

Validazione delle prestazioni confluenti
 Suggerisci modifiche
Suggerisci modifiche
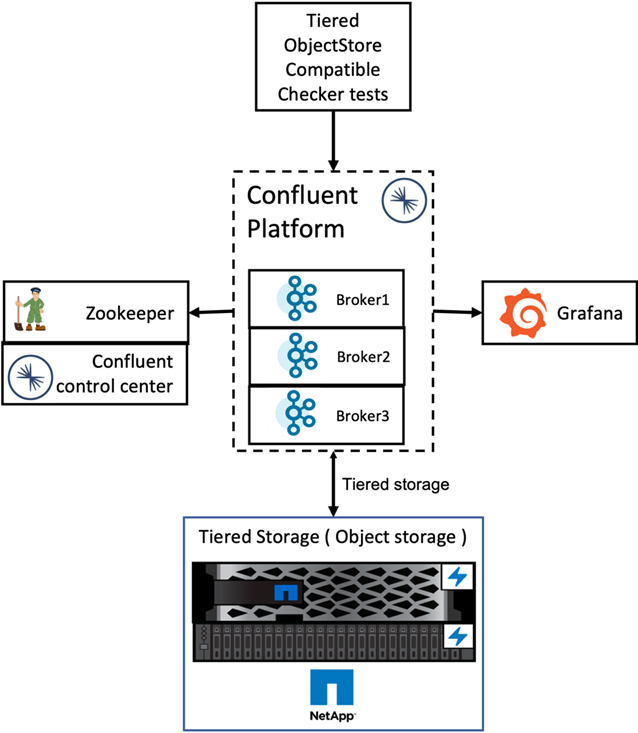
Abbiamo eseguito la verifica con Confluent Platform per l'archiviazione a livelli su NetApp ONTAP. I team NetApp e Confluent hanno lavorato insieme a questa verifica ed eseguito i casi di test richiesti.
Configurazione confluente
Per la configurazione abbiamo utilizzato tre guardiani dello zoo, cinque broker e cinque server di prova con 256 GB di RAM e 16 CPU. Per lo storage NetApp , abbiamo utilizzato ONTAP con una coppia AFF A900 HA. Lo storage e i broker erano collegati tramite connessioni 100GbE.
La figura seguente mostra la topologia di rete della configurazione utilizzata per la verifica dell'archiviazione a livelli.
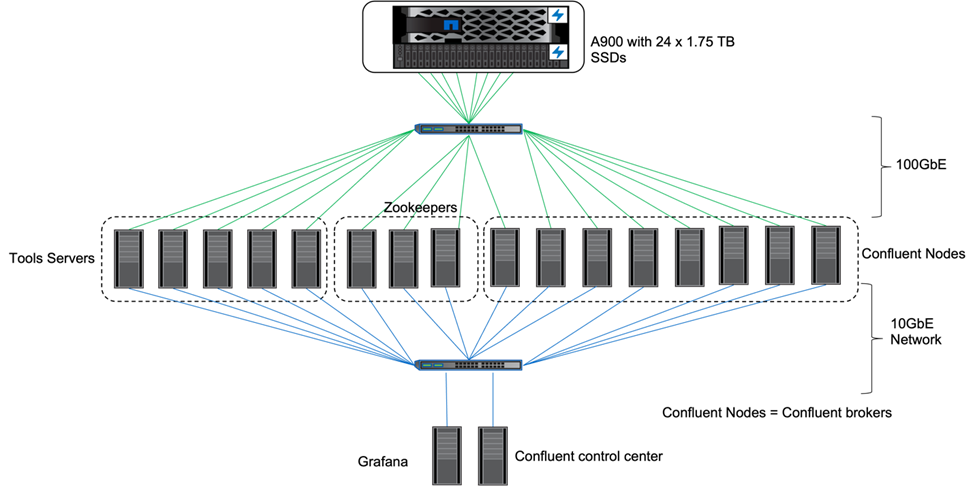
I server degli strumenti agiscono come client applicativi che inviano o ricevono eventi da o verso i nodi Confluent.
Configurazione di archiviazione a livelli confluenti
Abbiamo utilizzato i seguenti parametri di prova:
confluent.tier.fetcher.num.threads=80 confluent.tier.archiver.num.threads=80 confluent.tier.enable=true confluent.tier.feature=true confluent.tier.backend=S3 confluent.tier.s3.bucket=kafkabucket1-1 confluent.tier.s3.region=us-east-1 confluent.tier.s3.cred.file.path=/data/kafka/.ssh/credentials confluent.tier.s3.aws.endpoint.override=http://wle-mendocino-07-08/ confluent.tier.s3.force.path.style.access=true bootstrap.server=192.168.150.172:9092,192.168.150.120:9092,192.168.150.164:9092,192.168.150.198:9092,192.168.150.109:9092,192.168.150.165:9092,192.168.150.119:9092,192.168.150.133:9092 debug=true jmx.port=7203 num.partitions=80 num.records=200000000 #object PUT size - 512MB and fetch 100MB – netapp segment.bytes=536870912 max.partition.fetch.bytes=1048576000 #GET size is max.partition.fetch.bytes/num.partitions length.key.value=2048 trogdor.agent.nodes=node0,node1,node2,node3,node4 trogdor.coordinator.hostname.port=192.168.150.155:8889 num.producers=20 num.head.consumers=20 num.tail.consumers=1 test.binary.task.max.heap.size=32G test.binary.task.timeout.sec=3600 producer.timeout.sec=3600 consumer.timeout.sec=3600
Per la verifica abbiamo utilizzato ONTAP con il protocollo HTTP, ma ha funzionato anche HTTPS. La chiave di accesso e la chiave segreta sono memorizzate nel nome del file fornito nel confluent.tier.s3.cred.file.path parametro.
Controller di archiviazione NetApp – ONTAP
Abbiamo configurato una singola coppia HA in ONTAP per la verifica.
Risultati della verifica
Per la verifica abbiamo completato i seguenti cinque casi di test. I primi due erano test di funzionalità, mentre i restanti tre erano test di prestazioni.
Test di correttezza dell'archivio oggetti
Questo test esegue operazioni di base come get, put ed delete sull'archivio oggetti utilizzato per l'archiviazione a livelli tramite chiamate API.
Test di correttezza della funzionalità di tiering
Questo test verifica la funzionalità end-to-end dell'archiviazione degli oggetti. Crea un argomento, produce un flusso di eventi per l'argomento appena creato, attende che i broker archivino i segmenti nell'archivio oggetti, consuma il flusso di eventi e convalida la corrispondenza del flusso consumato con il flusso prodotto. Abbiamo eseguito questo test con e senza un'iniezione di errore nell'archivio oggetti. Abbiamo simulato un guasto del nodo arrestando il servizio di gestione dei servizi in uno dei nodi in ONTAP e convalidando che la funzionalità end-to-end funzioni con l'archiviazione degli oggetti.
Benchmark di recupero dei livelli
Questo test ha convalidato le prestazioni di lettura dell'archiviazione di oggetti a livelli e ha controllato le richieste di lettura di recupero dell'intervallo sotto carico pesante dai segmenti generati dal benchmark. In questo benchmark, Confluent ha sviluppato client personalizzati per soddisfare le richieste di recupero dei livelli.
Generatore di carico di lavoro di produzione-consumo
Questo test genera indirettamente un carico di lavoro di scrittura sull'archivio oggetti tramite l'archiviazione dei segmenti. Il carico di lavoro di lettura (segmenti letti) è stato generato dall'archiviazione degli oggetti quando i gruppi di consumatori hanno recuperato i segmenti. Questo carico di lavoro è stato generato da uno script TOCC. Questo test ha verificato le prestazioni di lettura e scrittura sull'archiviazione di oggetti in thread paralleli. Abbiamo eseguito i test con e senza l'iniezione di errori nell'archivio oggetti, come abbiamo fatto per il test di correttezza della funzionalità di tiering.
Generatore di carichi di lavoro di conservazione
Questo test ha verificato le prestazioni di eliminazione di un archivio di oggetti in presenza di un carico di lavoro di conservazione degli argomenti elevato. Il carico di lavoro di conservazione è stato generato utilizzando uno script TOCC che produce molti messaggi in parallelo a un argomento di prova. L'argomento del test era la configurazione con un'impostazione di conservazione aggressiva basata sulle dimensioni e sul tempo, che causava la continua eliminazione del flusso di eventi dall'archivio oggetti. I segmenti vennero poi archiviati. Ciò ha portato a numerose eliminazioni nell'archivio oggetti da parte del broker e alla raccolta delle prestazioni delle operazioni di eliminazione dell'archivio oggetti.
Per i dettagli di verifica, vedere il "Confluente" sito web.