

Flusso di lavoro di ripristino di emergenza
 Suggerisci modifiche
Suggerisci modifiche
Le aziende hanno adottato il cloud pubblico come risorsa e destinazione valida per il disaster recovery. SnapCenter rende questo processo il più fluido possibile. Questo flusso di lavoro di disaster recovery è molto simile al flusso di lavoro di clonazione, ma il ripristino del database viene eseguito tramite l'ultimo registro disponibile che è stato replicato sul cloud per recuperare tutte le transazioni aziendali possibili. Tuttavia, per il disaster recovery sono previsti ulteriori passaggi di pre-configurazione e post-configurazione.
Clona un database di produzione Oracle locale sul cloud per il DR
-
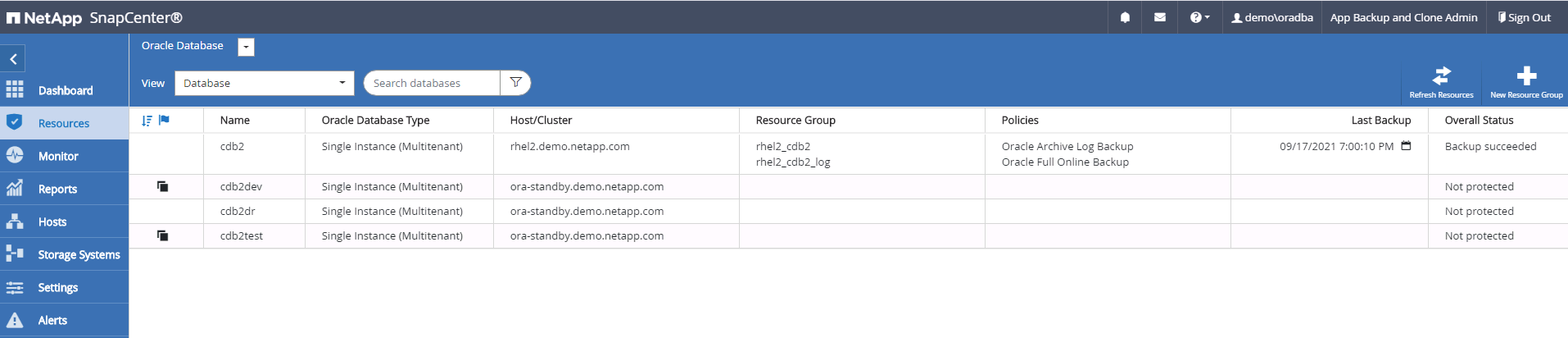
Per verificare che il ripristino del clone venga eseguito tramite l'ultimo registro disponibile, abbiamo creato una piccola tabella di prova e inserito una riga. I dati di prova verrebbero recuperati dopo un ripristino completo dell'ultimo registro disponibile.
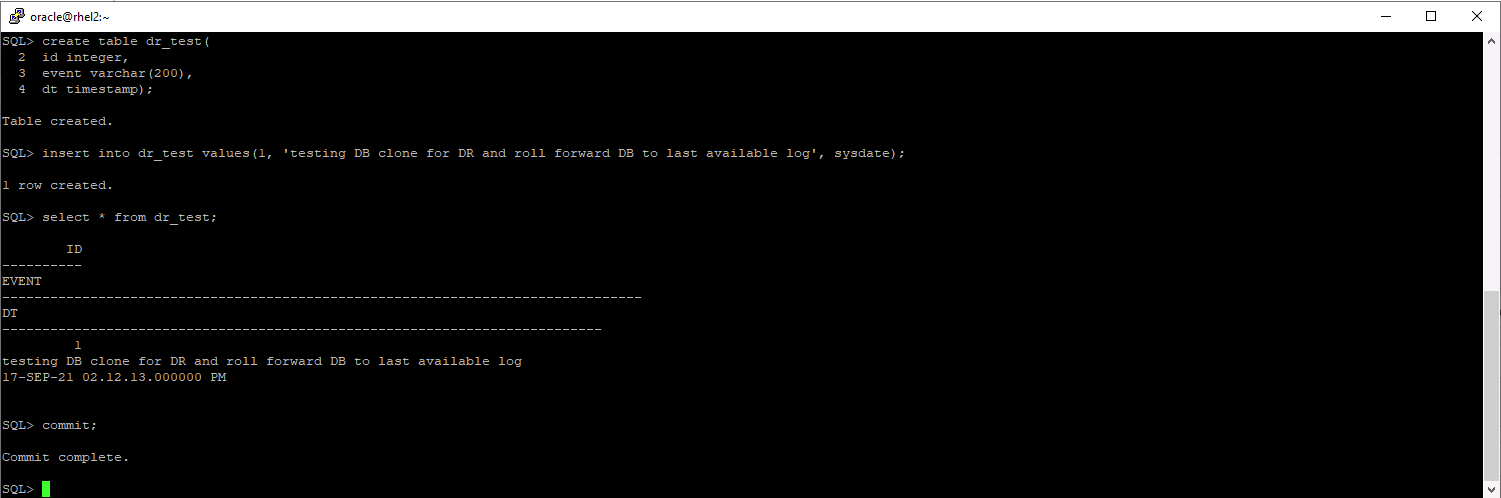
-
Accedi a SnapCenter come ID utente di gestione del database per Oracle. Passare alla scheda Risorse, che mostra i database Oracle protetti da SnapCenter.
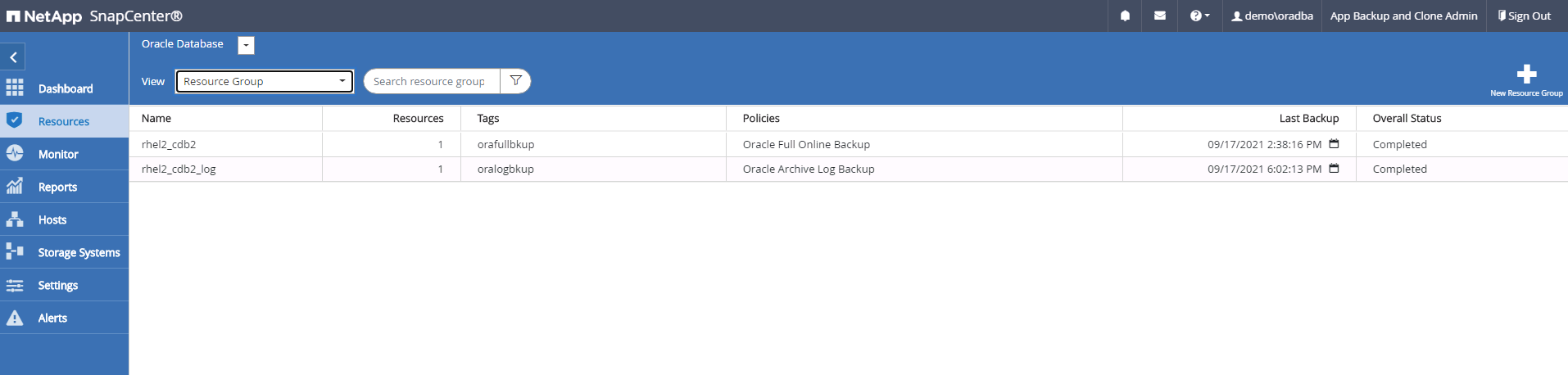
-
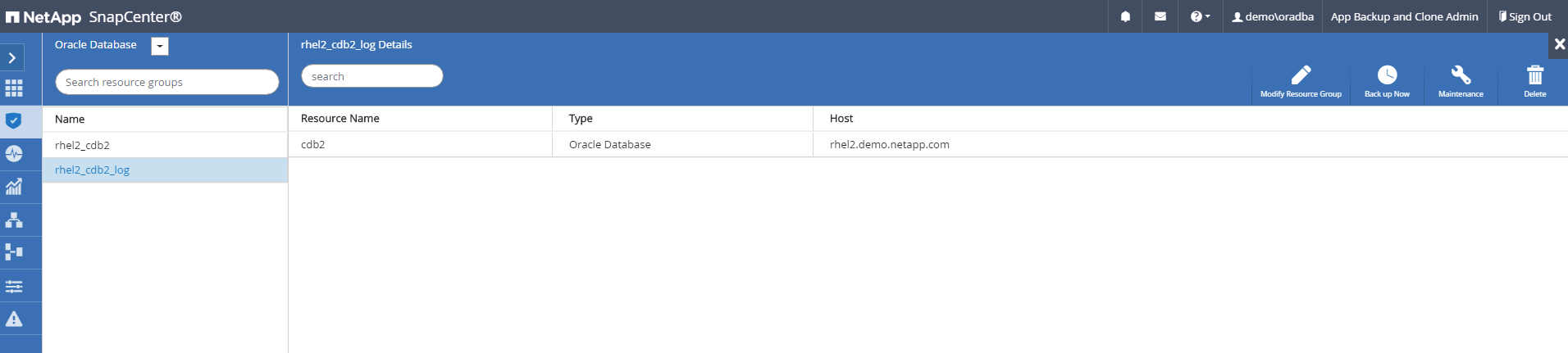
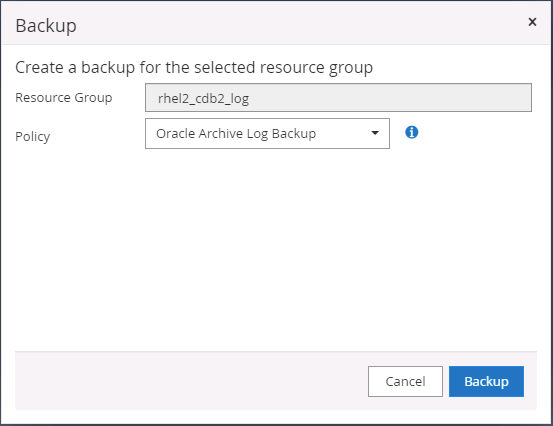
Selezionare il gruppo di risorse del registro Oracle e fare clic su Esegui backup ora per eseguire manualmente un backup del registro Oracle per scaricare l'ultima transazione nella destinazione nel cloud. In uno scenario DR reale, l'ultima transazione recuperabile dipende dalla frequenza di replicazione del volume del registro del database sul cloud, che a sua volta dipende dalla politica RTO o RPO dell'azienda.

SnapMirror asincrono perde i dati che non sono arrivati alla destinazione cloud nell'intervallo di backup del registro del database in uno scenario di ripristino di emergenza. Per ridurre al minimo la perdita di dati, è possibile pianificare backup del registro più frequenti. Tuttavia, esiste un limite alla frequenza di backup del registro tecnicamente realizzabile. -
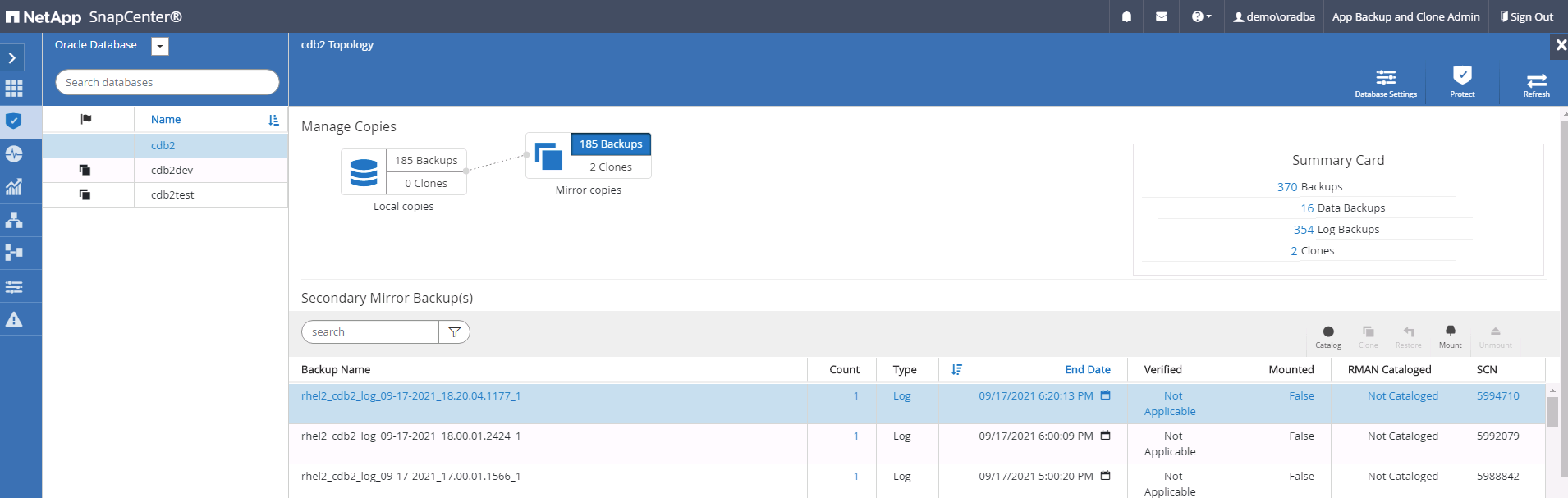
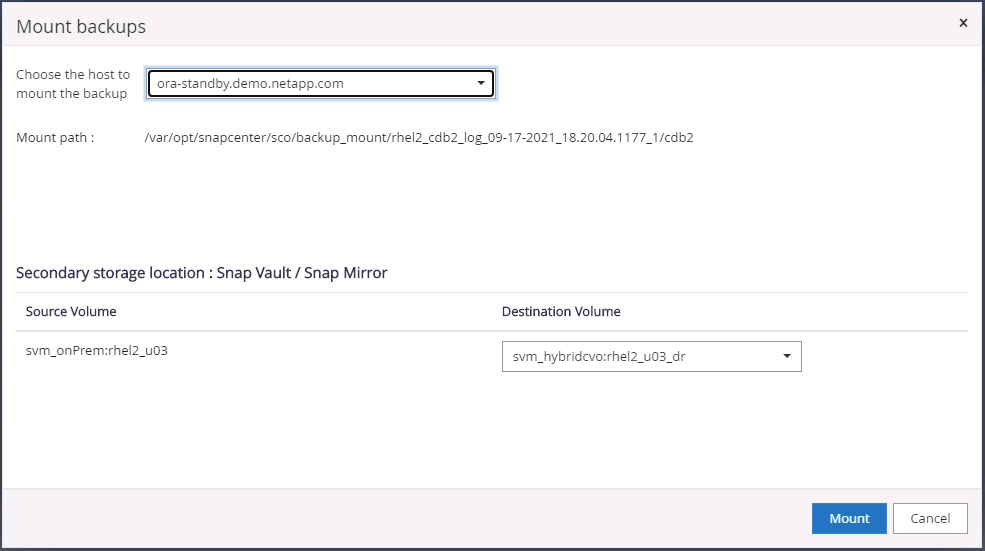
Selezionare l'ultimo backup del log sul/sui backup mirror secondario/i e montare il backup del log.
-
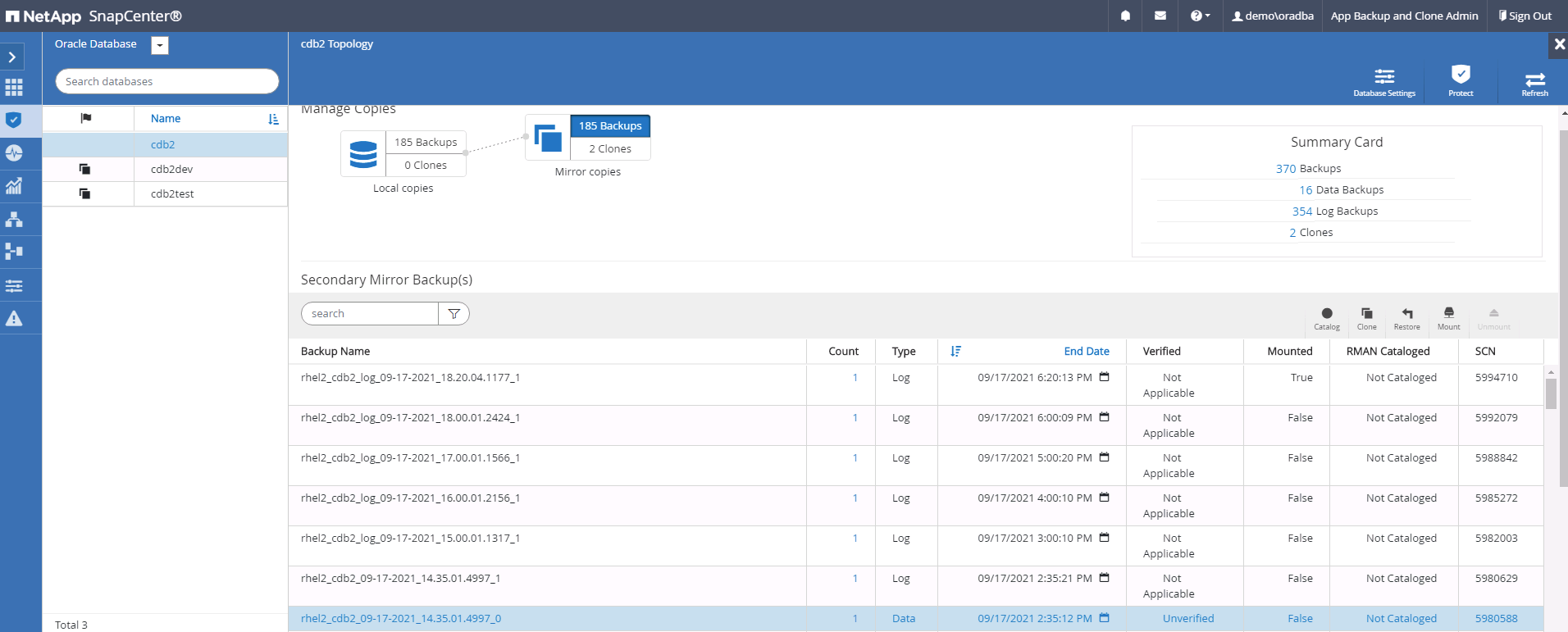
Selezionare l'ultimo backup completo del database e fare clic su Clona per avviare il flusso di lavoro di clonazione.
-
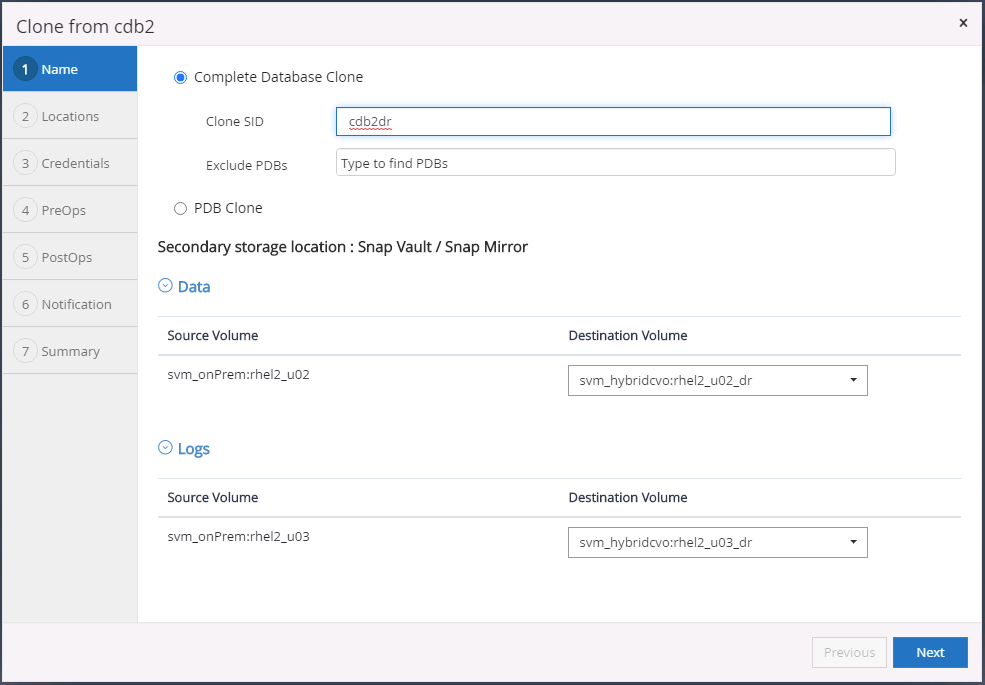
Selezionare un ID DB clone univoco sull'host.
-
Fornire un volume di registro e montarlo sul server DR di destinazione per l'area di ripristino flash Oracle e i registri online.
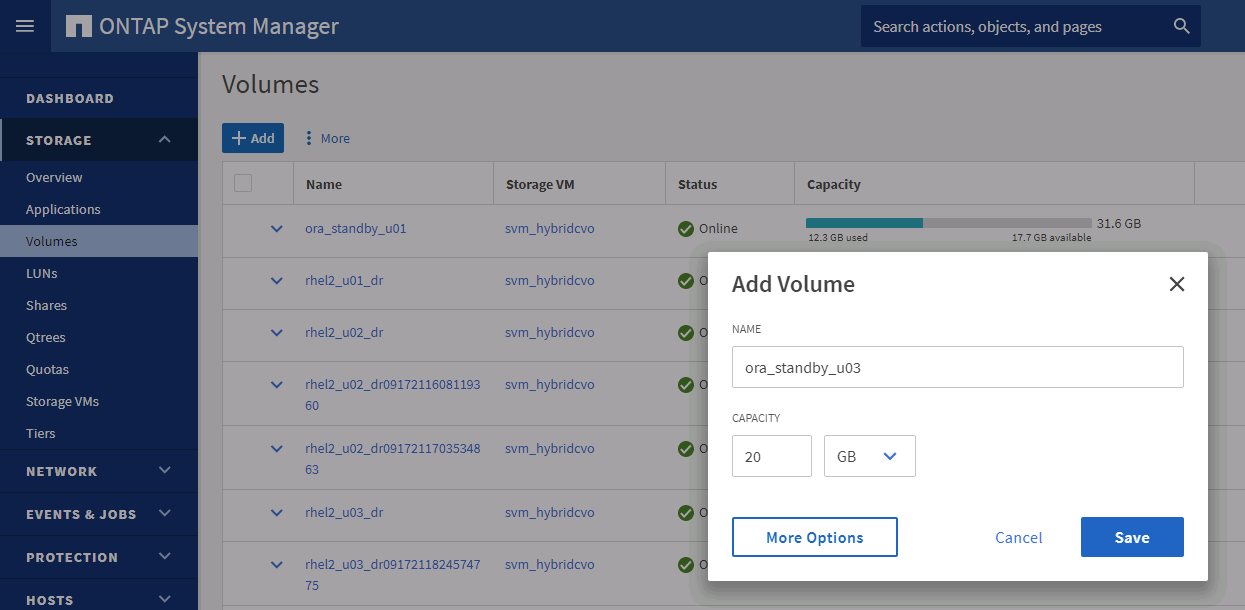
La procedura di clonazione di Oracle non crea un volume di registro, che deve essere predisposto sul server DR prima della clonazione. -
Selezionare l'host clone di destinazione e la posizione in cui posizionare i file di dati, i file di controllo e i redo log.
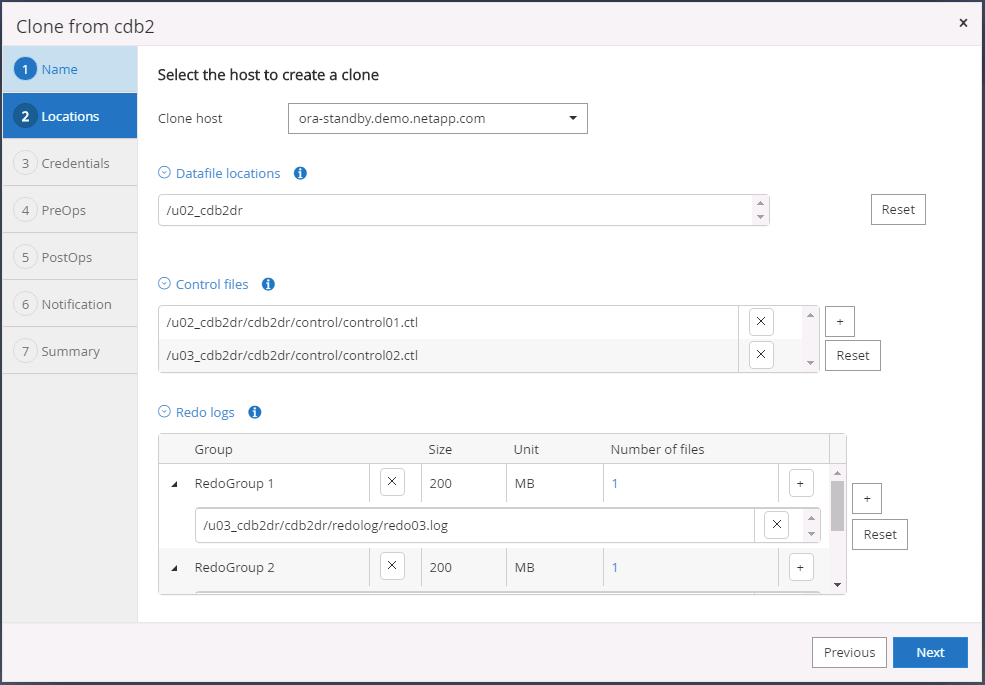
-
Selezionare le credenziali per il clone. Compilare i dettagli della configurazione Oracle home sul server di destinazione.
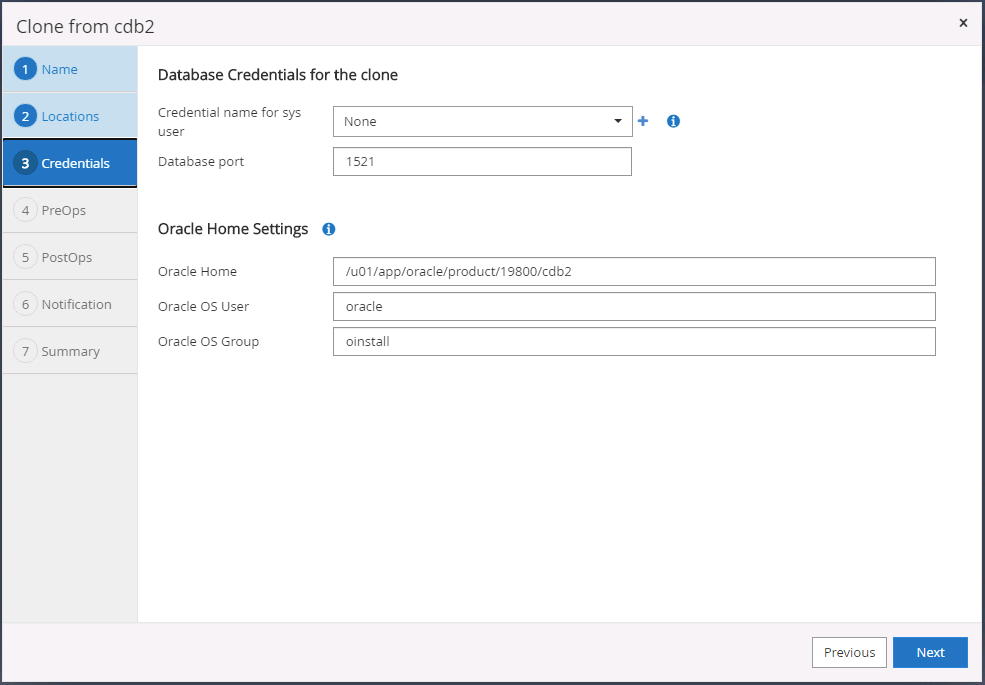
-
Specificare gli script da eseguire prima della clonazione. Se necessario, è possibile modificare i parametri del database.
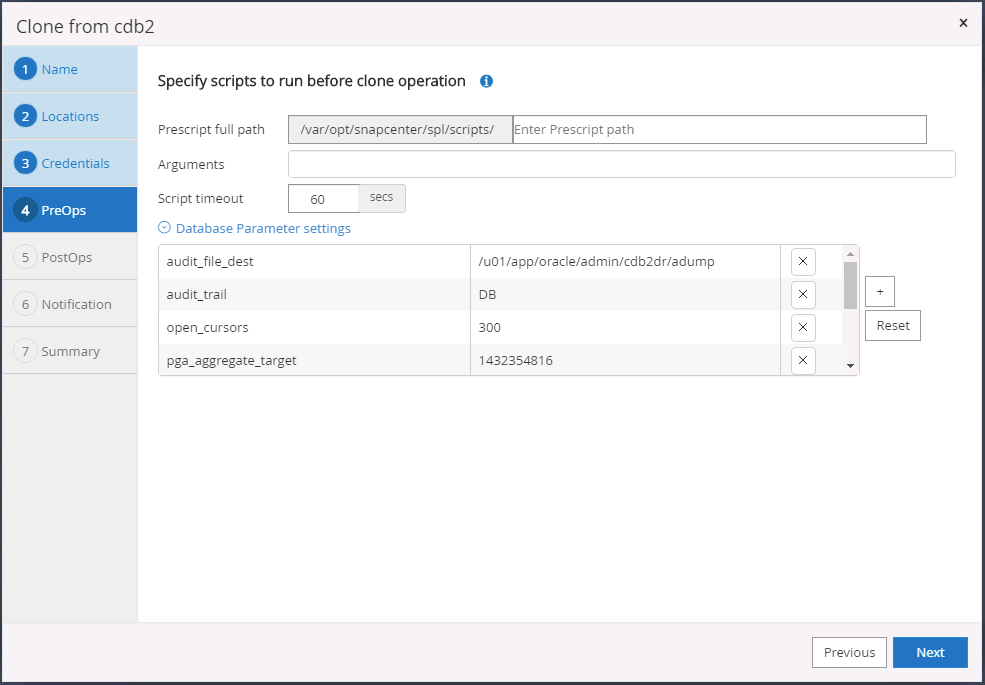
-
Selezionare Fino all'annullamento come opzione di ripristino in modo che il ripristino venga eseguito attraverso tutti i registri di archivio disponibili per recuperare l'ultima transazione replicata nella posizione cloud secondaria.
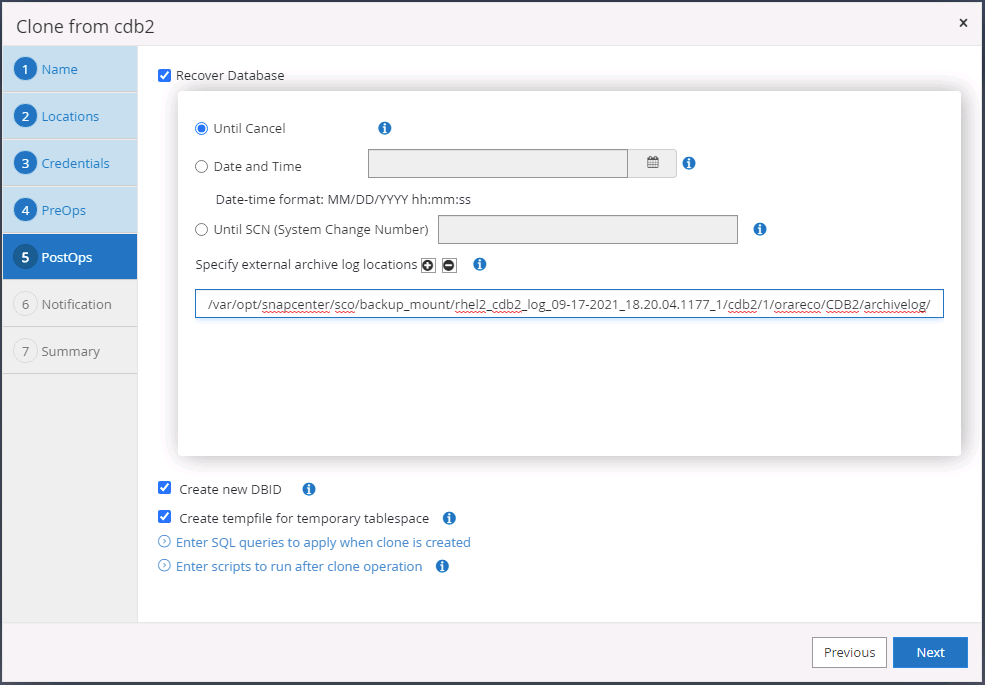
-
Se necessario, configurare il server SMTP per la notifica via e-mail.
-
Riepilogo del clone DR.
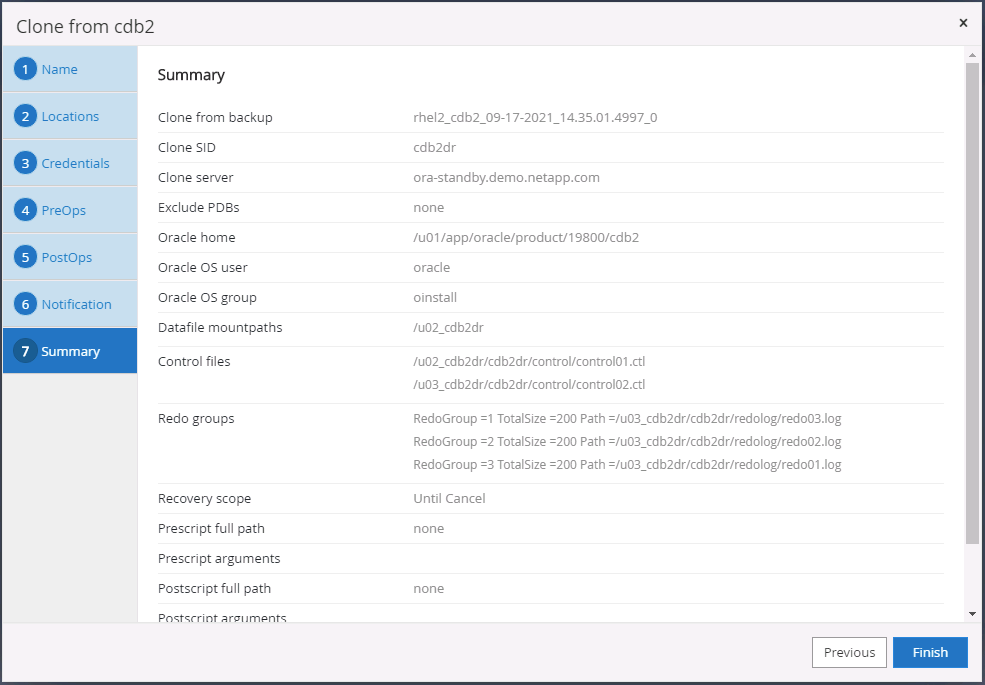
-
I DB clonati vengono registrati con SnapCenter subito dopo il completamento della clonazione e sono quindi disponibili per la protezione tramite backup.
Convalida e configurazione del clone post-DR per Oracle
-
Convalida l'ultima transazione di prova che è stata svuotata, replicata e ripristinata nella posizione DR nel cloud.
-
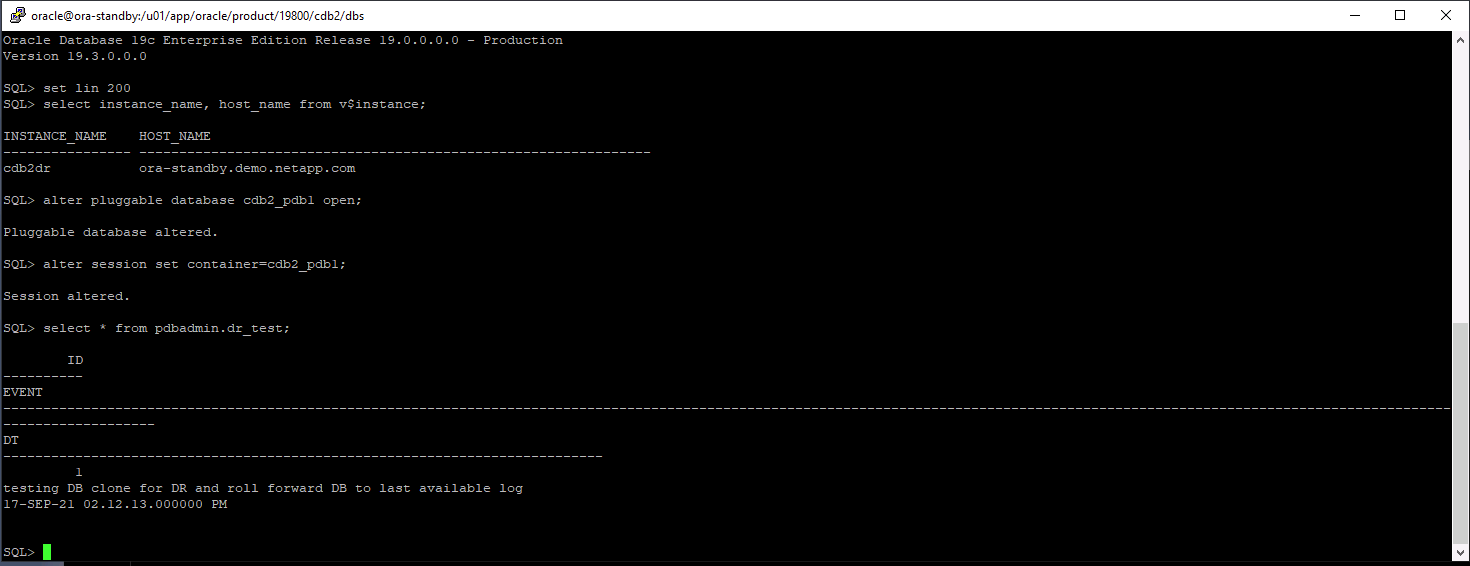
Configurare l'area di ripristino flash.
-
Configurare l'ascoltatore Oracle per l'accesso utente.
-
Dividere il volume clonato dal volume sorgente replicato.
-
Replica inversa dal cloud all'ambiente locale e ricostruzione del server di database locale non funzionante.
|
|
La suddivisione dei cloni può comportare un utilizzo temporaneo dello spazio di archiviazione molto più elevato rispetto al normale funzionamento. Tuttavia, dopo aver ricostruito il server DB locale, è possibile liberare spazio extra. |
Clona un database di produzione SQL locale sul cloud per il ripristino di emergenza
-
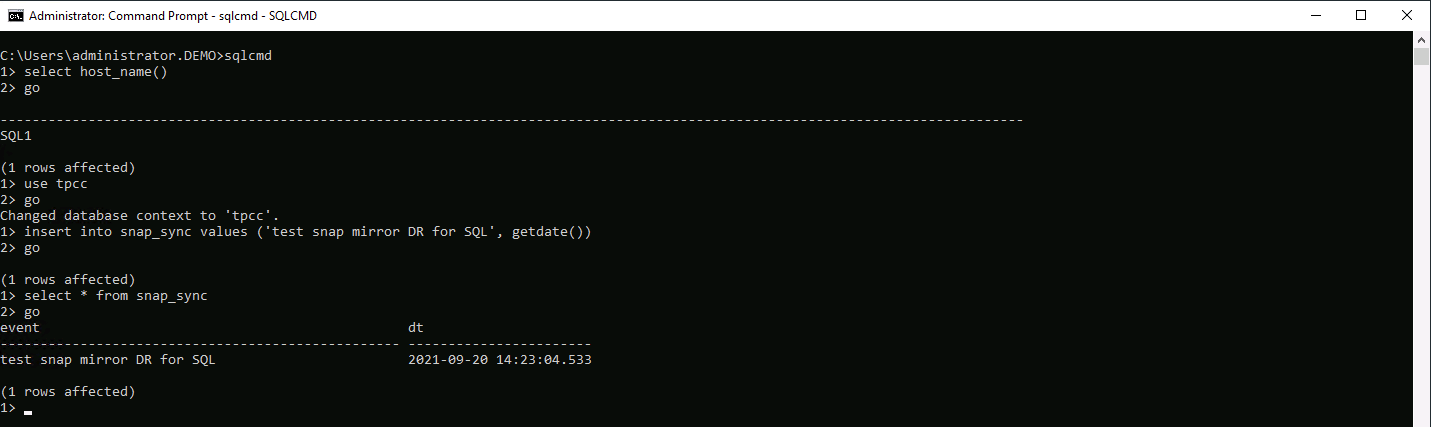
Allo stesso modo, per convalidare che il ripristino del clone SQL fosse stato eseguito tramite l'ultimo log disponibile, abbiamo creato una piccola tabella di prova e inserito una riga. I dati di prova verrebbero recuperati dopo un ripristino completo dell'ultimo registro disponibile.
-
Accedi a SnapCenter con un ID utente di gestione del database per SQL Server. Passare alla scheda Risorse, che mostra il gruppo di risorse di protezione di SQL Server.

-
Eseguire manualmente un backup del registro per eliminare l'ultima transazione da replicare nell'archivio secondario nel cloud pubblico.
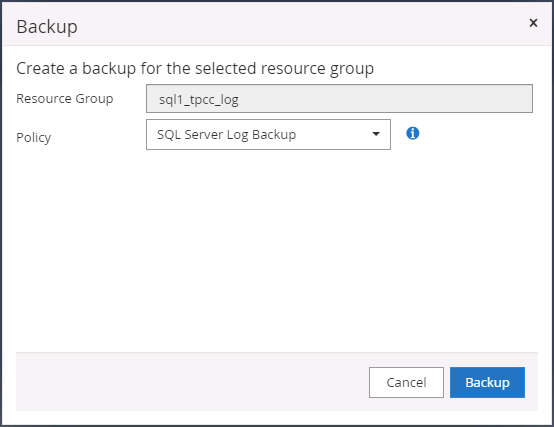
-
Selezionare l'ultimo backup completo di SQL Server per il clone.
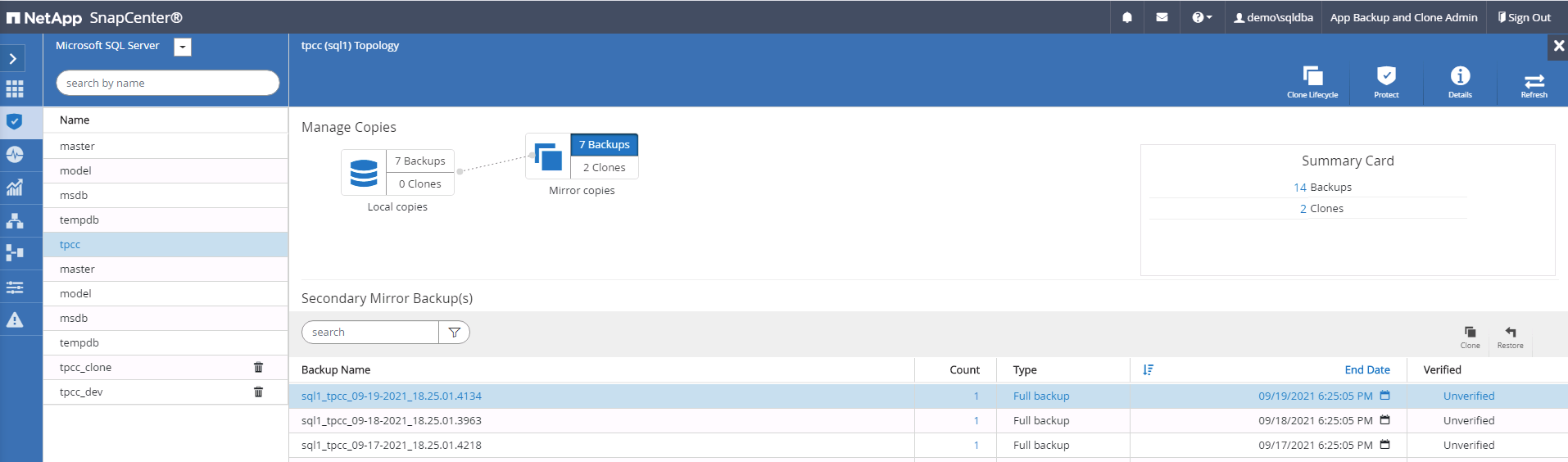
-
Imposta le impostazioni di clonazione, come il server di clonazione, l'istanza di clonazione, il nome di clonazione e l'opzione di montaggio. La posizione di archiviazione secondaria in cui viene eseguita la clonazione viene popolata automaticamente.
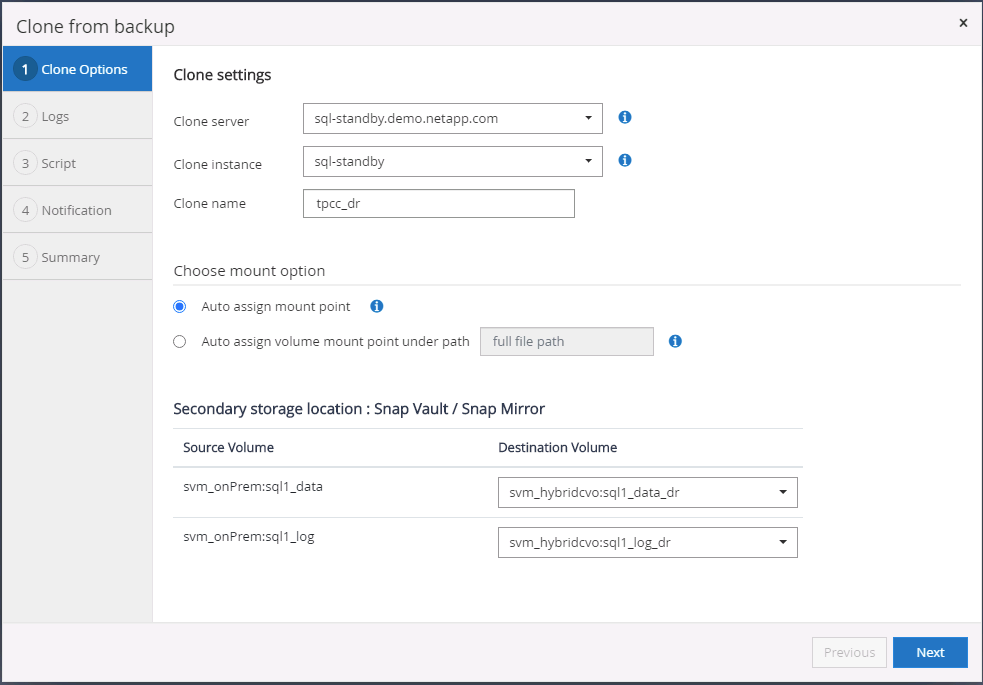
-
Seleziona tutti i backup del registro da applicare.
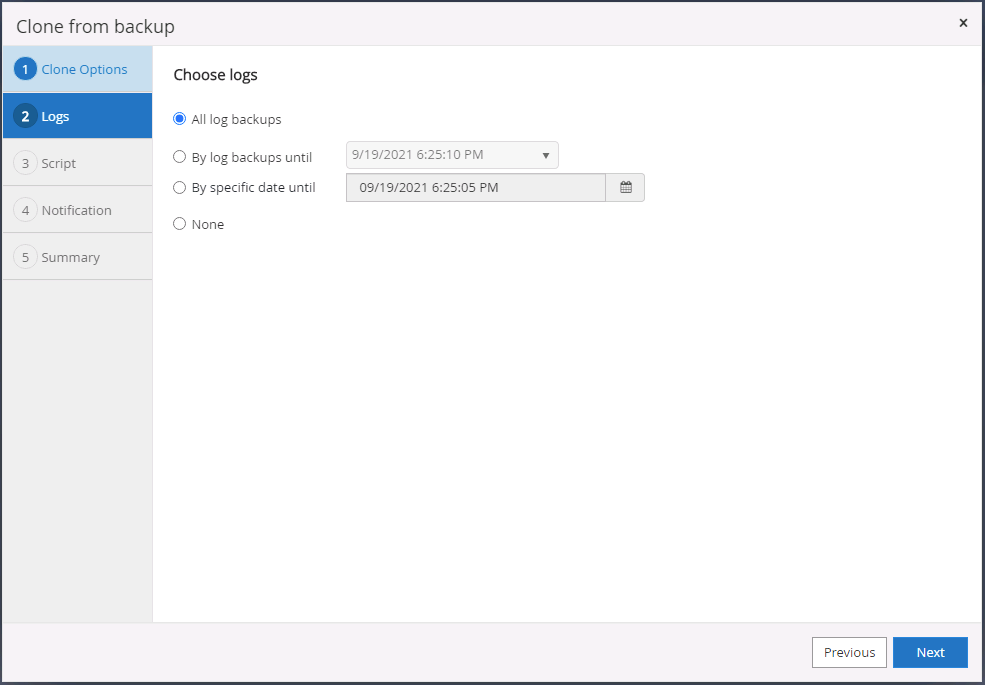
-
Specificare eventuali script facoltativi da eseguire prima o dopo la clonazione.
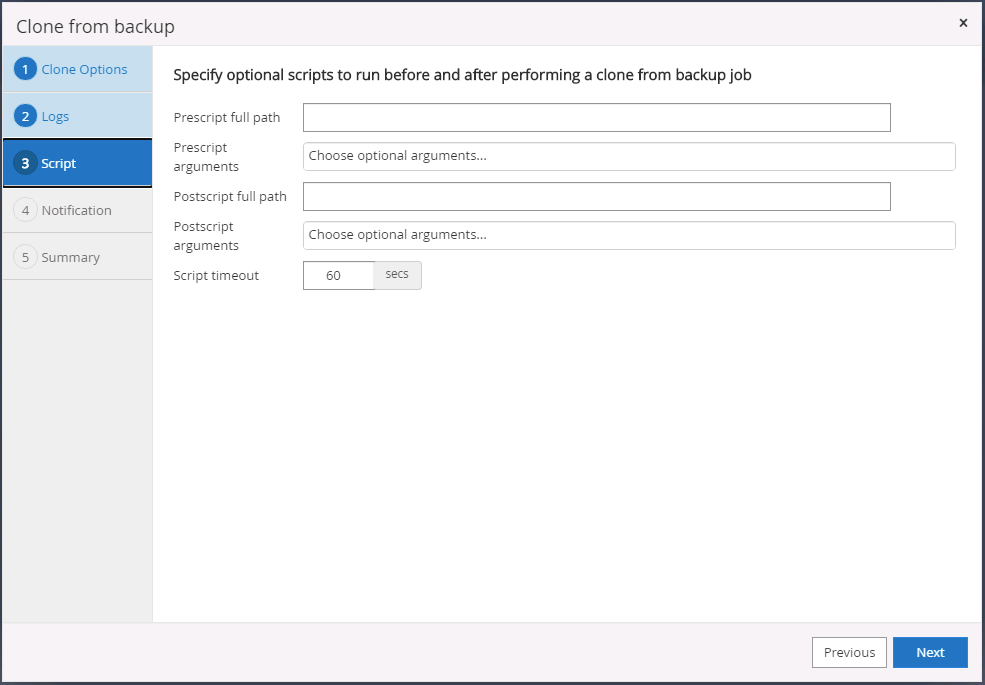
-
Specificare un server SMTP se si desidera la notifica via e-mail.
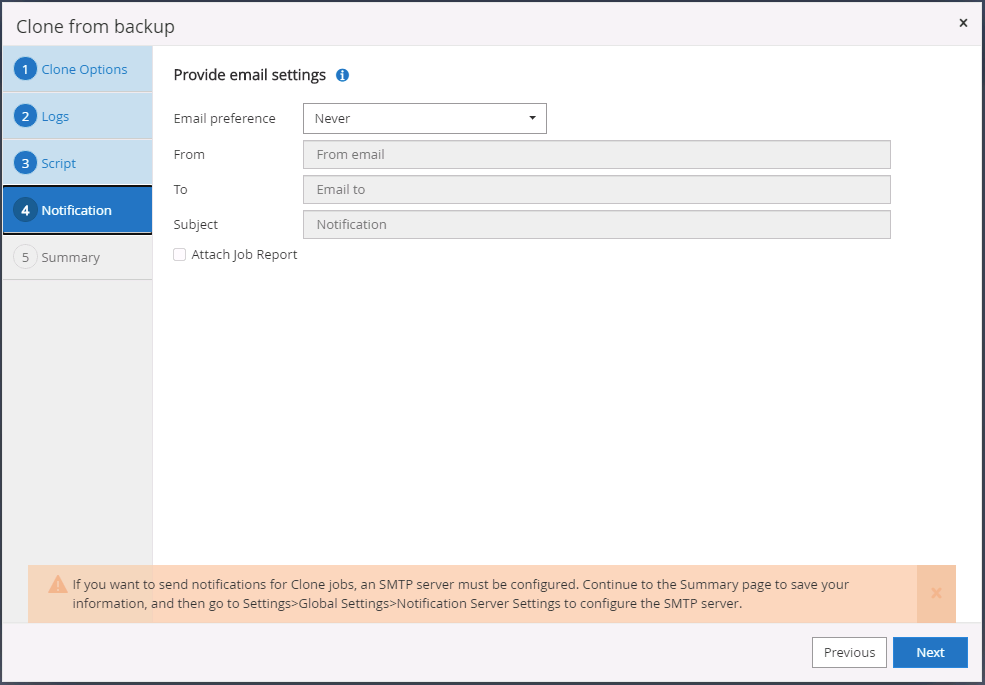
-
Riepilogo del clone DR. I database clonati vengono immediatamente registrati con SnapCenter e disponibili per la protezione tramite backup.
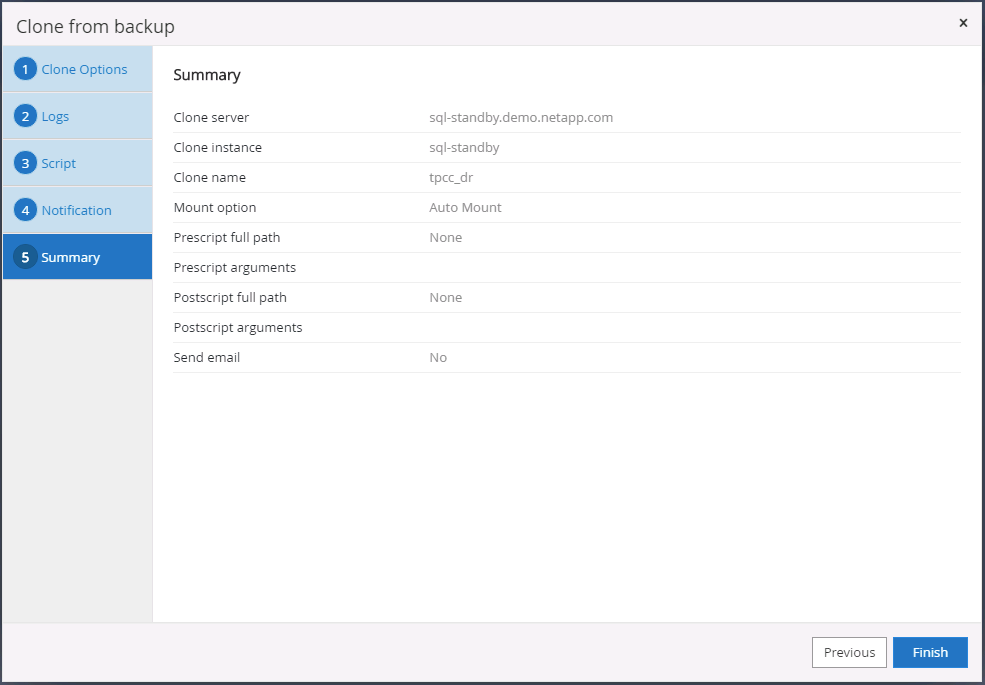
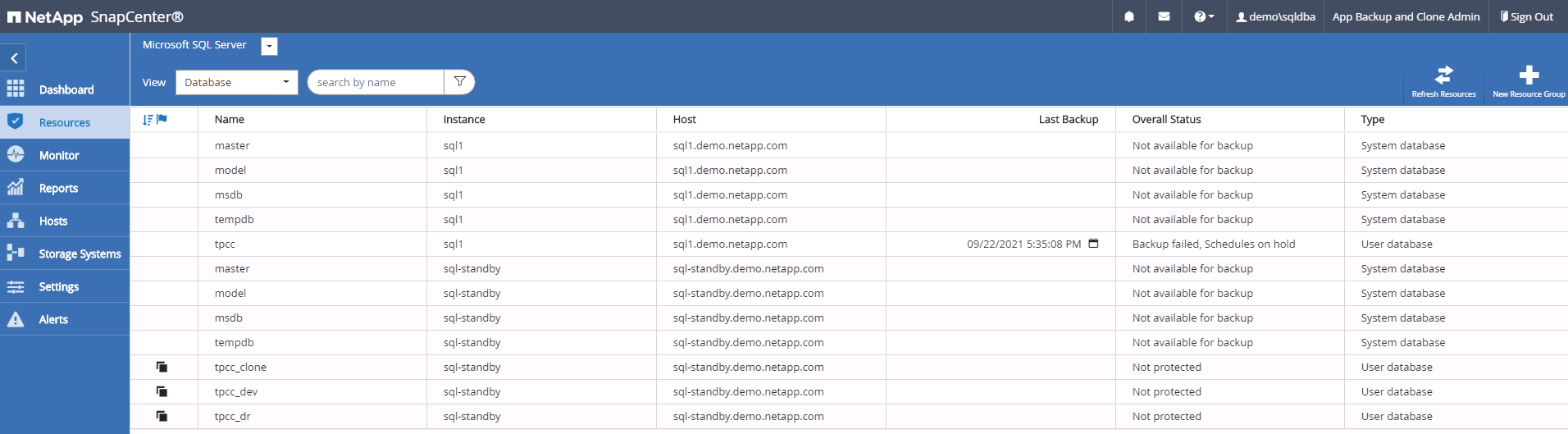
Convalida e configurazione del clone post-DR per SQL
-
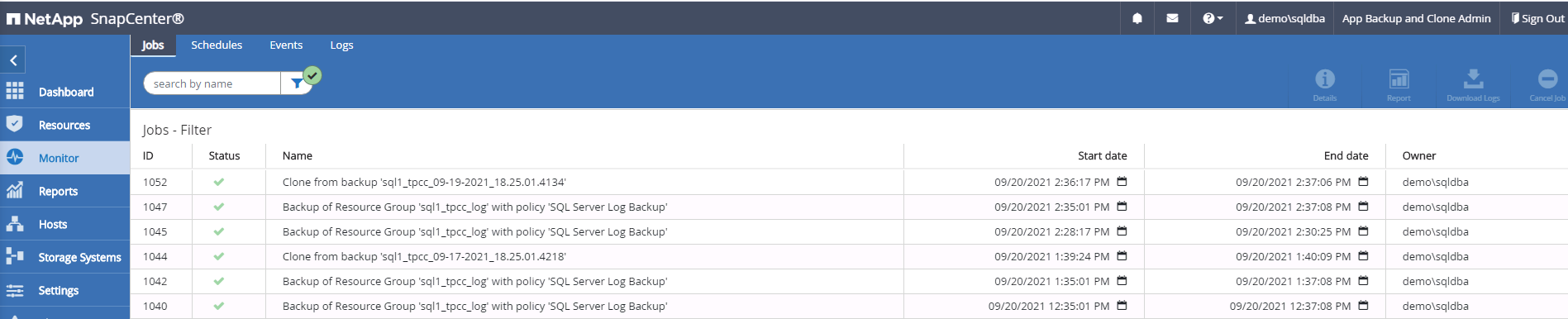
Monitorare lo stato del processo di clonazione.
-
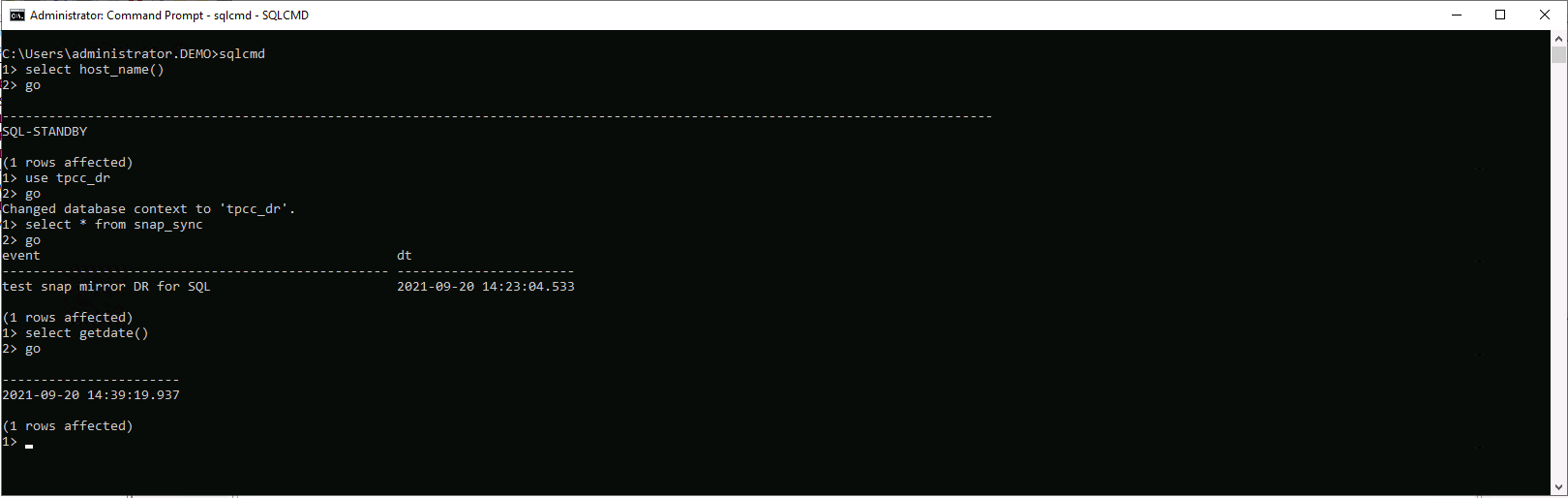
Convalidare che l'ultima transazione sia stata replicata e recuperata con tutti i cloni dei file di registro e il recupero.
-
Configurare una nuova directory di log di SnapCenter sul server DR per il backup del log di SQL Server.
-
Dividere il volume clonato dal volume sorgente replicato.
-
Replica inversa dal cloud all'ambiente locale e ricostruzione del server di database locale non funzionante.
Dove rivolgersi per chiedere aiuto?
Se hai bisogno di aiuto con questa soluzione e casi d'uso, unisciti a"Canale Slack di supporto della community NetApp Solution Automation" e cerca il canale solution-automation per pubblicare le tue domande o richieste.