

Prestazioni
 Suggerisci modifiche
Suggerisci modifiche
NetApp AFX è stato progettato pensando alle performance e alla scalabilità, in particolare per carichi di lavoro che richiedono un'elevata throughput in lettura e scrittura e che possono fornire una scalabilità semplice e lineare.
Prestazioni per nodo
Ciascun nodo di storage NetApp AFX fornisce una specifica quantità di throughput per le operazioni di lettura e scrittura. Con l'aggiunta di nodi al cluster, le prestazioni aumentano linearmente, come descritto nella sezione "Scalabilità lineare delle prestazioni dei nodi" di questo documento.
Attualmente, i tipi di nodo sono "AFX 1K" e forniscono throughput per letture e scritture approssimativamente pari ai valori riportati di seguito. Con la disponibilità di hardware più recente per NetApp AFX, questi limiti potrebbero cambiare. NOTA: Le prestazioni massime sono state raggiunte utilizzando più client che leggono e scrivono più file, come mostrato nella sezione "Risultati del benchmark" di seguito.
Stime delle prestazioni per nodo
| Tipo di nodo | Prestazioni di lettura massime | Prestazioni di scrittura massime |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
Per le stime di performance più aggiornate, contatta il tuo team di vendita NetApp. |
prestazioni per shelf
Ogni shelf contiene moduli shelf ad alte prestazioni con 16 porte Ethernet da 100 GB che sfruttano la comunicazione RoCEv2 per un'interazione di archiviazione ad alta larghezza di banda con i nodi di calcolo nel cluster. Come qualsiasi risorsa fisica, questi shelf hanno dei limiti massimi raggiungibili, soprattutto perché NetApp AFX può presentare più nodi che puntano allo stesso set di dischi. La tabella seguente mostra le prestazioni massime stimate in lettura e scrittura per un singolo shelf per le unità TLC e QLC. Per ulteriori informazioni sulle differenze tra TLC e QLC, vedere "TLC vs. QLC".
Stime delle prestazioni per shelf
| Tipo di modulo a scaffale | Prestazioni di lettura massime | Prestazioni di scrittura massime |
|---|---|---|
NSM 140 |
140GB/s (TLC e QLC) |
70GB/s TLC 35GB/s QLC |
|
|
Per le stime di performance più aggiornate, contatta il tuo team di vendita NetApp. |
densità delle performance
Nell'architettura ONTAP disaggregata, il disaccoppiamento dei nodi di storage dagli shelf consente a un maggior numero di nodi di indirizzare il traffico verso un numero inferiore di shelf, contribuendo così a ridurre l'ingombro complessivo del data center necessario per ottenere le massime performance con la sola capacità di cui hai bisogno.
Questo concetto di "densità delle prestazioni" consente agli amministratori dello storage di ottenere il massimo dall'hardware a loro disposizione senza mai dover effettuare un provisioning in eccesso del proprio ambiente di storage.
Ad esempio, in un cluster ONTAP unificato, poiché ogni nodo possiede un proprio set di dischi, le performance sono indirizzate solo ai dischi di proprietà del nodo e, poiché solo un nodo può accedere a un set di dischi, non è detto che possa saturare i dischi disponibili e raggiungere le sue massime performance.
Unified ONTAP – come vengono suddivise le prestazioni
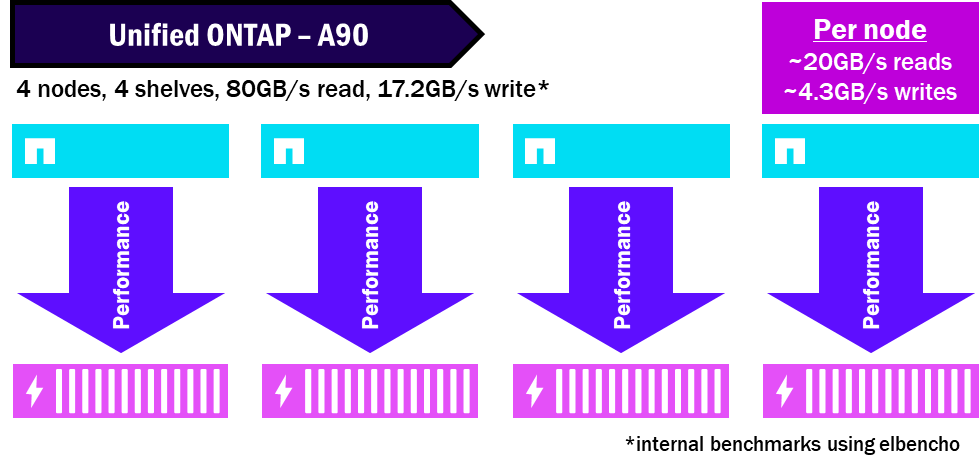
NetApp AFX raggruppa tutti i dischi in un'unica Storage Availability Zone, consentendo a tutti i nodi di sfruttare tutti i dischi. E poiché i dischi e i nodi sono disaccoppiati, non saranno necessari tanti shelf per ottenere le stesse performance. Questo concentra le performance e massimizza il potenziale massimo di performance dello shelf.
NetApp AFX – densità delle prestazioni
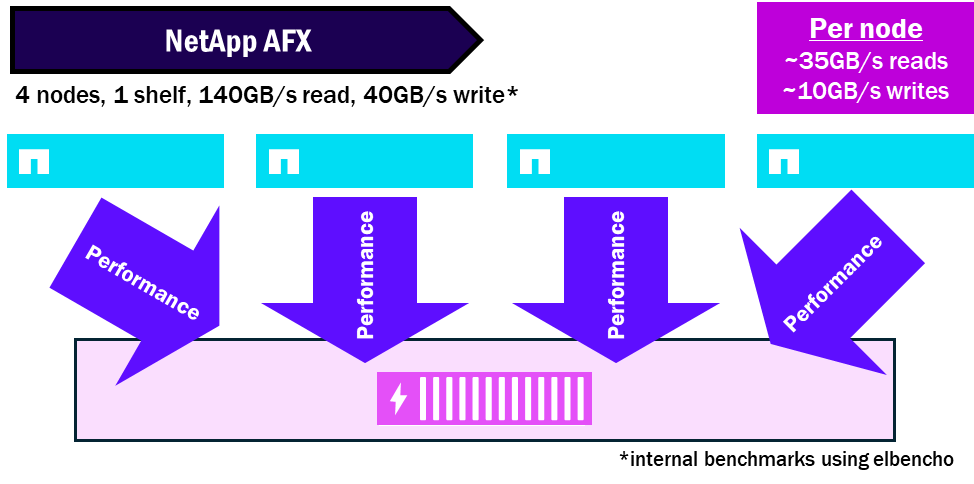
Rapporto nodo-scaffale
I nodi ONTAP unificati richiedono almeno un set di dischi per nodo e possono avere più unità di archiviazione collegate a un singolo nodo. Di conseguenza, possono verificarsi colli di bottiglia prestazionali nel singolo nodo che potrebbe non essere in grado di saturare i propri dischi.
NetApp AFX mette a disposizione di tutti i nodi tutti gli alloggiamenti per dischi. Ogni alloggiamento contiene moduli con 16 x 100GB interfacce compatibili RoCE per aumentare la quantità totale di performance consentita per alloggiamento. Grazie a ciò, è possibile saturare un singolo alloggiamento con più nodi che leggeranno e scriveranno sullo stesso set di dischi.
A partire da ONTAP 9.19.1, il rapporto di saturazione node:shelf è di circa 4:1.
Risultati del benchmark
La sezione seguente illustra i risultati dei benchmark ottenuti utilizzando un cluster NetApp AFX con i seguenti parametri di configurazione.
-
4 nodi, 4 interfacce dati
-
2 ripiani (unità da 7,6TB)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, trunking di sessione)
-
Volume FlexGroup
-
"ElBencho" benchmark
-
Scritture: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Letture: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 server Cisco C240 M8, 2 porte * schede CX-7 da 200GbE, 80 thread
-
Opzioni di montaggio NFS: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
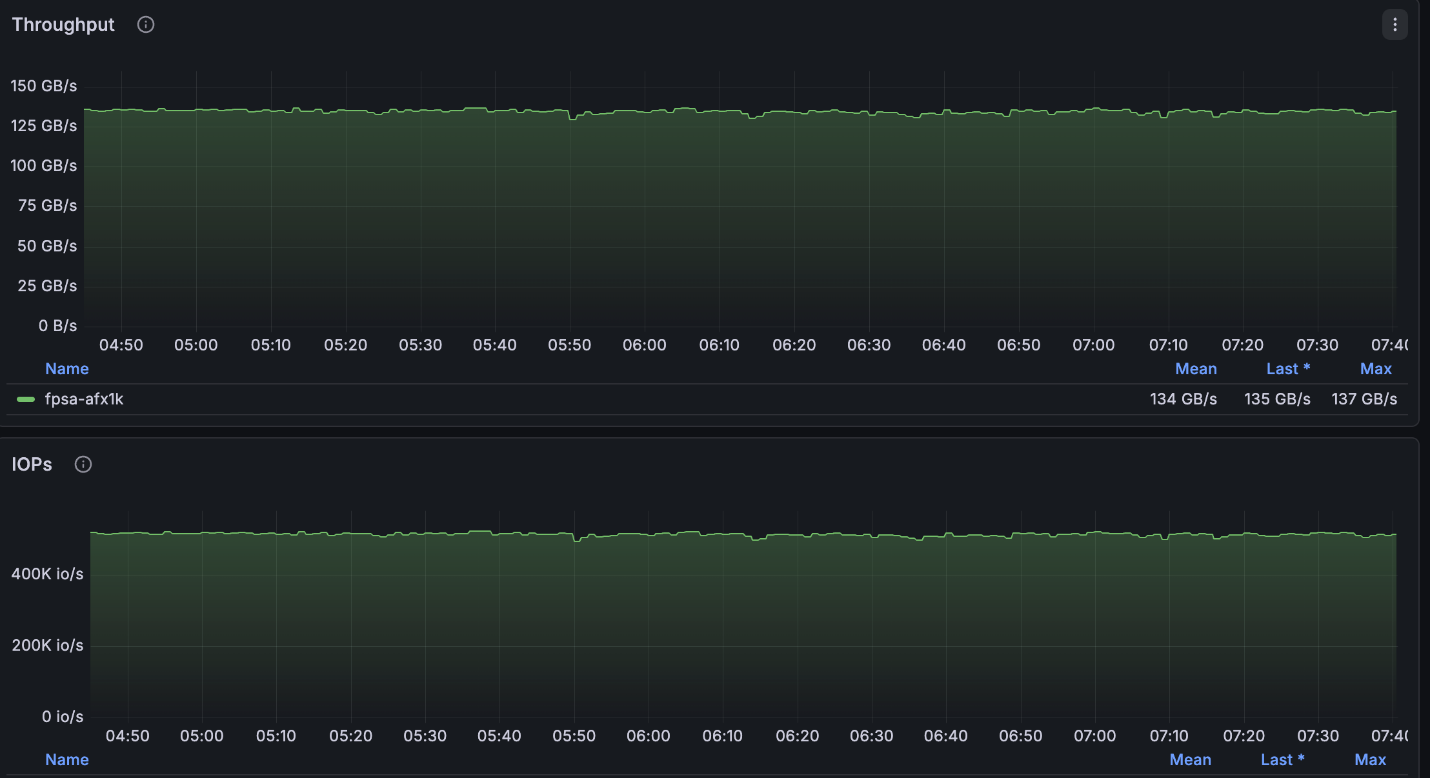
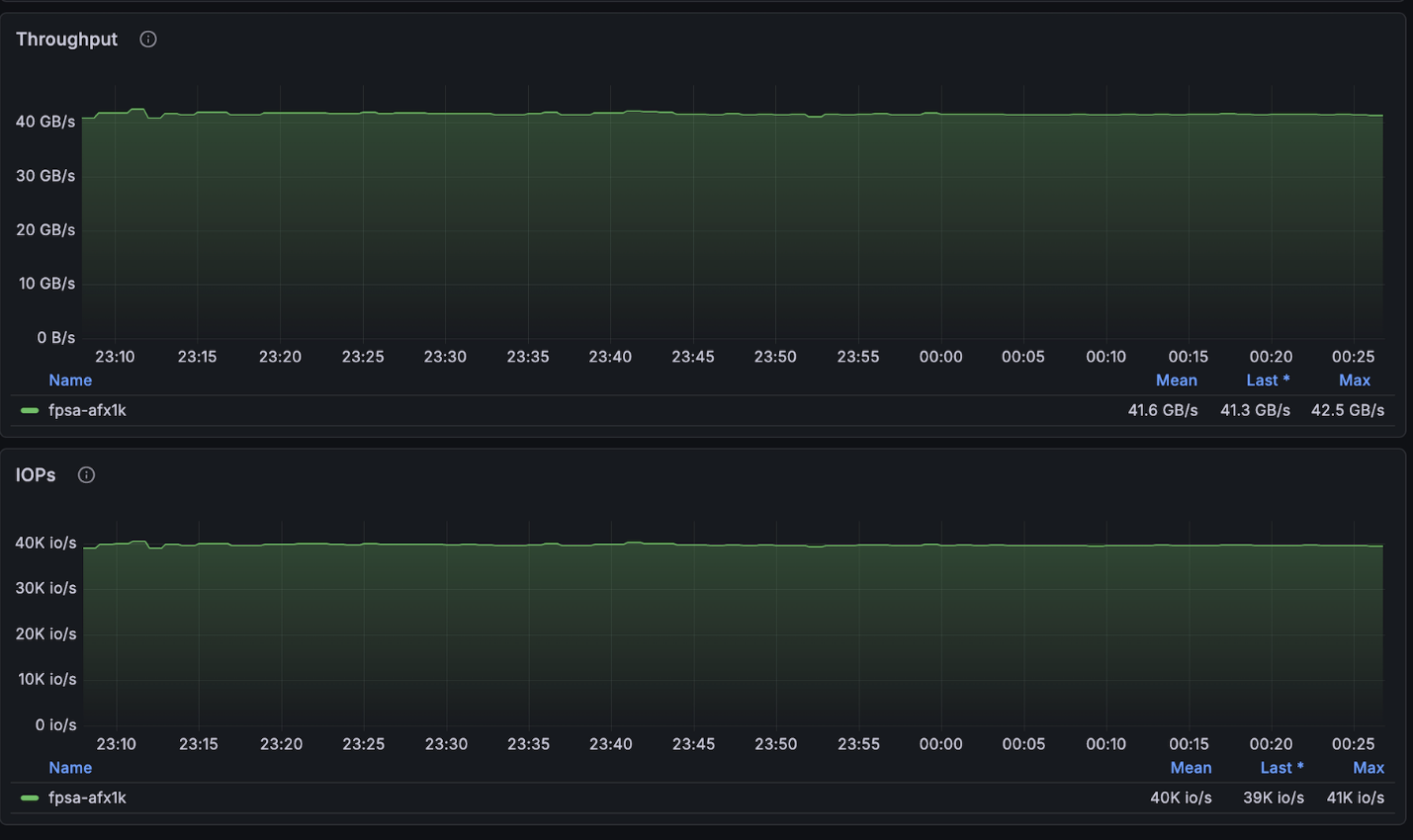
La configurazione sopra descritta ha raggiunto velocità di lettura molto vicine al massimo consentito per il cluster a 4 nodi (~134GB/s) ed era esattamente al massimo delle scritture consentite per nodo (40GB/s).
NetApp AFX – ElBencho prestazioni di lettura, 4 nodi
NetApp AFX – ElBencho prestazioni di scrittura, 4 nodi
Lettura anticipata aggressiva
Nei carichi di lavoro di streaming multimediale, un film in 4K viene spesso suddiviso in decine di migliaia di file, ciascuno di dimensioni tipiche comprese tra 50 MB e 250 MB. Ogni file rappresenta un fotogramma e l'applicazione legge un fotogramma intero in una singola richiesta. Per mantenere uno streaming fluido e ininterrotto, senza buffering visibile, la lettura di questi fotogrammi deve completarsi senza perdite.
ONTAP offre un'opzione a livello di volume (-aggressive-readahead-mode per ottimizzare questi carichi di lavoro. A partire da ONTAP 9.19.1, è stata introdotta una nuova cross_file_sequential_read modalità di prelettura aggressiva su AFX per accelerare i carichi di lavoro con modelli di I/O prevedibili su tipi di file simili (ad esempio, rendering e streaming multimediale).
La funzione cross_file_sequential_read prevede il prossimo file da leggere in base al suo nome e avvia la prelettura su tali file prima che il client emetta la chiamata di lettura. La logica di predizione presuppone che tutti i file in una directory seguano uno schema di denominazione con un suffisso numerico che aumenta monotonicamente (ad esempio, file1, file2, file3). Tutti i file nella directory devono seguire questo schema, utilizzando la numerazione decimale o esadecimale. I nomi dei file possono essere lunghi fino a 255 caratteri. La logica è indipendente dall'estensione e genera il successivo set di nomi di file nella attuale directory basandosi esclusivamente sul nome del file corrente. Se un nome di file generato in precedenza utilizzando la numerazione in base 10 non esiste nella directory, i nomi vengono rigenerati utilizzando la numerazione esadecimale. Se nessuno dei nomi di file generati esiste, non viene eseguita alcuna prelettura per quel set. La prelettura riprende quando viene emessa la successiva chiamata di lettura del client.
Con queste opzioni abilitate, "test del frame" i benchmark delle performance sono stati in grado di leggere 30.000 fotogrammi 4K a 30 fotogrammi al secondo con 30 client (NFSv3 e SMB3) e 34 client (NFSv4.1), senza perdere un singolo fotogramma.
Sebbene la lettura sequenziale tra file sia progettata principalmente per carichi di lavoro multimediali, anche altri carichi di lavoro ad alta intensità di lettura con modelli di accesso e nomi di file prevedibili, come l'addestramento e l'inferenza dell'AI, possono trarne vantaggio.
Considerazioni e avvertenze
-
Cache buffer condivisa – la lettura anticipata aggressiva utilizza la stessa cache buffer degli altri volumi sul nodo. L'abilitazione di questa funzione potrebbe influire sulle performance di lettura degli altri volumi su quel nodo.
-
Performance dello storage – se i file non possono essere letti abbastanza velocemente (ad esempio, sui sistemi FAS basati su HDD), i dati memorizzati nella cache potrebbero essere eliminati prima che la lettura da parte del client avvenga, annullando i vantaggi della prelettura.
-
Requisiti del modello di accesso – se il modello di lettura del carico di lavoro non è sequenziale o se i file in una directory non sono denominati in ordine sequenziale crescente, la modalità di prelettura aggressiva cross_file_sequential_read non fornirà vantaggi significativi.
Miglioramenti delle performance di NFSv4.x
NFS versione 3 è stata un punto di riferimento per le applicazioni NFS per decenni, fin dal 1995, anno della sua prima pubblicazione ufficiale. La sua combinazione di prestazioni e resilienza ha reso difficile considerare un passaggio a versioni più recenti di NFS, e a ragione.
Tuttavia, NFSv3 non è esente da limitazioni. L'assenza di stato del protocollo, pur essendo ottima per le performance e per ridurre al minimo le interruzioni in caso di failover dello storage, non è altrettanto efficace per la coerenza dei dati e la gestione dei lock. Un server NFS non tiene realmente traccia dello stato dei lock, quindi in caso di errore, il server NFS potrebbe rilasciare o meno i lock, e il client NFS potrebbe non sapere se un file è bloccato o meno.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). Nonostante NFSv4.x esista da oltre 20 anni, non c'è ancora stata un'adozione su larga scala per diversi motivi.
-
Complessità della gestione delle identità: molti ambienti non dispongono di una name service infrastructure per sfruttare appieno i requisiti di sicurezza relativi alle stringhe di nome e a Kerberos in NFSv4.x.
-
Necessità di client NFS più recenti: questa preoccupazione è meno pressante negli ambienti NFS moderni, man mano che ci allontaniamo dalla data di rilascio iniziale di NFSv4. Quasi tutti i sistemi operativi attualmente in uso includono client NFS con supporto completo per NFSv4, ma esistono ancora sistemi legacy che potrebbero non disporre dei pacchetti NFSv4.x necessari. Infatti, alcune applicazioni richiedono ancora l'utilizzo di versioni precedenti di NFS.
-
Mentalità del tipo "Se funziona, non toccarlo": le organizzazioni IT aziendali sono notoriamente conservative nell'adozione di nuove tecnologie, anche di quelle che esistono da oltre 20 anni. E se la versione attuale di NFS funziona bene, perché cambiarla?
-
Problemi di prestazioni: le prestazioni di un protocollo stateful come NFSv4.x sono rimaste indietro rispetto a quelle di NFSv3, che è stateless, per gran parte degli ultimi 20 anni. In passato, l'impatto sulle prestazioni ha spesso superato i vantaggi di NFSv4.x.
Miglioramenti a NFSv4.x in ONTAP 9.18.1 utilizzando AFX
Alcune modifiche architetturali apportate a ONTAP hanno fornito un notevole incremento di prestazioni a NFS in generale e hanno compiuto seri progressi nel miglioramento delle prestazioni di NFSv4.x in generale.
Di seguito è riportata una high-level sintesi di alcune di queste modifiche.
Miglioramento della lettura sequenziale: NFSv4.1 30% migliore di NFSv3
ONTAP 9.18.1 introduce il supporto per l'I/O multipath con NFSv4.1. Anziché elaborare le letture dal file system WAFL, MPIO sposta le operazioni di lettura in un dominio di rete per essere gestite in modo sicuro per il multipath. Questo approccio riduce i cambi di contesto, garantendo un maggiore parallelismo complessivo nel traffico di lettura sequenziale, oltre a ridurre l'overhead derivante dalla gestione del buffer bypassando WAFL.
Miglioramento della lettura casuale per i volumi FlexGroup: NFSv4.1 entro il 7% di NFSv3
I volumi FlexGroup sono volumi che includono molti volumi costituenti sottostanti e li presentano come un unico namespace unificato. In AFX, i volumi FlexGroup hanno il Bilanciamento Avanzato della Capacità abilitato per impostazione predefinita, che scrive i file di dimensioni superiori a 10GB su più volumi costituenti come file multipart. A causa della posizione remota di queste parti di file, le letture casuali hanno tradizionalmente subito un lieve svantaggio in termini di prestazioni con NFSv4.x (circa il 18% in meno rispetto a NFSv3). ONTAP 9.18.1 introduce il supporto per l'IO memorizzato nella cache per le letture multipart con NFSv4.x per contribuire a risolvere questo problema. NOTA: questa modifica non si applica ai volumi FlexVol.
Scritture sequenziali: +10% di miglioramento rispetto alle versioni precedenti
Un miglioramento nella modalità di replica dei dati NVLOG utilizzati per la funzionalità di failover HA ha incrementato le prestazioni complessive di scrittura sequenziale per i sistemi NetApp AFX.
Operazioni sui metadati: prestazioni entro il 15% rispetto a NFSv3 per i benchmark EDA
NFSv4.1 serializza tradizionalmente tutte le operazioni di OPEN e CLOSE, con un nodo del cluster che le elabora una alla volta prima di poterle inviare dalla rete a WAFL. ONTAP 9.18.1 introduce Concurrent Open Close (COC), che elimina la serializzazione di rete modificando il modo in cui vengono risolte le race condition, eliminando così i colli di bottiglia OPEN/CLOSE riscontrati nelle versioni precedenti.
Tutte queste modifiche, insieme ai cambiamenti architetturali introdotti in AFX, hanno permesso di migliorare le prestazioni complessive di NFSv4.1 in ONTAP 9.18.1.
Risultati I/O sequenziali
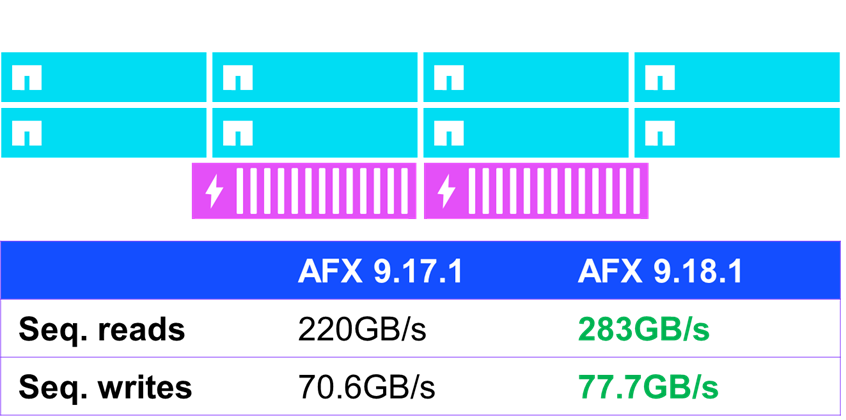
Una delle aree in cui si sono registrati modesti miglioramenti delle prestazioni è stata quella relativa all'I/O sequenziale (ovvero, I/O prevedibile ed eseguito consecutivamente). Nei test di prestazioni standard con fio, AFX con ONTAP 9.18.1 ha migliorato le prestazioni di lettura sequenziale di quasi il 30% e le prestazioni di scrittura sequenziale del 10%.
NetApp AFX – prestazioni IO sequenziali NFSv4.1 in ONTAP 9.18.1
Risultati di un carico di lavoro ricco di metadati
Ancora più impressionanti sono i miglioramenti in uno dei principali punti critici per le prestazioni di NFSv4.x – metadati. Si tratta di IO casuali, solitamente nell'ordine dei 4K, utilizzati per gestire i proprietari e gli attributi dei file, creare ed elencare i file e così via. A causa della gestione dello stato di NFSv4.x, questo tipo di operazioni tende a richiedere un maggiore utilizzo della CPU e latenza, riducendo di conseguenza le prestazioni complessive possibili.
Grazie alle modifiche introdotte in AFX ONTAP 9.18.1, le prestazioni di NFSv4.x per queste tipologie di carichi di lavoro sono migliorate in modo sostanziale e hanno ridotto il divario con le prestazioni di NFSv3 (entro il 15%).
I nostri team di ingegneria delle prestazioni hanno confrontato le prestazioni dei benchmark standard per immagini AI, EDA e compilazione software, riscontrando notevoli miglioramenti rispetto alla precedente release di ONTAP.
NetApp AFX – Prestazioni IO dei metadati NFSv4.1 in ONTAP 9.18.1
