

Sostituire un DIMM - FAS9000
 Suggerisci modifiche
Suggerisci modifiche
È necessario sostituire un modulo DIMM nel controller quando il sistema di archiviazione rileva errori quali la presenza di un numero eccessivo di codici di correzione degli errori CECC (Correctable Error Correction Codes) basati su avvisi di Health Monitor o errori ECC non correggibili, in genere causati da un singolo errore del modulo DIMM che impedisce al sistema di archiviazione di avviare ONTAP.
Tutti gli altri componenti del sistema devono funzionare correttamente; in caso contrario, contattare il supporto tecnico.
È necessario sostituire il componente guasto con un componente FRU sostitutivo ricevuto dal provider.
Fase 1: Spegnere il controller compromesso
È possibile arrestare o sostituire il controller compromesso utilizzando procedure diverse, a seconda della configurazione hardware del sistema di storage.
Prendere il controllo e arrestare il controller non funzionante in modo che il controller funzionante continui a fornire dati dalla memoria del controller non funzionante. Per fare questo, si sopprime la creazione automatica dei casi in AutoSupport, si disabilita il giveback automatico e si porta il controller non funzionante al prompt LOADER. Il prompt LOADER è lo stato di arresto sicuro da cui è possibile sostituire la FRU.
-
Se si dispone di un sistema SAN, è necessario aver controllato i messaggi di evento
cluster kernel-service show) per il blade SCSI del controller danneggiato. Ilcluster kernel-service showcomando (dalla modalità avanzata precedente) visualizza il nome del nodo, "stato quorum" di quel nodo, lo stato di disponibilità di quel nodo e lo stato operativo di quel nodo.Ogni processo SCSI-blade deve essere in quorum con gli altri nodi del cluster. Eventuali problemi devono essere risolti prima di procedere con la sostituzione.
-
Se si dispone di un cluster con più di due nodi, questo deve trovarsi in quorum. Se il cluster non è in quorum o un controller integro mostra false per idoneità e salute, è necessario correggere il problema prima di spegnere il controller compromesso; vedere "Sincronizzare un nodo con il cluster".
-
Se AutoSupport è attivato, eliminare la creazione automatica del caso richiamando un messaggio AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hCiò impedisce l'apertura automatica di richieste di assistenza durante la finestra di manutenzione. La durata massima della soppressione è di 72 ore. Se la manutenzione termina prima del termine, è possibile riattivare la creazione di richieste di assistenza richiamando un AutoSupport messaggio con
MAINT=END. Per ulteriori informazioni, consultare "Come disabilitare la creazione automatica di casi durante le finestre di manutenzione programmate".Il seguente messaggio AutoSupport elimina la creazione automatica del caso per due ore:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Disattiva la restituzione automatica:
-
Immettere il seguente comando dalla console del controller funzionante:
storage failover modify -node impaired_node_name -auto-giveback false -
Entra
yquando vedi il messaggio Vuoi disattivare la restituzione automatica?
-
-
Portare la centralina danneggiata al prompt DEL CARICATORE:
Se il controller non utilizzato visualizza… Quindi… Il prompt DEL CARICATORE
Passare alla fase successiva.
In attesa di un giveback…
Premere Ctrl-C, quindi rispondere
yquando richiesto.Prompt di sistema o prompt della password
Assumere il controllo o arrestare il controller compromesso dal controller integro:
storage failover takeover -ofnode impaired_node_name -halt trueIl parametro -halt true consente di visualizzare il prompt di Loader.
Per spegnere il controller compromesso, è necessario determinare lo stato del controller e, se necessario, sostituirlo in modo che il controller integro continui a servire i dati provenienti dallo storage del controller compromesso.
-
Al termine di questa procedura, è necessario lasciare accesi gli alimentatori per alimentare il controller integro.
-
Controllare lo stato MetroCluster per determinare se il controller compromesso è passato automaticamente al controller integro:
metrocluster show -
A seconda che si sia verificato uno switchover automatico, procedere come indicato nella seguente tabella:
Se il controller è compromesso… Quindi… Si è attivata automaticamente
Passare alla fase successiva.
Non si è attivato automaticamente
Eseguire un'operazione di switchover pianificata dal controller integro:
metrocluster switchoverNon è stato attivato automaticamente, si è tentato di eseguire lo switchover con
metrocluster switchovere lo switchover è stato vetoedEsaminare i messaggi di veto e, se possibile, risolvere il problema e riprovare. Se non si riesce a risolvere il problema, contattare il supporto tecnico.
-
Risincronizzare gli aggregati di dati eseguendo
metrocluster heal -phase aggregatesdal cluster esistente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcon il-override-vetoesparametro. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione sia stata completata utilizzando il comando MetroCluster Operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Controllare lo stato degli aggregati utilizzando
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Riparare gli aggregati root utilizzando
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcomando con il parametro -override-vetoes. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione di riparazione sia completa utilizzando
metrocluster operation showsul cluster di destinazione:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Sul modulo controller guasto, scollegare gli alimentatori.
Fase 2: Rimuovere il modulo controller
Per accedere ai componenti all'interno del controller, rimuovere prima il modulo controller dal sistema, quindi rimuovere il coperchio sul modulo controller.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Scollegare i cavi dal modulo controller guasto e tenere traccia del punto in cui sono stati collegati i cavi.
-
Far scorrere il pulsante arancione sulla maniglia della camma verso il basso fino a sbloccarla.
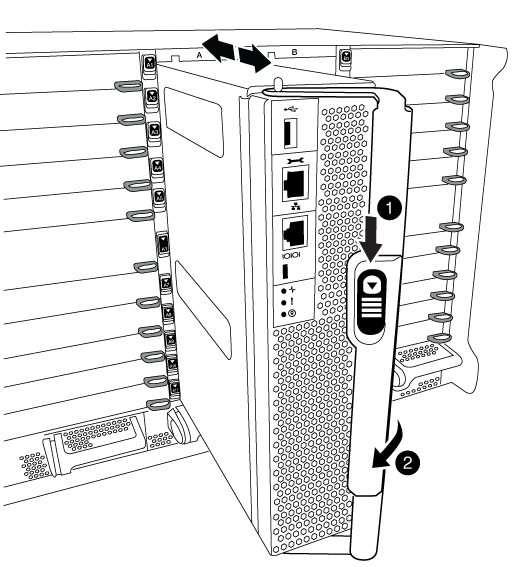

Pulsante di rilascio della maniglia della camma

Maniglia CAM
-
Ruotare la maniglia della camma in modo da disimpegnare completamente il modulo controller dal telaio, quindi estrarre il modulo controller dal telaio.
Assicurarsi di sostenere la parte inferiore del modulo controller mentre lo si sposta fuori dallo chassis.
-
Posizionare il coperchio del modulo controller con il lato rivolto verso l'alto su una superficie stabile e piana, premere il pulsante blu sul coperchio, far scorrere il coperchio sul retro del modulo controller, quindi sollevare il coperchio ed estrarlo dal modulo controller.
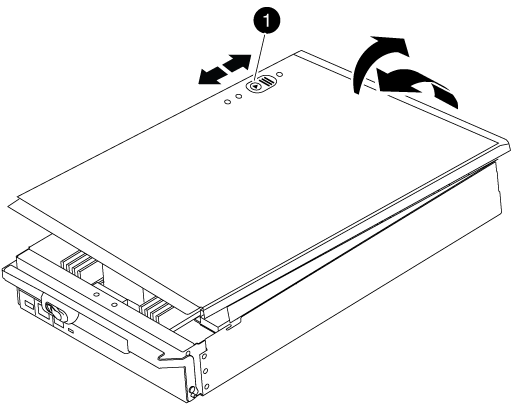
Pulsante di bloccaggio del coperchio del modulo controller
Fase 3: Sostituire i DIMM
Per sostituire i moduli DIMM, individuarli all'interno del controller e seguire la sequenza di passaggi specifica.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Individuare i DIMM sul modulo controller.

-
Estrarre il modulo DIMM dal relativo slot spingendo lentamente verso l'esterno le due linguette di espulsione dei moduli DIMM su entrambi i lati del modulo, quindi estrarre il modulo DIMM dallo slot.

Tenere il modulo DIMM per i bordi in modo da evitare di esercitare pressione sui componenti della scheda a circuiti stampati del modulo DIMM. 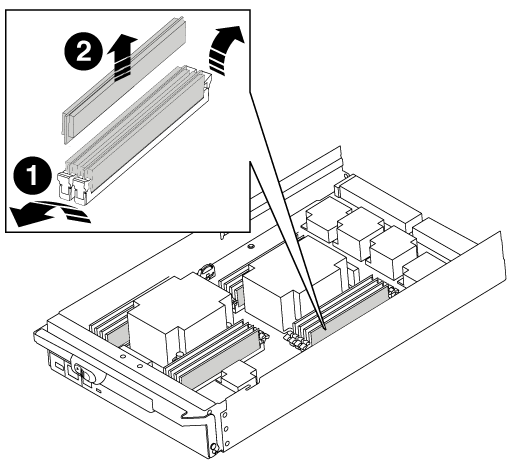
Schede di espulsione DIMM
DIMM
-
Rimuovere il modulo DIMM di ricambio dalla confezione antistatica, tenerlo per gli angoli e allinearlo allo slot.
La tacca tra i pin del DIMM deve allinearsi con la linguetta dello zoccolo.
-
Assicurarsi che le linguette di espulsione del modulo DIMM sul connettore siano aperte, quindi inserire il modulo DIMM correttamente nello slot.
Il DIMM si inserisce saldamente nello slot, ma dovrebbe essere inserito facilmente. In caso contrario, riallineare il DIMM con lo slot e reinserirlo.
Esaminare visivamente il DIMM per verificare che sia allineato in modo uniforme e inserito completamente nello slot. -
Spingere con cautela, ma con decisione, il bordo superiore del DIMM fino a quando le linguette dell'espulsore non scattano in posizione sulle tacche alle estremità del DIMM.
-
Chiudere il coperchio del modulo controller.
Fase 4: Installare il controller
Dopo aver installato i componenti nel modulo controller, è necessario installare nuovamente il modulo controller nel telaio del sistema e avviare il sistema operativo.
Per le coppie ha con due moduli controller nello stesso chassis, la sequenza in cui si installa il modulo controller è particolarmente importante perché tenta di riavviarsi non appena lo si installa completamente nello chassis.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Se non è già stato fatto, riposizionare il coperchio sul modulo controller.
-
Allineare l'estremità del modulo controller con l'apertura dello chassis, quindi spingere delicatamente il modulo controller a metà nel sistema.
Non inserire completamente il modulo controller nel telaio fino a quando non viene richiesto. -
Cablare solo le porte di gestione e console, in modo da poter accedere al sistema per eseguire le attività descritte nelle sezioni seguenti.
I cavi rimanenti verranno collegati al modulo controller più avanti in questa procedura. -
Completare la reinstallazione del modulo controller:
-
Se non è già stato fatto, reinstallare il dispositivo di gestione dei cavi.
-
Spingere con decisione il modulo controller nello chassis fino a quando non raggiunge la scheda intermedia e non è completamente inserito.
I fermi di bloccaggio si sollevano quando il modulo controller è completamente inserito.
Non esercitare una forza eccessiva quando si fa scorrere il modulo controller nel telaio per evitare di danneggiare i connettori.
Il modulo controller inizia ad avviarsi non appena viene inserito completamente nello chassis.
-
Ruotare i fermi di bloccaggio verso l'alto, inclinandoli in modo da liberare i perni di bloccaggio, quindi abbassarli in posizione di blocco.
-
Fase 5: Switch back aggregates in una configurazione MetroCluster a due nodi
Questa attività si applica solo alle configurazioni MetroCluster a due nodi.
-
Verificare che tutti i nodi si trovino in
enabledstato:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Verificare che la risincronizzazione sia completa su tutte le SVM:
metrocluster vserver show -
Verificare che tutte le migrazioni LIF automatiche eseguite dalle operazioni di riparazione siano state completate correttamente:
metrocluster check lif show -
Eseguire lo switchback utilizzando
metrocluster switchbackcomando da qualsiasi nodo del cluster esistente. -
Verificare che l'operazione di switchback sia stata completata:
metrocluster showL'operazione di switchback è ancora in esecuzione quando un cluster si trova in
waiting-for-switchbackstato:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
L'operazione di switchback è completa quando i cluster si trovano in
normalstato:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Se il completamento di uno switchback richiede molto tempo, è possibile verificare lo stato delle linee di base in corso utilizzando
metrocluster config-replication resync-status showcomando. -
Ripristinare le configurazioni SnapMirror o SnapVault.
Fase 6: Restituire la parte guasta a NetApp
Restituire la parte guasta a NetApp, come descritto nelle istruzioni RMA fornite con il kit. Vedere la "Restituzione e sostituzione delle parti" pagina per ulteriori informazioni.