3 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol1 /kafka_aggr22_vol1 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol2 /kafka_aggr22_vol2 nfs defaults,nconnect=16 0 0 172.30.0.242:/kafka_aggr22_vol3 /kafka_aggr22_vol3 nfs defaults,nconnect=16 0 0 [root@ip-172-30-0-121 ~]# mount -a [root@ip-172-30-0-121 ~]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 31G 0 31G 0% /dev tmpfs 31G 249M 31G 1% /run tmpfs 31G 0 31G 0% /sys/fs/cgroup /dev/nvme0n1p2 10G 2.8G 7.2G 28% / /dev/nvme1n1 2.3T 248G 2.1T 11% /mnt/data-1 /dev/nvme2n1 2.3T 245G 2.1T 11% /mnt/data-2 172.30.0.233:/kafka_aggr3_vol1 1.0T 12G 1013G 2% /kafka_aggr3_vol1 172.30.0.233:/kafka_aggr3_vol2 1.0T 5.5G 1019G 1% /kafka_aggr3_vol2 172.30.0.233:/kafka_aggr3_vol3 1.0T 8.9G 1016G 1% /kafka_aggr3_vol3 172.30.0.242:/kafka_aggr22_vol1 1.0T 7.3G 1017G 1% /kafka_aggr22_vol1 172.30.0.242:/kafka_aggr22_vol2 1.0T 6.9G 1018G 1% /kafka_aggr22_vol2 172.30.0.242:/kafka_aggr22_vol3 1.0T 5.9G 1019G 1% /kafka_aggr22_vol3 tmpfs 6.2G 0 6.2G 0% /run/user/1000 [root@ip-172-30-0-121 ~]#
-
Controllare le connessioni di rete in Cloud Volumes ONTAP. Il seguente comando ONTAP viene utilizzato dal singolo nodo Cloud Volumes ONTAP . Lo stesso passaggio è applicabile alla coppia Cloud Volumes ONTAP HA.
Last login time: 1/20/2023 00:16:29 kafka_nfs_cvo_sn::> network connections active show -service nfs* -fields remote-host node cid vserver remote-host ------------------- ---------- -------------------- ------------ kafka_nfs_cvo_sn-01 2315762628 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762629 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762630 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762631 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762632 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762633 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762634 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762635 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762636 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762637 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762639 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762640 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762641 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762642 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762643 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762644 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762645 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762646 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762647 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762648 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762649 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762650 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762651 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762652 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762653 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762656 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762657 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762658 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762659 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762660 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762661 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762662 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762663 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762664 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762665 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762666 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762667 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762668 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762669 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762670 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762671 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762672 svm_kafka_nfs_cvo_sn 172.30.0.72 kafka_nfs_cvo_sn-01 2315762673 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762674 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762676 svm_kafka_nfs_cvo_sn 172.30.0.121 kafka_nfs_cvo_sn-01 2315762677 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762678 svm_kafka_nfs_cvo_sn 172.30.0.223 kafka_nfs_cvo_sn-01 2315762679 svm_kafka_nfs_cvo_sn 172.30.0.223 48 entries were displayed. kafka_nfs_cvo_sn::>
-
Utilizziamo il seguente Kafka
server.propertiesin tutti i broker Kafka per la coppia Cloud Volumes ONTAP HA. ILlog.dirsLa proprietà è diversa per ogni broker, mentre le restanti proprietà sono comuni a tutti i broker. Per broker1, illog.dirsil valore è il seguente:[root@ip-172-30-0-121 ~]# cat /opt/kafka/config/server.properties broker.id=0 advertised.listeners=PLAINTEXT://172.30.0.121:9092 #log.dirs=/mnt/data-1/d1,/mnt/data-1/d2,/mnt/data-1/d3,/mnt/data-2/d1,/mnt/data-2/d2,/mnt/data-2/d3 log.dirs=/kafka_aggr3_vol1/broker1,/kafka_aggr3_vol2/broker1,/kafka_aggr3_vol3/broker1,/kafka_aggr22_vol1/broker1,/kafka_aggr22_vol2/broker1,/kafka_aggr22_vol3/broker1 zookeeper.connect=172.30.0.12:2181,172.30.0.30:2181,172.30.0.178:2181 num.network.threads=64 num.io.threads=64 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 replica.fetch.max.bytes=524288000 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 [root@ip-172-30-0-121 ~]#
-
Per broker2, il
log.dirsil valore della proprietà è il seguente:log.dirs=/kafka_aggr3_vol1/broker2,/kafka_aggr3_vol2/broker2,/kafka_aggr3_vol3/broker2,/kafka_aggr22_vol1/broker2,/kafka_aggr22_vol2/broker2,/kafka_aggr22_vol3/broker2
-
Per broker3, il
log.dirsil valore della proprietà è il seguente:log.dirs=/kafka_aggr3_vol1/broker3,/kafka_aggr3_vol2/broker3,/kafka_aggr3_vol3/broker3,/kafka_aggr22_vol1/broker3,/kafka_aggr22_vol2/broker3,/kafka_aggr22_vol3/broker3
-
-
Per il singolo nodo Cloud Volumes ONTAP , The Kafka
servers.propertiesè lo stesso della coppia Cloud Volumes ONTAP HA, ad eccezione dilog.dirsproprietà.-
Per broker1, il
log.dirsil valore è il seguente:log.dirs=/kafka_aggr2_vol1/broker1,/kafka_aggr2_vol2/broker1,/kafka_aggr2_vol3/broker1,/kafka_aggr2_vol4/broker1,/kafka_aggr2_vol5/broker1,/kafka_aggr2_vol6/broker1
-
Per broker2, il
log.dirsil valore è il seguente:log.dirs=/kafka_aggr2_vol1/broker2,/kafka_aggr2_vol2/broker2,/kafka_aggr2_vol3/broker2,/kafka_aggr2_vol4/broker2,/kafka_aggr2_vol5/broker2,/kafka_aggr2_vol6/broker2
-
Per broker3, il
log.dirsil valore della proprietà è il seguente:log.dirs=/kafka_aggr2_vol1/broker3,/kafka_aggr2_vol2/broker3,/kafka_aggr2_vol3/broker3,/kafka_aggr2_vol4/broker3,/kafka_aggr2_vol5/broker3,/kafka_aggr2_vol6/broker3
-
-
Il carico di lavoro nell'OMB è configurato con le seguenti proprietà:
(/opt/benchmark/workloads/1-topic-100-partitions-1kb.yaml).topics: 4 partitionsPerTopic: 100 messageSize: 32768 useRandomizedPayloads: true randomBytesRatio: 0.5 randomizedPayloadPoolSize: 100 subscriptionsPerTopic: 1 consumerPerSubscription: 80 producersPerTopic: 40 producerRate: 1000000 consumerBacklogSizeGB: 0 testDurationMinutes: 5
IL
messageSizepuò variare a seconda del caso d'uso. Nel nostro test delle prestazioni abbiamo utilizzato 3K.Abbiamo utilizzato due driver diversi, Sync o Throughput, di OMB per generare il carico di lavoro sul cluster Kafka.
-
Il file yaml utilizzato per le proprietà del driver di sincronizzazione è il seguente
(/opt/benchmark/driver- kafka/kafka-sync.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 flush.messages=1 flush.ms=0 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Il file yaml utilizzato per le proprietà del driver Throughput è il seguente
(/opt/benchmark/driver- kafka/kafka-throughput.yaml):name: Kafka driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver # Kafka client-specific configuration replicationFactor: 3 topicConfig: | min.insync.replicas=2 commonConfig: | bootstrap.servers=172.30.0.121:9092,172.30.0.72:9092,172.30.0.223:9092 default.api.timeout.ms=1200000 request.timeout.ms=1200000 producerConfig: | acks=all linger.ms=1 batch.size=1048576 consumerConfig: | auto.offset.reset=earliest enable.auto.commit=false max.partition.fetch.bytes=10485760
-
Metodologia di test
-
Un cluster Kafka è stato predisposto secondo le specifiche descritte sopra utilizzando Terraform e Ansible. Terraform viene utilizzato per creare l'infrastruttura utilizzando istanze AWS per il cluster Kafka, mentre Ansible crea il cluster Kafka su di esse.
-
Un carico di lavoro OMB è stato attivato con la configurazione del carico di lavoro descritta sopra e il driver Sync.
Sudo bin/benchmark –drivers driver-kafka/kafka- sync.yaml workloads/1-topic-100-partitions-1kb.yaml
-
Un altro carico di lavoro è stato attivato con il driver Throughput con la stessa configurazione del carico di lavoro.
sudo bin/benchmark –drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
Osservazione
Sono stati utilizzati due diversi tipi di driver per generare carichi di lavoro per confrontare le prestazioni di un'istanza Kafka in esecuzione su NFS. La differenza tra i driver è la proprietà di svuotamento del registro.
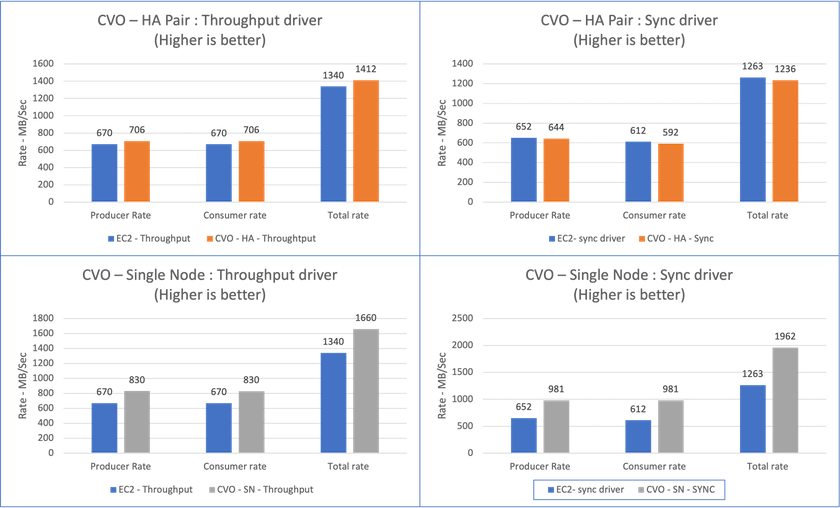
Per una coppia Cloud Volumes ONTAP HA:
-
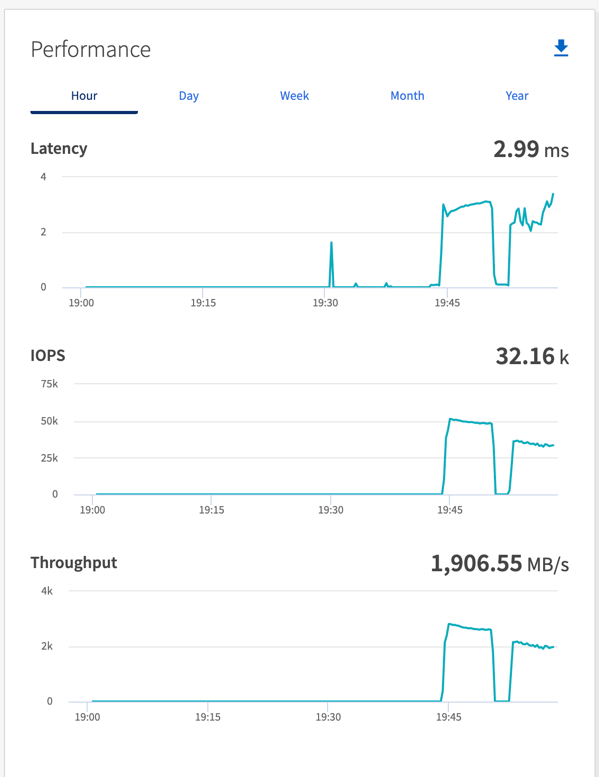
Velocità totale generata in modo coerente dal driver Sync: ~1236 MBps.
-
Throughput totale generato per il driver Throughput: picco ~1412 MBps.
Per un singolo Cloud Volumes ONTAP :
-
Velocità totale generata in modo coerente dal driver Sync: ~ 1962 MBps.
-
Throughput totale generato dal driver Throughput: picco ~1660MBps
Il driver Sync è in grado di generare un throughput costante poiché i log vengono scaricati sul disco all'istante, mentre il driver Throughput genera picchi di throughput poiché i log vengono salvati sul disco in blocco.
Questi numeri di throughput vengono generati per la configurazione AWS specificata. Per requisiti di prestazioni più elevati, i tipi di istanza possono essere ampliati e ulteriormente ottimizzati per ottenere numeri di throughput migliori. La produttività totale o tasso totale è la combinazione del tasso del produttore e del tasso del consumatore.
Assicurarsi di controllare la velocità di archiviazione quando si esegue il benchmarking della velocità di elaborazione o del driver di sincronizzazione.