Procedure di distribuzione Oracle passo dopo passo su AWS EC2 e FSx
 Suggerisci modifiche
Suggerisci modifiche
In questa sezione vengono descritte le procedure di distribuzione del database personalizzato Oracle RDS con storage FSx.
Distribuisci un'istanza EC2 Linux per Oracle tramite la console EC2
Se sei un nuovo utente di AWS, devi prima configurare un ambiente AWS. La scheda della documentazione nella landing page del sito Web AWS fornisce link alle istruzioni EC2 su come distribuire un'istanza EC2 Linux che può essere utilizzata per ospitare il database Oracle tramite la console AWS EC2. La sezione seguente è un riepilogo di questi passaggi. Per maggiori dettagli, consultare la documentazione specifica di AWS EC2.
Configurazione dell'ambiente AWS EC2
È necessario creare un account AWS per fornire le risorse necessarie per eseguire l'ambiente Oracle sul servizio EC2 e FSx. La seguente documentazione AWS fornisce i dettagli necessari:
Argomenti chiave:
-
Registrati ad AWS.
-
Crea una coppia di chiavi.
-
Crea un gruppo di sicurezza.
Abilitazione di più zone di disponibilità negli attributi dell'account AWS
Per una configurazione Oracle ad alta disponibilità, come illustrato nel diagramma dell'architettura, è necessario abilitare almeno quattro zone di disponibilità in una regione. Le zone di disponibilità multipla possono anche essere situate in regioni diverse per soddisfare le distanze richieste per il ripristino in caso di disastro.
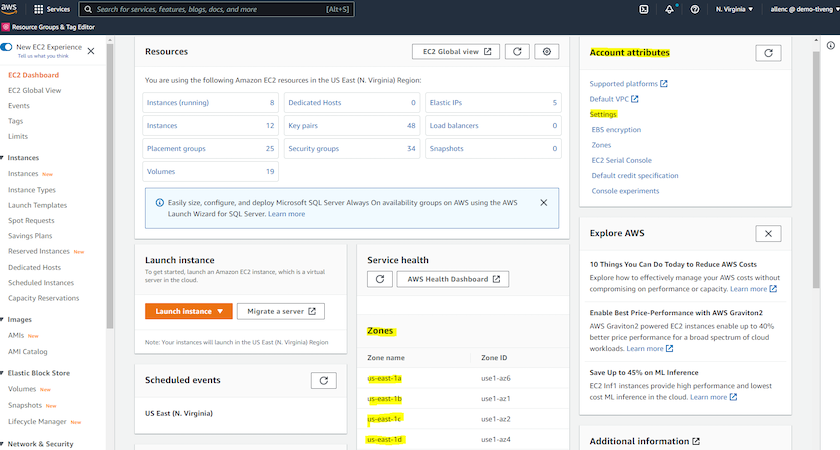
Creazione e connessione a un'istanza EC2 per l'hosting del database Oracle
Guarda il tutorial"Inizia con le istanze Amazon EC2 Linux" per procedure di distribuzione dettagliate e best practice.
Argomenti chiave:
-
Panoramica.
-
Prerequisiti.
-
Passaggio 1: avviare un'istanza.
-
Passaggio 2: connettiti alla tua istanza.
-
Passaggio 3: pulisci l'istanza.
Gli screenshot seguenti mostrano la distribuzione di un'istanza Linux di tipo m5 con la console EC2 per l'esecuzione di Oracle.
-
Dalla dashboard EC2, fare clic sul pulsante giallo Avvia istanza per avviare il flusso di lavoro di distribuzione dell'istanza EC2.
-
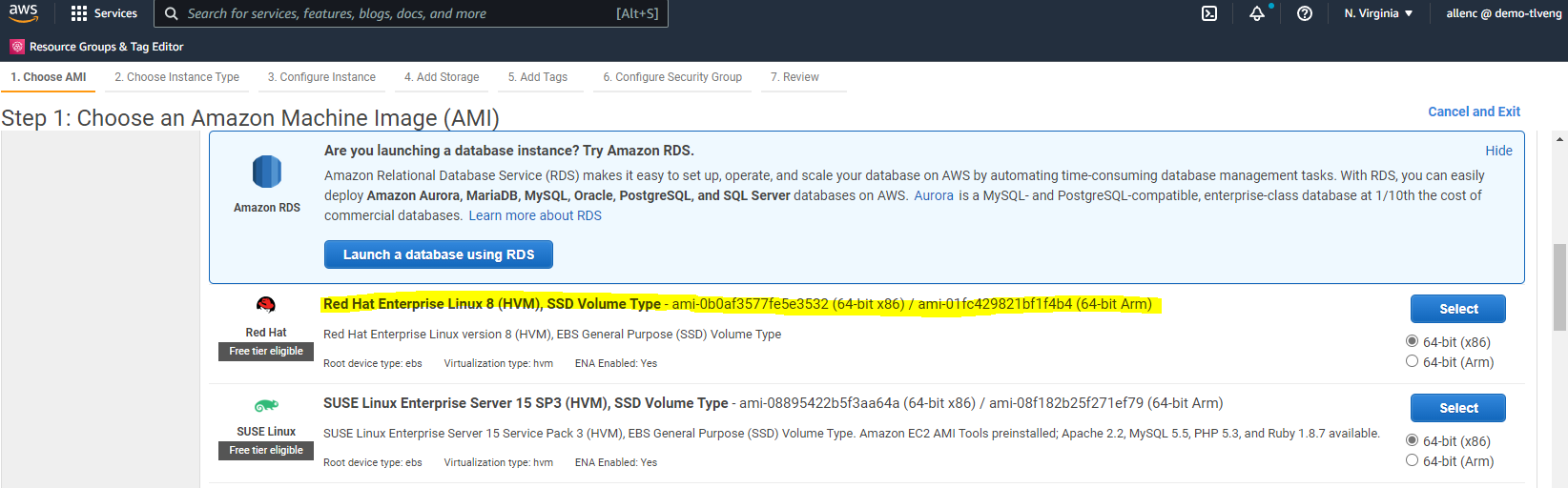
Nel passaggio 1, selezionare "Red Hat Enterprise Linux 8 (HVM), tipo di volume SSD - ami-0b0af3577fe5e3532 (64-bit x86) / ami-01fc429821bf1f4b4 (64-bit Arm)."
-
Nel passaggio 2, seleziona un tipo di istanza m5 con la CPU e l'allocazione di memoria appropriate in base al carico di lavoro del database Oracle. Fare clic su "Avanti: Configura dettagli istanza".
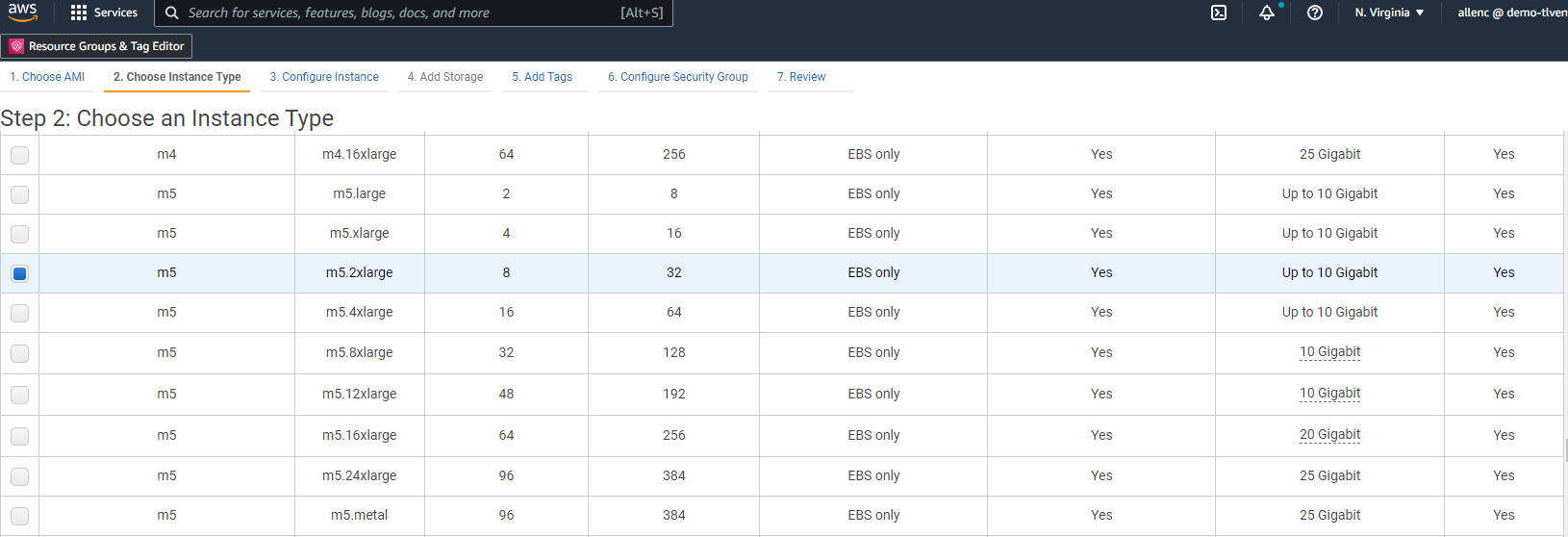
-
Nel passaggio 3, seleziona la VPC e la subnet in cui posizionare l'istanza e abilita l'assegnazione dell'IP pubblico. Fare clic su "Avanti: Aggiungi spazio di archiviazione".
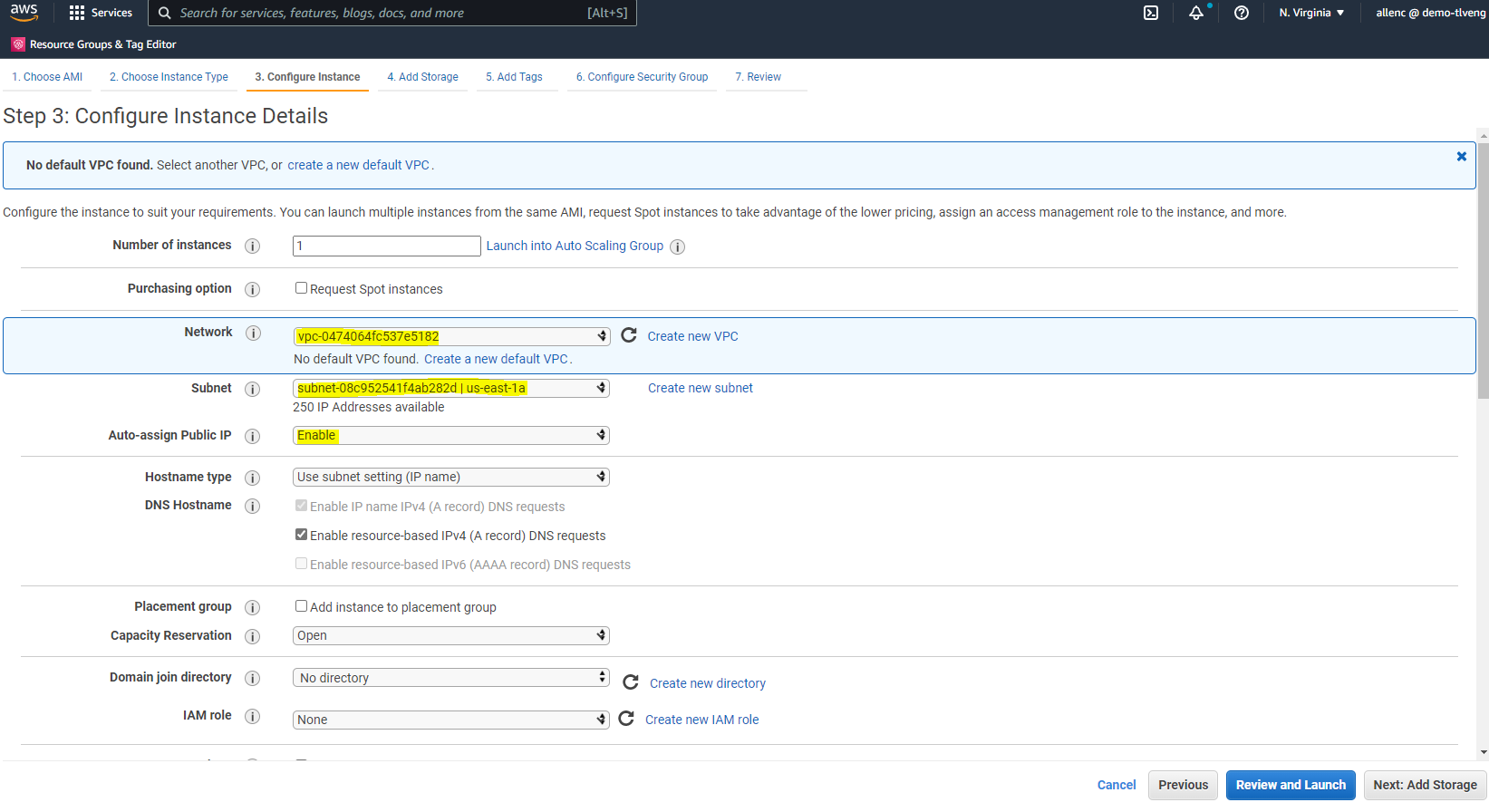
-
Nel passaggio 4, allocare spazio sufficiente per il disco radice. Potrebbe essere necessario spazio per aggiungere uno scambio. Per impostazione predefinita, l'istanza EC2 non assegna spazio di swap, il che non è ottimale per l'esecuzione di Oracle.
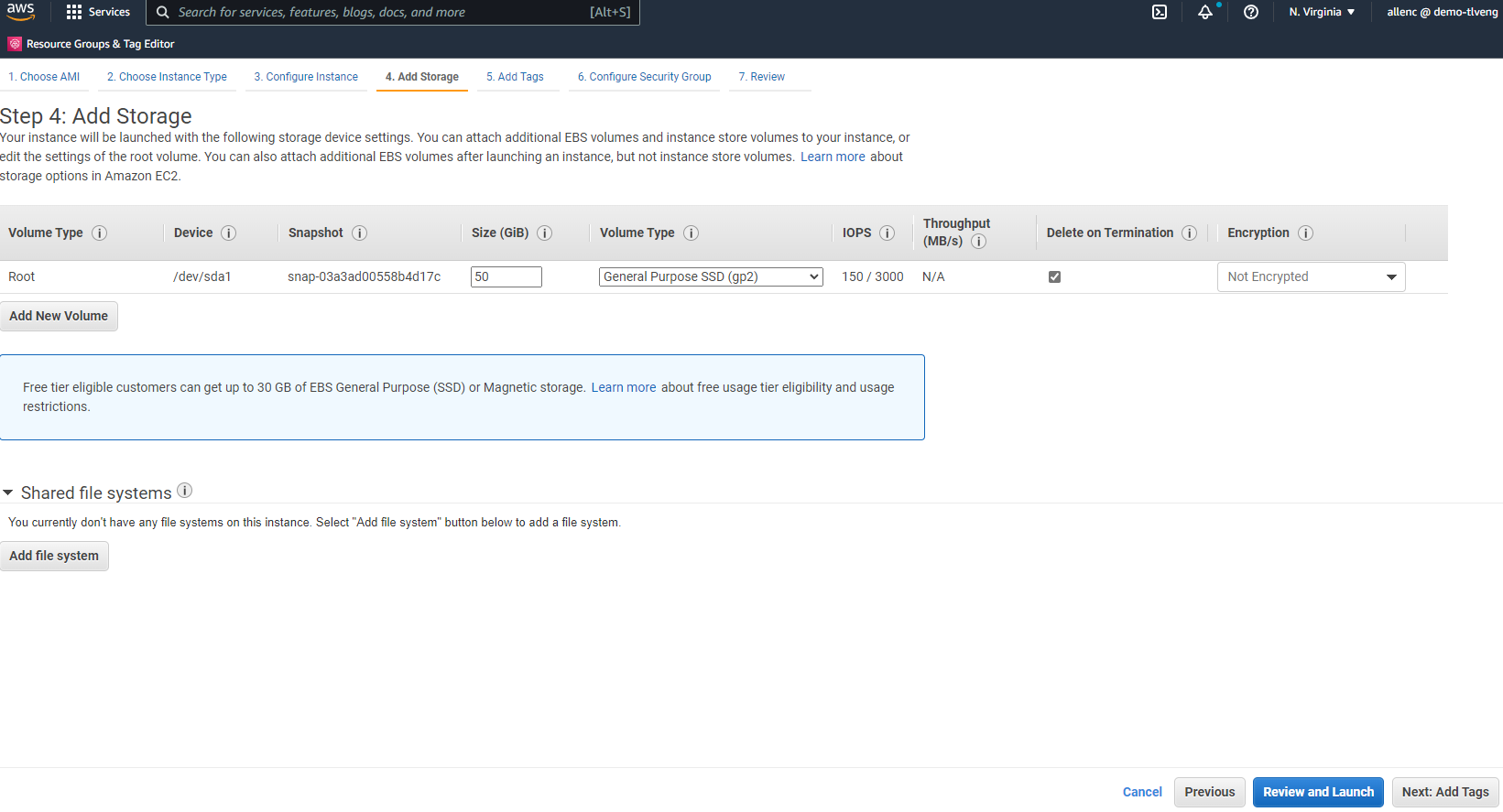
-
Nel passaggio 5, se necessario, aggiungere un tag per l'identificazione dell'istanza.
-
Nel passaggio 6, seleziona un gruppo di sicurezza esistente o creane uno nuovo con i criteri in entrata e in uscita desiderati per l'istanza.
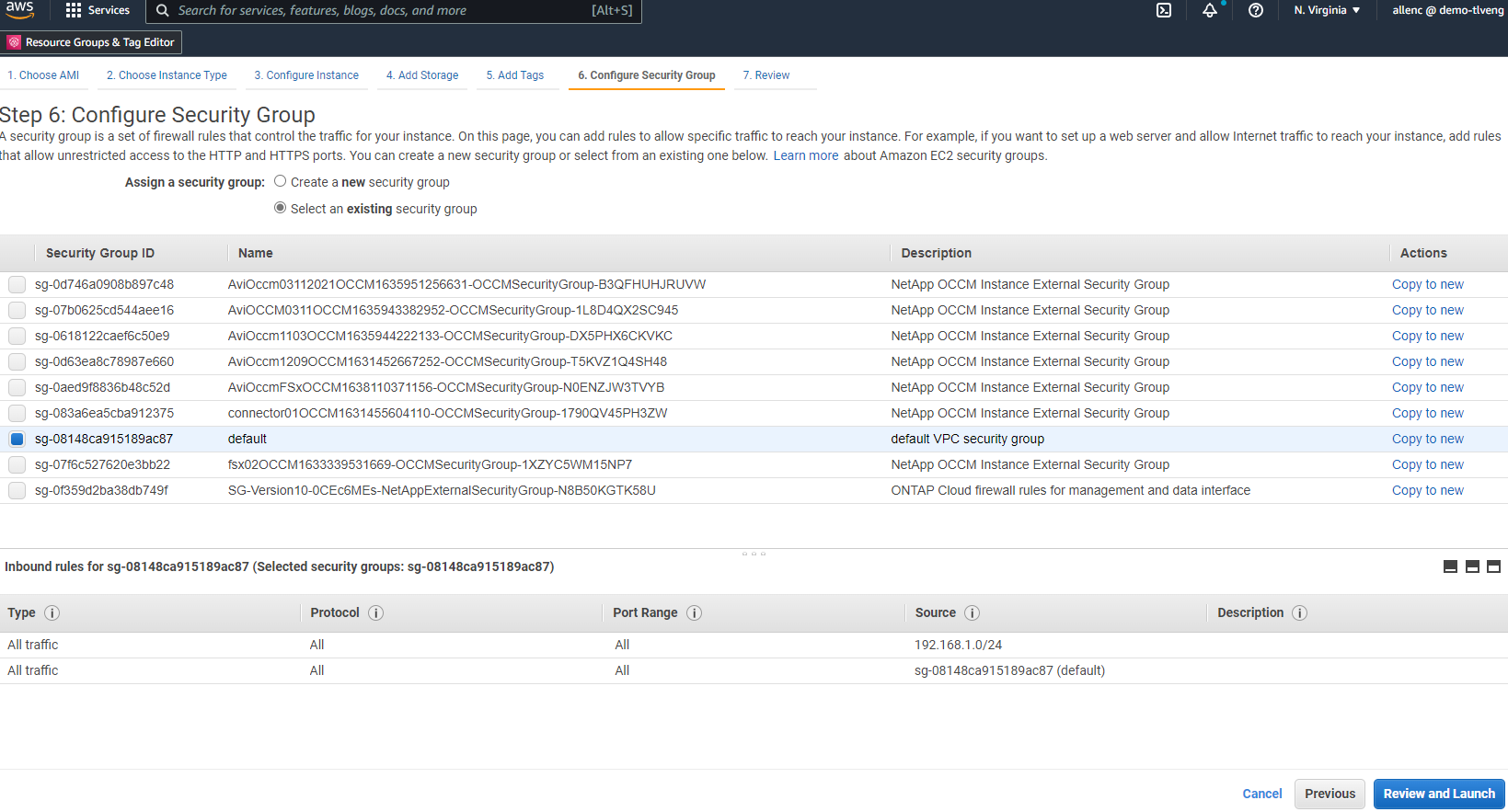
-
Nel passaggio 7, rivedere il riepilogo della configurazione dell'istanza e fare clic su Avvia per avviare la distribuzione dell'istanza. Ti verrà chiesto di creare una coppia di chiavi o di selezionarne una per accedere all'istanza.
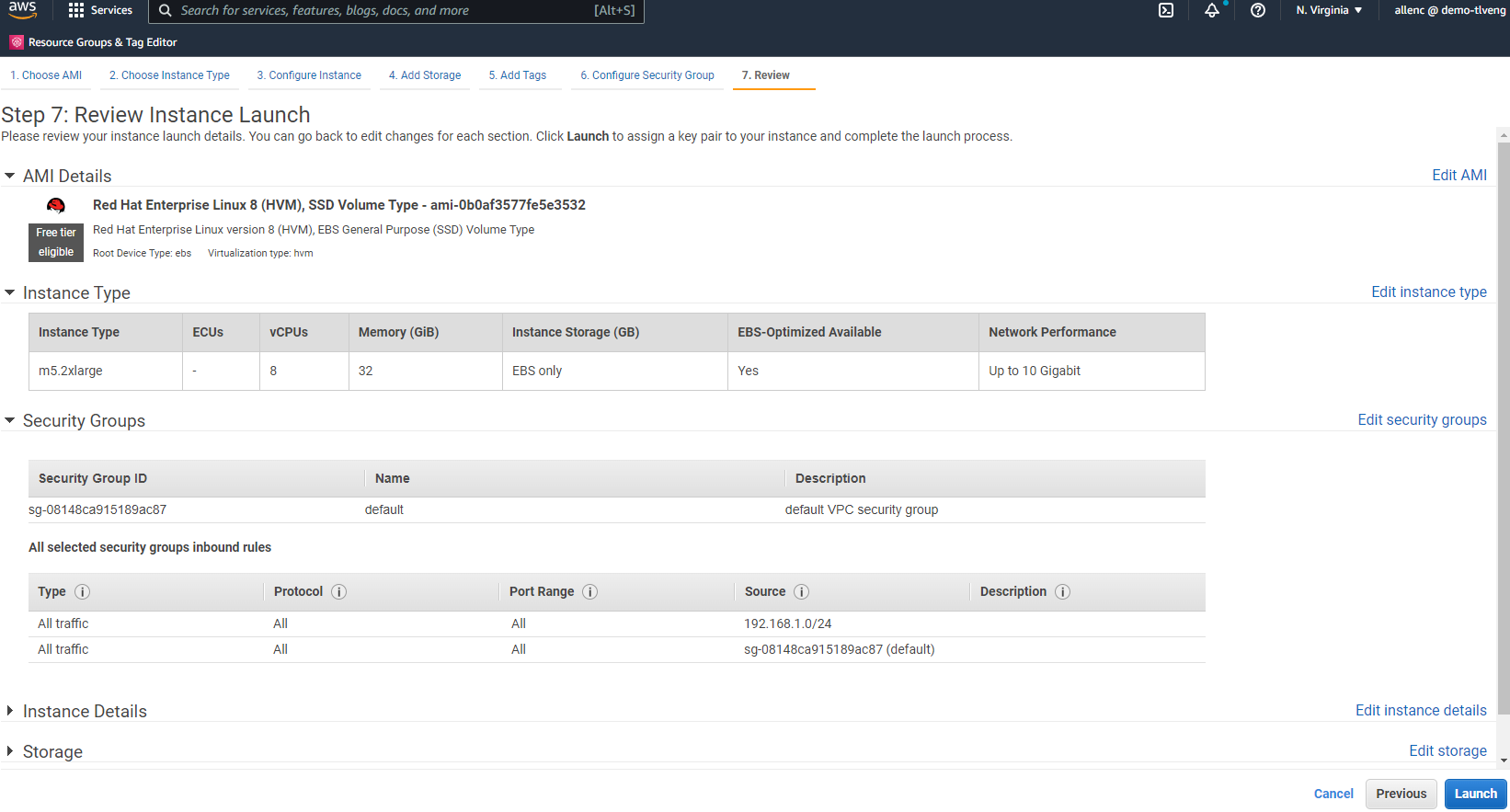
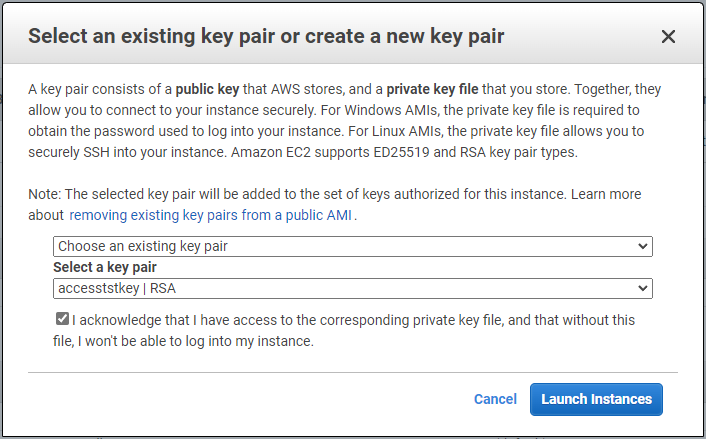
-
Accedi all'istanza EC2 utilizzando una coppia di chiavi SSH. Apportare le modifiche appropriate al nome della chiave e all'indirizzo IP dell'istanza.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
È necessario creare due istanze EC2 come server Oracle primario e di standby nella zona di disponibilità designata, come illustrato nel diagramma dell'architettura.
Fornire file system FSx ONTAP per l'archiviazione del database Oracle
La distribuzione dell'istanza EC2 alloca un volume root EBS per il sistema operativo. I file system FSx ONTAP forniscono volumi di archiviazione del database Oracle, inclusi i volumi binari, di dati e di registro di Oracle. Il provisioning dei volumi NFS di archiviazione FSx può essere effettuato dalla console AWS FSx o dall'installazione di Oracle e dall'automazione della configurazione che alloca i volumi in base alla configurazione effettuata dall'utente in un file di parametri di automazione.
Creazione di file system FSx ONTAP
Riferito a questa documentazione "Gestione dei file system FSx ONTAP" per la creazione di file system FSx ONTAP .
Considerazioni chiave:
-
Capacità di archiviazione SSD. Minimo 1024 GiB, massimo 192 TiB.
-
IOPS SSD forniti. In base ai requisiti del carico di lavoro, un massimo di 80.000 IOPS SSD per file system.
-
Capacità di produzione.
-
Imposta la password dell'amministratore fsxadmin/vsadmin. Necessario per l'automazione della configurazione FSx.
-
Backup e manutenzione. Disattiva i backup giornalieri automatici; il backup dell'archiviazione del database viene eseguito tramite la pianificazione SnapCenter .
-
Recuperare l'indirizzo IP di gestione SVM e gli indirizzi di accesso specifici del protocollo dalla pagina dei dettagli SVM. Necessario per l'automazione della configurazione FSx.
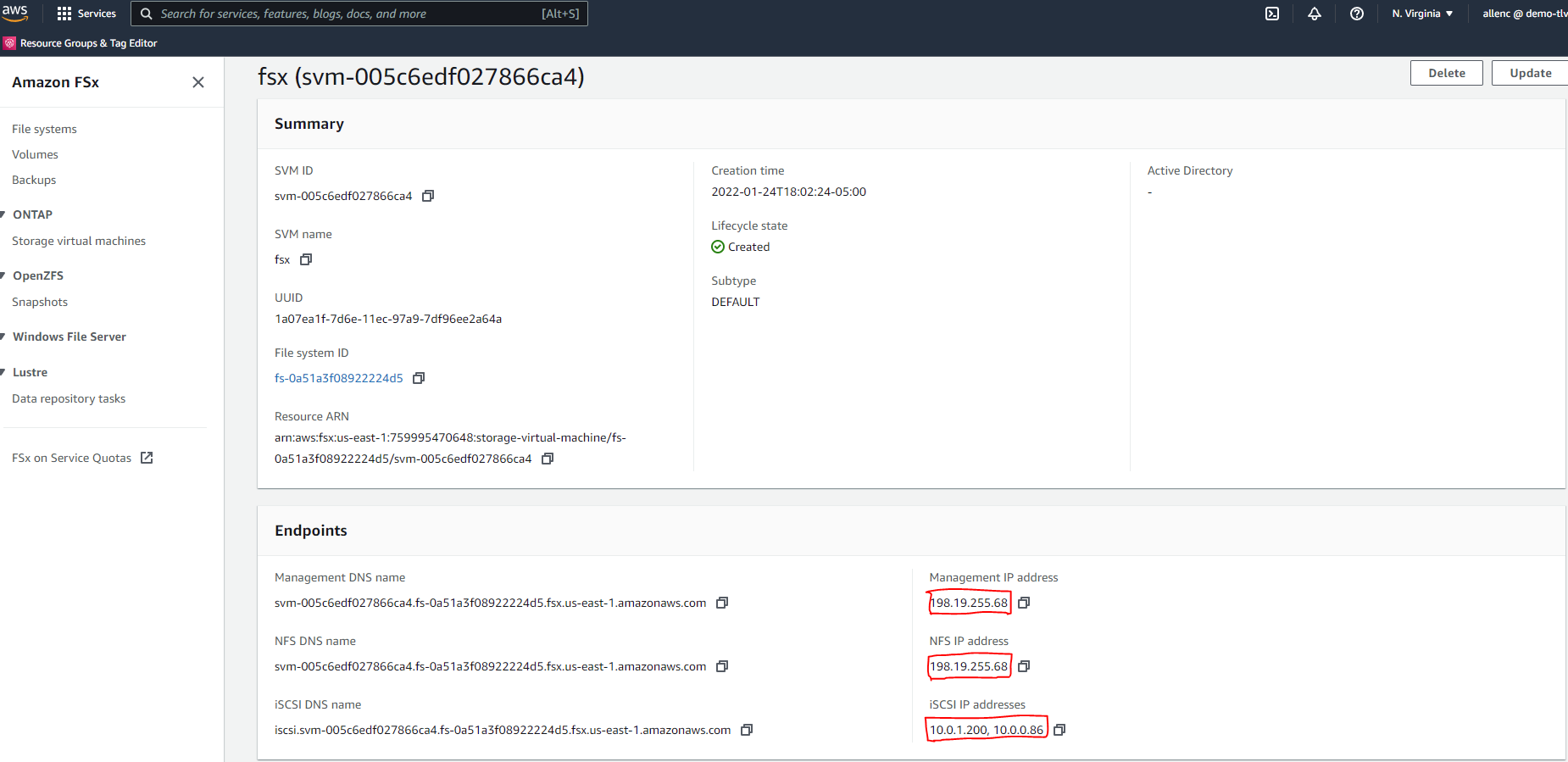
Per configurare un cluster HA FSx primario o di standby, consultare le seguenti procedure dettagliate.
-
Dalla console FSx, fare clic su Crea file system per avviare il flusso di lavoro di provisioning FSx.
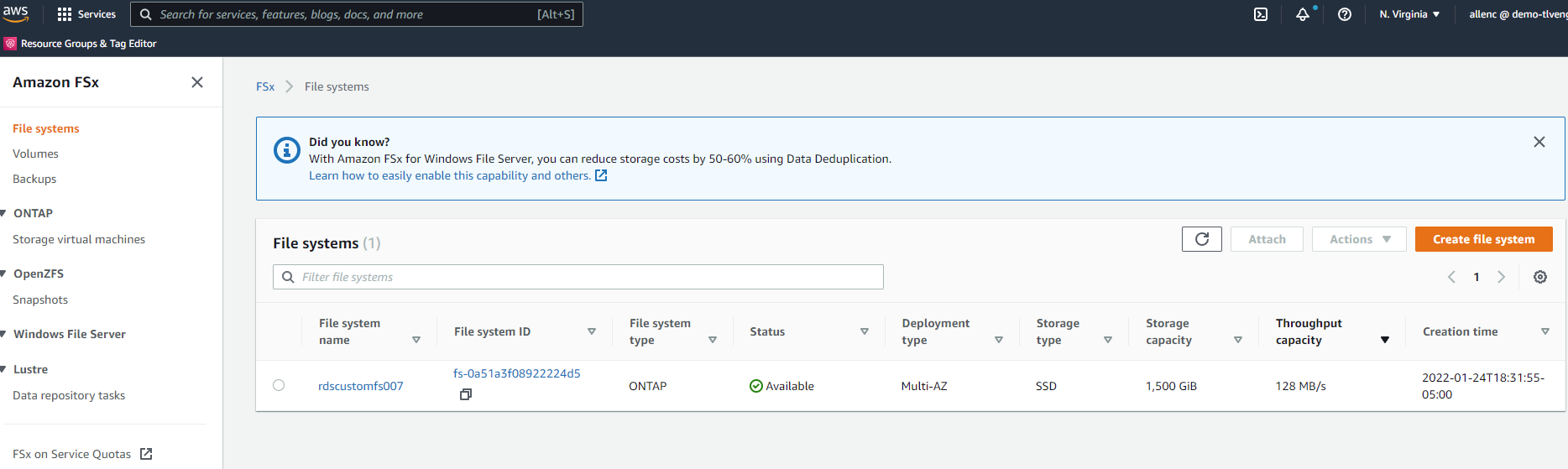
-
Selezionare Amazon FSx ONTAP. Quindi fare clic su Avanti.
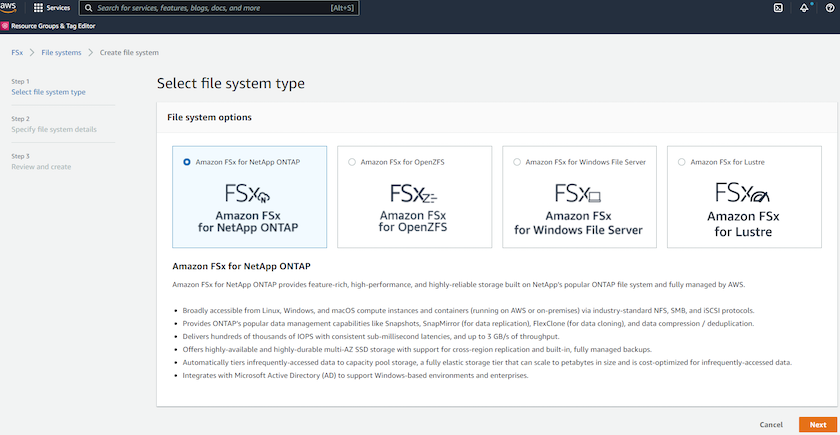
-
Selezionare Crea standard e, in Dettagli file system, assegnare al file system il nome Multi-AZ HA. In base al carico di lavoro del database, scegli IOPS automatici o forniti dall'utente fino a 80.000 IOPS SSD. Lo storage FSx è dotato di una cache NVMe fino a 2 TiB nel backend, in grado di fornire IOPS misurati ancora più elevati.
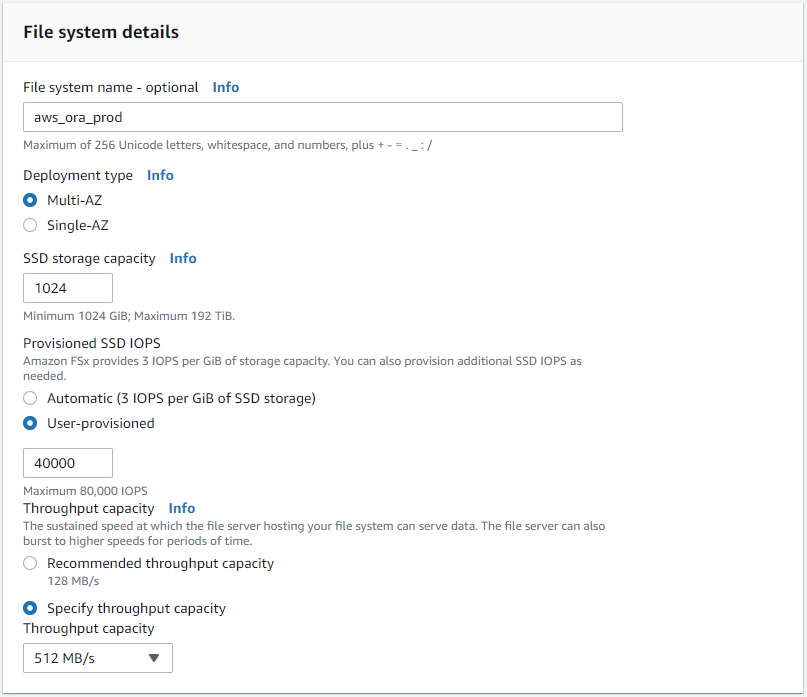
-
Nella sezione Rete e sicurezza, seleziona la VPC, il gruppo di sicurezza e le subnet. Dovrebbero essere creati prima della distribuzione di FSx. In base al ruolo del cluster FSx (primario o standby), posizionare i nodi di archiviazione FSx nelle zone appropriate.
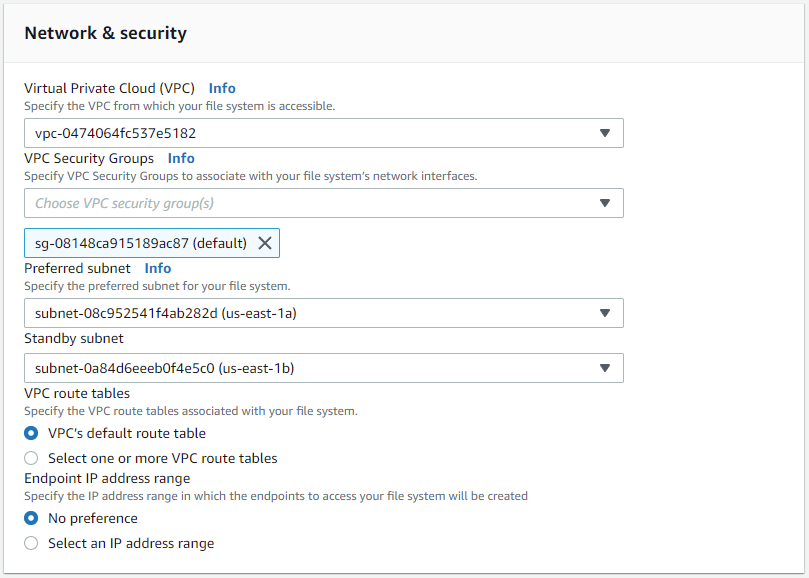
-
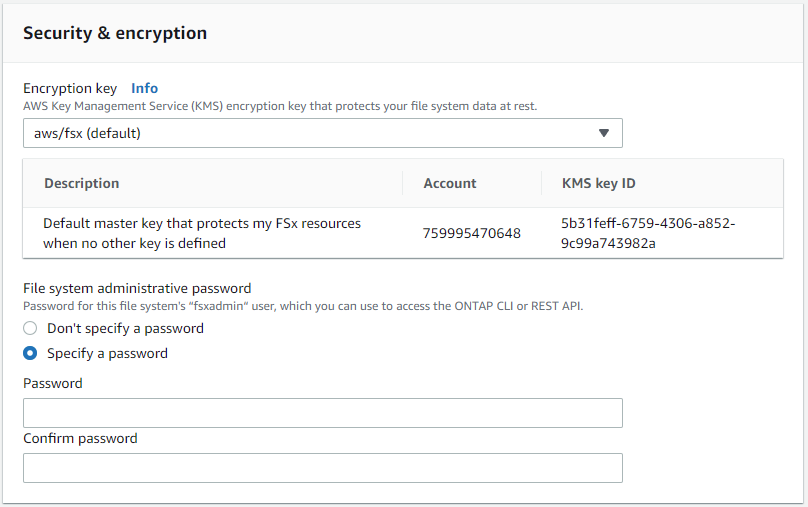
Nella sezione Sicurezza e crittografia, accetta l'impostazione predefinita e inserisci la password fsxadmin.
-
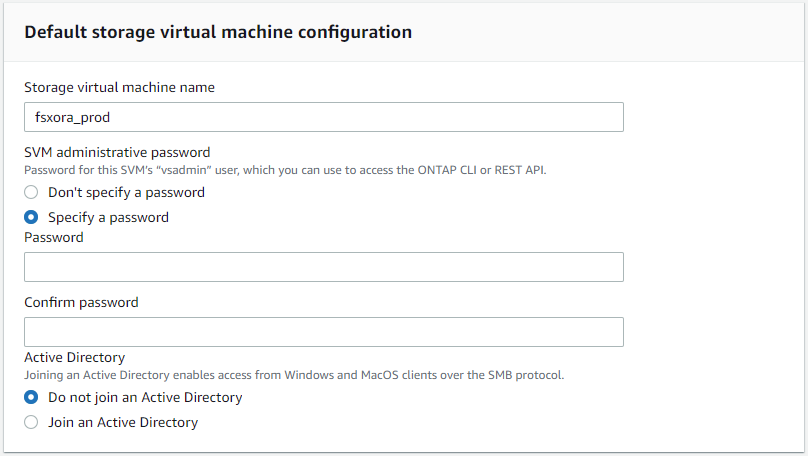
Immettere il nome SVM e la password vsadmin.
-
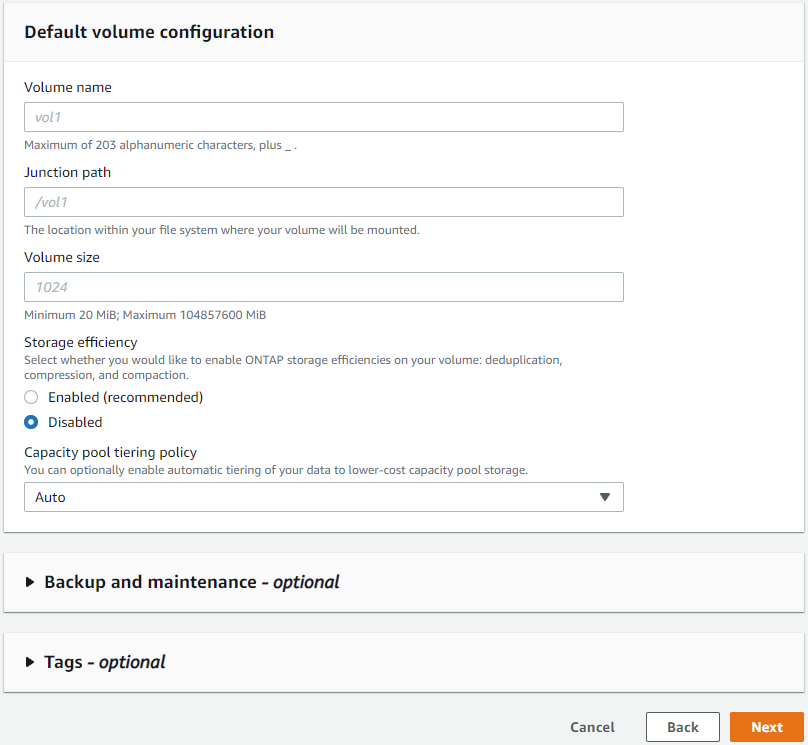
Lasciare vuota la configurazione del volume; non è necessario creare un volume in questa fase.
-
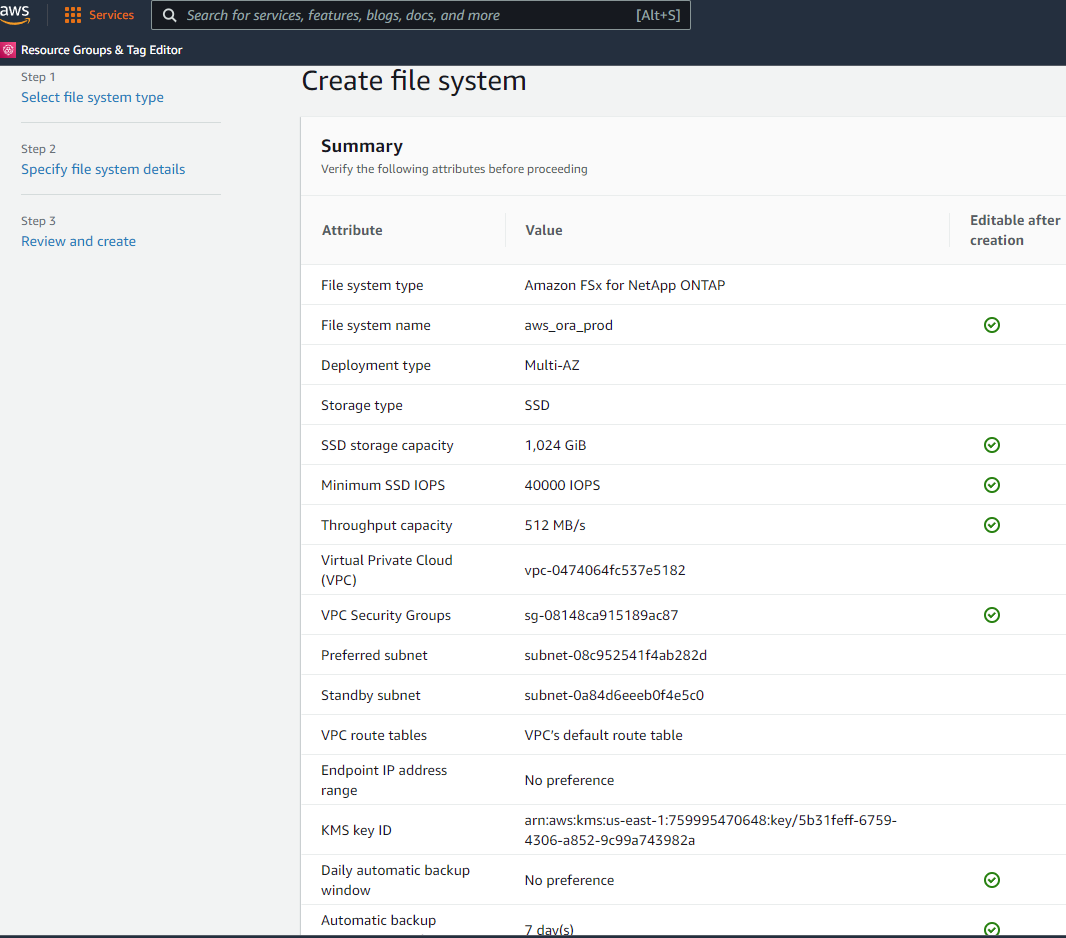
Rivedere la pagina Riepilogo e fare clic su Crea file system per completare il provisioning del file system FSx.
Provisioning di volumi di database per il database Oracle
Vedere"Gestione dei volumi FSx ONTAP : creazione di un volume" per i dettagli.
Considerazioni chiave:
-
Dimensionare adeguatamente i volumi del database.
-
Disabilitazione del criterio di suddivisione in livelli del pool di capacità per la configurazione delle prestazioni.
-
Abilitazione di Oracle dNFS per volumi di archiviazione NFS.
-
Impostazione di percorsi multipli per volumi di archiviazione iSCSI.
Crea volume di database dalla console FSx
Dalla console AWS FSx è possibile creare tre volumi per l'archiviazione dei file del database Oracle: uno per il binario Oracle, uno per i dati Oracle e uno per il log Oracle. Per una corretta identificazione, assicurarsi che la denominazione del volume corrisponda al nome host Oracle (definito nel file hosts nel toolkit di automazione). In questo esempio, utilizziamo db1 come nome host Oracle EC2 anziché un tipico nome host basato sull'indirizzo IP per un'istanza EC2.
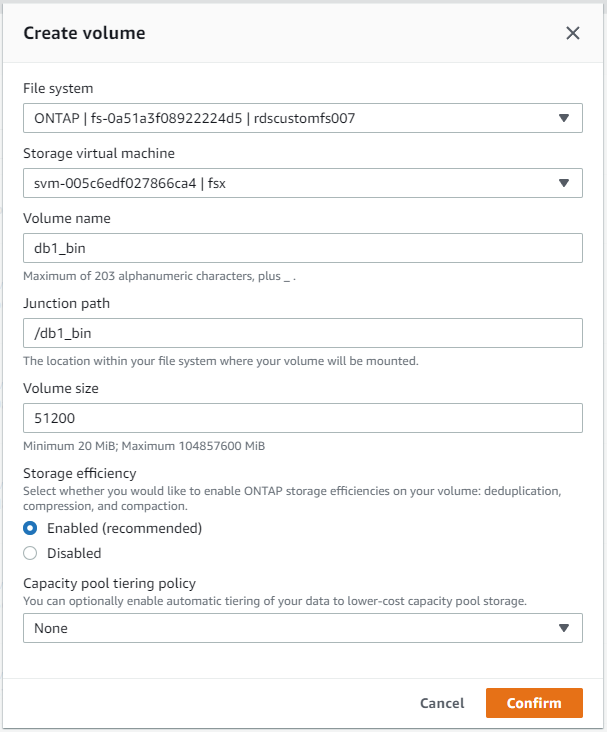
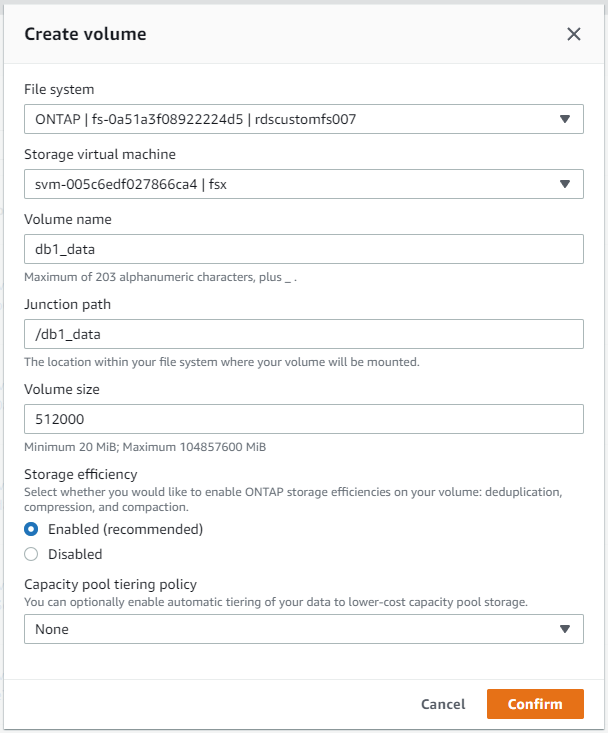
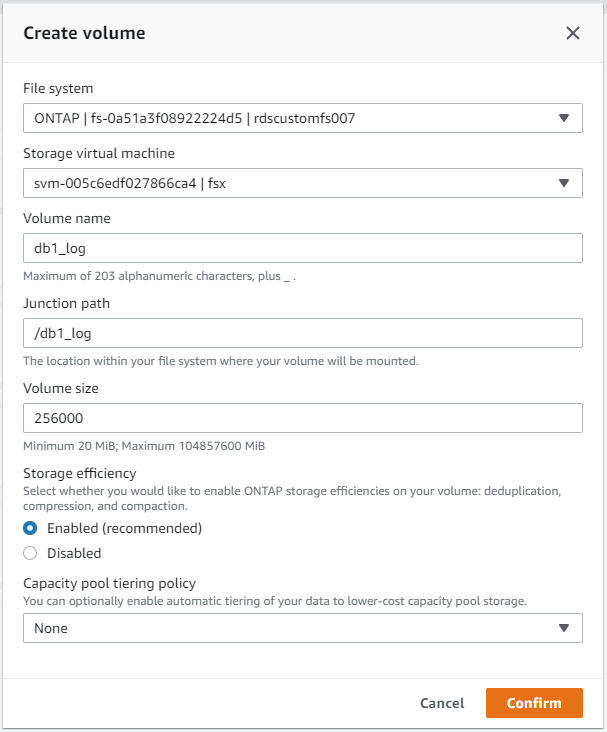

|
La creazione di LUN iSCSI non è attualmente supportata dalla console FSx. Per la distribuzione di LUN iSCSI per Oracle, i volumi e le LUN possono essere creati utilizzando l'automazione per ONTAP con NetApp Automation Toolkit. |
Installa e configura Oracle su un'istanza EC2 con volumi di database FSx
Il team di automazione NetApp fornisce un kit di automazione per eseguire l'installazione e la configurazione di Oracle su istanze EC2 secondo le best practice. La versione corrente del kit di automazione supporta Oracle 19c su NFS con la patch RU predefinita 19.8. Se necessario, il kit di automazione può essere facilmente adattato ad altre patch RU.
Preparare un controller Ansible per eseguire l'automazione
Seguire le istruzioni nella sezione "Creazione e connessione a un'istanza EC2 per l'hosting del database Oracle " per predisporre una piccola istanza EC2 Linux per eseguire il controller Ansible. Invece di usare RedHat, dovrebbe essere sufficiente Amazon Linux t2.large con 2 vCPU e 8 GB di RAM.
Recupera il toolkit di automazione della distribuzione NetApp Oracle
Accedi all'istanza del controller EC2 Ansible fornita dal passaggio 1 come ec2-user e dalla directory home di ec2-user, esegui il comando git clone comando per clonare una copia del codice di automazione.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.gitEseguire la distribuzione automatizzata di Oracle 19c utilizzando il toolkit di automazione
Vedi queste istruzioni dettagliate"Distribuzione CLI del database Oracle 19c" per distribuire Oracle 19c con automazione CLI. C'è una piccola modifica nella sintassi dei comandi per l'esecuzione del playbook perché si utilizza una coppia di chiavi SSH anziché una password per l'autenticazione dell'accesso all'host. L'elenco seguente è un riepilogo di alto livello:
-
Per impostazione predefinita, un'istanza EC2 utilizza una coppia di chiavi SSH per l'autenticazione dell'accesso. Dalle directory radice dell'automazione del controller Ansible
/home/ec2-user/na_oracle19c_deploy, E/home/ec2-user/na_rds_fsx_oranfs_config, crea una copia della chiave SSHaccesststkey.pemper l'host Oracle distribuito nel passaggio "Creazione e connessione a un'istanza EC2 per l'hosting del database Oracle ." -
Accedi all'host DB dell'istanza EC2 come ec2-user e installa la libreria python3.
sudo yum install python3 -
Creare uno spazio di swap da 16 GB dall'unità disco radice. Per impostazione predefinita, un'istanza EC2 non crea spazio di swap. Segui questa documentazione AWS:"Come posso allocare memoria da utilizzare come spazio di swap in un'istanza Amazon EC2 utilizzando un file di swap?" .
-
Torna al controller Ansible(
cd /home/ec2-user/na_rds_fsx_oranfs_config), ed eseguire il playbook preclone con i requisiti appropriati elinux_configtag.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
Passare a
/home/ec2-user/na_oracle19c_deploy-masterdirectory, leggere il file README e popolare il globalevars.ymlfile con i parametri globali rilevanti. -
Popola il
host_name.ymlfile con i parametri rilevanti nelhost_varselenco. -
Eseguire il playbook per Linux e premere Invio quando viene richiesta la password vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Eseguire il playbook per Oracle e premere Invio quando viene richiesta la password vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
Se necessario, modificare il bit di autorizzazione sul file chiave SSH su 400. Cambia l'host Oracle(ansible_host nel host_vars file) Indirizzo IP all'indirizzo pubblico della tua istanza EC2.
Impostazione di SnapMirror tra il cluster FSx HA primario e quello di standby
Per un'elevata disponibilità e il ripristino di emergenza, è possibile impostare la replica SnapMirror tra il cluster di archiviazione FSx primario e quello di standby. A differenza di altri servizi di archiviazione cloud, FSx consente all'utente di controllare e gestire la replicazione dell'archiviazione con la frequenza e la velocità di replica desiderate. Consente inoltre agli utenti di testare HA/DR senza alcun effetto sulla disponibilità.
I passaggi seguenti mostrano come impostare la replica tra un cluster di archiviazione FSx primario e uno di standby.
-
Impostare il peering del cluster primario e di standby. Accedere al cluster primario come utente fsxadmin ed eseguire il seguente comando. Questo processo di creazione reciproco esegue il comando di creazione sia sul cluster primario che su quello di standby. Sostituire
standby_cluster_namecon il nome appropriato per il tuo ambiente.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
Impostare il peering vServer tra il cluster primario e quello di standby. Accedi al cluster primario come utente vsadmin ed esegui il seguente comando. Sostituire
primary_vserver_name,standby_vserver_name,standby_cluster_namecon i nomi appropriati per il tuo ambiente.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
Verificare che i peering del cluster e del vserver siano configurati correttamente.
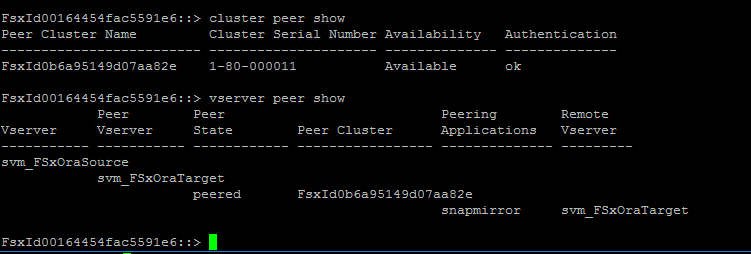
-
Creare volumi NFS di destinazione nel cluster FSx di standby per ciascun volume di origine nel cluster FSx primario. Sostituisci il nome del volume in base al tuo ambiente.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
È anche possibile creare volumi iSCSI e LUN per il binario Oracle, i dati Oracle e il registro Oracle se per l'accesso ai dati viene utilizzato il protocollo iSCSI. Lasciare circa il 10% di spazio libero nei volumi per gli snapshot.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -unix-permissions ---rwxr-xr-x -type RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
Per i LUN iSCSI, creare una mappatura per l'iniziatore host Oracle per ciascun LUN, utilizzando il LUN binario come esempio. Sostituire igroup con un nome appropriato per il proprio ambiente e incrementare lun-id per ogni LUN aggiuntivo.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
Creare una relazione SnapMirror tra i volumi del database primario e di standby. Sostituisci il nome SVM appropriato per il tuo ambiente.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
Questa configurazione SnapMirror può essere automatizzata con un NetApp Automation Toolkit per volumi di database NFS. Il toolkit può essere scaricato dal sito pubblico GitHub NetApp .
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLeggere attentamente le istruzioni README prima di tentare la configurazione e il test di failover.
|
|
La replica del binario Oracle dal cluster primario a uno standby potrebbe avere implicazioni sulla licenza Oracle. Per chiarimenti, contattare il rappresentante delle licenze Oracle. L'alternativa è installare e configurare Oracle al momento del ripristino e del failover. |
Distribuzione di SnapCenter
Installazione SnapCenter
Seguire"Installazione del server SnapCenter" per installare il server SnapCenter . Questa documentazione spiega come installare un server SnapCenter autonomo. Una versione SaaS di SnapCenter è in fase di revisione beta e potrebbe essere disponibile a breve. Se necessario, verificare la disponibilità con il proprio rappresentante NetApp .
Configurare il plugin SnapCenter per l'host Oracle EC2
-
Dopo l'installazione automatica SnapCenter , accedi a SnapCenter come utente amministratore per l'host Windows su cui è installato il server SnapCenter .

-
Dal menu a sinistra, fare clic su Impostazioni, quindi su Credenziali e Nuovo per aggiungere le credenziali ec2-user per l'installazione del plugin SnapCenter .
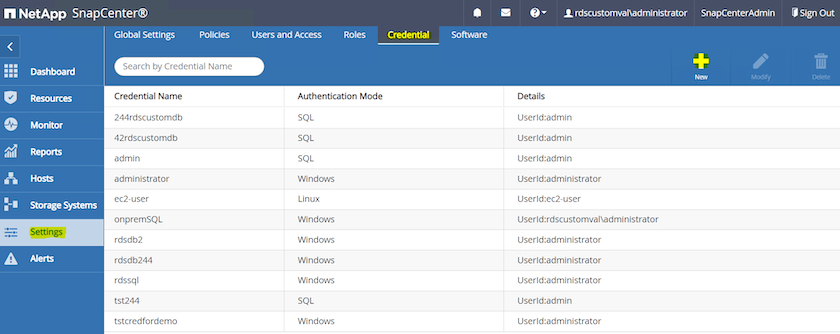
-
Reimposta la password ec2-user e abilita l'autenticazione SSH tramite password modificando
/etc/ssh/sshd_configfile sull'host dell'istanza EC2. -
Verificare che la casella di controllo "Usa privilegi sudo" sia selezionata. Nel passaggio precedente hai appena reimpostato la password ec2-user.
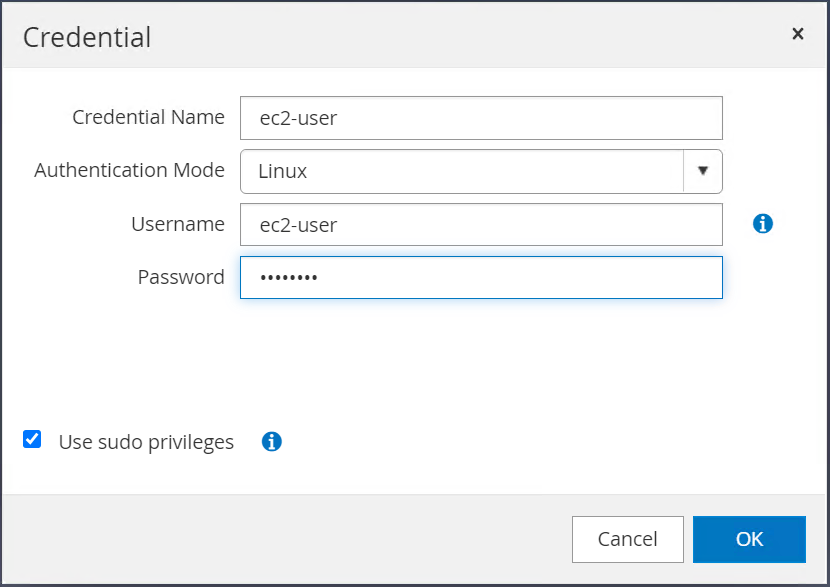
-
Aggiungere il nome del server SnapCenter e l'indirizzo IP al file host dell'istanza EC2 per la risoluzione dei nomi.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
Sull'host Windows del server SnapCenter , aggiungere l'indirizzo IP dell'host dell'istanza EC2 al file host Windows
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
Nel menu a sinistra, seleziona Host > Host gestiti, quindi fai clic su Aggiungi per aggiungere l'host dell'istanza EC2 a SnapCenter.
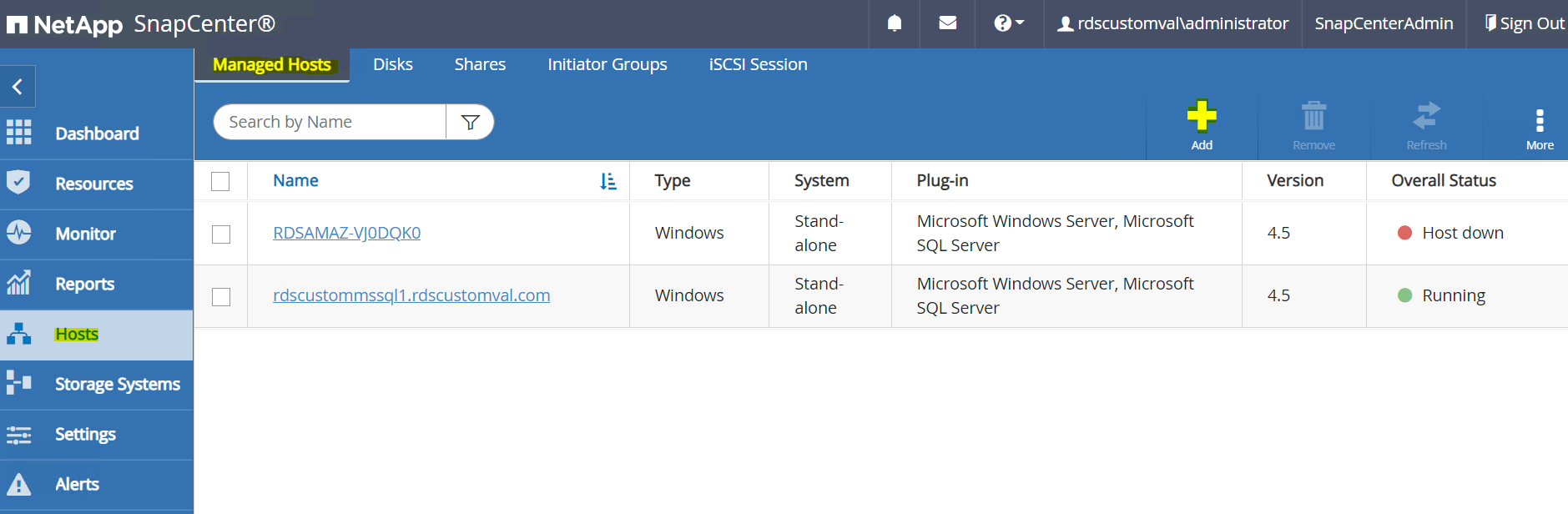
Selezionare Oracle Database e, prima di inviare, fare clic su Altre opzioni.
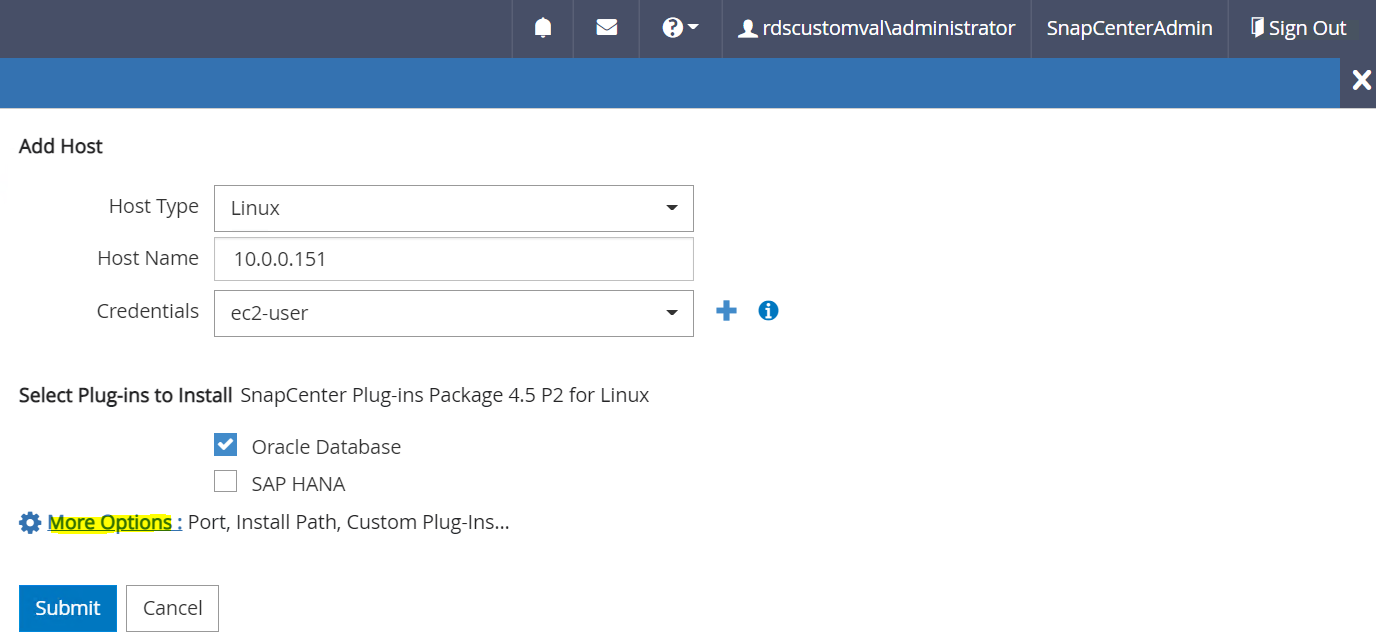
Selezionare Salta controlli preinstallazione. Confermare l'opzione "Salta controlli preinstallazione", quindi fare clic su Invia dopo aver salvato.
Verrà richiesto di confermare l'impronta digitale, quindi fare clic su Conferma e invia.
Dopo aver configurato correttamente il plugin, lo stato generale dell'host gestito viene visualizzato come In esecuzione.

Configurare la policy di backup per il database Oracle
Fare riferimento a questa sezione"Imposta la policy di backup del database in SnapCenter" per i dettagli sulla configurazione della policy di backup del database Oracle.
In genere è necessario creare una policy per il backup completo dello snapshot del database Oracle e una policy per il backup snapshot solo del log di archivio Oracle.
|
|
È possibile abilitare la potatura del log di archivio Oracle nella policy di backup per controllare lo spazio di archiviazione del log. Selezionare "Aggiorna SnapMirror dopo aver creato una copia Snapshot locale" in "Seleziona opzione di replica secondaria" poiché è necessario replicare in una posizione di standby per HA o DR. |
Configurare il backup e la pianificazione del database Oracle
Il backup del database in SnapCenter è configurabile dall'utente e può essere impostato individualmente o come gruppo in un gruppo di risorse. L'intervallo di backup dipende dagli obiettivi RTO e RPO. NetApp consiglia di eseguire un backup completo del database ogni poche ore e di archiviare il backup del registro con una frequenza maggiore, ad esempio ogni 10-15 minuti, per un ripristino rapido.
Fare riferimento alla sezione Oracle di"Implementare una politica di backup per proteggere il database" per una procedura dettagliata passo dopo passo per l'implementazione della policy di backup creata nella sezioneConfigurare la policy di backup per il database Oracle e per la pianificazione dei lavori di backup.
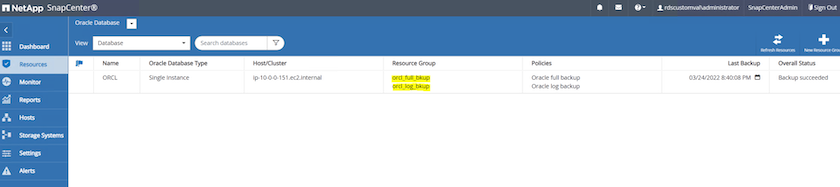
L'immagine seguente fornisce un esempio dei gruppi di risorse configurati per eseguire il backup di un database Oracle.