

Sostituire un modulo i/o - FAS9000
 Suggerisci modifiche
Suggerisci modifiche
Per sostituire un modulo i/o, è necessario eseguire una sequenza specifica di attività.
-
È possibile utilizzare questa procedura con tutte le versioni di ONTAP supportate dal sistema
-
Tutti gli altri componenti del sistema devono funzionare correttamente; in caso contrario, contattare il supporto tecnico.
Fase 1: Spegnere il controller compromesso
È possibile arrestare o sostituire il controller compromesso utilizzando procedure diverse, a seconda della configurazione hardware del sistema di storage.
Prendere il controllo e arrestare il controller non funzionante in modo che il controller funzionante continui a fornire dati dalla memoria del controller non funzionante. Per fare questo, si sopprime la creazione automatica dei casi in AutoSupport, si disabilita il giveback automatico e si porta il controller non funzionante al prompt LOADER. Il prompt LOADER è lo stato di arresto sicuro da cui è possibile sostituire la FRU.
-
Se si dispone di un sistema SAN, è necessario aver controllato i messaggi di evento
cluster kernel-service show) per il blade SCSI del controller danneggiato. Ilcluster kernel-service showcomando (dalla modalità avanzata precedente) visualizza il nome del nodo, "stato quorum" di quel nodo, lo stato di disponibilità di quel nodo e lo stato operativo di quel nodo.Ogni processo SCSI-blade deve essere in quorum con gli altri nodi del cluster. Eventuali problemi devono essere risolti prima di procedere con la sostituzione.
-
Se si dispone di un cluster con più di due nodi, questo deve trovarsi in quorum. Se il cluster non è in quorum o un controller integro mostra false per idoneità e salute, è necessario correggere il problema prima di spegnere il controller compromesso; vedere "Sincronizzare un nodo con il cluster".
-
Se AutoSupport è attivato, eliminare la creazione automatica del caso richiamando un messaggio AutoSupport:
system node autosupport invoke -node * -type all -message MAINT=<number of hours down>hCiò impedisce l'apertura automatica di richieste di assistenza durante la finestra di manutenzione. La durata massima della soppressione è di 72 ore. Se la manutenzione termina prima del termine, è possibile riattivare la creazione di richieste di assistenza richiamando un AutoSupport messaggio con
MAINT=END. Per ulteriori informazioni, consultare "Come disabilitare la creazione automatica di casi durante le finestre di manutenzione programmate".Il seguente messaggio AutoSupport elimina la creazione automatica del caso per due ore:
cluster1:> system node autosupport invoke -node * -type all -message MAINT=2h -
Disattiva la restituzione automatica:
-
Immettere il seguente comando dalla console del controller funzionante:
storage failover modify -node impaired_node_name -auto-giveback false -
Entra
yquando vedi il messaggio Vuoi disattivare la restituzione automatica?
-
-
Portare la centralina danneggiata al prompt DEL CARICATORE:
Se il controller non utilizzato visualizza… Quindi… Il prompt DEL CARICATORE
Passare alla fase successiva.
In attesa di un giveback…
Premere Ctrl-C, quindi rispondere
yquando richiesto.Prompt di sistema o prompt della password
Assumere il controllo o arrestare il controller compromesso dal controller integro:
storage failover takeover -ofnode impaired_node_name -halt trueIl parametro -halt true consente di visualizzare il prompt di Loader.
Per spegnere il controller compromesso, è necessario determinare lo stato del controller e, se necessario, sostituirlo in modo che il controller integro continui a servire i dati provenienti dallo storage del controller compromesso.
-
Al termine di questa procedura, è necessario lasciare accesi gli alimentatori per alimentare il controller integro.
-
Controllare lo stato MetroCluster per determinare se il controller compromesso è passato automaticamente al controller integro:
metrocluster show -
A seconda che si sia verificato uno switchover automatico, procedere come indicato nella seguente tabella:
Se il controller è compromesso… Quindi… Si è attivata automaticamente
Passare alla fase successiva.
Non si è attivato automaticamente
Eseguire un'operazione di switchover pianificata dal controller integro:
metrocluster switchoverNon è stato attivato automaticamente, si è tentato di eseguire lo switchover con
metrocluster switchovere lo switchover è stato vetoedEsaminare i messaggi di veto e, se possibile, risolvere il problema e riprovare. Se non si riesce a risolvere il problema, contattare il supporto tecnico.
-
Risincronizzare gli aggregati di dati eseguendo
metrocluster heal -phase aggregatesdal cluster esistente.controller_A_1::> metrocluster heal -phase aggregates [Job 130] Job succeeded: Heal Aggregates is successful.
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcon il-override-vetoesparametro. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione sia stata completata utilizzando il comando MetroCluster Operation show.
controller_A_1::> metrocluster operation show Operation: heal-aggregates State: successful Start Time: 7/25/2016 18:45:55 End Time: 7/25/2016 18:45:56 Errors: - -
Controllare lo stato degli aggregati utilizzando
storage aggregate showcomando.controller_A_1::> storage aggregate show Aggregate Size Available Used% State #Vols Nodes RAID Status --------- -------- --------- ----- ------- ------ ---------------- ------------ ... aggr_b2 227.1GB 227.1GB 0% online 0 mcc1-a2 raid_dp, mirrored, normal...
-
Riparare gli aggregati root utilizzando
metrocluster heal -phase root-aggregatescomando.mcc1A::> metrocluster heal -phase root-aggregates [Job 137] Job succeeded: Heal Root Aggregates is successful
Se la riparazione è vetoed, si ha la possibilità di riemettere il
metrocluster healcomando con il parametro -override-vetoes. Se si utilizza questo parametro opzionale, il sistema sovrascrive qualsiasi veto soft che impedisca l'operazione di riparazione. -
Verificare che l'operazione di riparazione sia completa utilizzando
metrocluster operation showsul cluster di destinazione:mcc1A::> metrocluster operation show Operation: heal-root-aggregates State: successful Start Time: 7/29/2016 20:54:41 End Time: 7/29/2016 20:54:42 Errors: - -
Sul modulo controller guasto, scollegare gli alimentatori.
Fase 2: Sostituire i moduli i/O.
Per sostituire un modulo i/o, individuarlo all'interno dello chassis e seguire la sequenza specifica dei passaggi.
-
Se non si è già collegati a terra, mettere a terra l'utente.
-
Scollegare i cavi associati al modulo i/o di destinazione.
Assicurarsi di etichettare i cavi in modo da conoscerne la provenienza.
-
Rimuovere il modulo i/o di destinazione dallo chassis:
-
Premere il tasto contrassegnato e numerato CAM.
Il pulsante CAM si allontana dal telaio.
-
Ruotare il fermo della camma verso il basso fino a portarlo in posizione orizzontale.
Il modulo i/o si disinnesta dallo chassis e si sposta di circa 1/2 pollici fuori dallo slot i/O.
-
Rimuovere il modulo i/o dallo chassis tirando le linguette sui lati del lato anteriore del modulo.
Assicurarsi di tenere traccia dello slot in cui si trovava il modulo i/O.
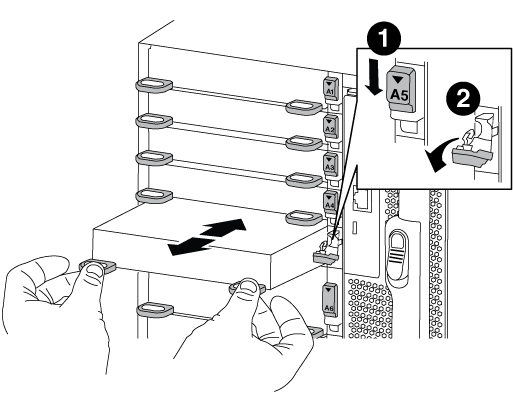

Latch i/o Cam intestato e numerato

Fermo i/o Cam completamente sbloccato
-
-
Mettere da parte il modulo i/O.
-
Installare il modulo i/o sostitutivo nello chassis facendo scorrere delicatamente il modulo i/o nello slot fino a quando il fermo della camma i/o con lettere e numeri inizia a innestarsi nel perno della camma i/o, quindi spingere il fermo della camma i/o completamente verso l'alto per bloccare il modulo in posizione.
-
Ricable il modulo i/o, secondo necessità.
Fase 3: Riavviare il controller dopo la sostituzione del modulo i/O.
Dopo aver sostituito un modulo i/o, è necessario riavviare il modulo controller.

|
Se il nuovo modulo i/o non è lo stesso modello del modulo guasto, è necessario prima riavviare il BMC. |
-
Riavviare il BMC se il modulo sostitutivo non è lo stesso modello del modulo precedente:
-
Dal prompt DEL CARICATORE, passare alla modalità avanzata dei privilegi:
priv set advanced -
Riavviare BMC:
sp reboot
-
-
Dal prompt DEL CARICATORE, riavviare il nodo:
bye
In questo modo, le schede PCIe e gli altri componenti vengono reinizializzati e il nodo viene riavviato. -
Se il sistema è configurato per supportare connessioni dati e di interconnessione cluster a 10 GbE su schede di rete 40 GbE o porte integrate, convertire queste porte in connessioni a 10 GbE utilizzando
nicadmin convertComando dalla modalità di manutenzione.
Assicurarsi di uscire dalla modalità di manutenzione dopo aver completato la conversione. -
Ripristinare il funzionamento normale del nodo:
storage failover giveback -ofnode impaired_node_name -
Se il giveback automatico è stato disattivato, riabilitarlo:
storage failover modify -node local -auto-giveback true
Se il sistema si trova in una configurazione MetroCluster a due nodi, è necessario ripristinare gli aggregati come descritto nella fase successiva.
Fase 4: Switch back aggregates in una configurazione MetroCluster a due nodi
Questa attività si applica solo alle configurazioni MetroCluster a due nodi.
-
Verificare che tutti i nodi si trovino in
enabledstato:metrocluster node showcluster_B::> metrocluster node show DR Configuration DR Group Cluster Node State Mirroring Mode ----- ------- -------------- -------------- --------- -------------------- 1 cluster_A controller_A_1 configured enabled heal roots completed cluster_B controller_B_1 configured enabled waiting for switchback recovery 2 entries were displayed. -
Verificare che la risincronizzazione sia completa su tutte le SVM:
metrocluster vserver show -
Verificare che tutte le migrazioni LIF automatiche eseguite dalle operazioni di riparazione siano state completate correttamente:
metrocluster check lif show -
Eseguire lo switchback utilizzando
metrocluster switchbackcomando da qualsiasi nodo del cluster esistente. -
Verificare che l'operazione di switchback sia stata completata:
metrocluster showL'operazione di switchback è ancora in esecuzione quando un cluster si trova in
waiting-for-switchbackstato:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured switchover Remote: cluster_A configured waiting-for-switchback
L'operazione di switchback è completa quando i cluster si trovano in
normalstato:cluster_B::> metrocluster show Cluster Configuration State Mode -------------------- ------------------- --------- Local: cluster_B configured normal Remote: cluster_A configured normal
Se il completamento di uno switchback richiede molto tempo, è possibile verificare lo stato delle linee di base in corso utilizzando
metrocluster config-replication resync-status showcomando. -
Ripristinare le configurazioni SnapMirror o SnapVault.
Fase 5: Restituire il componente guasto a NetApp
Restituire la parte guasta a NetApp, come descritto nelle istruzioni RMA fornite con il kit. Vedere la "Restituzione e sostituzione delle parti" pagina per ulteriori informazioni.