Perché NetApp NFS per i carichi di lavoro Kafka?
 Suggerisci modifiche
Suggerisci modifiche
Ora che esiste una soluzione per il problema di ridenominazione nello storage NFS con Kafka, puoi creare distribuzioni robuste che sfruttano lo storage NetApp ONTAP per il tuo carico di lavoro Kafka. Ciò non solo riduce significativamente i costi operativi, ma apporta anche i seguenti vantaggi ai cluster Kafka:
-
Utilizzo ridotto della CPU sui broker Kafka. L'utilizzo di storage NetApp ONTAP disaggregato separa le operazioni di I/O del disco dal broker, riducendo così l'ingombro della CPU.
-
Tempi di recupero del broker più rapidi. Poiché lo storage disaggregato NetApp ONTAP è condiviso tra i nodi broker Kafka, una nuova istanza di elaborazione può sostituire un broker non funzionante in qualsiasi momento e in una frazione del tempo rispetto alle distribuzioni Kafka convenzionali, senza dover ricostruire i dati.
-
Efficienza di archiviazione. Poiché il livello di storage dell'applicazione è ora fornito tramite NetApp ONTAP, i clienti possono usufruire di tutti i vantaggi dell'efficienza di storage offerti da ONTAP, come la compressione dei dati in linea, la deduplicazione e la compattazione.
Questi vantaggi sono stati testati e convalidati in casi di prova che analizzeremo in dettaglio in questa sezione.
Utilizzo ridotto della CPU sul broker Kafka
Abbiamo scoperto che l'utilizzo complessivo della CPU è inferiore rispetto alla controparte DAS quando abbiamo eseguito carichi di lavoro simili su due cluster Kafka separati, identici nelle specifiche tecniche ma diversi nelle tecnologie di archiviazione. Non solo l'utilizzo complessivo della CPU è inferiore quando il cluster Kafka utilizza l'archiviazione ONTAP , ma l'aumento dell'utilizzo della CPU ha mostrato un gradiente più graduale rispetto a un cluster Kafka basato su DAS.
Configurazione architettonica
La tabella seguente mostra la configurazione ambientale utilizzata per dimostrare un utilizzo ridotto della CPU.
| Componente della piattaforma | Configurazione dell'ambiente |
|---|---|
Strumento di benchmarking di Kafka 3.2.3: OpenMessaging |
|
Sistema operativo su tutti i nodi |
RHEL 8.7 o successivo |
Istanza ONTAP di NetApp Cloud Volumes ONTAP |
Istanza a nodo singolo – M5.2xLarge |
Strumento di benchmarking
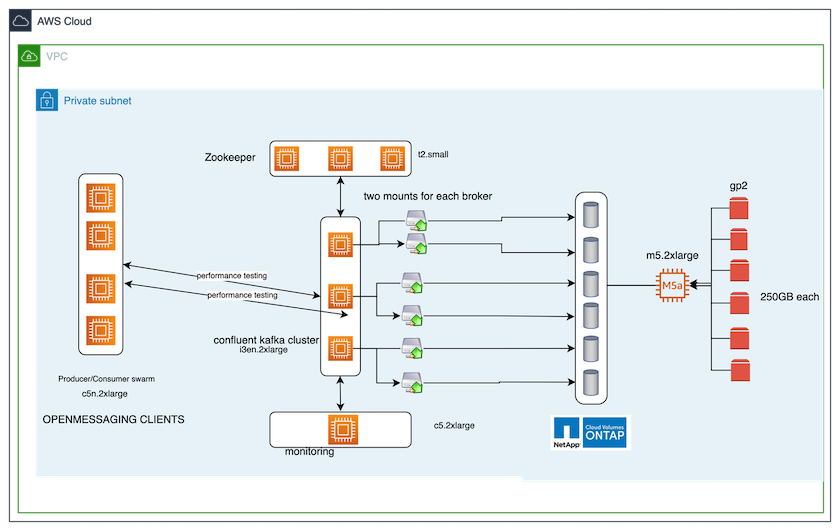
Lo strumento di benchmarking utilizzato in questo caso di prova è il "OpenMessaging" struttura. OpenMessaging è indipendente dal fornitore e dal linguaggio; fornisce linee guida di settore per finanza, e-commerce, IoT e big data e aiuta a sviluppare applicazioni di messaggistica e streaming su sistemi e piattaforme eterogenei. La figura seguente illustra l'interazione dei client OpenMessaging con un cluster Kafka.
-
Calcolare. Abbiamo utilizzato un cluster Kafka a tre nodi con un ensemble zookeeper a tre nodi in esecuzione su server dedicati. Ogni broker aveva due punti di montaggio NFSv4.1 su un singolo volume sull'istanza NetApp CVO tramite un LIF dedicato.
-
Monitoraggio. Abbiamo utilizzato due nodi per una combinazione Prometheus-Grafana. Per generare carichi di lavoro, disponiamo di un cluster separato a tre nodi che può produrre e consumare da questo cluster Kafka.
-
Magazzinaggio. Abbiamo utilizzato un'istanza ONTAP NetApp Cloud Volumes a nodo singolo con sei volumi GP2 AWS-EBS da 250 GB montati sull'istanza. Questi volumi sono stati quindi esposti al cluster Kafka come sei volumi NFSv4.1 tramite LIF dedicati.
-
Configurazione. I due elementi configurabili in questo caso di test erano i broker Kafka e i carichi di lavoro OpenMessaging.
-
Configurazione del broker. Per i broker Kafka sono state selezionate le seguenti specifiche. Abbiamo utilizzato un fattore di replicazione pari a 3 per tutte le misurazioni, come evidenziato di seguito.
-

-
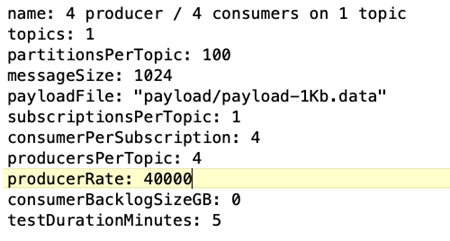
Configurazione del carico di lavoro del benchmark OpenMessaging (OMB). Sono state fornite le seguenti specifiche. Abbiamo specificato un tasso di produzione target, evidenziato di seguito.
Metodologia di test
-
Sono stati creati due cluster simili, ciascuno con il proprio set di swarm di cluster di benchmarking.
-
Gruppo 1. Cluster Kafka basato su NFS.
-
Gruppo 2. Cluster Kafka basato su DAS.
-
-
Utilizzando un comando OpenMessaging, sono stati attivati carichi di lavoro simili su ciascun cluster.
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
La configurazione della velocità di produzione è stata aumentata in quattro iterazioni e l'utilizzo della CPU è stato registrato con Grafana. Il tasso di produzione è stato fissato ai seguenti livelli:
-
10.000
-
40.000
-
80.000
-
100.000
-
Osservazione
L'utilizzo dello storage NFS NetApp con Kafka offre due vantaggi principali:
-
È possibile ridurre l'utilizzo della CPU di quasi un terzo. L'utilizzo complessivo della CPU con carichi di lavoro simili è risultato inferiore per NFS rispetto agli SSD DAS; i risparmi vanno dal 5% per tassi di produzione inferiori al 32% per tassi di produzione superiori.
-
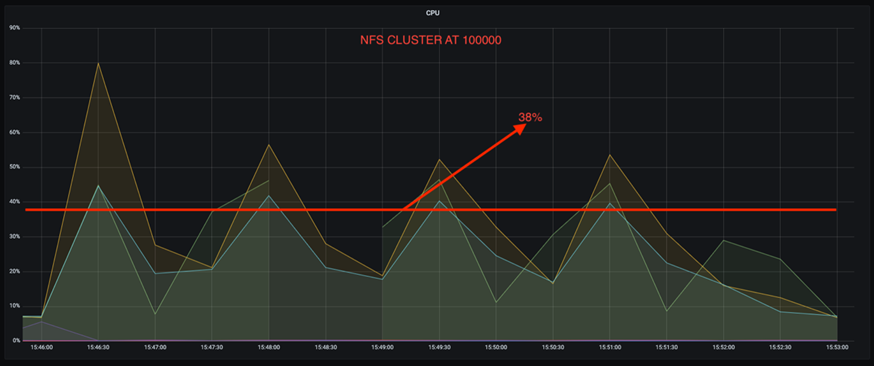
Una riduzione tripla dell'utilizzo della CPU a velocità di produzione più elevate. Come previsto, si è registrato un aumento dell'utilizzo della CPU con l'aumento dei tassi di produzione. Tuttavia, l'utilizzo della CPU sui broker Kafka che utilizzano DAS è aumentato dal 31% per il tasso di produzione più basso al 70% per il tasso di produzione più alto, con un incremento del 39%. Tuttavia, con un backend di archiviazione NFS, l'utilizzo della CPU è aumentato dal 26% al 38%, con un incremento del 12%.
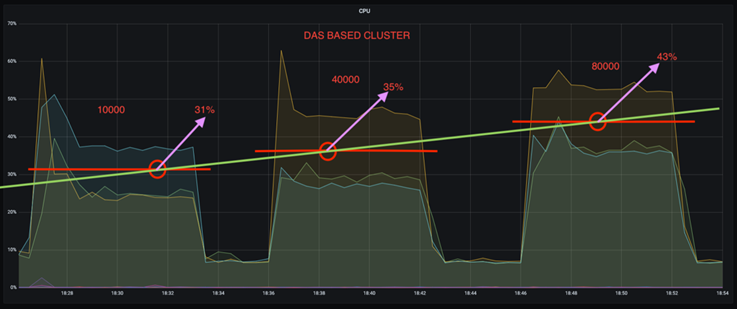
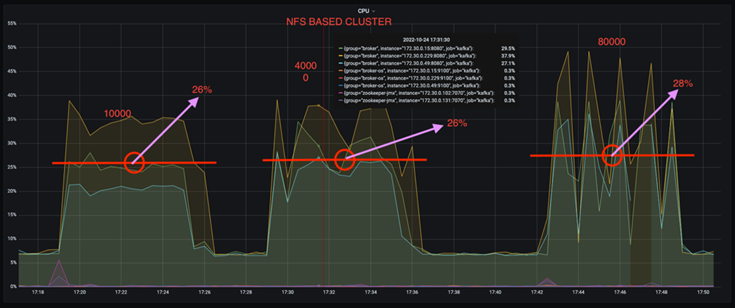
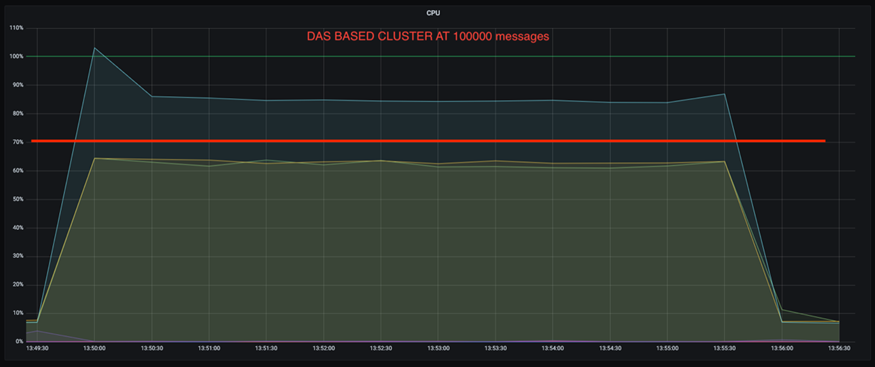
Inoltre, a 100.000 messaggi, DAS mostra un utilizzo della CPU maggiore rispetto a un cluster NFS.
Recupero più rapido del broker
Abbiamo scoperto che i broker Kafka ripristinano più velocemente quando utilizzano lo storage NetApp NFS condiviso. Quando un broker si blocca in un cluster Kafka, può essere sostituito da un broker funzionante con lo stesso ID broker. Dopo aver eseguito questo caso di test, abbiamo scoperto che, nel caso di un cluster Kafka basato su DAS, il cluster ricostruisce i dati su un broker funzionante appena aggiunto, il che richiede molto tempo. Nel caso di un cluster Kafka basato su NetApp NFS, il broker sostitutivo continua a leggere i dati dalla directory di registro precedente e ripristina molto più rapidamente.
Configurazione architettonica
La tabella seguente mostra la configurazione ambientale per un cluster Kafka che utilizza NAS.
| Componente della piattaforma | Configurazione dell'ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo su tutti i nodi |
RHEL8.7 o successivo |
Istanza ONTAP di NetApp Cloud Volumes ONTAP |
Istanza a nodo singolo – M5.2xLarge |
La figura seguente illustra l'architettura di un cluster Kafka basato su NAS.
-
Calcolare. Un cluster Kafka a tre nodi con un ensemble zookeeper a tre nodi in esecuzione su server dedicati. Ogni broker ha due punti di montaggio NFS su un singolo volume sull'istanza NetApp CVO tramite un LIF dedicato.
-
Monitoraggio. Due nodi per una combinazione Prometheus-Grafana. Per generare carichi di lavoro, utilizziamo un cluster separato a tre nodi in grado di produrre e consumare dati per questo cluster Kafka.
-
Magazzinaggio. Un'istanza ONTAP NetApp Cloud Volumes a nodo singolo con sei volumi GP2 AWS-EBS da 250 GB montati sull'istanza. Questi volumi vengono quindi esposti al cluster Kafka come sei volumi NFS tramite LIF dedicati.
-
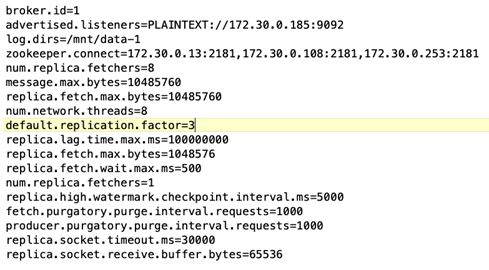
Configurazione del broker. L'unico elemento configurabile in questo caso di test sono i broker Kafka. Per i broker Kafka sono state selezionate le seguenti specifiche. IL
replica.lag.time.mx.msè impostato su un valore elevato perché determina la velocità con cui un nodo specifico viene rimosso dall'elenco ISR. Quando si passa da nodi danneggiati a nodi sani, non si desidera che l'ID del broker venga escluso dall'elenco ISR.
Metodologia di test
-
Sono stati creati due cluster simili:
-
Un cluster confluente basato su EC2.
-
Un cluster confluente basato su NetApp NFS.
-
-
È stato creato un nodo Kafka di standby con una configurazione identica ai nodi del cluster Kafka originale.
-
Su ciascuno dei cluster è stato creato un argomento di esempio e sono stati popolati circa 110 GB di dati su ciascun broker.
-
Cluster basato su EC2. Una directory di dati del broker Kafka è mappata su
/mnt/data-2(Nella figura seguente, Broker-1 del cluster1 [terminale sinistro]). -
* Cluster basato su NetApp NFS.* Una directory di dati del broker Kafka è montata sul punto NFS
/mnt/data(Nella figura seguente, Broker-1 del cluster2 [terminale destro]).
-
-
In ciascuno dei cluster, Broker-1 è stato terminato per attivare un processo di ripristino del broker non riuscito.
-
Dopo la chiusura del broker, l'indirizzo IP del broker è stato assegnato come IP secondario al broker standby. Ciò era necessario perché un broker in un cluster Kafka viene identificato da quanto segue:
-
Indirizzo IP. Assegnato riassegnando l'IP del broker non riuscito al broker standby.
-
ID broker. Questo è stato configurato nel broker standby
server.properties.
-
-
Dopo l'assegnazione dell'IP, il servizio Kafka è stato avviato sul broker standby.
-
Dopo un po', sono stati estratti i log del server per verificare il tempo impiegato per creare i dati sul nodo sostitutivo nel cluster.
Osservazione
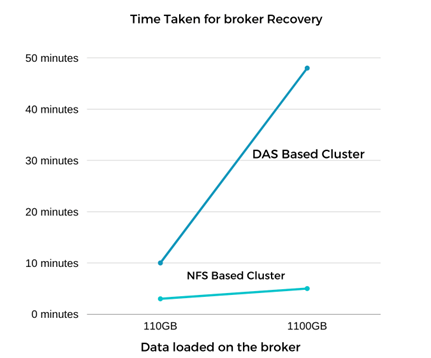
Il recupero del broker Kafka è stato quasi nove volte più rapido. È stato riscontrato che il tempo impiegato per ripristinare un nodo broker non riuscito è significativamente più rapido quando si utilizza l'archiviazione condivisa NetApp NFS rispetto all'utilizzo di SSD DAS in un cluster Kafka. Per 1 TB di dati di argomento, il tempo di ripristino per un cluster basato su DAS è stato di 48 minuti, rispetto a meno di 5 minuti per un cluster Kafka basato su NetApp-NFS.
Abbiamo osservato che il cluster basato su EC2 ha impiegato 10 minuti per ricostruire i 110 GB di dati sul nuovo nodo broker, mentre il cluster basato su NFS ha completato il ripristino in 3 minuti. Abbiamo anche osservato nei log che gli offset dei consumatori per le partizioni per EC2 erano 0, mentre, sul cluster NFS, gli offset dei consumatori venivano prelevati dal broker precedente.
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
Cluster basato su DAS
-
Il nodo di backup è stato avviato alle 08:55:53,730.

-
Il processo di ricostruzione dei dati è terminato alle 09:05:24,860. L'elaborazione di 110 GB di dati ha richiesto circa 10 minuti.

Cluster basato su NFS
-
Il nodo di backup è stato avviato alle 09:39:17,213. Di seguito è evidenziata la voce di registro iniziale.

-
Il processo di ricostruzione dei dati è terminato alle 09:42:29,115. L'elaborazione di 110 GB di dati ha richiesto circa 3 minuti.

Il test è stato ripetuto per broker contenenti circa 1 TB di dati, impiegando circa 48 minuti per il DAS e 3 minuti per l'NFS. I risultati sono rappresentati nel grafico seguente.
Efficienza di archiviazione
Poiché il livello di archiviazione del cluster Kafka è stato fornito tramite NetApp ONTAP, abbiamo ottenuto tutte le funzionalità di efficienza di archiviazione di ONTAP. Questa soluzione è stata testata generando una quantità significativa di dati su un cluster Kafka con storage NFS fornito su Cloud Volumes ONTAP. Abbiamo potuto constatare che si è verificata una significativa riduzione dello spazio grazie alle funzionalità ONTAP .
Configurazione architettonica
La tabella seguente mostra la configurazione ambientale per un cluster Kafka che utilizza NAS.
| Componente della piattaforma | Configurazione dell'ambiente |
|---|---|
Kafka 3.2.3 |
|
Sistema operativo su tutti i nodi |
RHEL8.7 o successivo |
Istanza ONTAP di NetApp Cloud Volumes ONTAP |
Istanza a nodo singolo – M5.2xLarge |
La figura seguente illustra l'architettura di un cluster Kafka basato su NAS.
-
Calcolare. Abbiamo utilizzato un cluster Kafka a tre nodi con un ensemble zookeeper a tre nodi in esecuzione su server dedicati. Ogni broker aveva due punti di montaggio NFS su un singolo volume sull'istanza NetApp CVO tramite un LIF dedicato.
-
Monitoraggio. Abbiamo utilizzato due nodi per una combinazione Prometheus-Grafana. Per generare i carichi di lavoro, abbiamo utilizzato un cluster separato a tre nodi in grado di produrre e consumare dati per questo cluster Kafka.
-
Magazzinaggio. Abbiamo utilizzato un'istanza NetApp Cloud Volumes ONTAP a nodo singolo con sei volumi GP2 AWS-EBS da 250 GB montati sull'istanza. Questi volumi sono stati quindi esposti al cluster Kafka come sei volumi NFS tramite LIF dedicati.
-
Configurazione. Gli elementi configurabili in questo caso di prova erano i broker Kafka.
La compressione è stata disattivata dal produttore, consentendogli così di generare un rendimento elevato. L'efficienza dell'archiviazione era invece gestita dal livello di elaborazione.
Metodologia di test
-
È stato predisposto un cluster Kafka con le specifiche sopra menzionate.
-
Sul cluster sono stati prodotti circa 350 GB di dati utilizzando lo strumento OpenMessaging Benchmarking.
-
Una volta completato il carico di lavoro, le statistiche sull'efficienza dell'archiviazione sono state raccolte utilizzando ONTAP System Manager e la CLI.
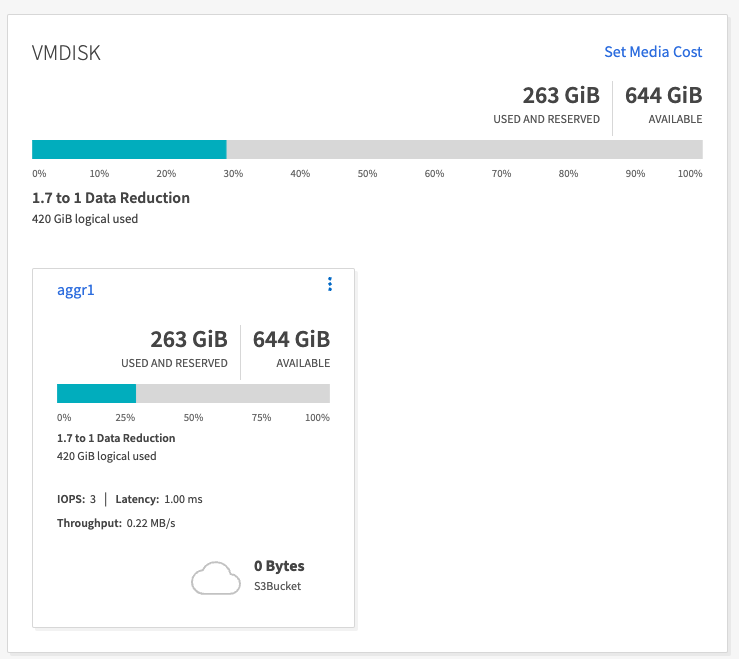
Osservazione
Per i dati generati utilizzando lo strumento OMB, abbiamo riscontrato un risparmio di spazio di circa il 33% con un rapporto di efficienza di archiviazione di 1,70:1. Come si può vedere nelle figure seguenti, lo spazio logico utilizzato dai dati prodotti era di 420,3 GB e lo spazio fisico utilizzato per contenere i dati era di 281,7 GB.