

HA ulteriori dettagli
 Suggerisci modifiche
Suggerisci modifiche
Heartbeat del disco HA, mailbox ha, heartbeat ha, failover ha e Giveback lavorano per migliorare la protezione dei dati.
Heartbeat dei dischi
Sebbene l'architettura ONTAP Select ha utilizzi molti dei percorsi di codice utilizzati dagli array FAS tradizionali, esistono alcune eccezioni. Una di queste eccezioni riguarda l'implementazione del heartbeat basato su disco, un metodo di comunicazione non basato sulla rete utilizzato dai nodi del cluster per impedire che l'isolamento della rete causi un comportamento split-brain. Uno scenario split-brain è il risultato del partizionamento del cluster, in genere causato da errori di rete, per cui ciascun lato ritiene che l'altro sia inattivo e tenta di assumere il controllo delle risorse del cluster.
Le implementazioni di ha di livello Enterprise devono gestire questo tipo di scenario in modo corretto. ONTAP esegue questa operazione attraverso un metodo di heartbeat personalizzato e basato su disco. Questo è il lavoro della mailbox ha, una posizione sullo storage fisico che viene utilizzata dai nodi del cluster per passare i messaggi heartbeat. In questo modo, il cluster può determinare la connettività e definire il quorum in caso di failover.
Negli array FAS, che utilizzano un'architettura di storage ha condivisa, ONTAP risolve i problemi di split-brain nei seguenti modi:
-
Riserve persistenti SCSI
-
Metadati ha persistenti
-
Stato HA inviato tramite interconnessione ha
Tuttavia, all'interno dell'architettura shared-nothing di un cluster ONTAP Select, un nodo è in grado di vedere solo il proprio storage locale e non quello del partner ha. Pertanto, quando la partizione di rete isola ciascun lato di una coppia ha, i metodi precedenti per determinare il quorum del cluster e il comportamento di failover non sono disponibili.
Sebbene non sia possibile utilizzare il metodo esistente di rilevamento ed evasione del cervello diviso, è comunque necessario un metodo di mediazione che rientri nei limiti di un ambiente senza condivisione. ONTAP Select estende ulteriormente l'infrastruttura di caselle postali esistente, consentendo all'IT di agire come metodo di mediazione in caso di partizione della rete. Poiché lo storage condiviso non è disponibile, la mediazione viene eseguita attraverso l'accesso ai dischi della mailbox su NAS. Questi dischi sono distribuiti in tutto il cluster, incluso il mediatore in un cluster a due nodi, utilizzando il protocollo iSCSI. Pertanto, un nodo del cluster può prendere decisioni di failover intelligenti in base all'accesso a questi dischi. Se un nodo può accedere ai dischi della mailbox di altri nodi al di fuori del proprio partner ha, è probabile che sia funzionante.

|
L'architettura della mailbox e il metodo di heartbeat basato su disco per risolvere i problemi di quorum del cluster e di split-brain sono i motivi per cui la variante multinodo di ONTAP Select richiede quattro nodi separati o un mediatore per un cluster a due nodi. |
Pubblicazione della mailbox HA
L'architettura della cassetta postale ha utilizza un modello di message post. A intervalli ripetuti, i nodi del cluster pubblicano messaggi su tutti gli altri dischi della mailbox nel cluster, incluso il mediatore, indicando che il nodo è attivo e in esecuzione. All'interno di un cluster integro in qualsiasi momento, un singolo disco della mailbox su un nodo del cluster contiene messaggi inviati da tutti gli altri nodi del cluster.
A ciascun nodo del cluster Select è collegato un disco virtuale che viene utilizzato specificamente per l'accesso alla mailbox condivisa. Questo disco viene chiamato disco della mailbox del mediatore, perché la sua funzione principale è quella di agire come metodo di mediazione del cluster in caso di guasti al nodo o partizione di rete. Questo disco della mailbox contiene partizioni per ciascun nodo del cluster ed è montato su una rete iSCSI da altri nodi del cluster Select. Periodicamente, questi nodi pubblicano gli stati di integrità nella partizione appropriata del disco della mailbox. L'utilizzo di dischi di mailbox accessibili dalla rete distribuiti in tutto il cluster consente di dedurre lo stato dei nodi attraverso una matrice di raggiungibilità. Ad esempio, i nodi del cluster A e B possono inviare messaggi alla cassetta postale del nodo del cluster D, ma non alla cassetta postale del nodo C. inoltre, il nodo del cluster D non può inviare messaggi alla cassetta postale del nodo C, pertanto è probabile che il nodo C sia inattivo o isolato dalla rete e debba essere sostituito.
HA heartbeat
Come per le piattaforme NetApp FAS, ONTAP Select invia periodicamente messaggi heartbeat ha tramite l'interconnessione ha. All'interno del cluster ONTAP Select, questa operazione viene eseguita tramite una connessione di rete TCP/IP esistente tra i partner ha. Inoltre, i messaggi heartbeat basati su disco vengono passati a tutti i dischi di ha mailbox, inclusi i dischi di mediatore mailbox. Questi messaggi vengono trasmessi ogni pochi secondi e letti periodicamente. La frequenza con cui questi vengono inviati e ricevuti consente al cluster ONTAP Select di rilevare gli eventi di guasto ha entro circa 15 secondi, la stessa finestra disponibile sulle piattaforme FAS. Quando i messaggi heartbeat non vengono più letti, viene attivato un evento di failover.
La figura seguente mostra il processo di invio e ricezione di messaggi heartbeat sui dischi di interconnessione ha e mediatore dal punto di vista di un singolo nodo del cluster ONTAP Select, il nodo C.
|
|
Gli heartbeat di rete vengono inviati tramite l'interconnessione ha al partner ha, nodo D, mentre gli heartbeat dei dischi utilizzano i dischi delle cassette postali in tutti i nodi del cluster, A, B, C e D. |
Heartbeating ha in un cluster a quattro nodi: Stato stazionario 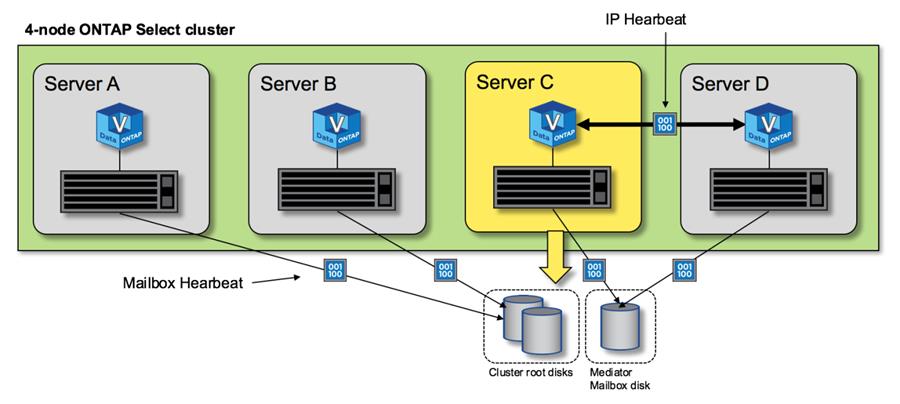
Failover E giveback HA
Durante un'operazione di failover, il nodo sopravvissuto assume le responsabilità di servizio dei dati per il nodo peer utilizzando la copia locale dei dati del partner ha. L'i/o del client può continuare senza interruzioni, ma le modifiche a questi dati devono essere replicate prima che possa verificarsi il giveback. Si noti che ONTAP Select non supporta un giveback forzato perché ciò causa la perdita delle modifiche memorizzate nel nodo sopravvissuto.
L'operazione di sincronizzazione viene attivata automaticamente quando il nodo riavviato si ricongiunge al cluster. Il tempo necessario per la sincronizzazione dipende da diversi fattori. Questi fattori includono il numero di modifiche da replicare, la latenza di rete tra i nodi e la velocità dei sottosistemi dei dischi su ciascun nodo. È possibile che il tempo necessario per la sincronizzazione superi la finestra di ritorno automatico di 10 minuti. In questo caso, è necessario un giveback manuale dopo la sincronizzazione. È possibile monitorare l'avanzamento della sincronizzazione utilizzando il seguente comando:
storage aggregate status -r -aggregate <aggregate name>