

Risultati dei test
 Suggerisci modifiche
Suggerisci modifiche
Sono stati eseguiti numerosi test per valutare le prestazioni dell'architettura proposta.
Sono disponibili sei diversi carichi di lavoro (classificazione delle immagini, rilevamento di oggetti [piccolo], rilevamento di oggetti [grande], imaging medico, conversione di parlato in testo ed elaborazione del linguaggio naturale [NLP]), che è possibile eseguire in tre scenari diversi: offline, flusso singolo e multiflusso.

|
L'ultimo scenario è implementato solo per la classificazione delle immagini e il rilevamento degli oggetti. |
Ciò fornisce 15 possibili carichi di lavoro, tutti testati in tre configurazioni diverse:
-
Server singolo/archiviazione locale
-
Server singolo/archiviazione di rete
-
Archiviazione multi-server/di rete
I risultati sono descritti nelle sezioni seguenti.
Inferenza AI in uno scenario offline per AFF
In questo scenario, tutti i dati erano disponibili sul server ed è stato misurato il tempo impiegato per elaborare tutti i campioni. Come risultati dei test riportiamo le larghezze di banda in campioni al secondo. Quando è stato utilizzato più di un server di elaborazione, riportiamo la larghezza di banda totale sommata su tutti i server. I risultati per tutti e tre i casi d'uso sono mostrati nella figura seguente. Nel caso di due server, riportiamo la larghezza di banda combinata di entrambi i server.
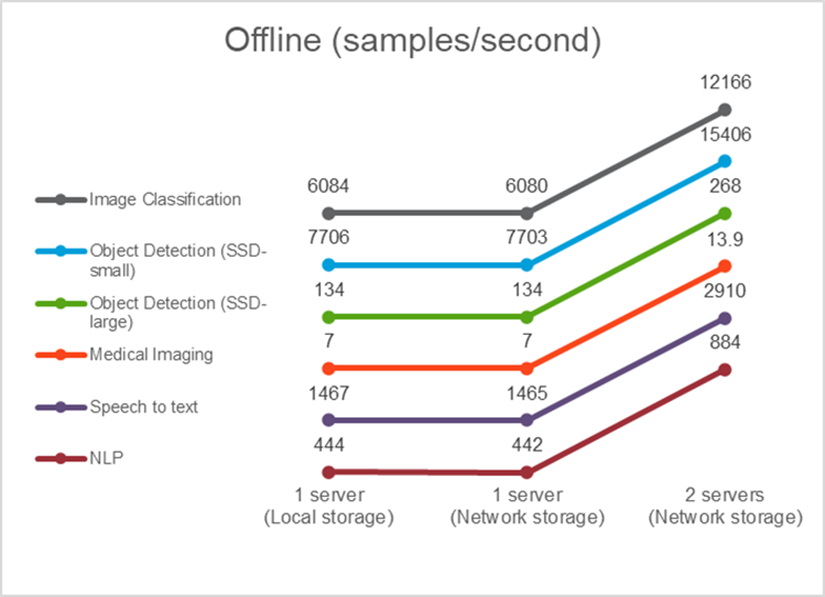
I risultati mostrano che l'archiviazione di rete non influisce negativamente sulle prestazioni: la modifica è minima e per alcune attività non si riscontra alcuna modifica. Aggiungendo il secondo server, la larghezza di banda totale raddoppia esattamente o, nel peggiore dei casi, la variazione è inferiore all'1%.
Inferenza AI in uno scenario a flusso singolo per AFF
Questo benchmark misura la latenza. Nel caso di più server di calcolo, riportiamo la latenza media. I risultati per la serie di attività sono riportati nella figura sottostante. Nel caso di due server, riportiamo la latenza media di entrambi i server.
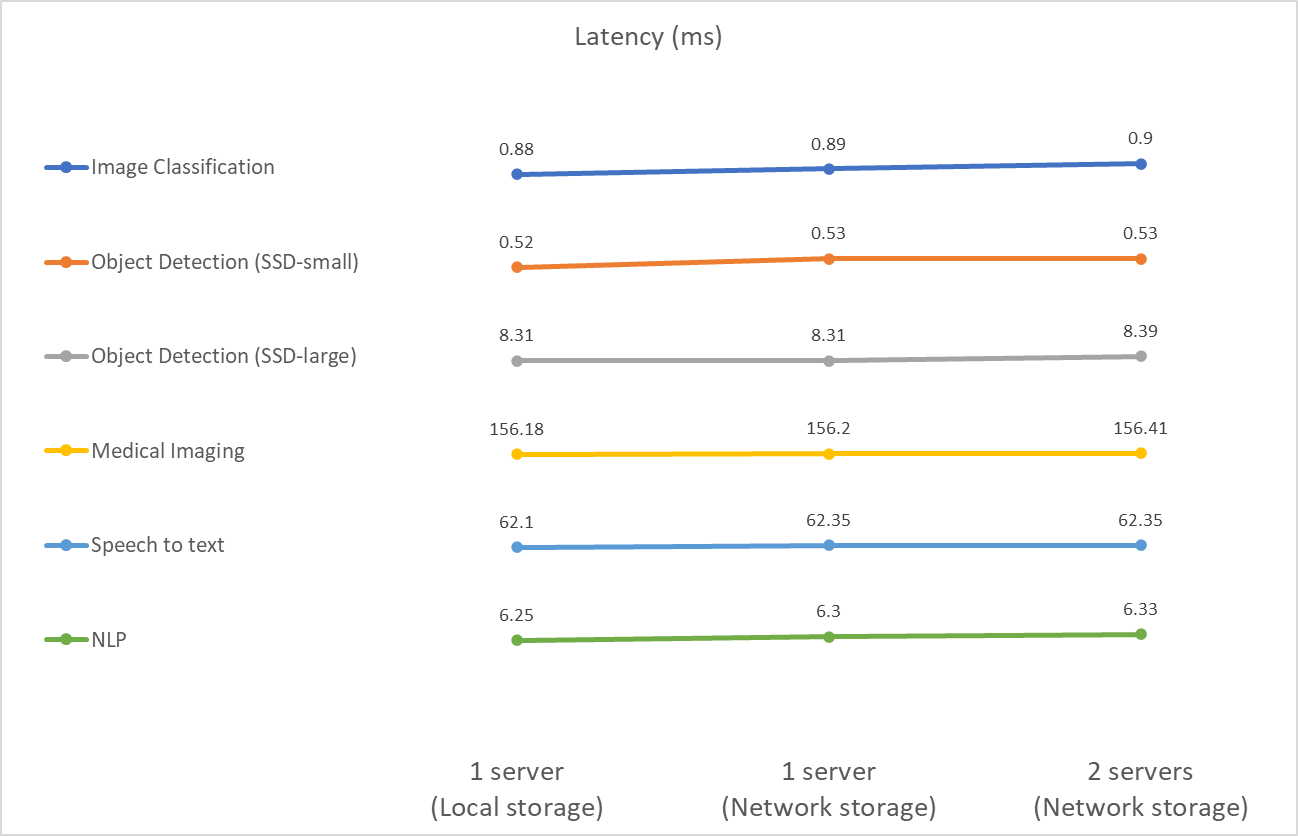
I risultati dimostrano ancora una volta che lo storage di rete è sufficiente per gestire le attività. Nel caso di un singolo server, la differenza tra storage locale e storage di rete è minima o nulla. Allo stesso modo, quando due server utilizzano lo stesso storage, la latenza su entrambi i server rimane invariata o cambia di poco.
Inferenza AI in uno scenario multistream per AFF
In questo caso, il risultato è il numero di flussi che il sistema può gestire rispettando il vincolo QoS. Pertanto il risultato è sempre un numero intero. Per più di un server, riportiamo il numero totale di flussi sommati su tutti i server. Non tutti i carichi di lavoro supportano questo scenario, ma abbiamo eseguito quelli che lo supportano. I risultati dei nostri test sono riassunti nella figura seguente. Nel caso di due server, riportiamo il numero combinato di flussi da entrambi i server.
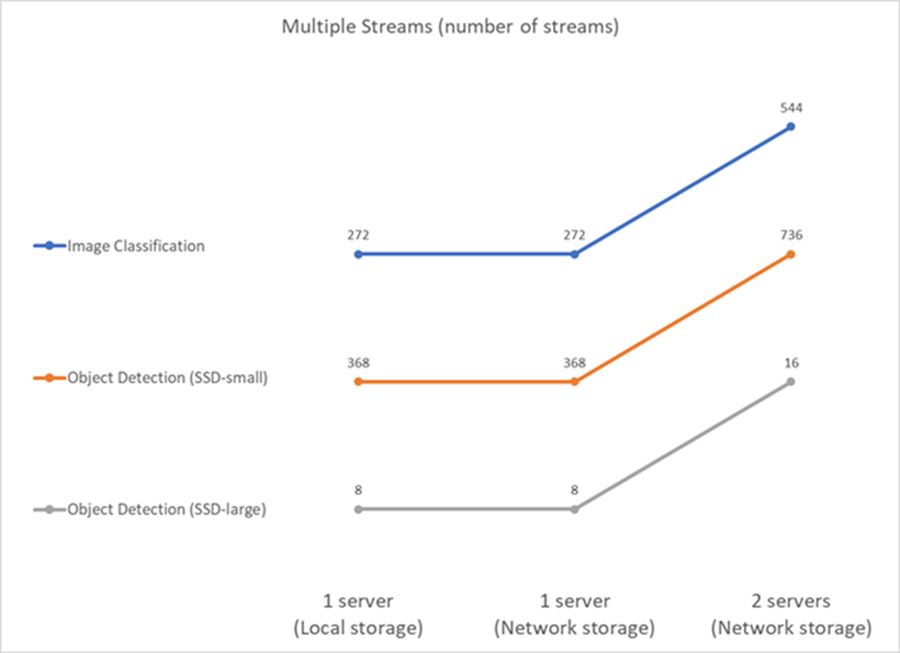
I risultati mostrano prestazioni perfette della configurazione: l'archiviazione locale e di rete danno gli stessi risultati e l'aggiunta del secondo server raddoppia il numero di flussi che la configurazione proposta può gestire.
Risultati dei test per EF
Sono stati eseguiti numerosi test per valutare le prestazioni dell'architettura proposta. Sono stati eseguiti sei carichi di lavoro diversi (classificazione delle immagini, rilevamento di oggetti [piccolo], rilevamento di oggetti [grande], imaging medico, conversione di parlato in testo ed elaborazione del linguaggio naturale [NLP]), che sono stati eseguiti in due scenari diversi: offline e flusso singolo. I risultati sono descritti nelle sezioni seguenti.
Inferenza AI in uno scenario offline per EF
In questo scenario, tutti i dati erano disponibili sul server ed è stato misurato il tempo impiegato per elaborare tutti i campioni. Come risultati dei test riportiamo le larghezze di banda in campioni al secondo. Per le esecuzioni su un singolo nodo riportiamo la media di entrambi i server, mentre per le esecuzioni su due server riportiamo la larghezza di banda totale sommata su tutti i server. I risultati per i casi d'uso sono mostrati nella figura seguente.
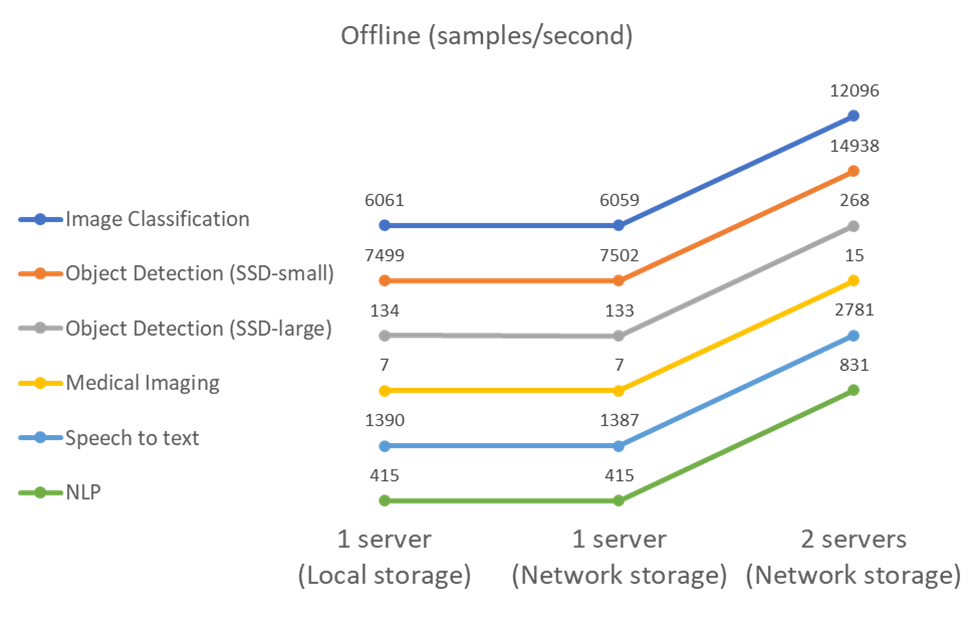
I risultati mostrano che l'archiviazione di rete non influisce negativamente sulle prestazioni: la modifica è minima e per alcune attività non si riscontra alcuna modifica. Aggiungendo il secondo server, la larghezza di banda totale raddoppia esattamente o, nel peggiore dei casi, la variazione è inferiore all'1%.
Inferenza AI in uno scenario a flusso singolo per EF
Questo benchmark misura la latenza. Per tutti i casi, riportiamo la latenza media su tutti i server coinvolti nelle esecuzioni. Vengono forniti i risultati per la serie di attività.
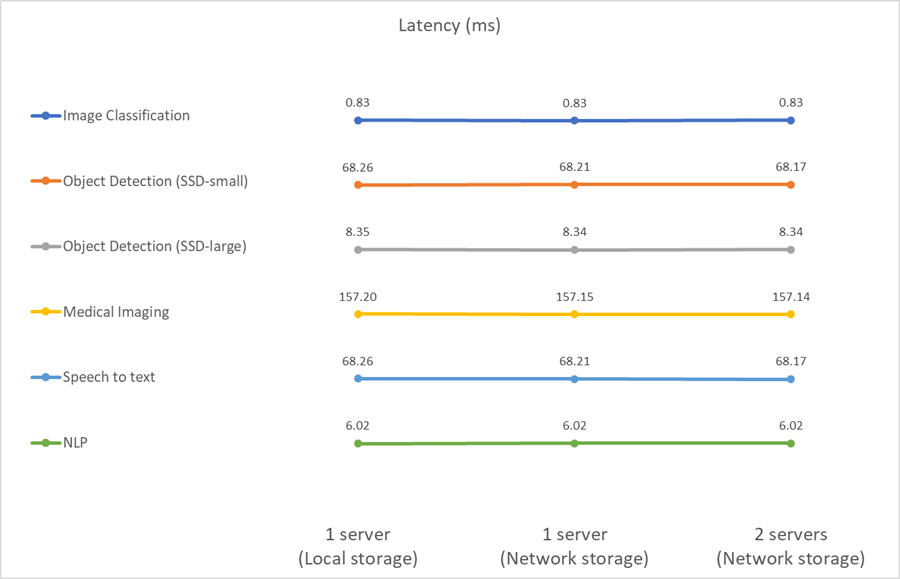
I risultati dimostrano ancora una volta che lo storage di rete è sufficiente per gestire le attività. La differenza tra l'archiviazione locale e quella di rete nel caso di un singolo server è minima o nulla. Allo stesso modo, quando due server utilizzano lo stesso storage, la latenza su entrambi i server rimane invariata o cambia di poco.