

Panoramica della tecnologia
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione descrive la tecnologia utilizzata in questa soluzione.
NetApp StorageGRID
NetApp StorageGRID è una piattaforma di storage di oggetti conveniente e ad alte prestazioni. Utilizzando l'archiviazione a livelli, la maggior parte dei dati su Confluent Kafka, archiviati nell'archiviazione locale o nell'archiviazione SAN del broker, vengono scaricati nell'archivio oggetti remoto. Questa configurazione comporta notevoli miglioramenti operativi riducendo i tempi e i costi per ribilanciare, espandere o ridurre i cluster o sostituire un broker guasto. L'archiviazione di oggetti svolge un ruolo importante nella gestione dei dati che risiedono nel livello di archiviazione di oggetti, motivo per cui è importante scegliere l'archiviazione di oggetti giusta.
StorageGRID offre una gestione intelligente dei dati globali basata su policy, utilizzando un'architettura grid distribuita basata su nodi. Semplifica la gestione di petabyte di dati non strutturati e miliardi di oggetti attraverso il suo onnipresente spazio dei nomi degli oggetti globali combinato con sofisticate funzionalità di gestione dei dati. L'accesso agli oggetti con una sola chiamata si estende su più siti e semplifica le architetture ad alta disponibilità, garantendo al contempo un accesso continuo agli oggetti, indipendentemente dalle interruzioni del sito o dell'infrastruttura.
La multitenancy consente di gestire in modo sicuro più applicazioni cloud e dati aziendali non strutturati all'interno della stessa griglia, aumentando il ROI e i casi d'uso di NetApp StorageGRID. È possibile creare più livelli di servizio con policy del ciclo di vita degli oggetti basate sui metadati, ottimizzando la durabilità, la protezione, le prestazioni e la località in più aree geografiche. Gli utenti possono adattare le policy di gestione dei dati e monitorare e applicare limiti di traffico per riallinearsi al panorama dei dati senza interruzioni, man mano che le loro esigenze cambiano in ambienti IT in continua evoluzione.
Gestione semplice con Grid Manager
StorageGRID Grid Manager è un'interfaccia grafica basata su browser che consente di configurare, gestire e monitorare il sistema StorageGRID in sedi distribuite a livello globale da un unico pannello di controllo.
Con l'interfaccia di StorageGRID Grid Manager è possibile eseguire le seguenti attività:
-
Gestisci repository di oggetti quali immagini, video e record distribuiti a livello globale, su scala petabyte.
-
Monitorare i nodi e i servizi della griglia per garantire la disponibilità degli oggetti.
-
Gestire il posizionamento dei dati degli oggetti nel tempo utilizzando le regole di gestione del ciclo di vita delle informazioni (ILM). Queste regole stabiliscono cosa accade ai dati di un oggetto dopo che sono stati acquisiti, come vengono protetti dalla perdita, dove vengono archiviati i dati dell'oggetto e per quanto tempo.
-
Monitorare le transazioni, le prestazioni e le operazioni all'interno del sistema.
Politiche di gestione del ciclo di vita delle informazioni
StorageGRID dispone di policy di gestione dei dati flessibili che includono la conservazione di copie replicate degli oggetti e l'utilizzo di schemi EC (erasure coding) come 2+1 e 4+2 (tra gli altri) per archiviare gli oggetti, a seconda dei requisiti specifici di prestazioni e protezione dei dati. Poiché i carichi di lavoro e i requisiti cambiano nel tempo, è normale che anche le policy ILM debbano cambiare nel tempo. La modifica delle policy ILM è una funzionalità fondamentale che consente ai clienti StorageGRID di adattarsi in modo rapido e semplice al loro ambiente in continua evoluzione.
Prestazione
StorageGRID aumenta le prestazioni aggiungendo più nodi di storage, che possono essere VM, bare metal o appliance appositamente realizzate come"SG5712, SG5760, SG6060 o SGF6024" . Nei nostri test abbiamo superato i requisiti di prestazioni chiave di Apache Kafka con una griglia di tre nodi di dimensioni minime utilizzando l'appliance SGF6024. Man mano che i clienti ampliano il loro cluster Kafka con broker aggiuntivi, possono aggiungere più nodi di archiviazione per aumentare prestazioni e capacità.
Configurazione del bilanciatore del carico e degli endpoint
I nodi amministrativi in StorageGRID forniscono l'interfaccia utente (UI) di Grid Manager e l'endpoint API REST per visualizzare, configurare e gestire il sistema StorageGRID , nonché registri di controllo per monitorare l'attività del sistema. Per fornire un endpoint S3 ad alta disponibilità per l'archiviazione a livelli Confluent Kafka, abbiamo implementato il bilanciatore del carico StorageGRID , che viene eseguito come servizio sui nodi di amministrazione e sui nodi gateway. Inoltre, il bilanciatore del carico gestisce anche il traffico locale e comunica con il GSLB (Global Server Load Balancing) per facilitare il ripristino in caso di emergenza.
Per migliorare ulteriormente la configurazione degli endpoint, StorageGRID fornisce criteri di classificazione del traffico integrati nel nodo di amministrazione, consente di monitorare il traffico del carico di lavoro e applica vari limiti di qualità del servizio (QoS) ai carichi di lavoro. I criteri di classificazione del traffico vengono applicati agli endpoint del servizio StorageGRID Load Balancer per i nodi gateway e i nodi amministrativi. Queste politiche possono aiutare a modellare e monitorare il traffico.
Classificazione del traffico in StorageGRID
StorageGRID ha funzionalità QoS integrate. Le policy di classificazione del traffico possono aiutare a monitorare diversi tipi di traffico S3 provenienti da un'applicazione client. È quindi possibile creare e applicare policy per limitare questo traffico in base alla larghezza di banda in entrata/uscita, al numero di richieste di lettura/scrittura simultanee o alla velocità delle richieste di lettura/scrittura.
Apache Kafka
Apache Kafka è un framework di implementazione di un bus software che utilizza l'elaborazione di flussi, scritto in Java e Scala. Il suo scopo è fornire una piattaforma unificata, ad alta produttività e bassa latenza per la gestione di feed di dati in tempo reale. Kafka può connettersi a un sistema esterno per l'esportazione e l'importazione di dati tramite Kafka Connect e fornisce Kafka streams, una libreria di elaborazione di flussi Java. Kafka utilizza un protocollo binario basato su TCP, ottimizzato per l'efficienza e basato su un'astrazione di "set di messaggi" che raggruppa naturalmente i messaggi per ridurre il sovraccarico del roundtrip di rete. Ciò consente operazioni sequenziali su disco più grandi, pacchetti di rete più grandi e blocchi di memoria contigui, consentendo così a Kafka di trasformare un flusso continuo di scritture di messaggi casuali in scritture lineari. La figura seguente illustra il flusso di dati di base di Apache Kafka.
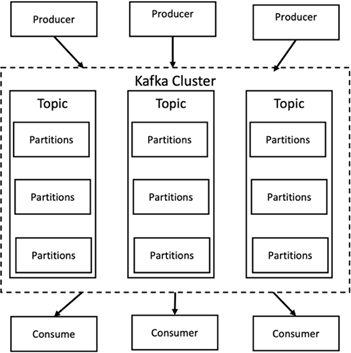
Kafka memorizza messaggi chiave-valore provenienti da un numero arbitrario di processi chiamati produttori. I dati possono essere suddivisi in diverse partizioni all'interno di argomenti diversi. All'interno di una partizione, i messaggi vengono ordinati rigorosamente in base ai loro offset (la posizione di un messaggio all'interno di una partizione) e indicizzati e archiviati insieme a un timestamp. Altri processi chiamati consumatori possono leggere i messaggi dalle partizioni. Per l'elaborazione dei flussi, Kafka offre l'API Streams che consente di scrivere applicazioni Java che utilizzano dati da Kafka e scrivono i risultati in Kafka. Apache Kafka funziona anche con sistemi di elaborazione di flussi esterni come Apache Apex, Apache Flink, Apache Spark, Apache Storm e Apache NiFi.
Kafka viene eseguito su un cluster di uno o più server (chiamati broker) e le partizioni di tutti gli argomenti sono distribuite tra i nodi del cluster. Inoltre, le partizioni vengono replicate su più broker. Questa architettura consente a Kafka di distribuire flussi massivi di messaggi in modalità fault-tolerant e gli ha permesso di sostituire alcuni dei sistemi di messaggistica convenzionali come Java Message Service (JMS), Advanced Message Queuing Protocol (AMQP) e così via. A partire dalla versione 0.11.0.0, Kafka offre scritture transazionali, che forniscono l'elaborazione di flussi esattamente una volta utilizzando l'API Streams.
Kafka supporta due tipi di argomenti: regolari e compattati. Gli argomenti regolari possono essere configurati con un limite di tempo di conservazione o di spazio. Se sono presenti record più vecchi del tempo di conservazione specificato o se viene superato il limite di spazio per una partizione, Kafka può eliminare i vecchi dati per liberare spazio di archiviazione. Per impostazione predefinita, gli argomenti sono configurati con un tempo di conservazione di 7 giorni, ma è anche possibile archiviare i dati a tempo indeterminato. Per gli argomenti compattati, i record non scadono in base a limiti di tempo o di spazio. Kafka, invece, tratta i messaggi successivi come aggiornamenti di messaggi più vecchi con la stessa chiave e garantisce di non eliminare mai l'ultimo messaggio per chiave. Gli utenti possono eliminare completamente i messaggi scrivendo un cosiddetto messaggio tombstone con il valore null per una chiave specifica.
Ci sono cinque API principali in Kafka:
-
API del produttore. Consente a un'applicazione di pubblicare flussi di record.
-
API per i consumatori. Consente a un'applicazione di iscriversi ad argomenti ed elaborare flussi di record.
-
API del connettore. Esegue le API riutilizzabili del produttore e del consumatore che possono collegare gli argomenti alle applicazioni esistenti.
-
API Stream. Questa API converte i flussi di input in output e produce il risultato.
-
API di amministrazione. Utilizzato per gestire argomenti Kafka, broker e altri oggetti Kafka.
Le API consumer e producer si basano sul protocollo di messaggistica Kafka e offrono un'implementazione di riferimento per i client consumer e producer Kafka in Java. Il protocollo di messaggistica sottostante è un protocollo binario che gli sviluppatori possono utilizzare per scrivere i propri client consumer o producer in qualsiasi linguaggio di programmazione. Ciò sblocca Kafka dall'ecosistema Java Virtual Machine (JVM). Un elenco dei client non Java disponibili è disponibile nel wiki di Apache Kafka.
Casi d'uso di Apache Kafka
Apache Kafka è particolarmente diffuso per la messaggistica, il monitoraggio delle attività sui siti web, le metriche, l'aggregazione dei log, l'elaborazione dei flussi, l'event sourcing e la registrazione degli commit.
-
Kafka ha migliorato la produttività, ha integrato il partizionamento, la replica e la tolleranza agli errori, il che lo rende una buona soluzione per applicazioni di elaborazione dei messaggi su larga scala.
-
Kafka può ricostruire le attività di un utente (visualizzazioni di pagina, ricerche) in una pipeline di monitoraggio come un insieme di feed di pubblicazione-sottoscrizione in tempo reale.
-
Kafka viene spesso utilizzato per i dati di monitoraggio operativo. Ciò comporta l'aggregazione di statistiche provenienti da applicazioni distribuite per produrre feed centralizzati di dati operativi.
-
Molte persone utilizzano Kafka come sostituto di una soluzione di aggregazione dei log. L'aggregazione dei log in genere raccoglie i file di log fisici dai server e li colloca in un luogo centrale (ad esempio, un file server o HDFS) per l'elaborazione. Kafka astrae i dettagli dei file e fornisce un'astrazione più pulita dei dati di log o di eventi come flusso di messaggi. Ciò consente un'elaborazione a bassa latenza e un supporto più semplice per più fonti di dati e un consumo di dati distribuito.
-
Molti utenti di Kafka elaborano i dati in pipeline di elaborazione costituite da più fasi, in cui i dati di input grezzi vengono utilizzati dagli argomenti di Kafka e quindi aggregati, arricchiti o altrimenti trasformati in nuovi argomenti per un ulteriore utilizzo o un'elaborazione successiva. Ad esempio, una pipeline di elaborazione per consigliare articoli di notizie potrebbe analizzare il contenuto degli articoli dai feed RSS e pubblicarlo in un argomento "articoli". Un'ulteriore elaborazione potrebbe normalizzare o deduplicare questo contenuto e pubblicare il contenuto dell'articolo ripulito in un nuovo argomento; una fase di elaborazione finale potrebbe tentare di consigliare questo contenuto agli utenti. Tali pipeline di elaborazione creano grafici di flussi di dati in tempo reale basati sui singoli argomenti.
-
L'event souring è uno stile di progettazione delle applicazioni in cui le modifiche di stato vengono registrate come una sequenza di record ordinata nel tempo. Il supporto di Kafka per dati di log memorizzati di grandi dimensioni lo rende un backend eccellente per un'applicazione creata in questo stile.
-
Kafka può fungere da una sorta di registro di commit esterno per un sistema distribuito. Il registro aiuta a replicare i dati tra i nodi e funge da meccanismo di risincronizzazione per i nodi non riusciti per ripristinare i propri dati. La funzionalità di compattazione dei log in Kafka aiuta a supportare questo caso d'uso.
Confluente
Confluent Platform è una piattaforma pronta per le aziende che completa Kafka con funzionalità avanzate progettate per accelerare lo sviluppo e la connettività delle applicazioni, abilitare le trasformazioni tramite l'elaborazione in streaming, semplificare le operazioni aziendali su larga scala e soddisfare rigorosi requisiti architettonici. Sviluppato dai creatori originali di Apache Kafka, Confluent amplia i vantaggi di Kafka con funzionalità di livello aziendale, eliminando al contempo l'onere della gestione o del monitoraggio di Kafka. Oggi, oltre l'80% delle aziende Fortune 100 si avvale della tecnologia di streaming dei dati e la maggior parte di queste utilizza Confluent.
Perché Confluent?
Integrando dati storici e in tempo reale in un'unica fonte centrale di verità, Confluent semplifica la creazione di una categoria completamente nuova di applicazioni moderne basate sugli eventi, l'acquisizione di una pipeline di dati universale e lo sblocco di nuovi potenti casi d'uso con piena scalabilità, prestazioni e affidabilità.
A cosa serve Confluent?
Confluent Platform ti consente di concentrarti su come ricavare valore aziendale dai tuoi dati anziché preoccuparti dei meccanismi sottostanti, ad esempio come i dati vengono trasportati o integrati tra sistemi diversi. Nello specifico, Confluent Platform semplifica la connessione delle fonti di dati a Kafka, la creazione di applicazioni di streaming, nonché la protezione, il monitoraggio e la gestione dell'infrastruttura Kafka. Oggi, Confluent Platform viene utilizzata per un'ampia gamma di casi d'uso in numerosi settori, dai servizi finanziari, alla vendita al dettaglio omnicanale e alle auto autonome, fino al rilevamento delle frodi, ai microservizi e all'IoT.
La figura seguente mostra i componenti della piattaforma Confluent Kafka.
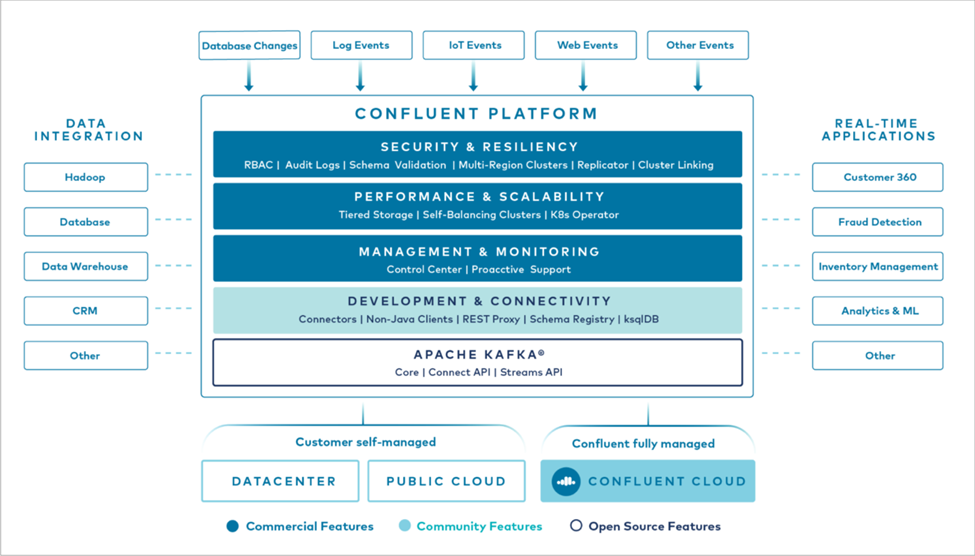
Panoramica della tecnologia di streaming degli eventi di Confluent
Il cuore della piattaforma Confluent è "Apache Kafka" , la piattaforma di streaming distribuita open source più popolare. Le principali capacità di Kafka sono le seguenti:
-
Pubblica e abbonati a flussi di record.
-
Memorizzare flussi di record in modo tollerante agli errori.
-
Elaborare flussi di record.
Confluent Platform include anche Schema Registry, REST Proxy, un totale di oltre 100 connettori Kafka predefiniti e ksqlDB.
Panoramica delle funzionalità aziendali della piattaforma Confluent
-
Centro di controllo confluente. Un sistema basato su GUI per la gestione e il monitoraggio di Kafka. Consente di gestire facilmente Kafka Connect e di creare, modificare e gestire connessioni ad altri sistemi.
-
Confluent per Kubernetes. Confluent per Kubernetes è un operatore Kubernetes. Gli operatori Kubernetes estendono le capacità di orchestrazione di Kubernetes fornendo funzionalità e requisiti esclusivi per una specifica applicazione della piattaforma. Per Confluent Platform, ciò include una notevole semplificazione del processo di distribuzione di Kafka su Kubernetes e l'automazione delle tipiche attività del ciclo di vita dell'infrastruttura.
-
Connettori confluenti con Kafka. I connettori utilizzano l'API Kafka Connect per connettere Kafka ad altri sistemi, quali database, archivi chiave-valore, indici di ricerca e file system. Confluent Hub dispone di connettori scaricabili per le fonti e i sink di dati più diffusi, comprese versioni completamente testate e supportate di questi connettori con Confluent Platform. Maggiori dettagli possono essere trovati "Qui" .
-
Cluster autobilancianti. Fornisce bilanciamento automatico del carico, rilevamento degli errori e auto-riparazione. Fornisce supporto per l'aggiunta o la disattivazione di broker in base alle necessità, senza necessità di ottimizzazione manuale.
-
Collegamento di cluster confluenti. Collega direttamente i cluster tra loro e rispecchia gli argomenti da un cluster all'altro tramite un ponte di collegamento. Il collegamento dei cluster semplifica la configurazione di distribuzioni multi-datacenter, multi-cluster e cloud ibride.
-
Bilanciatore automatico dei dati Confluent. Monitora il cluster per quanto riguarda il numero di broker, la dimensione delle partizioni, il numero di partizioni e il numero di leader all'interno del cluster. Consente di spostare i dati per creare un carico di lavoro uniforme nel cluster, limitando al contempo il traffico di ribilanciamento per ridurre al minimo l'effetto sui carichi di lavoro di produzione durante il ribilanciamento.
-
Replicatore confluente. Rende più semplice che mai la gestione di più cluster Kafka in più data center.
-
Archiviazione a livelli. Offre opzioni per archiviare grandi volumi di dati Kafka utilizzando il tuo provider cloud preferito, riducendo così i costi e gli oneri operativi. Grazie all'archiviazione a livelli, puoi conservare i dati su un archivio oggetti conveniente e utilizzare broker di scalabilità solo quando hai bisogno di più risorse di elaborazione.
-
Client JMS confluente. Confluent Platform include un client compatibile con JMS per Kafka. Questo client Kafka implementa l'API standard JMS 1.1, utilizzando i broker Kafka come backend. Questa funzionalità è utile se si dispone di applicazioni legacy che utilizzano JMS e si desidera sostituire il broker di messaggi JMS esistente con Kafka.
-
Proxy MQTT confluente. Fornisce un modo per pubblicare dati direttamente su Kafka da dispositivi e gateway MQTT senza la necessità di un broker MQTT intermedio.
-
Plugin di sicurezza Confluent. I plugin di sicurezza Confluent vengono utilizzati per aggiungere funzionalità di sicurezza a vari strumenti e prodotti della piattaforma Confluent. Attualmente è disponibile un plugin per il proxy REST Confluent che aiuta ad autenticare le richieste in arrivo e a propagare il principal autenticato alle richieste a Kafka. Ciò consente ai client proxy REST Confluent di utilizzare le funzionalità di sicurezza multitenant del broker Kafka.