

Panoramica delle soluzioni NetApp Spark
 Suggerisci modifiche
Suggerisci modifiche
NetApp dispone di tre portafogli di storage: FAS/ AFF, E-Series e Cloud Volumes ONTAP. Abbiamo convalidato AFF e la serie E con il sistema di archiviazione ONTAP per le soluzioni Hadoop con Apache Spark.
Il data fabric basato su NetApp integra servizi e applicazioni di gestione dei dati (elementi costitutivi) per l'accesso, il controllo, la protezione e la sicurezza dei dati, come mostrato nella figura seguente.
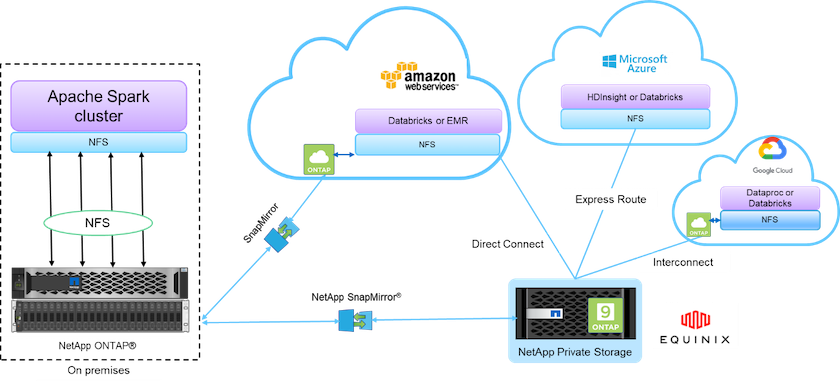
Gli elementi costitutivi nella figura sopra includono:
-
* Accesso diretto NetApp NFS.* Fornisce i cluster Hadoop e Spark più recenti con accesso diretto ai volumi NetApp NFS senza requisiti aggiuntivi di software o driver.
-
* NetApp Cloud Volumes ONTAP e Google Cloud NetApp Volumes.* Archiviazione connessa definita dal software basata su ONTAP in esecuzione in Amazon Web Services (AWS) o Azure NetApp Files (ANF) nei servizi cloud di Microsoft Azure.
-
* Tecnologia NetApp SnapMirror .* Fornisce funzionalità di protezione dei dati tra istanze locali e istanze ONTAP Cloud o NPS.
-
Fornitori di servizi cloud. Tra questi fornitori figurano AWS, Microsoft Azure, Google Cloud e IBM Cloud.
-
PaaS. Servizi di analisi basati su cloud come Amazon Elastic MapReduce (EMR) e Databricks in AWS, nonché Microsoft Azure HDInsight e Azure Databricks.
La figura seguente illustra la soluzione Spark con storage NetApp .
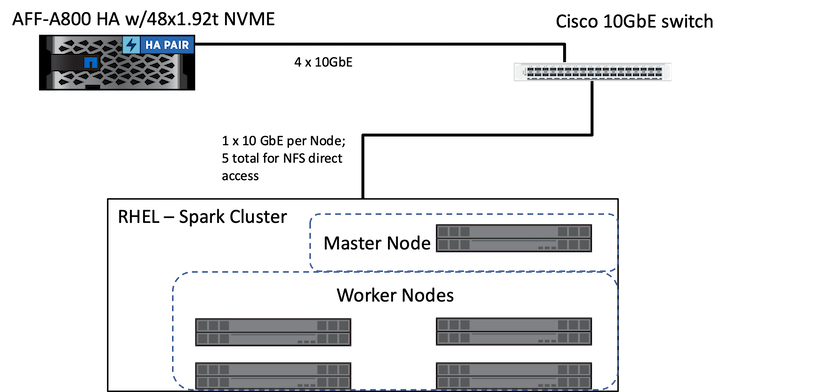
La soluzione ONTAP Spark utilizza il protocollo di accesso diretto NetApp NFS per analisi in loco e flussi di lavoro AI, ML e DL utilizzando l'accesso ai dati di produzione esistenti. I dati di produzione disponibili per i nodi Hadoop vengono esportati per eseguire analisi in loco e attività di intelligenza artificiale, apprendimento automatico e apprendimento automatico (IA), nonché attività di DL. È possibile accedere ai dati da elaborare nei nodi Hadoop con o senza accesso diretto NetApp NFS. In Spark con la versione standalone o yarn gestore cluster, è possibile configurare un volume NFS utilizzando file://<target_volume> . Abbiamo convalidato tre casi d'uso con diversi set di dati. I dettagli di queste convalide sono presentati nella sezione "Risultati dei test". (xrif)
La figura seguente illustra il posizionamento dello storage NetApp Apache Spark/Hadoop.
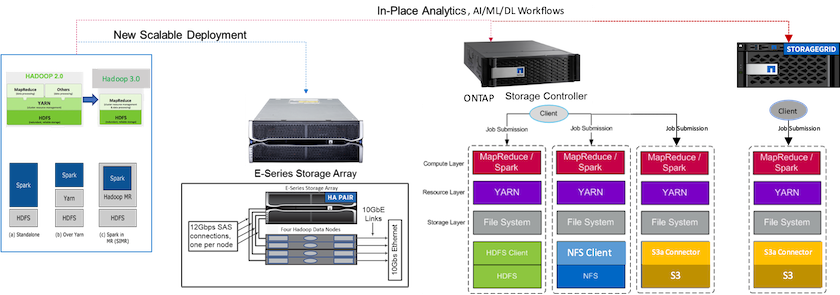
Abbiamo identificato le caratteristiche uniche della soluzione E-Series Spark, della soluzione AFF/ FAS ONTAP Spark e della soluzione StorageGRID Spark, e abbiamo eseguito convalide e test dettagliati. Sulla base delle nostre osservazioni, NetApp consiglia la soluzione E-Series per installazioni greenfield e nuove distribuzioni scalabili e la soluzione AFF/ FAS per analisi in loco, carichi di lavoro AI, ML e DL utilizzando dati NFS esistenti e StorageGRID per AI, ML e DL e analisi dei dati moderne quando è richiesto l'archiviazione di oggetti.
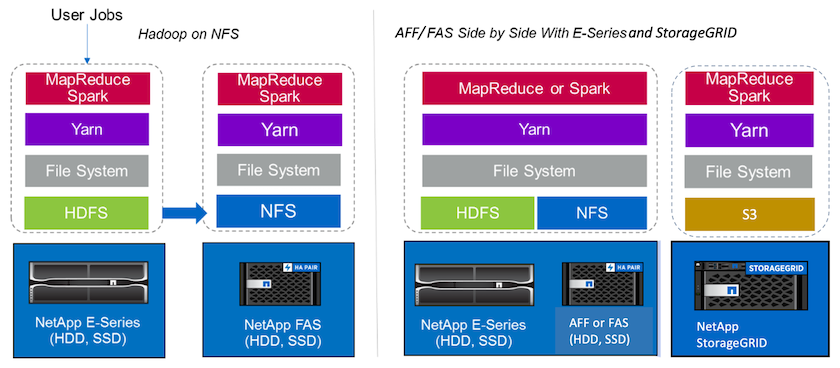
Un data lake è un repository di archiviazione per grandi set di dati in formato nativo che può essere utilizzato per attività di analisi, intelligenza artificiale, apprendimento automatico e DL. Abbiamo creato un repository di data lake per le soluzioni E-Series, AFF/ FAS e StorageGRID SG6060 Spark. Il sistema E-Series fornisce l'accesso HDFS al cluster Hadoop Spark, mentre l'accesso ai dati di produzione esistenti avviene tramite il protocollo di accesso diretto NFS al cluster Hadoop. Per i set di dati che risiedono nell'archiviazione di oggetti, NetApp StorageGRID fornisce accesso sicuro S3 e S3a.