Validazione funzionale - Correzione stupida del cambio di nome
 Suggerisci modifiche
Suggerisci modifiche
Per la convalida funzionale, abbiamo dimostrato che un cluster Kafka con un mount NFSv3 per l'archiviazione non riesce a eseguire operazioni Kafka come la ridistribuzione delle partizioni, mentre un altro cluster montato su NFSv4 con la correzione può eseguire le stesse operazioni senza interruzioni.
Impostazione di convalida
L'installazione viene eseguita su AWS. Nella tabella seguente sono riportati i diversi componenti della piattaforma e la configurazione ambientale utilizzati per la convalida.
| Componente della piattaforma | Configurazione dell'ambiente |
|---|---|
Piattaforma Confluent versione 7.2.1 |
|
Sistema operativo su tutti i nodi |
RHEL8.7 o successivo |
Istanza ONTAP di NetApp Cloud Volumes ONTAP |
Istanza a nodo singolo – M5.2xLarge |
La figura seguente mostra la configurazione architettonica di questa soluzione.
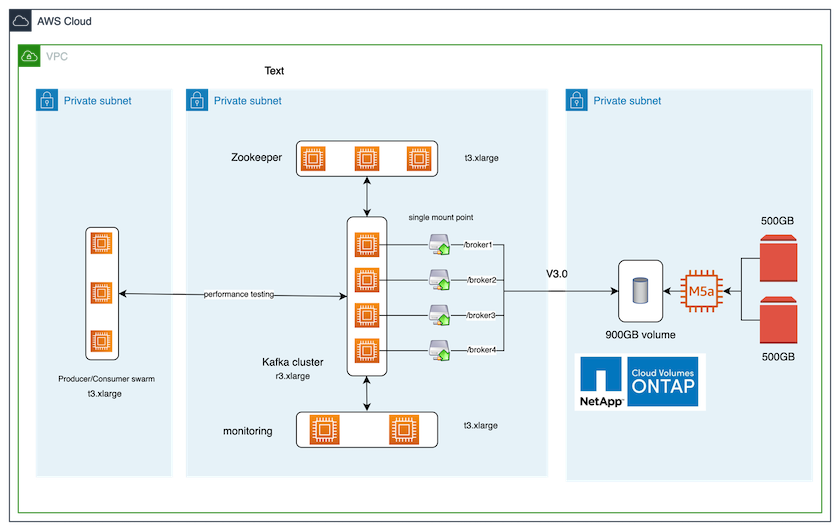
Flusso architettonico
-
Calcolare. Abbiamo utilizzato un cluster Kafka a quattro nodi con un ensemble zookeeper a tre nodi in esecuzione su server dedicati.
-
Monitoraggio. Abbiamo utilizzato due nodi per una combinazione Prometheus-Grafana.
-
Carico di lavoro. Per generare carichi di lavoro, abbiamo utilizzato un cluster separato a tre nodi in grado di produrre e consumare da questo cluster Kafka.
-
Magazzinaggio. Abbiamo utilizzato un'istanza ONTAP NetApp Cloud Volumes a nodo singolo con due volumi GP2 AWS-EBS da 500 GB collegati all'istanza. Questi volumi sono stati quindi esposti al cluster Kafka come singoli volumi NFSv4.1 tramite un LIF.
Per tutti i server sono state scelte le proprietà predefinite di Kafka. Lo stesso è stato fatto per lo sciame dei guardiani dello zoo.
Metodologia di test
-
Aggiornamento
-is-preserve-unlink-enabled trueal volume di Kafka, come segue:aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
Sono stati creati due cluster Kafka simili con la seguente differenza:
-
Gruppo 1. Il server backend NFS v4.1 che esegue ONTAP versione 9.12.1 pronto per la produzione era ospitato da un'istanza NetApp CVO. Sui broker sono stati installati RHEL 8.7/RHEL 9.1.
-
Gruppo 2. Il server NFS backend era un server Linux NFSv3 generico creato manualmente.
-
-
È stato creato un argomento dimostrativo su entrambi i cluster Kafka.
Gruppo 1:

Gruppo 2:

-
I dati sono stati caricati in questi argomenti appena creati per entrambi i cluster. Ciò è stato fatto utilizzando il toolkit producer-perf-test incluso nel pacchetto Kafka predefinito:
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
È stato eseguito un controllo dello stato di salute per broker-1 per ciascuno dei cluster utilizzando telnet:
-
telnet
172.30.0.160 9092 -
telnet
172.30.0.198 9092Nella schermata successiva viene mostrato un controllo dello stato di salute riuscito per i broker su entrambi i cluster:
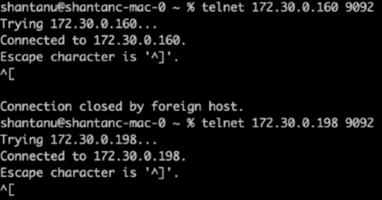
-
-
Per innescare la condizione di errore che causa l'arresto anomalo dei cluster Kafka che utilizzano volumi di archiviazione NFSv3, abbiamo avviato il processo di riassegnazione delle partizioni su entrambi i cluster. La riassegnazione della partizione è stata eseguita utilizzando
kafka-reassign-partitions.sh. Il processo dettagliato è il seguente:-
Per riassegnare le partizioni per un argomento in un cluster Kafka, abbiamo generato la configurazione di riassegnazione proposta in formato JSON (questa operazione è stata eseguita per entrambi i cluster).
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
Il JSON di riassegnazione generato è stato quindi salvato in
/tmp/reassignment- file.json. -
Il processo di riassegnazione della partizione effettiva è stato attivato dal seguente comando:
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
Dopo alcuni minuti, una volta completata la riassegnazione, un altro controllo dello stato di salute dei broker ha mostrato che il cluster che utilizzava volumi di storage NFSv3 aveva riscontrato un problema di ridenominazione e si era bloccato, mentre il Cluster 1 che utilizzava volumi di storage NetApp ONTAP NFSv4.1 con la correzione ha continuato a funzionare senza interruzioni.
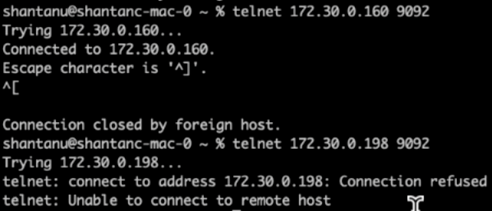
-
Cluster1-Broker-1 è attivo.
-
Cluster2-broker-1 è morto.
-
-
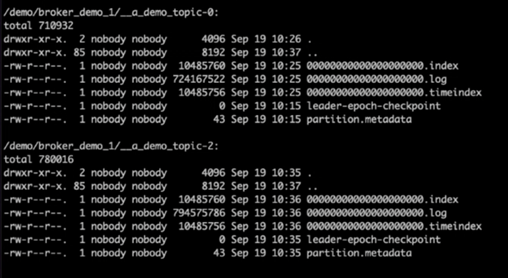
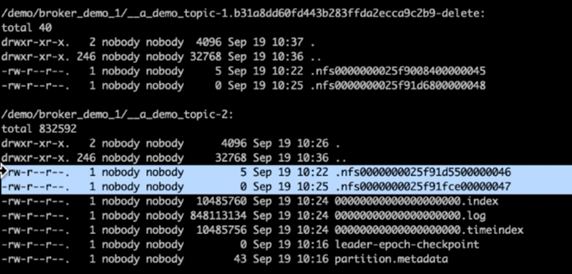
Dopo aver controllato le directory del registro di Kafka, è risultato chiaro che il Cluster 1 che utilizzava volumi di storage NetApp ONTAP NFSv4.1 con la correzione aveva un'assegnazione di partizioni pulita, mentre il Cluster 2 che utilizzava storage NFSv3 generico non aveva un'assegnazione di partizioni pulita a causa di stupidi problemi di ridenominazione, che hanno causato l'arresto anomalo. L'immagine seguente mostra il ribilanciamento delle partizioni del Cluster 2, che ha causato un problema di ridenominazione nello storage NFSv3.
L'immagine seguente mostra un ribilanciamento pulito della partizione del Cluster 1 utilizzando lo storage NetApp NFSv4.1.