

Sostituire il modulo NVRAM o i DIMM NVRAM - AFF A700
 Suggerisci modifiche
Suggerisci modifiche
Il modulo NVRAM è costituito da NVRAM10 GB e DIMM e fino a due moduli Flash cache SSD NVMe (moduli Flash cache o di caching) per modulo NVRAM. È possibile sostituire un modulo NVRAM guasto o i DIMM all'interno del modulo NVRAM.
Per sostituire un modulo NVRAM guasto, occorre rimuoverlo dallo chassis, rimuovere il modulo o i moduli Flash cache dal modulo NVRAM, spostare i DIMM nel modulo sostitutivo, reinstallare il modulo o i moduli Flash cache e installare il modulo NVRAM sostitutivo nello chassis.
Poiché l'ID di sistema deriva dal modulo NVRAM, in caso di sostituzione del modulo, i dischi appartenenti al sistema vengono riassegnati al nuovo ID di sistema.
-
Tutti gli shelf di dischi devono funzionare correttamente.
-
Se il sistema si trova in una coppia ha, il nodo partner deve essere in grado di assumere il nodo associato al modulo NVRAM da sostituire.
-
Questa procedura utilizza la seguente terminologia:
-
Il nodo alterato è il nodo su cui si esegue la manutenzione.
-
Il nodo healthy è il partner ha del nodo compromesso.
-
-
Questa procedura include la procedura per la riassegnazione automatica o manuale dei dischi al modulo controller associato al nuovo modulo NVRAM. È necessario riassegnare i dischi quando richiesto nella procedura. Il completamento della riassegnazione del disco prima del giveback può causare problemi.
-
È necessario sostituire il componente guasto con un componente FRU sostitutivo ricevuto dal provider.
-
Non è possibile modificare dischi o shelf di dischi come parte di questa procedura.
Fase 1: Spegnere il controller compromesso
Arrestare o sostituire il controller compromesso utilizzando una delle seguenti opzioni.
Prendere il controllo e arrestare il controller non funzionante in modo che il controller funzionante continui a fornire dati dalla memoria del controller non funzionante. Per fare questo, si sopprime la creazione automatica dei casi in AutoSupport, si disabilita il giveback automatico e si porta il controller non funzionante al prompt LOADER. Il prompt LOADER è lo stato di arresto sicuro da cui è possibile sostituire la FRU.
-
Se si dispone di un sistema SAN, è necessario aver controllato i messaggi di evento
cluster kernel-service show) per il blade SCSI del controller danneggiato. Ilcluster kernel-service showcomando (dalla modalità avanzata precedente) visualizza il nome del nodo, "stato quorum" di quel nodo, lo stato di disponibilità di quel nodo e lo stato operativo di quel nodo.Ogni processo SCSI-blade deve essere in quorum con gli altri nodi del cluster. Eventuali problemi devono essere risolti prima di procedere con la sostituzione.
-
Se si dispone di un cluster con più di due nodi, questo deve trovarsi in quorum. Se il cluster non è in quorum o un controller integro mostra false per idoneità e salute, è necessario correggere il problema prima di spegnere il controller compromesso; vedere "Sincronizzare un nodo con il cluster".
-
Se AutoSupport è attivato, eliminare la creazione automatica del caso richiamando un messaggio AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hCiò impedisce l'apertura automatica di richieste di assistenza durante la finestra di manutenzione. La durata massima della soppressione è di 72 ore. Se la manutenzione termina prima del termine, è possibile riattivare la creazione di richieste di assistenza richiamando un AutoSupport messaggio con
MAINT=END. Per ulteriori informazioni, consultare "Come disabilitare la creazione automatica di casi durante le finestre di manutenzione programmate".Il seguente messaggio AutoSupport elimina la creazione automatica del caso per due ore:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Disattiva la restituzione automatica:
-
Immettere il seguente comando dalla console del controller funzionante:
storage failover modify -node impaired_node_name -auto-giveback false -
Entra
yquando vedi il messaggio Vuoi disattivare la restituzione automatica?
-
-
Portare la centralina danneggiata al prompt DEL CARICATORE:
Se il controller non utilizzato visualizza… Quindi… Il prompt DEL CARICATORE
Passare alla fase successiva.
In attesa di un giveback…
Premere Ctrl-C, quindi rispondere
yquando richiesto.Prompt di sistema o prompt della password
Assumere il controllo o arrestare il controller compromesso dal controller integro:
storage failover takeover -ofnode impaired_node_name -halt trueIl parametro -halt true consente di visualizzare il prompt di Loader.
Per spegnere il controller compromesso, è necessario determinare lo stato del controller e, se necessario, sostituirlo in modo che il controller integro continui a servire i dati provenienti dallo storage del controller compromesso.
-
Al termine di questa procedura, è necessario lasciare accesi gli alimentatori per alimentare il controller integro.
-
Controllare lo stato MetroCluster per determinare se il controller compromesso è passato automaticamente al controller integro:
metrocluster show -
A seconda che si sia verificato uno switchover automatico, procedere come indicato nella seguente tabella:
Se il controller è compromesso… Quindi… Si è attivata automaticamente
Passare alla fase successiva.
Non si è attivato automaticamente
Eseguire un'operazione di switchover pianificata dal controller integro:
metrocluster switchoverNon è stato attivato automaticamente, si è tentato di eseguire lo switchover con
metrocluster switchovere lo switchover è stato vetoedEsaminare i messaggi di veto e, se possibile, risolvere il problema e riprovare. Se non si riesce a risolvere il problema, contattare il supporto tecnico.
-
Risincronizzare gli aggregati di dati eseguendo
metrocluster heal -phase aggregatesdal cluster esistente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcon il-override-vetoesparametro. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione sia stata completata utilizzando il comando MetroCluster Operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Controllare lo stato degli aggregati utilizzando
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Riparare gli aggregati root utilizzando
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcomando con il parametro -override-vetoes. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione di riparazione sia completa utilizzando
metrocluster operation showsul cluster di destinazione:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Sul modulo controller guasto, scollegare gli alimentatori.
Fase 2: Sostituire il modulo NVRAM
Per sostituire il modulo NVRAM, posizionarlo nello slot 6 dello chassis e seguire la sequenza di passaggi specifica.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Spostare il modulo Flash cache dal vecchio modulo NVRAM al nuovo modulo NVRAM:
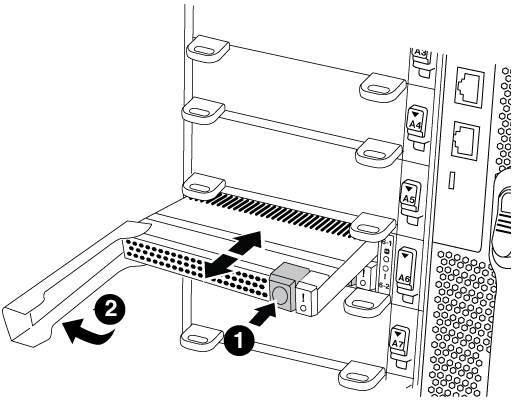

Pulsante di rilascio arancione (grigio sui moduli Flash cache vuoti)

Gestione della camma di Flash cache
-
Premere il pulsante arancione sulla parte anteriore del modulo Flash cache.

Il pulsante di rilascio sui moduli Flash cache vuoti è di colore grigio. -
Ruotare la maniglia della camma verso l'esterno fino a quando il modulo inizia a scorrere fuori dal vecchio modulo NVRAM.
-
Afferrare la maniglia della camma del modulo ed estrarla dal modulo NVRAM e inserirla nella parte anteriore del nuovo modulo NVRAM.
-
Spingere delicatamente il modulo Flash cache fino in fondo nel modulo NVRAM, quindi chiudere la maniglia della camma fino a bloccare il modulo in posizione.
-
-
Rimuovere il modulo NVRAM di destinazione dal telaio:
-
Premere il tasto contrassegnato e numerato CAM.
Il pulsante CAM si allontana dal telaio.
-
Ruotare il fermo della camma verso il basso fino a portarlo in posizione orizzontale.
Il modulo NVRAM si disinnesta dal telaio e si sposta di alcuni centimetri.
-
Rimuovere il modulo NVRAM dallo chassis tirando le linguette di estrazione sui lati del lato anteriore del modulo.
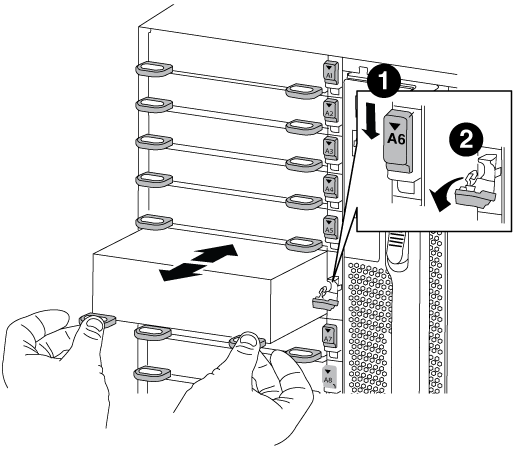
Latch i/o Cam intestato e numerato
Fermo i/o completamente sbloccato
-
-
Posizionare il modulo NVRAM su una superficie stabile e rimuovere il coperchio dal modulo NVRAM premendo verso il basso il pulsante di bloccaggio blu sul coperchio, quindi, tenendo premuto il pulsante blu, estrarre il coperchio dal modulo NVRAM.
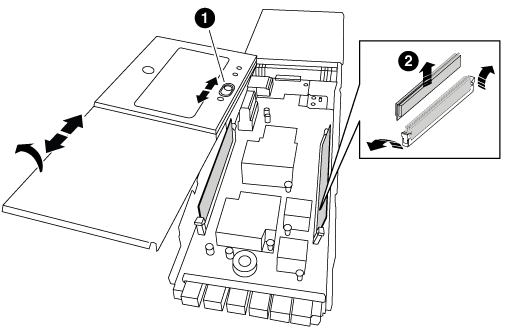
Pulsante di bloccaggio del coperchio
Schede di espulsione DIMM e DIMM
-
Rimuovere i DIMM, uno alla volta, dal vecchio modulo NVRAM e installarli nel modulo NVRAM sostitutivo.
-
Chiudere il coperchio del modulo.
-
Installare il modulo NVRAM sostitutivo nel telaio:
-
Allineare il modulo con i bordi dell'apertura dello chassis nello slot 6.
-
Far scorrere delicatamente il modulo nello slot fino a quando il dispositivo di chiusura della camma i/o con lettere e numeri inizia a innestarsi nel perno della camma i/o, quindi spingere il dispositivo di chiusura della camma i/o fino in fondo per bloccare il modulo in posizione.
-
Fase 3: Sostituire un DIMM NVRAM
Per sostituire i DIMM NVRAM nel modulo NVRAM, rimuovere il modulo NVRAM, aprire il modulo e sostituire il DIMM di destinazione.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Rimuovere il modulo NVRAM di destinazione dal telaio:
-
Premere il tasto contrassegnato e numerato CAM.
Il pulsante CAM si allontana dal telaio.
-
Ruotare il fermo della camma verso il basso fino a portarlo in posizione orizzontale.
Il modulo NVRAM si disinnesta dal telaio e si sposta di alcuni centimetri.
-
Rimuovere il modulo NVRAM dallo chassis tirando le linguette di estrazione sui lati del lato anteriore del modulo.
Latch i/o Cam intestato e numerato
Fermo i/o completamente sbloccato
-
-
Posizionare il modulo NVRAM su una superficie stabile e rimuovere il coperchio dal modulo NVRAM premendo verso il basso il pulsante di bloccaggio blu sul coperchio, quindi, tenendo premuto il pulsante blu, estrarre il coperchio dal modulo NVRAM.
Pulsante di bloccaggio del coperchio
Schede di espulsione DIMM e DIMM
-
Individuare il modulo DIMM da sostituire all'interno del modulo NVRAM, quindi rimuoverlo premendo verso il basso le linguette di bloccaggio del modulo DIMM ed estraendolo dallo zoccolo.
-
Installare il modulo DIMM sostitutivo allineandolo allo zoccolo e spingendolo delicatamente nello zoccolo fino a quando le linguette di bloccaggio non si bloccano in posizione.
-
Chiudere il coperchio del modulo.
-
Installare il modulo NVRAM sostitutivo nel telaio:
-
Allineare il modulo con i bordi dell'apertura dello chassis nello slot 6.
-
Far scorrere delicatamente il modulo nello slot fino a quando il dispositivo di chiusura della camma i/o con lettere e numeri inizia a innestarsi nel perno della camma i/o, quindi spingere il dispositivo di chiusura della camma i/o fino in fondo per bloccare il modulo in posizione.
-
Fase 4: Riavviare il controller dopo la sostituzione della FRU
Dopo aver sostituito la FRU, è necessario riavviare il modulo controller.
-
Per avviare ONTAP dal prompt DEL CARICATORE, immettere
bye.
Fase 5: Riassegnare i dischi
A seconda che si disponga di una coppia ha o di una configurazione MetroCluster a due nodi, è necessario verificare la riassegnazione dei dischi al nuovo modulo controller o riassegnare manualmente i dischi.
Selezionare una delle seguenti opzioni per istruzioni su come riassegnare i dischi al nuovo controller.
È necessario confermare la modifica dell'ID di sistema quando si avvia il nodo replacement e verificare che la modifica sia stata implementata.

|
La riassegnazione del disco è necessaria solo quando si sostituisce il modulo NVRAM e non si applica alla sostituzione del DIMM NVRAM. |
-
Se il nodo sostitutivo è in modalità manutenzione (che mostra il
*>Uscire dalla modalità di manutenzione e passare al prompt DEL CARICATORE:halt -
Dal prompt DEL CARICATORE sul nodo sostitutivo, avviare il nodo, immettendo
ySe viene richiesto di ignorare l'ID di sistema a causa di una mancata corrispondenza dell'ID di sistema.boot_ontap byeIl nodo viene riavviato, se è impostato l'autoboot.
-
Attendere il
Waiting for giveback…Viene visualizzato sulla console del nodo replacement e quindi, dal nodo integro, verificare che il nuovo ID di sistema del partner sia stato assegnato automaticamente:storage failover showNell'output del comando, viene visualizzato un messaggio che indica che l'ID del sistema è stato modificato sul nodo con problemi, mostrando i vecchi e i nuovi ID corretti. Nell'esempio seguente, il node2 è stato sostituito e ha un nuovo ID di sistema pari a 151759706.
node1> `storage failover show` Takeover Node Partner Possible State Description ------------ ------------ -------- ------------------------------------- node1 node2 false System ID changed on partner (Old: 151759755, New: 151759706), In takeover node2 node1 - Waiting for giveback (HA mailboxes) -
Dal nodo integro, verificare che tutti i coredump siano salvati:
-
Passare al livello di privilegio avanzato:
set -privilege advancedPuoi rispondere
Yquando viene richiesto di passare alla modalità avanzata. Viene visualizzato il prompt della modalità avanzata (*>). -
Salva i coredump:
system node run -node local-node-name partner savecore -
Attendere il completamento del comando `savecore`prima di emettere il giveback.
È possibile immettere il seguente comando per monitorare l'avanzamento del comando savecore:
system node run -node local-node-name partner savecore -s -
Tornare al livello di privilegio admin:
set -privilege admin
-
-
Restituire il nodo:
-
Dal nodo integro, restituire lo storage del nodo sostituito:
storage failover giveback -ofnode replacement_node_nameIl nodo replacement riprende lo storage e completa l'avvio.
Se viene richiesto di ignorare l'ID di sistema a causa di una mancata corrispondenza dell'ID di sistema, immettere
y.
Se il giveback viene vetoed, puoi prendere in considerazione la possibilità di ignorare i veti.
-
Una volta completato il giveback, verificare che la coppia ha sia in buone condizioni e che sia possibile effettuare il takeover:
storage failover showL'output di
storage failover showil comando non deve includereSystem ID changed on partnermessaggio.
-
-
Verificare che i dischi siano stati assegnati correttamente:
storage disk show -ownershipI dischi appartenenti al nodo replacement devono mostrare il nuovo ID di sistema. Nell'esempio seguente, i dischi di proprietà di node1 ora mostrano il nuovo ID di sistema, 1873775277:
node1> `storage disk show -ownership` Disk Aggregate Home Owner DR Home Home ID Owner ID DR Home ID Reserver Pool ----- ------ ----- ------ -------- ------- ------- ------- --------- --- 1.0.0 aggr0_1 node1 node1 - 1873775277 1873775277 - 1873775277 Pool0 1.0.1 aggr0_1 node1 node1 1873775277 1873775277 - 1873775277 Pool0 . . .
-
Se il sistema si trova in una configurazione MetroCluster, monitorare lo stato del nodo:
metrocluster node showLa configurazione MetroCluster impiega alcuni minuti dopo la sostituzione per tornare a uno stato normale, in cui ogni nodo mostra uno stato configurato, con mirroring DR abilitato e una modalità normale. Il
metrocluster node show -fields node-systemidL'output del comando visualizza il vecchio ID di sistema fino a quando la configurazione MetroCluster non torna allo stato normale. -
Se il nodo si trova in una configurazione MetroCluster, a seconda dello stato MetroCluster, verificare che il campo DR home ID (ID origine DR) indichi il proprietario originale del disco se il proprietario originale è un nodo del sito di emergenza.
Ciò è necessario se si verificano entrambe le seguenti condizioni:
-
La configurazione MetroCluster è in uno stato di switchover.
-
Il nodo replacement è l'attuale proprietario dei dischi nel sito di disastro.
-
-
Se il sistema si trova in una configurazione MetroCluster, verificare che ciascun nodo sia configurato:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verificare che i volumi previsti siano presenti per ciascun nodo:
vol show -node node-name -
Se al riavvio è stato disattivato il Takeover automatico, attivarlo dal nodo integro:
storage failover modify -node replacement-node-name -onreboot true
In una configurazione MetroCluster a due nodi che esegue ONTAP, è necessario riassegnare manualmente i dischi all'ID di sistema del nuovo controller prima di riportare il sistema alla normale condizione operativa.
Questa procedura si applica solo ai sistemi in una configurazione MetroCluster a due nodi che esegue ONTAP.
Assicurarsi di eseguire i comandi di questa procedura sul nodo corretto:
-
Il nodo alterato è il nodo su cui si esegue la manutenzione.
-
Il nodo replacement è il nuovo nodo che ha sostituito il nodo compromesso come parte di questa procedura.
-
Il nodo healthy è il partner DR del nodo compromesso.
-
Se non lo si è già fatto, riavviare il nodo replacement e interrompere il processo di avvio immettendo
Ctrl-C, Quindi selezionare l'opzione per avviare la modalità di manutenzione dal menu visualizzato.È necessario immettere
YQuando viene richiesto di sostituire l'ID di sistema a causa di una mancata corrispondenza dell'ID di sistema. -
Visualizzare i vecchi ID di sistema dal nodo integro:
`metrocluster node show -fields node-systemid,dr-partner-systemid`In questo esempio, Node_B_1 è il nodo precedente, con il vecchio ID di sistema 118073209:
dr-group-id cluster node node-systemid dr-partner-systemid ----------- --------------------- -------------------- ------------- ------------------- 1 Cluster_A Node_A_1 536872914 118073209 1 Cluster_B Node_B_1 118073209 536872914 2 entries were displayed.
-
Visualizzare il nuovo ID di sistema al prompt della modalità di manutenzione sul nodo non valido:
disk showIn questo esempio, il nuovo ID di sistema è 118065481:
Local System ID: 118065481 ... ... -
Riassegnare la proprietà del disco (per sistemi FAS) utilizzando le informazioni sull'ID di sistema ottenute dal comando disk show:
disk reassign -s old system IDNel caso dell'esempio precedente, il comando è:
disk reassign -s 118073209Puoi rispondere
Yquando viene richiesto di continuare. -
Verificare che i dischi siano stati assegnati correttamente:
disk show -aVerificare che i dischi appartenenti al nodo replacement mostrino il nuovo ID di sistema per il nodo replacement. Nell'esempio seguente, i dischi di proprietà del sistema-1 ora mostrano il nuovo ID di sistema, 118065481:
*> disk show -a Local System ID: 118065481 DISK OWNER POOL SERIAL NUMBER HOME ------- ------------- ----- ------------- ------------- disk_name system-1 (118065481) Pool0 J8Y0TDZC system-1 (118065481) disk_name system-1 (118065481) Pool0 J8Y09DXC system-1 (118065481) . . .
-
Dal nodo integro, verificare che tutti i coredump siano salvati:
-
Passare al livello di privilegio avanzato:
set -privilege advancedPuoi rispondere
Yquando viene richiesto di passare alla modalità avanzata. Viene visualizzato il prompt della modalità avanzata (*>). -
Verificare che i coredump siano salvati:
system node run -node local-node-name partner savecoreSe l'output del comando indica che il salvataggio è in corso, attendere il completamento del salvataggio prima di emettere il giveback. È possibile monitorare l'avanzamento del salvataggio utilizzando
system node run -node local-node-name partner savecore -s command</info>. -
Tornare al livello di privilegio admin:
set -privilege admin
-
-
Se il nodo replacement è in modalità Maintenance (con il prompt *>), uscire dalla modalità Maintenance (manutenzione) e passare al prompt DEL CARICATORE:
halt -
Avviare il nodo replacement:
boot_ontap -
Una volta avviato il nodo replacement, eseguire uno switchback:
metrocluster switchback -
Verificare la configurazione di MetroCluster:
metrocluster node show - fields configuration-statenode1_siteA::> metrocluster node show -fields configuration-state dr-group-id cluster node configuration-state ----------- ---------------------- -------------- ------------------- 1 node1_siteA node1mcc-001 configured 1 node1_siteA node1mcc-002 configured 1 node1_siteB node1mcc-003 configured 1 node1_siteB node1mcc-004 configured 4 entries were displayed.
-
Verificare il funzionamento della configurazione MetroCluster in Data ONTAP:
-
Verificare la presenza di eventuali avvisi sullo stato di salute su entrambi i cluster:
system health alert show -
Verificare che MetroCluster sia configurato e in modalità normale:
metrocluster show -
Eseguire un controllo MetroCluster:
metrocluster check run -
Visualizzare i risultati del controllo MetroCluster:
metrocluster check show -
Eseguire Config Advisor. Accedere alla pagina Config Advisor sul sito del supporto NetApp all'indirizzo "support.netapp.com/NOW/download/tools/config_advisor/".
Dopo aver eseguito Config Advisor, esaminare l'output dello strumento e seguire le raccomandazioni nell'output per risolvere eventuali problemi rilevati.
-
-
Simulare un'operazione di switchover:
-
Dal prompt di qualsiasi nodo, passare al livello di privilegio avanzato:
set -privilege advancedDevi rispondere con
yquando viene richiesto di passare alla modalità avanzata e di visualizzare il prompt della modalità avanzata (*>). -
Eseguire l'operazione di switchback con il parametro -simulate:
metrocluster switchover -simulate -
Tornare al livello di privilegio admin:
set -privilege admin
-
Fase 6: Restituire la parte guasta a NetApp
Restituire la parte guasta a NetApp, come descritto nelle istruzioni RMA fornite con il kit. Vedere la "Restituzione e sostituzione delle parti" pagina per ulteriori informazioni.