

Panoramica della tecnologia
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione si concentra sulla panoramica tecnologica per OpenSource MLOps con NetApp.
Intelligenza artificiale
L'intelligenza artificiale è una disciplina informatica in cui i computer vengono addestrati a imitare le funzioni cognitive della mente umana. Gli sviluppatori di intelligenza artificiale addestrano i computer ad apprendere e a risolvere i problemi in un modo simile, o addirittura superiore, a quello degli esseri umani. L'apprendimento profondo e l'apprendimento automatico sono sottocampi dell'intelligenza artificiale. Le organizzazioni stanno adottando sempre più intelligenza artificiale, apprendimento automatico e apprendimento automatico (DL) per supportare le loro esigenze aziendali critiche. Ecco alcuni esempi:
-
Analizzare grandi quantità di dati per scoprire informazioni aziendali precedentemente sconosciute
-
Interagire direttamente con i clienti utilizzando l'elaborazione del linguaggio naturale
-
Automazione di vari processi e funzioni aziendali
I moderni carichi di lavoro di addestramento e inferenza dell'intelligenza artificiale richiedono capacità di elaborazione parallela estremamente elevate. Per questo motivo, le GPU vengono sempre più utilizzate per eseguire operazioni di intelligenza artificiale, perché le capacità di elaborazione parallela delle GPU sono di gran lunga superiori a quelle delle CPU generiche.
Contenitori
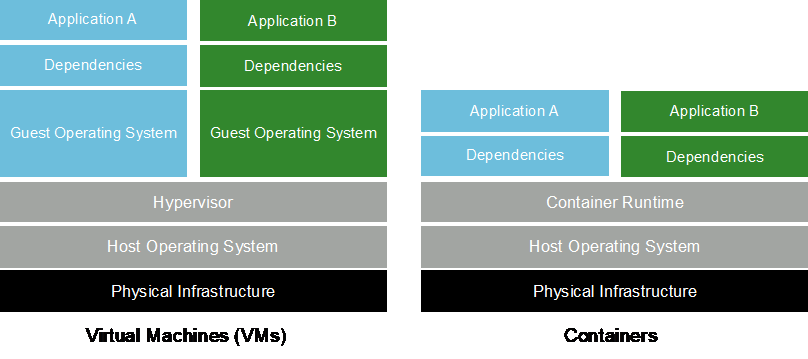
I container sono istanze isolate dello spazio utente che vengono eseguite su un kernel del sistema operativo host condiviso. L'adozione dei container è in rapida crescita. I container offrono molti degli stessi vantaggi dell'application sandboxing offerti dalle macchine virtuali (VM). Tuttavia, poiché sono stati eliminati i livelli dell'hypervisor e del sistema operativo guest su cui si basano le VM, i container sono molto più leggeri. La figura seguente illustra una visualizzazione delle macchine virtuali rispetto ai container.
I contenitori consentono inoltre di impacchettare in modo efficiente le dipendenze delle applicazioni, i tempi di esecuzione e così via, direttamente con un'applicazione. Il formato di packaging dei container più comunemente utilizzato è il container Docker. Un'applicazione che è stata containerizzata nel formato contenitore Docker può essere eseguita su qualsiasi macchina in grado di eseguire contenitori Docker. Ciò è vero anche se le dipendenze dell'applicazione non sono presenti sulla macchina, perché tutte le dipendenze sono impacchettate nel contenitore stesso. Per maggiori informazioni, visita il "Sito web Docker" .
Kubernetes
Kubernetes è una piattaforma di orchestrazione di container distribuita e open source, originariamente progettata da Google e ora gestita dalla Cloud Native Computing Foundation (CNCF). Kubernetes consente l'automazione delle funzioni di distribuzione, gestione e ridimensionamento per le applicazioni containerizzate. Negli ultimi anni, Kubernetes si è affermato come la piattaforma di orchestrazione dei container dominante. Per maggiori informazioni, visita il "Sito web di Kubernetes" .
NetApp Trident
"Trident"consente l'utilizzo e la gestione delle risorse di storage su tutte le piattaforme di storage NetApp più diffuse, nel cloud pubblico o in locale, tra cui ONTAP (AFF, FAS, Select, Cloud, Amazon FSx ONTAP), il servizio Azure NetApp Files e Google Cloud NetApp Volumes. Trident è un orchestratore di storage dinamico compatibile con Container Storage Interface (CSI) che si integra in modo nativo con Kubernetes.
Kit di strumenti NetApp DataOps
IL"Kit di strumenti NetApp DataOps" è uno strumento basato su Python che semplifica la gestione degli spazi di lavoro di sviluppo/formazione e dei server di inferenza supportati da storage NetApp ad alte prestazioni e scalabile. Le principali funzionalità includono:
-
Fornisci rapidamente nuovi spazi di lavoro ad alta capacità supportati da storage NetApp scalabile e ad alte prestazioni.
-
Clonare quasi istantaneamente spazi di lavoro ad alta capacità per consentire la sperimentazione o l'iterazione rapida.
-
Salvataggio quasi istantaneo di snapshot di spazi di lavoro ad alta capacità per backup e/o tracciabilità/baselining.
-
Esegui il provisioning, la clonazione e l'istantanea di volumi di dati ad alta capacità e ad alte prestazioni in modo quasi istantaneo.
Apache Airflow
Apache Airflow è una piattaforma open source per la gestione dei flussi di lavoro che consente la creazione, la pianificazione e il monitoraggio programmatici di flussi di lavoro aziendali complessi. Viene spesso utilizzato per automatizzare i flussi di lavoro ETL e di pipeline di dati, ma non si limita a questi tipi di flussi di lavoro. Il progetto Airflow è stato avviato da Airbnb, ma nel frattempo è diventato molto popolare nel settore e ora rientra sotto l'egida della Apache Software Foundation. Airflow è scritto in Python, i flussi di lavoro di Airflow vengono creati tramite script Python e Airflow è progettato secondo il principio della "configurazione come codice". Molti utenti aziendali di Airflow ora eseguono Airflow su Kubernetes.
Grafi aciclici diretti (DAG)
In Airflow, i flussi di lavoro sono chiamati grafi aciclici diretti (DAG). I DAG sono costituiti da attività eseguite in sequenza, in parallelo o con una combinazione delle due, a seconda della definizione del DAG. Lo scheduler Airflow esegue singole attività su una serie di worker, rispettando le dipendenze a livello di attività specificate nella definizione del DAG. I DAG vengono definiti e creati tramite script Python.
Quaderno di Jupyter
I Jupyter Notebook sono documenti simili a wiki che contengono codice live e testo descrittivo. I notebook Jupyter sono ampiamente utilizzati nella comunità AI e ML come mezzo per documentare, archiviare e condividere progetti AI e ML. Per maggiori informazioni sui Jupyter Notebooks, visita il "Sito web di Jupyter" .
Server Jupyter Notebook
Un server Jupyter Notebook è un'applicazione web open source che consente agli utenti di creare Jupyter Notebook.
JupyterHub
JupyterHub è un'applicazione multiutente che consente a un singolo utente di effettuare il provisioning e accedere al proprio server Jupyter Notebook. Per maggiori informazioni su JupyterHub, visita il "Sito web JupyterHub" .
Flusso ML
MLflow è una popolare piattaforma open source per la gestione del ciclo di vita dell'intelligenza artificiale. Le caratteristiche principali di MLflow includono il monitoraggio degli esperimenti AI/ML e un repository di modelli AI/ML. Per maggiori informazioni su MLflow, visita il "Sito web MLflow" .
Kubeflow
Kubeflow è un toolkit open source di intelligenza artificiale e apprendimento automatico per Kubernetes, originariamente sviluppato da Google. Il progetto Kubeflow rende le distribuzioni di flussi di lavoro di intelligenza artificiale e apprendimento automatico su Kubernetes semplici, portabili e scalabili. Kubeflow astrae le complessità di Kubernetes, consentendo agli scienziati dei dati di concentrarsi su ciò che conoscono meglio: la scienza dei dati. Per una visualizzazione, vedere la figura seguente. Kubeflow è una buona opzione open source per le organizzazioni che preferiscono una piattaforma MLOps all-in-one. Per maggiori informazioni, visita il "Sito web di Kubeflow" .
Pipeline Kubeflow
Le pipeline di Kubeflow sono un componente chiave di Kubeflow. Le pipeline Kubeflow sono una piattaforma e uno standard per la definizione e l'implementazione di flussi di lavoro AI e ML portatili e scalabili. Per maggiori informazioni, vedere il "documentazione ufficiale di Kubeflow" .
Notebook Kubeflow
Kubeflow semplifica il provisioning e la distribuzione dei server Jupyter Notebook su Kubernetes. Per ulteriori informazioni sui Jupyter Notebook nel contesto di Kubeflow, vedere "documentazione ufficiale di Kubeflow" .
Katib
Katib è un progetto nativo di Kubernetes per l'apprendimento automatico automatizzato (AutoML). Katib supporta la sintonizzazione degli iperparametri, l'arresto anticipato e la ricerca dell'architettura neurale (NAS). Katib è un progetto indipendente dai framework di apprendimento automatico (ML). Può ottimizzare gli iperparametri delle applicazioni scritte in qualsiasi linguaggio scelto dall'utente e supporta in modo nativo molti framework ML, come TensorFlow, MXNet, PyTorch, XGBoost e altri. Katib supporta molti algoritmi AutoML diversi, come l'ottimizzazione bayesiana, gli stimatori dell'albero di Parzen, la ricerca casuale, la strategia di evoluzione dell'adattamento della matrice di covarianza, l'iperbanda, la ricerca efficiente dell'architettura neurale, la ricerca dell'architettura differenziabile e molti altri. Per ulteriori informazioni sui Jupyter Notebook nel contesto di Kubeflow, vedere "documentazione ufficiale di Kubeflow" .
NetApp ONTAP
ONTAP 9, l'ultima generazione di software di gestione dello storage di NetApp, consente alle aziende di modernizzare l'infrastruttura e passare a un data center pronto per il cloud. Sfruttando le funzionalità di gestione dei dati leader del settore, ONTAP consente la gestione e la protezione dei dati con un unico set di strumenti, indipendentemente da dove risiedano. È inoltre possibile spostare liberamente i dati ovunque siano necessari: edge, core o cloud. ONTAP 9 include numerose funzionalità che semplificano la gestione dei dati, accelerano e proteggono i dati critici e abilitano le funzionalità infrastrutturali di nuova generazione nelle architetture cloud ibride.
Semplificare la gestione dei dati
La gestione dei dati è fondamentale per le operazioni IT aziendali e per gli scienziati dei dati, in modo che vengano utilizzate risorse appropriate per le applicazioni di intelligenza artificiale e per la formazione di set di dati di intelligenza artificiale/apprendimento automatico. Le seguenti informazioni aggiuntive sulle tecnologie NetApp esulano dall'ambito di questa convalida, ma potrebbero essere rilevanti a seconda della distribuzione.
Il software di gestione dati ONTAP include le seguenti funzionalità per semplificare e snellire le operazioni e ridurre i costi operativi totali:
-
Compattazione dei dati in linea e deduplicazione estesa. La compattazione dei dati riduce lo spazio sprecato all'interno dei blocchi di archiviazione, mentre la deduplicazione aumenta significativamente la capacità effettiva. Ciò vale sia per i dati archiviati localmente sia per i dati archiviati a livelli nel cloud.
-
Qualità del servizio minima, massima e adattiva (AQoS). I controlli granulari della qualità del servizio (QoS) aiutano a mantenere i livelli di prestazioni per le applicazioni critiche in ambienti altamente condivisi.
-
NetApp FabricPool. Fornisce la suddivisione automatica dei dati inattivi in opzioni di archiviazione cloud pubbliche e private, tra cui Amazon Web Services (AWS), Azure e la soluzione di archiviazione NetApp StorageGRID . Per ulteriori informazioni su FabricPool, vedere "TR-4598: Buone pratiche FabricPool" .
Accelerare e proteggere i dati
ONTAP garantisce livelli superiori di prestazioni e protezione dei dati ed estende queste capacità nei seguenti modi:
-
Prestazioni e latenza più bassa. ONTAP offre la massima capacità di trasmissione possibile con la minima latenza possibile.
-
Protezione dei dati. ONTAP offre funzionalità integrate di protezione dei dati con gestione comune su tutte le piattaforme.
-
Crittografia del volume NetApp (NVE). ONTAP offre la crittografia nativa a livello di volume con supporto sia per la gestione delle chiavi integrate che per quella esterna.
-
Multitenancy e autenticazione multifattore. ONTAP consente la condivisione delle risorse infrastrutturali con i massimi livelli di sicurezza.
Infrastruttura a prova di futuro
ONTAP aiuta a soddisfare le esigenze aziendali più esigenti e in continua evoluzione grazie alle seguenti funzionalità:
-
Scalabilità fluida e operazioni senza interruzioni. ONTAP supporta l'aggiunta non distruttiva di capacità ai controller esistenti e ai cluster scalabili. I clienti possono passare alle tecnologie più recenti senza costose migrazioni di dati o interruzioni.
-
Connessione cloud. ONTAP è il software di gestione dello storage più connesso al cloud, con opzioni per lo storage definito dal software e istanze cloud native in tutti i cloud pubblici.
-
Integrazione con applicazioni emergenti. ONTAP offre servizi dati di livello aziendale per piattaforme e applicazioni di nuova generazione, come veicoli autonomi, città intelligenti e Industria 4.0, utilizzando la stessa infrastruttura che supporta le app aziendali esistenti.
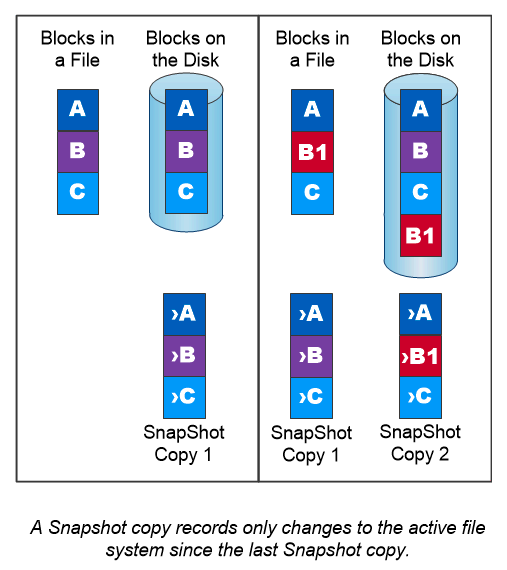
Copie snapshot NetApp
Una copia Snapshot NetApp è un'immagine di un volume, di sola lettura e in un determinato momento. L'immagine consuma uno spazio di archiviazione minimo e comporta un sovraccarico di prestazioni trascurabile, poiché registra solo le modifiche apportate ai file creati dopo l'ultima copia Snapshot, come illustrato nella figura seguente.
Le copie snapshot devono la loro efficienza alla tecnologia di virtualizzazione dello storage ONTAP di base, Write Anywhere File Layout (WAFL). Come un database, WAFL utilizza i metadati per puntare ai blocchi di dati effettivi sul disco. Tuttavia, a differenza di un database, WAFL non sovrascrive i blocchi esistenti. Scrive i dati aggiornati in un nuovo blocco e modifica i metadati. Le copie Snapshot sono così efficienti perché ONTAP fa riferimento ai metadati quando crea una copia Snapshot, anziché copiare blocchi di dati. In questo modo si elimina il tempo di ricerca impiegato da altri sistemi per individuare i blocchi da copiare, nonché il costo della copia stessa.
È possibile utilizzare una copia Snapshot per recuperare singoli file o LUN oppure per ripristinare l'intero contenuto di un volume. ONTAP confronta le informazioni del puntatore nella copia Snapshot con i dati sul disco per ricostruire l'oggetto mancante o danneggiato, senza tempi di inattività o costi significativi in termini di prestazioni.
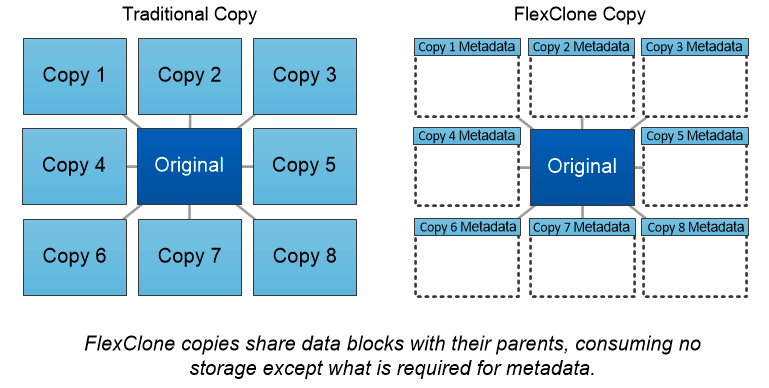
Tecnologia NetApp FlexClone
La tecnologia NetApp FlexClone fa riferimento ai metadati Snapshot per creare copie scrivibili e puntuali di un volume. Le copie condividono blocchi di dati con i loro genitori, senza consumare spazio di archiviazione, se non quello necessario per i metadati, finché le modifiche non vengono scritte sulla copia, come illustrato nella figura seguente. Mentre le copie tradizionali possono richiedere minuti o addirittura ore per essere create, il software FlexClone consente di copiare anche i set di dati più grandi in modo quasi istantaneo. Ciò lo rende ideale per le situazioni in cui sono necessarie più copie di set di dati identici (ad esempio, un'area di lavoro di sviluppo) o copie temporanee di un set di dati (per testare un'applicazione rispetto a un set di dati di produzione).
Tecnologia di replicazione dei dati NetApp SnapMirror
Il software NetApp SnapMirror è una soluzione di replica unificata conveniente e facile da usare nell'intero data fabric. Replica i dati ad alta velocità su LAN o WAN. Offre un'elevata disponibilità dei dati e una rapida replicazione dei dati per applicazioni di tutti i tipi, comprese le applicazioni aziendali critiche in ambienti sia virtuali che tradizionali. Quando si replicano i dati su uno o più sistemi di storage NetApp e si aggiornano continuamente i dati secondari, i dati vengono mantenuti aggiornati e sono disponibili ogni volta che ne hai bisogno. Non sono richiesti server di replicazione esterni. Per un esempio di architettura che sfrutta la tecnologia SnapMirror , vedere la figura seguente.
Il software SnapMirror sfrutta l'efficienza di archiviazione NetApp ONTAP inviando sulla rete solo i blocchi modificati. Il software SnapMirror utilizza anche la compressione di rete integrata per accelerare i trasferimenti di dati e ridurre l'utilizzo della larghezza di banda di rete fino al 70%. Grazie alla tecnologia SnapMirror , è possibile sfruttare un flusso di dati di replica sottile per creare un singolo repository che gestisce sia il mirror attivo sia le copie point-in-time precedenti, riducendo il traffico di rete fino al 50%.
Copia e sincronizzazione NetApp BlueXP
"BlueXP Copia e Sincronizza"è un servizio NetApp per la sincronizzazione rapida e sicura dei dati. Che tu debba trasferire file tra condivisioni file NFS o SMB locali, NetApp StorageGRID, NetApp ONTAP S3, Google Cloud NetApp Volumes, Azure NetApp Files, AWS S3, AWS EFS, Azure Blob, Google Cloud Storage o IBM Cloud Object Storage, BlueXP Copy and Sync sposta i file dove ti servono in modo rapido e sicuro.
Una volta trasferiti, i dati saranno completamente disponibili per l'uso sia sulla sorgente che sulla destinazione. BlueXP Copy and Sync può sincronizzare i dati su richiesta quando viene attivato un aggiornamento oppure sincronizzare i dati in modo continuo in base a una pianificazione predefinita. In ogni caso, BlueXP Copy and Sync sposta solo i delta, riducendo al minimo il tempo e il denaro spesi per la replicazione dei dati.
BlueXP Copy and Sync è uno strumento software as a service (SaaS) estremamente semplice da configurare e utilizzare. I trasferimenti di dati attivati da BlueXP Copy and Sync vengono eseguiti da broker di dati. I broker di dati BlueXP Copy and Sync possono essere distribuiti su AWS, Azure, Google Cloud Platform o in locale.
NetApp XCP
"NetApp XCP"è un software basato su client per migrazioni di dati da NetApp a NetApp e da NetApp a NetApp e per analisi del file system. XCP è progettato per scalare e raggiungere le massime prestazioni utilizzando tutte le risorse di sistema disponibili per gestire set di dati di grandi volumi e migrazioni ad alte prestazioni. XCP ti aiuta ad ottenere una visibilità completa del file system con la possibilità di generare report.
Volumi NetApp ONTAP FlexGroup
Un set di dati di addestramento può essere una raccolta di potenzialmente miliardi di file. I file possono contenere testo, audio, video e altre forme di dati non strutturati che devono essere archiviati ed elaborati per poter essere letti in parallelo. Il sistema di archiviazione deve memorizzare un gran numero di file di piccole dimensioni e deve leggere tali file in parallelo per l'I/O sequenziale e casuale.
Un volume FlexGroup è un singolo spazio dei nomi che comprende più volumi membri costituenti, come mostrato nella figura seguente. Dal punto di vista di un amministratore di storage, un volume FlexGroup viene gestito e si comporta come un FlexVol volume NetApp FlexVol. I file in un volume FlexGroup vengono assegnati ai singoli volumi membri e non vengono distribuiti tra volumi o nodi. Abilitano le seguenti funzionalità:
-
I volumi FlexGroup forniscono diversi petabyte di capacità e una latenza bassa e prevedibile per carichi di lavoro con metadati elevati.
-
Supportano fino a 400 miliardi di file nello stesso namespace.
-
Supportano operazioni parallelizzate nei carichi di lavoro NAS su CPU, nodi, aggregati e volumi FlexVol costituenti.
