
Come utilizzare il remap delle porte
 Suggerisci modifiche
Suggerisci modifiche
Potrebbe essere necessario rimappare una porta in entrata o in uscita per diversi motivi. È possibile passare dal servizio di bilanciamento del carico CLB legacy all'endpoint corrente di bilanciamento del carico del servizio nginx e mantenere la stessa porta per ridurre l'impatto sui client, utilizzare la porta 443 per il client S3 su una rete client con nodo di amministrazione o per le restrizioni del firewall.
Migrare i client S3 da CLB a NGINX con il remap della porta
Nelle release precedenti a StorageGRID 11.3, il servizio bilanciamento del carico incluso nei nodi gateway è il bilanciamento del carico di connessione (CLB). In StorageGRID 11.3, NetApp introduce il servizio NGINX come soluzione integrata ricca di funzionalità per il bilanciamento del carico del traffico HTTP. Poiché il servizio CLB rimane disponibile nella release corrente di StorageGRID, non è possibile riutilizzare la porta 8082 nella nuova configurazione dell'endpoint del bilanciamento del carico. Per risolvere questo problema, la porta in entrata 8082 viene rimappata a 10443. In questo modo, tutte le richieste HTTPS inviate alla porta 8082 del gateway vengono reindirizzate alla porta 10443, ignorando il servizio CLB e connettendosi invece al servizio NGINX. Sebbene le seguenti istruzioni siano per VMware, la funzionalità PORT_REMAP esiste per tutti i metodi di installazione ed è possibile utilizzare un processo simile per le implementazioni e le appliance bare metal.
Implementazione di VMware Virtual Machine Gateway Node
I seguenti passaggi riguardano un'implementazione StorageGRID in cui il nodo gateway o i nodi vengono implementati in VMware vSphere 7 come macchine virtuali utilizzando il formato di virtualizzazione aperta (OVF) di StorageGRID. Il processo comporta la rimozione distruttiva della macchina virtuale e la ridistribuzione della macchina virtuale con lo stesso nome e configurazione. Prima di accendere la macchina virtuale, modificare la proprietà vApp per rimappare la porta, quindi accendere la macchina virtuale e seguire il processo di ripristino del nodo.
Prerequisiti
-
Si utilizza StorageGRID 11.3 o versione successiva
-
È stato scaricato e si dispone dell'accesso ai file di installazione della versione di StorageGRID installata.
-
Si dispone di un account vCenter con autorizzazioni per accendere/spegnere le macchine virtuali, modificare le impostazioni delle macchine virtuali e delle applicazioni, rimuovere le macchine virtuali da vCenter e implementare le macchine virtuali tramite OVF.
-
È stato creato un endpoint per il bilanciamento del carico
-
La porta è configurata sulla porta di reindirizzamento desiderata
-
Il certificato SSL dell'endpoint è uguale a quello installato per il servizio CLB nel certificato server di configurazione/certificati server/servizio API di archiviazione oggetti o il client è in grado di accettare una modifica del certificato.
-

|
If your existing certificate is self-signed, you cannot reuse it in the new endpoint. You must generate a new self-signed certificate when creating the endpoint and configure the clients to accept the new certificate. |
Distruggere il primo nodo gateway
Per distruggere il primo nodo gateway, attenersi alla seguente procedura:
-
Scegliere il nodo gateway con cui iniziare se la griglia contiene più di uno.
-
Rimuovere gli IP dei nodi da tutte le entità round robin DNS o dai pool di bilanciamento del carico, se applicabile.
-
Attendere la scadenza del TTL (Time-to-Live) e delle sessioni aperte.
-
Spegnere il nodo VM.
-
Rimuovere il nodo VM dal disco.
Implementare il nodo gateway sostitutivo
Per implementare il nodo gateway sostitutivo, attenersi alla seguente procedura:
-
Implementare la nuova macchina virtuale da OVF, selezionando i file .ovf, .mf e .vmdk dal pacchetto di installazione scaricato dal sito di supporto:
-
vsphere-gateway.mf
-
vsphere-gateway.ovf
-
NetApp-SG-11.4.0-20200721.1338.d3969b3.vmdk
-
-
Una volta implementata la macchina virtuale, selezionarla dall'elenco delle macchine virtuali e selezionare la scheda Configura opzioni vApp.
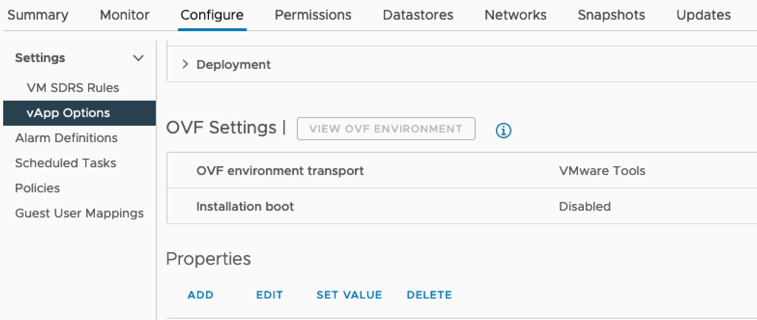
-
Scorrere fino alla sezione Proprietà e selezionare LA proprietà PORT_REMAP_INBOUND
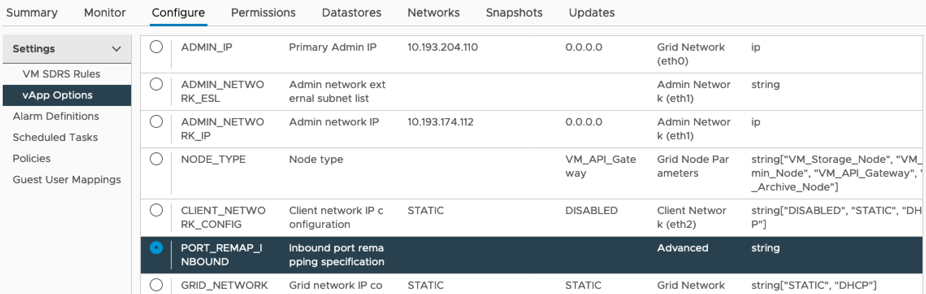
-
Scorrere fino all'inizio dell'elenco Proprietà e fare clic su Modifica
-
Selezionare la scheda tipo, verificare che la casella di controllo configurabile dall'utente sia selezionata, quindi fare clic su Salva.
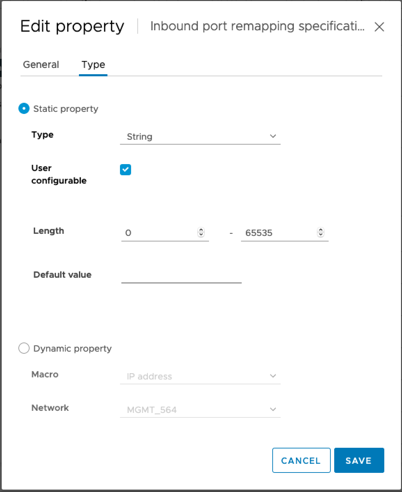
-
Nella parte superiore dell'elenco Proprietà, con la proprietà "PORT_REMAP_INBOUND" ancora selezionata, fare clic su Imposta valore.
-
Nel campo Property Value (valore proprietà), inserire la rete (griglia, amministratore o client), il TCP, la porta originale (8082) e la nuova porta (10443) con "/" tra ciascun valore, come illustrato di seguito.
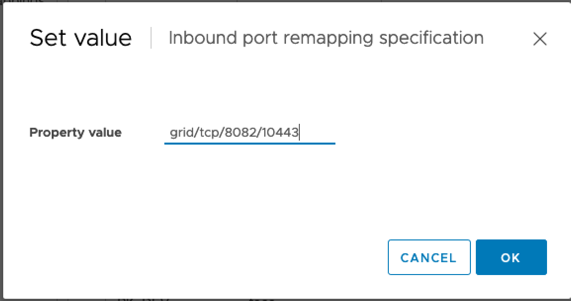
-
Se si utilizzano più reti, utilizzare una virgola (,) per separare le stringhe di rete, ad esempio Grid/tcp/8082/10443,admin/tcp/8082/10443,client/tcp/8082/10443
Ripristinare il nodo gateway
Per ripristinare il nodo gateway, attenersi alla seguente procedura:
-
Accedere alla sezione manutenzione/Ripristino dell'interfaccia utente di Grid Management.
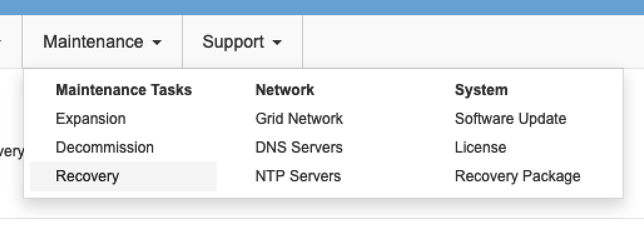
-
Accendere il nodo VM e attendere che venga visualizzato nella sezione Maintenance/Recovery Pending Nodes dell'interfaccia utente Grid Management.

For information and directions for node recovery, see the https://docs.netapp.com/sgws-114/topic/com.netapp.doc.sg-maint/GUID-7E22B1B9-4169-4800-8727-75F25FC0FFB1.html[Recovery and Maintenance guide]
-
Una volta ripristinato il nodo, l'IP può essere incluso in tutte le entità round robin DNS o nei pool di bilanciamento del carico, se applicabile.
A questo punto, tutte le sessioni HTTPS sulla porta 8082 vanno alla porta 10443
Rimappare la porta 443 per l'accesso al client S3 su un nodo Admin
La configurazione predefinita nel sistema StorageGRID per un nodo admin o un gruppo ha contenente un nodo Admin prevede che le porte 443 e 80 siano riservate alle interfacce utente di gestione e di gestione del tenant e non possano essere utilizzate per gli endpoint di bilanciamento del carico. La soluzione consiste nell'utilizzare la funzione di remap delle porte e reindirizzare la porta in entrata 443 a una nuova porta che verrà configurata come endpoint del bilanciamento del carico. Una volta completato il traffico del client S3, sarà possibile utilizzare la porta 443, l'interfaccia utente di gestione della griglia sarà accessibile solo tramite la porta 8443 e l'interfaccia utente di gestione del tenant sarà accessibile solo sulla porta 9443. La funzione di remap port può essere configurata solo al momento dell'installazione del nodo. Per implementare un remap di porta di un nodo attivo nella griglia, è necessario ripristinarlo allo stato preinstallato. Si tratta di una procedura distruttiva che include un ripristino del nodo una volta apportata la modifica alla configurazione.
Log e database di backup
I nodi di amministrazione contengono registri di audit, metriche prometheus e informazioni storiche su attributi, allarmi e avvisi. Avere più nodi di amministrazione significa avere più copie di questi dati. Se non si dispone di più nodi di amministrazione nella griglia, assicurarsi di conservare questi dati per il ripristino dopo che il nodo è stato ripristinato al termine di questo processo. Se si dispone di un altro nodo admin nella griglia, è possibile copiare i dati da tale nodo durante il processo di ripristino. Se non si dispone di un altro nodo admin nella griglia, è possibile seguire queste istruzioni per copiare i dati prima di distruggere il nodo.
Copia dei registri di audit
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Creare la directory per copiare tutti i file di log di audit in una posizione temporanea su un nodo griglia separato. Utilizzare storage_node_01:
-
ssh admin@storage_node_01_IP -
mkdir -p /var/local/tmp/saved-audit-logs
-
-
Tornare al nodo admin, arrestare il servizio AMS per impedire la creazione di un nuovo file di log:
service ams stop -
Rinominare il file audit.log in modo che non sovrascriva il file esistente quando lo si copia nel nodo di amministrazione recuperato.
-
Rinominare il file audit.log con un nome di file univoco numerato, ad esempio yyyy-mm-dd.txt.1. Ad esempio, è possibile rinominare il file di log di audit in 2015-10-25.txt.1
cd /var/local/audit/export ls -l mv audit.log 2015-10-25.txt.1
-
-
Riavviare il servizio AMS:
service ams start -
Copia tutti i file di log di audit:
scp * admin@storage_node_01_IP:/var/local/tmp/saved-audit-logs
Copia dei dati Prometheus
|
|
La copia del database Prometheus potrebbe richiedere un'ora o più. Alcune funzionalità di Grid Manager non saranno disponibili mentre i servizi vengono arrestati sul nodo di amministrazione. |
-
Creare la directory per copiare i dati prometheus in una posizione temporanea su un nodo griglia separato, ancora una volta utilizzeremo storage_node_01:
-
Accedere al nodo di storage:
-
Immettere il seguente comando:
ssh admin@storage_node_01_IP -
Immettere la password elencata in
Passwords.txtfile. -
mkdir -p /var/local/tmp/prometheus`
-
-
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@admin_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Dal nodo di amministrazione, arrestare il servizio Prometheus:
service prometheus stop-
Copiare il database Prometheus dal nodo di amministrazione di origine al nodo di storage percorso di backup nodo:
/rsync -azh --stats "/var/local/mysql_ibdata/prometheus/data" "storage_node_01_IP:/var/local/tmp/prometheus/"
-
-
Riavviare il servizio Prometheus sul nodo di amministrazione di origine.
service prometheus start
Backup delle informazioni cronologiche
Le informazioni storiche sono memorizzate in un database mysql. Per eseguire il dump di una copia del database, sono necessari l'utente e la password di NetApp. Se si dispone di un altro nodo admin nella griglia, questo passaggio non è necessario e il database può essere clonato da un nodo admin rimanente durante il processo di recovery.
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@admin_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Arrestare i servizi StorageGRID sul nodo di amministrazione e avviare ntp e mysql
-
Arrestare tutti i servizi:
service servermanager stop -
riavviare il servizio ntp:
service ntp start..riavviare il servizio mysql:service mysql start
-
-
Dump del database mi in /var/local/tmp
-
immettere il seguente comando:
mysqldump –u username –p password mi > /var/local/tmp/mysql-mi.sql
-
-
Copiare il file dump mysql in un nodo alternativo, verrà utilizzato storage_node_01:
scp /var/local/tmp/mysql-mi.sql _storage_node_01_IP:/var/local/tmp/mysql-mi.sql-
Se non si richiede più l'accesso senza password ad altri server, rimuovere la chiave privata dall'agente SSH. Inserire:
ssh-add -D
-
Ricostruire il nodo Admin
Ora che si dispone di una copia di backup di tutti i dati e i registri desiderati su un altro nodo admin nella griglia o memorizzati in una posizione temporanea, è il momento di ripristinare l'appliance in modo da poter configurare il rimap della porta.
-
La reimpostazione di un'appliance riporta l'appliance allo stato preinstallato, dove conserva solo il nome host, gli IP e le configurazioni di rete. Tutti i dati andranno persi, motivo per cui ci siamo assicurati di avere un backup di tutte le informazioni importanti.
-
immettere il seguente comando:
sgareinstallroot@sg100-01:~ # sgareinstall WARNING: All StorageGRID Webscale services on this node will be shut down. WARNING: Data stored on this node may be lost. WARNING: You will have to reinstall StorageGRID Webscale to this node. After running this command and waiting a few minutes for the node to reboot, browse to one of the following URLs to reinstall StorageGRID Webscale on this node: https://10.193.174.192:8443 https://10.193.204.192:8443 https://169.254.0.1:8443 Are you sure you want to continue (y/n)? y Renaming SG installation flag file. Initiating a reboot to trigger the StorageGRID Webscale appliance installation wizard.
-
-
Dopo un certo periodo di tempo, l'appliance si riavvierà e sarà possibile accedere all'interfaccia utente PGE del nodo.
-
Accedere alla scheda Configure Networking (Configura rete)
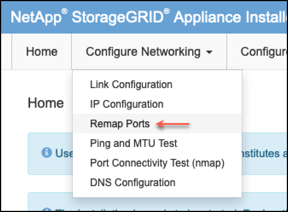
-
Selezionare la rete, il protocollo, la direzione e le porte desiderate, quindi fare clic sul pulsante Add Rule (Aggiungi regola).
Il rimappamento della porta in entrata 443 sulla rete GRID interromperà l'installazione e le procedure di espansione. Si sconsiglia di rimappare la porta 443 sulla rete GRID. 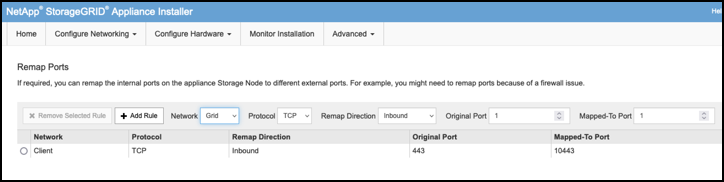
-
Una volta aggiunti i rimap di porta desiderati, è possibile tornare alla scheda home e fare clic sul pulsante Start Installation (Avvia installazione).
A questo punto, è possibile seguire le procedure di ripristino del nodo Admin in "documentazione del prodotto"
Ripristinare database e registri
Una volta ripristinato il nodo admin, è possibile ripristinare le metriche, i registri e le informazioni storiche. Se si dispone di un altro nodo admin nella griglia, seguire la "documentazione del prodotto" utilizzando gli script prometheus-clone-db.sh e mi-clone-db.sh. Se si tratta dell'unico nodo admin e si è scelto di eseguire il backup di questi dati, attenersi alla procedura riportata di seguito per ripristinare le informazioni.
Copia dei log di audit
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Copiare i file di log di controllo conservati nel nodo di amministrazione recuperato:
scp admin@grid_node_IP:/var/local/tmp/saved-audit-logs/YYYY* . -
Per motivi di sicurezza, eliminare i registri di controllo dal nodo Grid guasto dopo aver verificato che siano stati copiati correttamente nel nodo Admin ripristinato.
-
Aggiornare le impostazioni di utente e gruppo dei file di log di controllo sul nodo di amministrazione recuperato:
chown ams-user:bycast *
È inoltre necessario ripristinare qualsiasi accesso client preesistente alla condivisione di controllo. Per ulteriori informazioni, consultare le istruzioni per l'amministrazione di StorageGRID.
Ripristinare le metriche Prometheus
|
|
La copia del database Prometheus potrebbe richiedere un'ora o più. Alcune funzionalità di Grid Manager non saranno disponibili mentre i servizi vengono arrestati sul nodo di amministrazione. |
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Dal nodo di amministrazione, arrestare il servizio Prometheus:
service prometheus stop-
Copiare il database Prometheus dalla posizione di backup temporaneo al nodo admin:
/rsync -azh --stats "backup_node:/var/local/tmp/prometheus/" "/var/local/mysql_ibdata/prometheus/" -
verificare che i dati siano nel percorso corretto e che siano completi
ls /var/local/mysql_ibdata/prometheus/data/
-
-
Riavviare il servizio Prometheus sul nodo di amministrazione di origine.
service prometheus start
Ripristinare le informazioni cronologiche
-
Accedere al nodo di amministrazione:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile. -
Aggiungere la chiave privata SSH all'agente SSH. Inserire:
ssh-add -
Inserire la password di accesso SSH elencata in
Passwords.txtfile.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
Copiare il file dump mysql dal nodo alternativo:
scp grid_node_IP_:/var/local/tmp/mysql-mi.sql /var/local/tmp/mysql-mi.sql -
Arrestare i servizi StorageGRID sul nodo di amministrazione e avviare ntp e mysql
-
Arrestare tutti i servizi:
service servermanager stop -
riavviare il servizio ntp:
service ntp start..riavviare il servizio mysql:service mysql start
-
-
Rilasciare il database mi e creare un nuovo database vuoto:
mysql -u username -p password -A mi -e "drop database mi; create database mi;" -
ripristinare il database mysql dal dump del database:
mysql -u username -p password -A mi < /var/local/tmp/mysql-mi.sql -
Riavviare tutti gli altri servizi
service servermanager start
Di Aron Klein