

File di database e filegroup
 Suggerisci modifiche
Suggerisci modifiche
Il corretto posizionamento dei file del database SQL Server su ONTAP è fondamentale durante la fase di distribuzione iniziale. Ciò garantisce prestazioni ottimali, gestione dello spazio, tempi di backup e ripristino che possono essere configurati in base alle esigenze aziendali.
In teoria, SQL Server (a 64 bit) supporta 32.767 database per istanza e 524.272TB di dimensioni del database, sebbene l'installazione tipica abbia in genere diversi database. Tuttavia, il numero di database che SQL Server è in grado di gestire dipende dal carico e dall'hardware. Non è insolito vedere le istanze di SQL Server che ospitano decine, centinaia o persino migliaia di database di piccole dimensioni.
File di database e filegroup
Ogni database è costituito da uno o più file di dati e da uno o più file di registro delle transazioni. Il registro delle transazioni memorizza le informazioni sulle transazioni del database e tutte le modifiche apportate ai dati da ciascuna sessione. Ogni volta che i dati vengono modificati, SQL Server memorizza informazioni sufficienti nel log delle transazioni per annullare (eseguire il rollback) o ripristinare (riprodurre nuovamente) l'azione. Un log delle transazioni di SQL Server è parte integrante della reputazione di SQL Server in termini di integrità e robustezza dei dati. Il log delle transazioni è fondamentale per le funzionalità di atomicità, coerenza, isolamento e durata (ACID) di SQL Server. SQL Server scrive nel registro delle transazioni non appena si verifica una modifica alla pagina dei dati. Ogni istruzione DML (Data Manipulation Language) (ad esempio, SELECT, INSERT, Update o DELETE) è una transazione completa e il log delle transazioni garantisce che l'intera operazione basata su set abbia luogo, assicurando l'atomicità della transazione.
Ogni database dispone di un file di dati primario che, per impostazione predefinita, ha l'estensione .mdf. Inoltre, ogni database può disporre di file di database secondari. Questi file, per impostazione predefinita, hanno estensioni .ndf.
Tutti i file di database sono raggruppati in filegroup. Un filegroup è l'unità logica, che semplifica l'amministrazione del database. Consentono la separazione tra il posizionamento degli oggetti logici e i file di database fisici. Quando si creano le tabelle degli oggetti del database, si specifica in quale filegroup devono essere posizionati senza preoccuparsi della configurazione del file di dati sottostante.
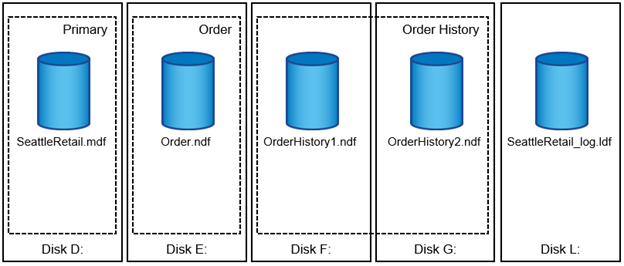
La possibilità di inserire più file di dati all'interno del filegroup consente di distribuire il carico su diversi dispositivi di archiviazione, migliorando le prestazioni di i/o del sistema. Al contrario, il log delle transazioni non trae vantaggio dai file multipli poiché SQL Server scrive nel log delle transazioni in modo sequenziale.
La separazione tra il posizionamento degli oggetti logici nei filegroup e i file di database fisici consente di ottimizzare il layout dei file di database, ottenendo il massimo dal sottosistema di storage. Il numero di file di dati che supportano un carico di lavoro può essere variato in base alle necessità per supportare i requisiti di i/o e la capacità prevista, senza influire sull'applicazione. Queste variazioni nel layout del database sono trasparenti per gli sviluppatori di applicazioni, che posizionano gli oggetti del database nei filegroup piuttosto che nei file di database.

|
NetApp recommended evitare l'utilizzo del filegroup primario per oggetti diversi da quelli di sistema. La creazione di un filegroup separato o di un set di filegroup per gli oggetti utente semplifica l'amministrazione del database e il ripristino di emergenza, soprattutto nel caso di database di grandi dimensioni. |
Inizializzazione del file di istanza del database
È possibile specificare le dimensioni iniziali del file e i parametri di crescita automatica al momento della creazione del database o dell'aggiunta di nuovi file a un database esistente. SQL Server utilizza un algoritmo di riempimento proporzionale quando sceglie in quale file di dati scrivere i dati. Scrive una quantità di dati proporzionalmente allo spazio libero disponibile nei file. Maggiore è lo spazio libero nel file, maggiore è il numero di scritture gestite.
|
|
NetApp consiglia che tutti i file nel singolo filegroup abbiano le stesse dimensioni iniziali e parametri di crescita automatica, con la dimensione di crescita definita in megabyte piuttosto che in percentuali. Questo aiuta l'algoritmo di riempimento proporzionale a bilanciare uniformemente le attività di scrittura nei file di dati. |
Ogni volta che SQL Server espande i file, riempie di zero lo spazio appena allocato. Questo processo blocca tutte le sessioni che devono scrivere nel file corrispondente o, in caso di crescita del log delle transazioni, genera record di log delle transazioni.
SQL Server azzera sempre il log delle transazioni e questo comportamento non può essere modificato. Tuttavia, è possibile controllare se i file di dati vengono azzerati attivando o disattivando l'inizializzazione istantanea dei file. L'attivazione dell'inizializzazione immediata dei file consente di velocizzare la crescita dei file di dati e di ridurre il tempo necessario per creare o ripristinare il database.
Un piccolo rischio per la sicurezza è associato all'inizializzazione immediata dei file. Quando questa opzione è attivata, le parti non allocate del file di dati possono contenere informazioni provenienti da file del sistema operativo eliminati in precedenza. Gli amministratori di database possono esaminare tali dati.
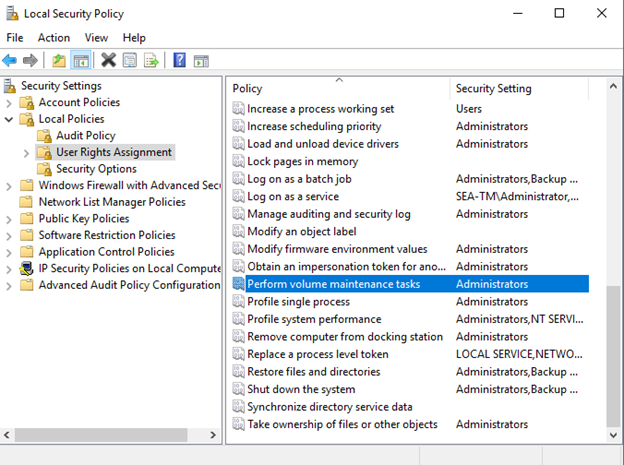
È possibile attivare l'inizializzazione immediata dei file aggiungendo l'autorizzazione SA_MANAGE_VOLUME_NAME, nota anche come "Esegui attività di manutenzione del volume" all'account di avvio di SQL Server. È possibile eseguire questa operazione nell'applicazione di gestione dei criteri di protezione locale (secpol.msc), come illustrato nella figura seguente. Aprire le proprietà per l'autorizzazione "Esegui attività di manutenzione del volume" e aggiungere l'account di avvio di SQL Server all'elenco degli utenti.
Per verificare se l'autorizzazione è attivata, è possibile utilizzare il codice riportato nell'esempio seguente. Questo codice imposta due flag di traccia che obbligano SQL Server a scrivere informazioni aggiuntive nel registro degli errori, a creare un database di piccole dimensioni e a leggere il contenuto del registro.
DBCC TRACEON(3004,3605,-1) GO CREATE DATABASE DelMe GO EXECUTE sp_readerrorlog GO DROP DATABASE DelMe GO DBCC TRACEOFF(3004,3605,-1) GO
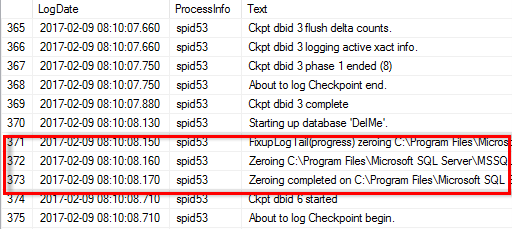
Quando l'inizializzazione immediata del file non è attivata, il registro degli errori di SQL Server mostra che SQL Server sta azzerando il file di dati mdf oltre a azzerare il file di registro ldf, come illustrato nell'esempio seguente. Quando l'inizializzazione immediata del file è attivata, viene visualizzato solo l'azzeramento del file di registro.
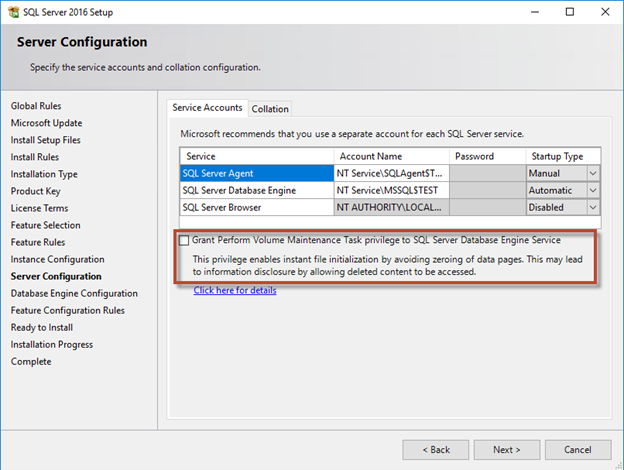
L'attività Esegui manutenzione volume è semplificata in SQL Server 2016 e viene fornita come opzione durante il processo di installazione. In questa figura viene visualizzata l'opzione per concedere al servizio del motore di database di SQL Server il privilegio di eseguire l'attività di manutenzione del volume.
Un'altra importante opzione del database che controlla le dimensioni dei file di database è l'autohrink. Quando questa opzione è attivata, SQL Server riduce regolarmente i file di database, ne riduce le dimensioni e rilascia spazio al sistema operativo. Questa operazione richiede molte risorse ed è raramente utile perché i file di database crescono di nuovo dopo un certo periodo di tempo quando nuovi dati entrano nel sistema. Il collegamento automatico non deve essere attivato nel database.
Directory di log
La directory di registro è specificata in SQL Server per memorizzare i dati di backup del registro delle transazioni a livello di host. Se si utilizza SnapCenter per eseguire il backup dei file di registro, ciascun host SQL Server utilizzato da SnapCenter deve disporre di una directory di registro host configurata per eseguire i backup dei registri. SnapCenter dispone di un repository di database, pertanto i metadati relativi alle operazioni di backup, ripristino o clonazione vengono memorizzati in un repository di database centrale.
Le dimensioni della directory del registro host vengono calcolate come segue:
Dimensione della directory del log host = ( (dimensione massima LDF DB x velocità di modifica giornaliera del log %) x (conservazione snapshot) ÷ (1 - spazio di overhead LUN %)
La formula di dimensionamento della directory del registro host presuppone uno spazio di overhead LUN del 10%
Posizionare la directory di registro su un volume o LUN dedicato. La quantità di dati nella directory del registro host dipende dalle dimensioni dei backup e dal numero di giorni in cui i backup vengono conservati. SnapCenter consente una sola directory di registro host per host SQL Server. È possibile configurare le directory del registro host in SnapCenter -→ host -→ Configura plug-in.
|
|
NetApp consiglia quanto segue per una directory del registro host:
|