

Esempio di caso d'uso: lavoro di formazione TensorFlow
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione descrive le attività che devono essere eseguite per eseguire un processo di training TensorFlow in un ambiente NVIDIA AI Enterprise.
Prerequisiti
Prima di eseguire i passaggi descritti in questa sezione, si presume che sia già stato creato un modello di VM guest seguendo le istruzioni descritte in"Impostare" pagina.
Crea una VM guest dal modello
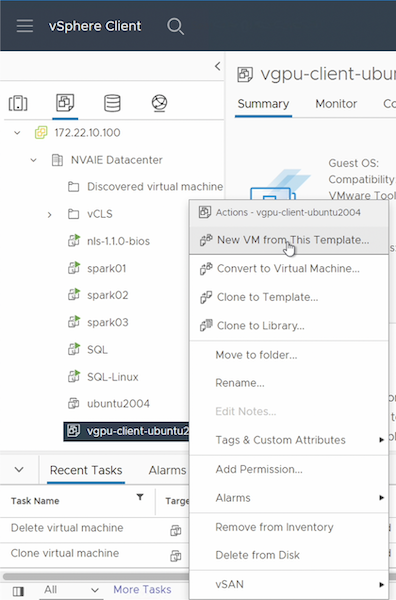
Per prima cosa, devi creare una nuova VM guest dal modello creato nella sezione precedente. Per creare una nuova VM guest dal tuo modello, accedi a VMware vSphere, fai clic con il pulsante destro del mouse sul nome del modello, scegli "Nuova VM da questo modello…" e segui la procedura guidata.
Crea e monta il volume dati
Successivamente, è necessario creare un nuovo volume di dati su cui archiviare il set di dati di addestramento. È possibile creare rapidamente un nuovo volume di dati utilizzando NetApp DataOps Toolkit. Il comando di esempio che segue mostra la creazione di un volume denominato 'imagenet' con una capacità di 2 TB.
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
Prima di poter popolare il volume dati con i dati, è necessario montarlo nella VM guest. È possibile montare rapidamente un volume di dati utilizzando NetApp DataOps Toolkit. Il comando di esempio che segue mostra il montaggio del volume creato nel passaggio precedente.
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
Popola il volume dei dati
Dopo aver eseguito il provisioning e il montaggio del nuovo volume, il set di dati di training può essere recuperato dalla posizione di origine e posizionato sul nuovo volume. In genere, ciò comporta l'estrazione dei dati da un data lake S3 o Hadoop e talvolta richiede l'aiuto di un data engineer.
Esegui il job di training di TensorFlow
Ora sei pronto per eseguire il tuo job di training TensorFlow. Per eseguire il processo di addestramento TensorFlow, eseguire le seguenti attività.
-
Estrarre l'immagine del contenitore NVIDIA NGC Enterprise TensorFlow.
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Avvia un'istanza del contenitore NVIDIA NGC Enterprise TensorFlow. Utilizzare l'opzione '-v' per allegare il volume di dati al contenitore.
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Esegui il programma di addestramento TensorFlow all'interno del contenitore. Il comando di esempio seguente mostra l'esecuzione di un programma di formazione ResNet-50 di esempio incluso nell'immagine del contenitore.
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data