

Risolvere i problemi relativi ai metadati
 Suggerisci modifiche
Suggerisci modifiche
È possibile eseguire diverse attività per determinare l'origine dei problemi relativi ai metadati.
Avviso di spazio di archiviazione dei metadati insufficiente
Se viene attivato l'avviso Low metadata storage, è necessario aggiungere nuovi nodi di storage.
-
Hai effettuato l'accesso a Grid Manager utilizzando un "browser web supportato".
StorageGRID riserva una certa quantità di spazio sul volume 0 di ciascun nodo di storage per i metadati dell'oggetto. Questo spazio è noto come spazio riservato effettivo e viene suddiviso nello spazio consentito per i metadati dell'oggetto (lo spazio consentito per i metadati) e nello spazio richiesto per le operazioni essenziali del database, come la compattazione e la riparazione. Lo spazio consentito per i metadati regola la capacità complessiva degli oggetti.
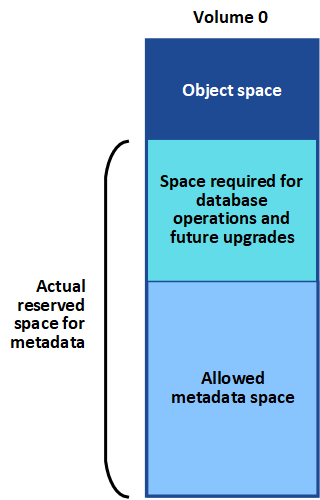
Se i metadati degli oggetti consumano più del 100% dello spazio consentito per i metadati, le operazioni del database non possono essere eseguite in modo efficiente e si verificano errori.
È possibile "Monitorare la capacità dei metadati degli oggetti per ciascun nodo di storage" per aiutarti a prevenire gli errori e correggerli prima che si verifichino.
StorageGRID utilizza la seguente metrica Prometheus per misurare la quantità di spazio consentito per i metadati:
storagegrid_storage_utilization_metadata_bytes/storagegrid_storage_utilization_metadata_allowed_bytes
Quando l'espressione Prometheus raggiunge determinate soglie, viene attivato l'avviso Low metadata storage.
-
Minore: I metadati degli oggetti utilizzano almeno il 70% dello spazio consentito per i metadati. È necessario aggiungere nuovi nodi di storage il prima possibile.
-
Major: I metadati degli oggetti utilizzano almeno il 90% dello spazio consentito per i metadati. È necessario aggiungere immediatamente nuovi nodi di storage.

Quando i metadati dell'oggetto utilizzano almeno il 90% dello spazio consentito per i metadati, viene visualizzato un avviso sul dashboard. Se viene visualizzato questo avviso, è necessario aggiungere immediatamente nuovi nodi di storage. Non è mai necessario consentire ai metadati degli oggetti di utilizzare più del 100% dello spazio consentito. -
Critico: I metadati degli oggetti utilizzano almeno il 100% dello spazio consentito e stanno iniziando a consumare lo spazio necessario per le operazioni essenziali del database. È necessario interrompere l'acquisizione di nuovi oggetti e aggiungere immediatamente nuovi nodi di storage.
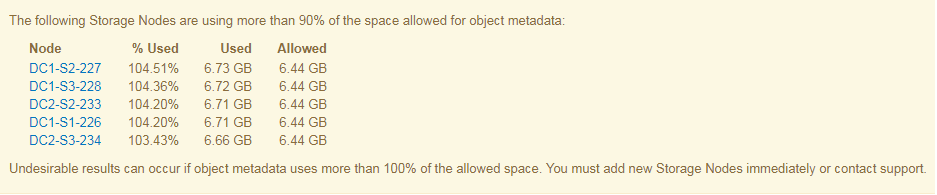
Nell'esempio seguente, i metadati degli oggetti utilizzano oltre il 100% dello spazio consentito per i metadati. Si tratta di una situazione critica, che può causare errori e operazioni inefficienti del database.
|
|
Se la dimensione del volume 0 è inferiore all'opzione di storage Metadata Reserved Space (ad esempio, in un ambiente non in produzione), il calcolo dell'avviso Low metadata storage potrebbe essere impreciso. |
-
Selezionare ALERTS > current.
-
Dalla tabella degli avvisi, espandere il gruppo di avvisi Low metadata storage, se necessario, e selezionare l'avviso specifico che si desidera visualizzare.
-
Esaminare i dettagli nella finestra di dialogo degli avvisi.
-
Se è stato attivato un avviso importante o critico Low metadata storage, eseguire un'espansione per aggiungere immediatamente i nodi di storage.

Poiché StorageGRID conserva copie complete di tutti i metadati degli oggetti in ogni sito, la capacità dei metadati dell'intera griglia è limitata dalla capacità dei metadati del sito più piccolo. Se devi aggiungere capacità di metadati a un sito, dovresti anche "espandere qualsiasi altro sito" Dello stesso numero di nodi di storage. Dopo aver eseguito l'espansione, StorageGRID ridistribuisce i metadati degli oggetti esistenti nei nuovi nodi, aumentando così la capacità complessiva dei metadati della griglia. Non è richiesta alcuna azione da parte dell'utente. L'avviso Low metadata storage viene cancellato.
Servizi: Stato - allarme Cassandra (SVST)
L'allarme servizi: Stato - Cassandra (SVST) indica che potrebbe essere necessario ricostruire il database Cassandra per un nodo di storage. Cassandra viene utilizzato come archivio di metadati per StorageGRID.
-
È necessario accedere a Grid Manager utilizzando un "browser web supportato".
-
È necessario disporre di autorizzazioni di accesso specifiche.
-
È necessario disporre di
Passwords.txtfile.
Se Cassandra viene arrestato per più di 15 giorni (ad esempio, il nodo di storage viene spento), Cassandra non si avvia quando il nodo viene riportato in linea. È necessario ricostruire il database Cassandra per il servizio DDS interessato.
È possibile "eseguire la diagnostica" per ottenere ulteriori informazioni sullo stato corrente della griglia.
|
|
Se due o più servizi di database Cassandra rimangono inutilizzati per più di 15 giorni, contattare il supporto tecnico e non procedere con la procedura riportata di seguito. |
-
Selezionare SUPPORT > Tools > Grid topology.
-
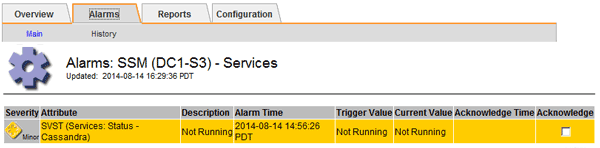
Selezionare Site > Storage Node > SSM > Services > Alarms > Main per visualizzare gli allarmi.
Questo esempio mostra che l'allarme SVST è stato attivato.
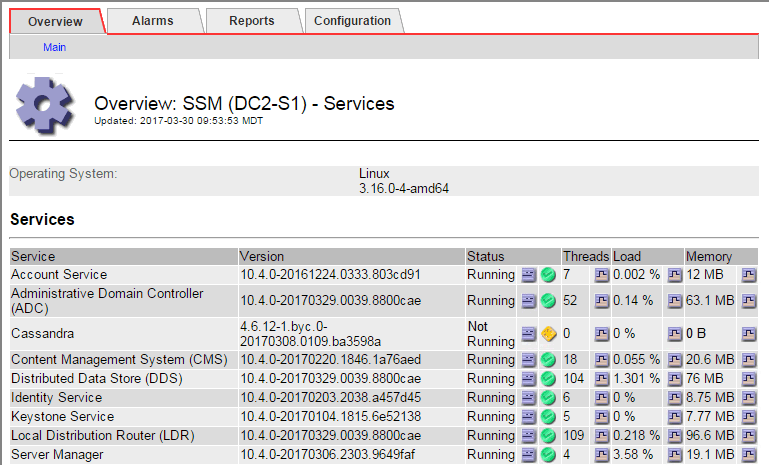
La pagina principale dei servizi SSM indica inoltre che Cassandra non è in esecuzione.
-
prova a riavviare Cassandra dal nodo di storage:
-
Accedere al nodo Grid:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. Una volta effettuato l'accesso come root, il prompt cambia da$a.#.
-
-
Inserire:
/etc/init.d/cassandra status -
Se Cassandra non è in esecuzione, riavviarlo:
/etc/init.d/cassandra restart
-
-
Se Cassandra non si riavvia, determinare per quanto tempo Cassandra è rimasto inattivo. Se Cassandra è rimasto inattivo per più di 15 giorni, è necessario ricostruire il database Cassandra.
Se due o più servizi di database Cassandra non sono disponibili, contattare il supporto tecnico e non procedere con la procedura riportata di seguito. È possibile determinare per quanto tempo Cassandra è rimasta inattiva, inserendolo nella cartella o esaminando il file servermanager.log.
-
Per inserire il grafico Cassandra:
-
Selezionare SUPPORT > Tools > Grid topology. Quindi selezionare Site > Storage Node > SSM > servizi > Report > grafici.
-
Selezionare attributo > Servizio: Stato - Cassandra.
-
Per Data di inizio, immettere una data che sia almeno 16 giorni prima della data corrente. Per Data di fine, inserire la data corrente.
-
Fare clic su Aggiorna.
-
Se il grafico mostra Cassandra come inattivo per più di 15 giorni, ricostruire il database Cassandra.
L'esempio seguente mostra che Cassandra è rimasta inattiva per almeno 17 giorni.
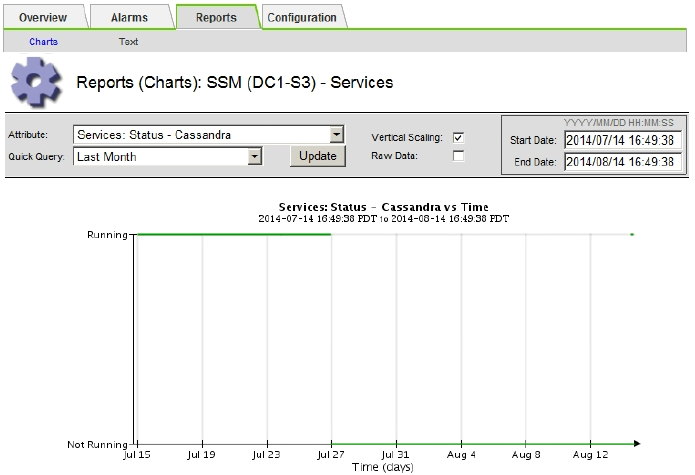
-
-
Per esaminare il file servermanager.log sul nodo di storage:
-
Accedere al nodo Grid:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. Una volta effettuato l'accesso come root, il prompt cambia da$a.#.
-
-
Inserire:
cat /var/local/log/servermanager.logViene visualizzato il contenuto del file servermanager.log.
Se Cassandra rimane inattivo per più di 15 giorni, nel file servermanager.log viene visualizzato il seguente messaggio:
"2014-08-14 21:01:35 +0000 | cassandra | cassandra not started because it has been offline for longer than its 15 day grace period - rebuild cassandra
-
Assicurarsi che la data e l'ora del messaggio siano quelle in cui si è tentato di riavviare Cassandra, come indicato al punto Riavviare Cassandra dal nodo di storage.
Per Cassandra possono essere presenti più voci; è necessario individuare la voce più recente.
-
Se Cassandra è rimasto inattivo per più di 15 giorni, è necessario ricostruire il database Cassandra.
Per istruzioni, vedere "Recovery Storage Node Down per più di 15 giorni".
-
Contattare il supporto tecnico se gli allarmi non vengono disattivati dopo la ricostruzione di Cassandra.
-
Errori di memoria esaurita di Cassandra (allarme SMTT)
Un allarme SMTT (Total Events) viene attivato quando il database Cassandra presenta un errore di memoria esaurita. Se si verifica questo errore, contattare il supporto tecnico per risolvere il problema.
Se si verifica un errore di memoria insufficiente per il database Cassandra, viene creato un dump heap, viene attivato un allarme SMTT (Total Events) e il conteggio degli errori Cassandra Heap out of Memory viene incrementato di uno.
-
Per visualizzare l'evento, selezionare SUPPORT > Tools > Grid topology > Configuration.
-
Verificare che il conteggio degli errori di memoria esaurita di Cassandra sia pari o superiore a 1.
È possibile "eseguire la diagnostica" per ottenere ulteriori informazioni sullo stato corrente della griglia.
-
Passare a.
/var/local/core/, comprimereCassandra.hprofe inviarla al supporto tecnico. -
Eseguire un backup di
Cassandra.hprofed eliminarlo da/var/local/core/ directory.Questo file può avere una dimensione massima di 24 GB, quindi è necessario rimuoverlo per liberare spazio.
-
Una volta risolto il problema, selezionare la casella di controllo Reset (Ripristina) per il conteggio degli errori Cassandra Heap out of Memory (heap Cassandra fuori memoria). Quindi selezionare Apply Changes (Applica modifiche).
Per reimpostare i conteggi degli eventi, è necessario disporre dell'autorizzazione di configurazione della pagina topologia griglia.