

Procedura di prova
 Suggerisci modifiche
Suggerisci modifiche
In questa sezione vengono descritte le attività necessarie per completare la convalida.
Prerequisiti
Per eseguire le attività descritte in questa sezione, è necessario avere accesso a un host Linux o macOS con i seguenti strumenti installati e configurati:
Scenario 1 – Inferenza su richiesta in JupyterLab
-
Creare uno spazio dei nomi Kubernetes per carichi di lavoro di inferenza AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilizzare NetApp DataOps Toolkit per predisporre un volume persistente in cui archiviare i dati su cui eseguire l'inferenza.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Utilizzare NetApp DataOps Toolkit per creare un nuovo spazio di lavoro JupyterLab. Montare il volume persistente creato nel passaggio precedente utilizzando
--mount- pvcopzione. Assegnare le GPU NVIDIA all'area di lavoro secondo necessità utilizzando-- nvidia-gpuopzione.Nell'esempio seguente, il volume persistente
inference-dataè montato sul contenitore dell'area di lavoro JupyterLab in/home/jovyan/data. Quando si utilizzano immagini ufficiali del contenitore Project Jupyter,/home/jovyanviene presentata come directory di primo livello all'interno dell'interfaccia web di JupyterLab.$ netapp_dataops_k8s_cli.py create jupyterlab --namespace=inference --workspace-name=live-inference --size=50Gi --nvidia-gpu=2 --mount-pvc=inference-data:/home/jovyan/data Set workspace password (this password will be required in order to access the workspace): Re-enter password: Creating persistent volume for workspace... Creating PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Creating Service 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Service successfully created. Attaching Additional PVC: 'inference-data' at mount_path: '/home/jovyan/data'. Creating Deployment 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Deployment 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Deployment 'ntap-dsutil-jupyterlab-live-inference' to reach Ready state. Deployment successfully created. Workspace successfully created. To access workspace, navigate to http://192.168.0.152:32721
-
Accedi all'area di lavoro JupyterLab utilizzando l'URL specificato nell'output del
create jupyterlabcomando. La directory dati rappresenta il volume persistente montato nell'area di lavoro.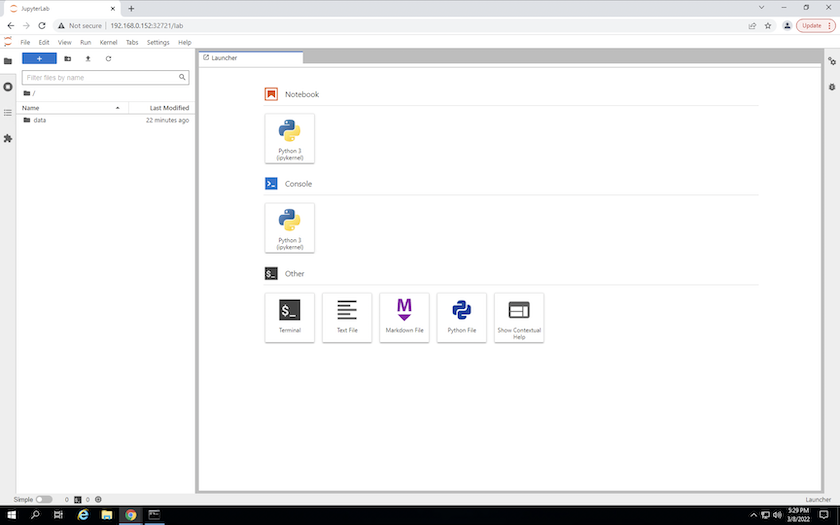
-
Apri il
datadirectory e caricare i file su cui eseguire l'inferenza. Quando i file vengono caricati nella directory dati, vengono automaticamente archiviati sul volume persistente montato nell'area di lavoro. Per caricare i file, fare clic sull'icona Carica file, come mostrato nell'immagine seguente.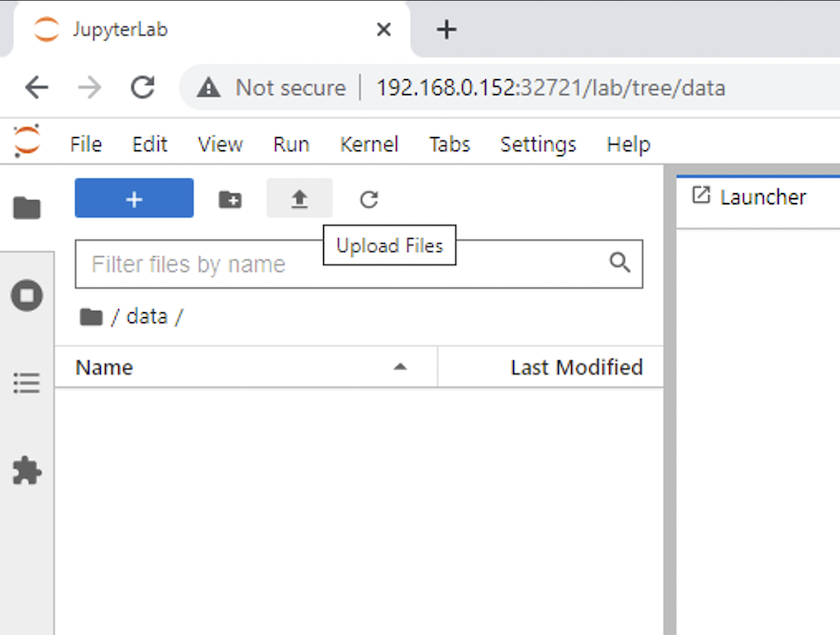
-
Torna alla directory di livello superiore e crea un nuovo notebook.
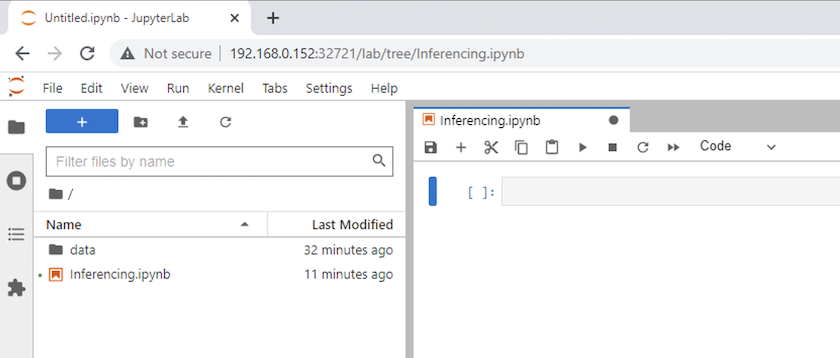
-
Aggiungere il codice di inferenza al notebook. L'esempio seguente mostra il codice di inferenza per un caso d'uso di rilevamento delle immagini.
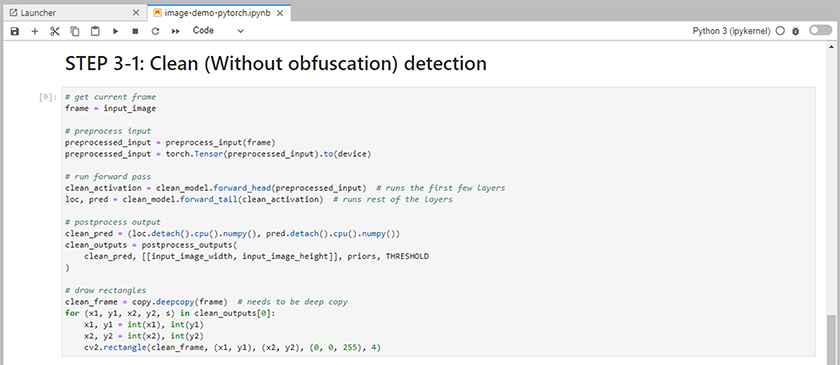
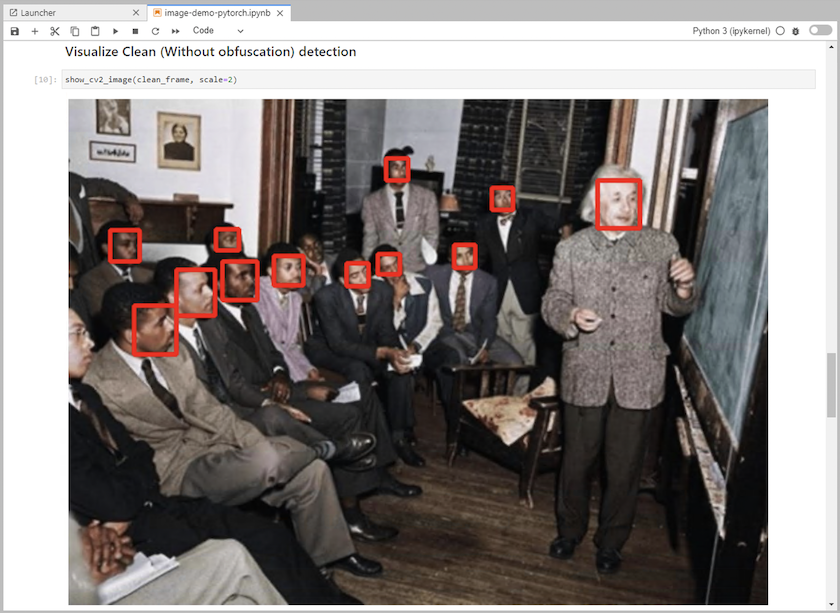
-
Aggiungi l'offuscamento Protopia al tuo codice di inferenza. Protopia collabora direttamente con i clienti per fornire documentazione specifica per i casi d'uso e non rientra nell'ambito di questo rapporto tecnico. L'esempio seguente mostra il codice di inferenza per un caso d'uso di rilevamento delle immagini con aggiunta dell'offuscamento Protopia.
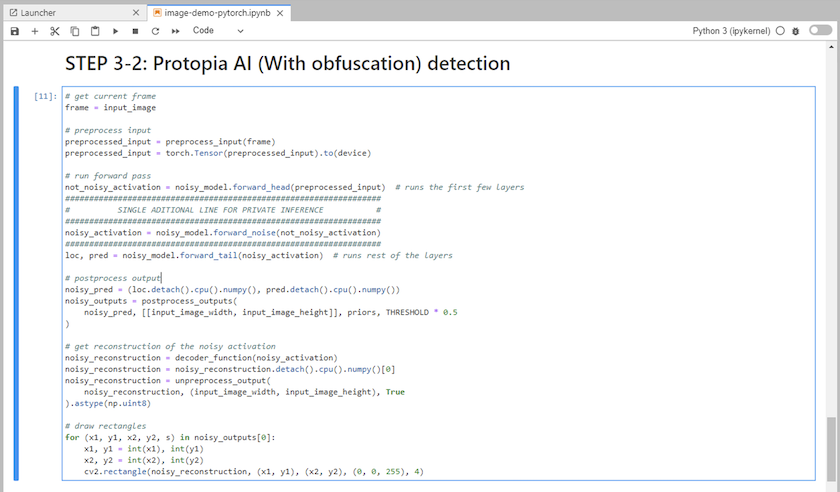
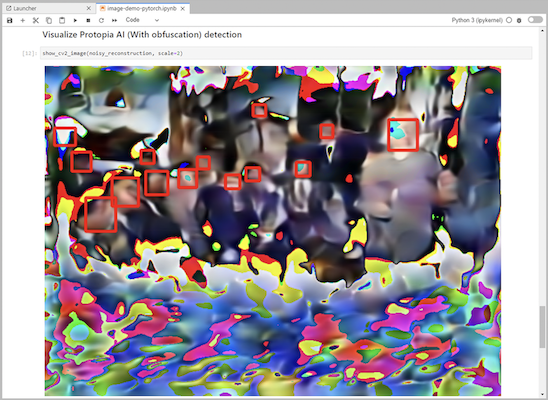
Scenario 2 – Inferenza batch su Kubernetes
-
Creare uno spazio dei nomi Kubernetes per carichi di lavoro di inferenza AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilizzare NetApp DataOps Toolkit per predisporre un volume persistente in cui archiviare i dati su cui eseguire l'inferenza.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Popolare il nuovo volume persistente con i dati su cui si eseguirà l'inferenza.
Esistono diversi metodi per caricare dati su un PVC. Se i tuoi dati sono attualmente archiviati in una piattaforma di archiviazione di oggetti compatibile con S3, come NetApp StorageGRID o Amazon S3, puoi utilizzare "Funzionalità di NetApp DataOps Toolkit S3 Data Mover" . Un altro metodo semplice è quello di creare uno spazio di lavoro JupyterLab e quindi caricare i file tramite l'interfaccia web di JupyterLab, come descritto nei passaggi da 3 a 5 nella sezione "Scenario 1 – Inferenza su richiesta in JupyterLab ."
-
Crea un processo Kubernetes per la tua attività di inferenza batch. L'esempio seguente mostra un processo di inferenza batch per un caso d'uso di rilevamento delle immagini. Questo lavoro esegue l'inferenza su ciascuna immagine in un set di immagini e scrive le metriche di accuratezza dell'inferenza su stdout.
$ vi inference-job-raw.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-raw namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-raw.yaml job.batch/netapp-inference-raw created -
Conferma che il processo di inferenza è stato completato correttamente.
$ kubectl -n inference logs netapp-inference-raw-255sp 100%|██████████| 89/89 [00:52<00:00, 1.68it/s] Reading Predictions : 100%|██████████| 10/10 [00:01<00:00, 6.23it/s] Predicting ... : 100%|██████████| 10/10 [00:16<00:00, 1.64s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.9491256561145955 FDDB-fold-2 Val AP: 0.9205024466101926 FDDB-fold-3 Val AP: 0.9253013871078468 FDDB-fold-4 Val AP: 0.9399781485863011 FDDB-fold-5 Val AP: 0.9504280149478732 FDDB-fold-6 Val AP: 0.9416473519339292 FDDB-fold-7 Val AP: 0.9241631566241117 FDDB-fold-8 Val AP: 0.9072663297546659 FDDB-fold-9 Val AP: 0.9339648715035469 FDDB-fold-10 Val AP: 0.9447707905560152 FDDB Dataset Average AP: 0.9337148153739079 ================================================= mAP: 0.9337148153739079
-
Aggiungi l'offuscamento di Protopia al tuo lavoro di inferenza. È possibile trovare istruzioni specifiche per i casi d'uso per aggiungere l'offuscamento di Protopia direttamente da Protopia, il che esula dall'ambito di questo rapporto tecnico. L'esempio seguente mostra un processo di inferenza batch per un caso d'uso di rilevamento facciale con offuscamento Protopia aggiunto utilizzando un valore ALPHA di 0,8. Questo lavoro applica l'offuscamento di Protopia prima di eseguire l'inferenza per ogni immagine in un set di immagini e quindi scrive le metriche di accuratezza dell'inferenza su stdout.
Abbiamo ripetuto questo passaggio per i valori ALPHA 0,05, 0,1, 0,2, 0,4, 0,6, 0,8, 0,9 e 0,95. Puoi vedere i risultati in"Confronto dell'accuratezza dell'inferenza."
$ vi inference-job-protopia-0.8.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-protopia-0.8 namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent env: - name: ALPHA value: "0.8" command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB", "--alpha", "$(ALPHA)", "--noisy"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-protopia-0.8.yaml job.batch/netapp-inference-protopia-0.8 created -
Conferma che il processo di inferenza è stato completato correttamente.
$ kubectl -n inference logs netapp-inference-protopia-0.8-b4dkz 100%|██████████| 89/89 [01:05<00:00, 1.37it/s] Reading Predictions : 100%|██████████| 10/10 [00:02<00:00, 3.67it/s] Predicting ... : 100%|██████████| 10/10 [00:22<00:00, 2.24s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.8953066115834589 FDDB-fold-2 Val AP: 0.8819580264029936 FDDB-fold-3 Val AP: 0.8781107458462862 FDDB-fold-4 Val AP: 0.9085731346308461 FDDB-fold-5 Val AP: 0.9166445508275378 FDDB-fold-6 Val AP: 0.9101178994188819 FDDB-fold-7 Val AP: 0.8383443678423771 FDDB-fold-8 Val AP: 0.8476311547659464 FDDB-fold-9 Val AP: 0.8739624502111121 FDDB-fold-10 Val AP: 0.8905468076424851 FDDB Dataset Average AP: 0.8841195749171925 ================================================= mAP: 0.8841195749171925
Scenario 3 – Server di inferenza NVIDIA Triton
-
Creare uno spazio dei nomi Kubernetes per carichi di lavoro di inferenza AI/ML.
$ kubectl create namespace inference namespace/inference created
-
Utilizzare NetApp DataOps Toolkit per predisporre un volume persistente da utilizzare come repository di modelli per NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=triton-model-repo --size=100Gi Creating PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'. PersistentVolumeClaim (PVC) 'triton-model-repo' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'.
-
Memorizza il tuo modello sul nuovo volume persistente in un "formato" riconosciuto dal server di inferenza NVIDIA Triton.
Esistono diversi metodi per caricare dati su un PVC. Un metodo semplice è quello di creare uno spazio di lavoro JupyterLab e quindi caricare i file tramite l'interfaccia web di JupyterLab, come descritto nei passaggi da 3 a 5 in "Scenario 1 – Inferenza su richiesta in JupyterLab . "
-
Utilizzare NetApp DataOps Toolkit per distribuire una nuova istanza di NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create triton-server --namespace=inference --server-name=netapp-inference --model-repo-pvc-name=triton-model-repo Creating Service 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Service successfully created. Creating Deployment 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Deployment 'ntap-dsutil-triton-netapp-inference' created. Waiting for Deployment 'ntap-dsutil-triton-netapp-inference' to reach Ready state. Deployment successfully created. Server successfully created. Server endpoints: http: 192.168.0.152: 31208 grpc: 192.168.0.152: 32736 metrics: 192.168.0.152: 30009/metrics
-
Utilizzare un SDK client Triton per eseguire un'attività di inferenza. Il seguente estratto di codice Python utilizza l'SDK client Python Triton per eseguire un'attività di inferenza per un caso d'uso di rilevamento dei volti. Questo esempio richiama l'API Triton e passa un'immagine per l'inferenza. Il server di inferenza Triton riceve quindi la richiesta, richiama il modello e restituisce l'output di inferenza come parte dei risultati dell'API.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass clean_activation = clean_model_head(preprocessed_input) # runs the first few layers ###################################################################################### # pass clean image to Triton Inference Server API for inferencing # ###################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_base" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(clean_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ###################################################################################### # postprocess output clean_pred = (loc_numpy, pred_numpy) clean_outputs = postprocess_outputs( clean_pred, [[input_image_width, input_image_height]], priors, THRESHOLD ) # draw rectangles clean_frame = copy.deepcopy(frame) # needs to be deep copy for (x1, y1, x2, y2, s) in clean_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(clean_frame, (x1, y1), (x2, y2), (0, 0, 255), 4) -
Aggiungi l'offuscamento Protopia al tuo codice di inferenza. È possibile trovare istruzioni specifiche per i casi d'uso per aggiungere l'offuscamento di Protopia direttamente da Protopia; tuttavia, questo processo esula dall'ambito di questo rapporto tecnico. L'esempio seguente mostra lo stesso codice Python mostrato nel passaggio 5 precedente, ma con l'aggiunta dell'offuscamento di Protopia.
Si noti che l'offuscamento Protopia viene applicato all'immagine prima che venga passata all'API Triton. In questo modo, l'immagine non offuscata non lascia mai la macchina locale. Solo l'immagine offuscata viene trasmessa attraverso la rete. Questo flusso di lavoro è applicabile ai casi d'uso in cui i dati vengono raccolti all'interno di una zona attendibile ma devono poi essere trasmessi al di fuori di tale zona attendibile per l'inferenza. Senza l'offuscamento di Protopia, non è possibile implementare questo tipo di flusso di lavoro senza che i dati sensibili escano dalla zona attendibile.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass not_noisy_activation = noisy_model_head(preprocessed_input) # runs the first few layers ################################################################## # obfuscate image locally prior to inferencing # # SINGLE ADITIONAL LINE FOR PRIVATE INFERENCE # ################################################################## noisy_activation = noisy_model_noise(not_noisy_activation) ################################################################## ########################################################################################### # pass obfuscated image to Triton Inference Server API for inferencing # ########################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_noisy" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(noisy_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ########################################################################################### # postprocess output noisy_pred = (loc_numpy, pred_numpy) noisy_outputs = postprocess_outputs( noisy_pred, [[input_image_width, input_image_height]], priors, THRESHOLD * 0.5 ) # get reconstruction of the noisy activation noisy_reconstruction = decoder_function(noisy_activation) noisy_reconstruction = noisy_reconstruction.detach().cpu().numpy()[0] noisy_reconstruction = unpreprocess_output( noisy_reconstruction, (input_image_width, input_image_height), True ).astype(np.uint8) # draw rectangles for (x1, y1, x2, y2, s) in noisy_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(noisy_reconstruction, (x1, y1), (x2, y2), (0, 0, 255), 4)