

Tiering intelligente e risparmio sui costi
 Suggerisci modifiche
Suggerisci modifiche
Man mano che i clienti si rendono conto della potenza e della semplicità di utilizzo dell'analisi dei dati di Splunk, è naturale che vogliano indicizzare una quantità di dati sempre maggiore. Con l'aumentare della quantità di dati, aumenta anche l'infrastruttura di elaborazione e archiviazione necessaria per gestirli. Poiché i dati più vecchi vengono consultati meno frequentemente, impegnare la stessa quantità di risorse di elaborazione e consumare costosi archivi primari diventa sempre più inefficiente. Per operare su larga scala, i clienti traggono vantaggio dallo spostamento dei dati "caldi" a un livello più conveniente, liberando risorse di elaborazione e di storage primario per i dati "caldi".
Splunk SmartStore con StorageGRID offre alle organizzazioni una soluzione scalabile, performante e conveniente. Poiché SmartStore è consapevole dei dati, valuta automaticamente i modelli di accesso ai dati per determinare quali dati devono essere accessibili per analisi in tempo reale (dati attivi) e quali dati devono risiedere in un archivio a lungo termine a basso costo (dati attivi). SmartStore utilizza in modo dinamico e intelligente l'API AWS S3, standard del settore, inserendo i dati nello storage S3 fornito da StorageGRID. L'architettura flessibile e scalabile di StorageGRID consente al livello di dati caldi di crescere in modo economicamente vantaggioso in base alle necessità. L'architettura basata su nodi di StorageGRID garantisce che i requisiti di prestazioni e costi siano soddisfatti in modo ottimale.
L'immagine seguente illustra la suddivisione in livelli di Splunk e StorageGRID .
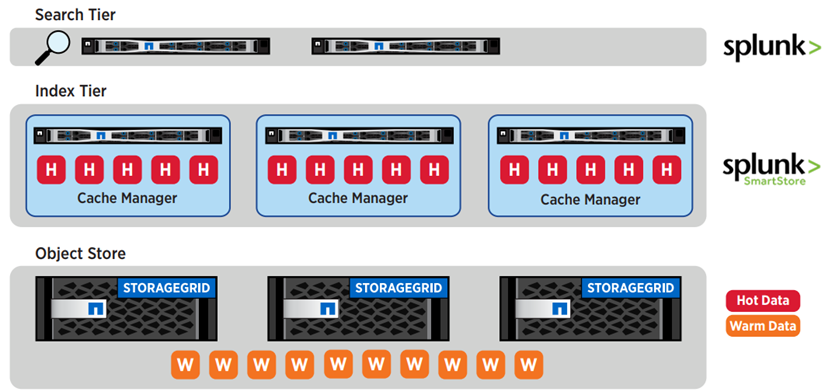
La combinazione leader del settore di Splunk SmartStore con NetApp StorageGRID offre i vantaggi di un'architettura disaccoppiata tramite una soluzione full-stack.