

検索と復元を使用したONTAPバックアップからの復元
 変更を提案
変更を提案
検索と復元を使用して、ONTAPバックアップファイルからボリューム、フォルダー、またはファイルをリカバリできます。検索と復元機能を使用すると、システム名、ボリューム名、ファイル名を正確に指定することなく、すべてのバックアップ(ローカルSnapshot、レプリケートされたボリューム、オブジェクトストレージを含む)を検索できます。
通常、ローカル スナップショットまたは複製されたボリュームからの復元は、オブジェクト ストレージからの復元よりも高速でコストも低くなります。
ボリューム全体を復元する場合、 NetApp Backup and Recovery はバックアップ データを使用して新しいボリュームを作成します。元のシステム、同じクラウド アカウント内の別のシステム、またはオンプレミスのONTAPシステムに復元できます。フォルダーとファイルは、元の場所、同じシステム内の別のボリューム、同じクラウド アカウント内の別のシステム、またはオンプレミス システムに復元できます。
復元機能はONTAP のバージョンによって異なります。
-
フォルダ: ONTAP 9.13.0 以降を使用すると、すべてのファイルとサブフォルダを含むフォルダを復元できます。それ以前のバージョンでは、フォルダ内のファイルのみを復元できます。
-
アーカイブ ストレージ: アーカイブ ストレージ ( ONTAP 9.10.1 以降で利用可能) からの復元は遅くなり、追加コストが発生する可能性があります。
-
宛先クラスタの要件:
-
ボリュームリストア: ONTAP 9.10.1 以上
-
ファイル復元: ONTAP 9.11.1 以上
-
Google Archive およびStorageGRID: ONTAP 9.12.1 以上
-
フォルダの復元: ONTAP 9.13.1 以上
-

|
|
開始する前に、復元するボリュームまたはファイルの名前または場所をある程度把握しておく必要があります。
検索と復元がサポートされているシステムとオブジェクト ストレージ プロバイダー
セカンダリ システム (複製されたボリューム) またはオブジェクト ストレージ (バックアップ ファイル) にあるバックアップ ファイルから、次のシステムにONTAPデータを復元できます。スナップショットはソース システム上に存在し、同じシステムにのみ復元できます。
注意: ボリュームとファイルはどのタイプのバックアップ ファイルからでも復元できますが、現時点では、フォルダーを復元できるのはオブジェクト ストレージ内のバックアップ ファイルからのみです。
| バックアップファイルの場所 | 宛先システム | |
|---|---|---|
オブジェクトストア(バックアップ) |
セカンダリシステム(レプリケーション) |
|
Amazon S3 |
AWS オンプレミスONTAPシステムのCloud Volumes ONTAP |
AWS オンプレミスONTAPシステムのCloud Volumes ONTAP |
Azure ブロブ |
Azure のCloud Volumes ONTAPオンプレミスONTAPシステム |
Azure のCloud Volumes ONTAPオンプレミスONTAPシステム |
Google Cloud Storage |
Google オンプレミスONTAPシステムのCloud Volumes ONTAP |
Google オンプレミスONTAPシステムのCloud Volumes ONTAP |
NetAppStorageGRID |
オンプレミスのONTAPシステムCloud Volumes ONTAP |
オンプレミスのONTAPシステム |
ONTAP S3 |
オンプレミスのONTAPシステムCloud Volumes ONTAP |
オンプレミスのONTAPシステム |
検索と復元の場合、コンソール エージェントは次の場所にインストールできます。
-
Amazon S3の場合、コンソールエージェントはAWSまたはオンプレミスに導入できます。
-
Azure Blobの場合、コンソールエージェントはAzureまたはオンプレミスに展開できます。
-
Google Cloud Storage の場合、コンソール エージェントを Google Cloud Platform VPC にデプロイする必要があります。
-
StorageGRIDの場合、コンソールエージェントは、インターネットアクセスの有無にかかわらず、お客様の敷地内に導入する必要があります。
-
ONTAP S3の場合、コンソールエージェントは、オンプレミス(インターネットアクセスの有無にかかわらず)またはクラウドプロバイダー環境に導入できます。
「オンプレミスのONTAPシステム」への参照には、 FAS、 AFF、およびONTAP Selectシステムが含まれることに注意してください。
検索と復元の前提条件
検索と復元を有効にする前に、環境が次の要件を満たしていることを確認してください。
-
クラスタの要件:
-
ONTAPバージョンは 9.8 以上である必要があります。
-
ストレージVM上にIPv4 NFSデータLIFを設定し、ボリュームのNFSエクスポートを設定する必要があります。Search & Restoreは、NFSボリュームとSMB/CIFSボリュームの両方をサポートしています。
-
SnapDiff RPC サーバーをストレージ VM 上で有効化する必要があります。システムでインデックス作成を有効にすると、コンソールはこれを自動的に実行します。(SnapDiff は、スナップショット間のファイルとディレクトリの差異を迅速に識別するテクノロジーです。)
-
-
NetApp、検索と復元の回復力を高めるために、コンソール エージェントに別のボリュームをマウントすることを推奨しています。手順については、ボリュームをマウントしてカタログのインデックスを再作成する 。
レガシー検索と復元の前提条件(インデックスカタログ v1 を使用)
従来のインデックスを使用する場合の検索と復元の要件は次のとおりです。
Details
-
AWS 要件:
-
コンソールに権限を付与するユーザー ロールに、特定の Amazon Athena、AWS Glue、および AWS S3 権限を追加する必要があります。"すべての権限が正しく設定されていることを確認してください"。
以前に設定したコンソール エージェントでNetApp Backup and Recoveryをすでに使用していた場合は、コンソール ユーザー ロールに Athena および Glue 権限を追加する必要があることに注意してください。これらは検索と復元に必要です。
-
-
Azure の要件:
-
Azure Synapse Analytics リソース プロバイダー (「Microsoft.Synapse」と呼ばれます) をサブスクリプションに登録する必要があります。 "このリソースプロバイダーをサブスクリプションに登録する方法をご覧ください" 。リソース プロバイダーを登録するには、サブスクリプションの 所有者 または 投稿者 である必要があります。
-
コンソールに権限を付与するユーザー ロールに、特定の Azure Synapse ワークスペースおよび Data Lake Storage アカウントの権限を追加する必要があります。"すべての権限が正しく設定されていることを確認してください"。
以前に構成したコンソール エージェントでNetApp Backup and Recovery を既に使用していた場合は、Azure Synapse ワークスペースと Data Lake ストレージ アカウントのアクセス許可をコンソール ユーザー ロールに追加する必要があることに注意してください。これらは検索と復元に必要です。
-
コンソール エージェントは、インターネットへの HTTP 通信用にプロキシ サーバーなしで構成する必要があります。コンソール エージェントに HTTP プロキシ サーバーを構成している場合は、検索と復元機能は使用できません。
-
-
Google Cloud の要件:
-
NetApp Consoleに権限を付与するユーザー ロールに、特定の Google BigQuery 権限を追加する必要があります。"すべての権限が正しく設定されていることを確認してください"。
以前に構成したコンソール エージェントでNetApp Backup and Recovery をすでに使用していた場合は、コンソール ユーザー ロールに BigQuery 権限を追加する必要があります。これらは検索と復元に必要です。
-
-
StorageGRIDおよびONTAP S3 の要件:
構成に応じて、検索と復元を実装する方法は 2 つあります。
-
アカウントにクラウド プロバイダーの資格情報がない場合、インデックス カタログ情報はコンソール エージェントに保存されます。
インデックス カタログ v2 の詳細については、インデックス カタログを有効にする方法に関する以下のセクションを参照してください。
-
プライベート (ダーク) サイトでコンソール エージェントを使用している場合、インデックス カタログ情報はコンソール エージェントに保存されます (コンソール エージェント バージョン 3.9.25 以上が必要です)。
-
もしあなたが "AWS認証情報"または "Azure 資格情報"アカウントにインデックスカタログがある場合は、クラウドに展開されたコンソールエージェントと同様に、インデックスカタログはクラウドプロバイダーに保存されます。 (両方の認証情報がある場合、デフォルトで AWS が選択されます。)
オンプレミスのコンソール エージェントを使用している場合でも、コンソール エージェントの権限とクラウド プロバイダー リソースの両方について、クラウド プロバイダーの要件を満たす必要があります。この実装を使用する場合は、上記の AWS および Azure の要件を参照してください。
-
検索と復元のプロセス
プロセスは次のようになります。
-
検索と復元を使用する前に、ボリューム データを復元する各ソース システムで「インデックス作成」を有効にする必要があります。これにより、インデックス カタログは各ボリュームのバックアップ ファイルを追跡できるようになります。
Backup and Recoveryでは、作成タイムスタンプが同じボリューム内の別のスナップショットと完全に一致するスナップショットはインデックス化されません。 -
ボリューム バックアップからボリュームまたはファイルを復元する場合は、[検索と復元] で [検索と復元] を選択します。
-
ボリューム名の一部または全部、ファイル名の一部または全部、バックアップ場所、サイズの範囲、作成日の範囲、その他の検索フィルターでボリューム、フォルダー、またはファイルの検索条件を入力し、[検索] を選択します。
「検索結果」ページには、検索条件に一致するファイルまたはボリュームがあるすべての場所が表示されます。
-
ボリュームまたはファイルの復元に使用する場所の「すべてのバックアップを表示」を選択し、使用する実際のバックアップ ファイルで「復元」を選択します。
-
ボリューム、フォルダー、またはファイルを復元する場所を選択し、「復元」を選択します。
-
ボリューム、フォルダー、またはファイルが復元されます。
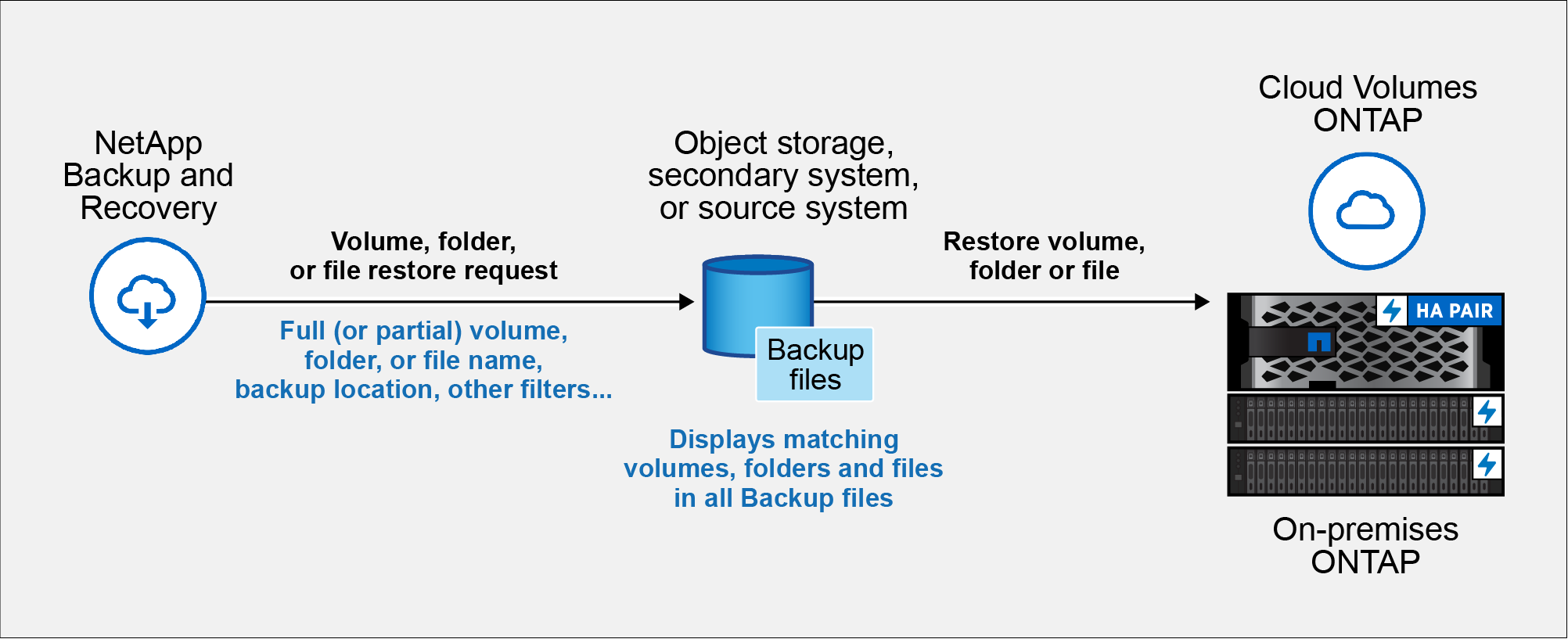
名前の一部を知るだけで、 NetApp Backup and Recovery は検索に一致するすべてのバックアップ ファイルを検索します。
各システムでインデックスカタログを有効にする
検索と復元を使用する前に、ボリュームまたはファイルを復元する予定の各ソース システムで「インデックス作成」を有効にする必要があります。これにより、インデックス カタログはすべてのボリュームとすべてのバックアップ ファイルを追跡できるようになり、検索が非常に迅速かつ効率的になります。
インデックス カタログは、システム内のすべてのボリュームとバックアップ ファイルに関するメタデータを保存するデータベースです。これは、復元するデータが含まれているバックアップ ファイルをすばやく見つけるために、検索と復元機能によって使用されます。
NetApp Backup and Recovery、インデックス カタログを使用する場合、別のバケットはプロビジョニングされません。代わりに、AWS、Azure、Google Cloud Platform、 StorageGRID、またはONTAP S3 に保存されているバックアップの場合、サービスはコンソール エージェントまたはクラウド プロバイダー環境にスペースをプロビジョニングします。
インデックス カタログは以下をサポートします。
-
3分以内にグローバル検索を効率化
-
最大50億ファイル
-
クラスターあたり最大5000ボリューム
-
ボリュームあたり最大10万個のスナップショット
-
ベースライン インデックスの最大時間は 7 日未満です。実際の時間は環境によって異なります。
システムでインデックス作成がすでに有効になっている場合は、次のセクションに進み、データを復元してください。
まず、カタログ ファイルを保持するための別のボリュームをマウントする必要があります。これにより、スナップショットを保持するファイルのサイズが大きくなりすぎた場合にデータが失われるのを防ぎます。これはすべてのクラスターで必要なわけではなく、環境内の任意のクラスターから任意の 1 つのボリュームをマウントできます。これを行わないと、インデックスが正しく機能しない可能性があります。
マウントされたボリュームについては、次のサイズ設定ガイダンスを使用します。
-
NetApp NFSボリュームを使用する
-
300 MB/秒のディスク スループットを備えたAFFストレージを推奨します。スループットが低下すると、検索やその他の操作に影響します。
-
NetAppスナップショットを有効にして、カタログバックアップzipファイルに加えてカタログメタデータを保護します。
-
10億ファイルあたり50GB
-
カタログデータ用に 20 GB、zip ファイル作成および一時ファイル用の追加スペース
-
ボリュームをマウントする
/opt/application/netapp/cbs次のコマンドを入力します。-
volume nameカタログファイルが保存されるクラスタ上のボリュームです -
/opt/application/netapp/cbsマウントされているパスですmount <cluster IP address>:/<volume name> /opt/application/netapp/cbs例:
mount 10.192.24.17:/CATALOG_SCALE_234 /opt/application/netapp/cbs -
-
次のいずれかを実行します。
-
システムがインデックスされていない場合は、復元ダッシュボードの [検索と復元] で [システムのインデックスを有効にする] を選択します。
-
少なくとも 1 つのシステムがすでにインデックスされている場合は、復元ダッシュボードの [検索と復元] で [インデックス設定] を選択します。
-
-
システムに対して*インデックスを有効にする*を選択します。
すべてのサービスがプロビジョニングされ、インデックス カタログがアクティブ化されると、システムは「アクティブ」として表示されます。
システム内のボリュームのサイズと、3 つのバックアップ場所すべてにあるバックアップ ファイルの数によっては、初期のインデックス作成プロセスに最大 1 時間かかる場合があります。その後は、最新の状態を維持するために、1 時間ごとに段階的な変更が透過的に更新されます。
検索と復元を使用してボリューム、フォルダ、ファイルを復元する
完了したらシステムのインデックスを有効にしました、検索と復元を使用してボリューム、フォルダー、およびファイルを復元できます。これにより、幅広いフィルターを使用して、すべてのバックアップ ファイルから復元するファイルまたはボリュームを正確に見つけることができます。
-
コンソール メニューから、保護 > バックアップとリカバリ を選択します。
-
*復元*タブを選択すると、復元ダッシュボードが表示されます。
-
[検索と復元] セクションから、[検索と復元] を選択します。
-
[検索と復元] セクションから、[検索と復元] を選択します。
-
検索と復元ページから:
-
検索バー に、ボリューム名、フォルダー名、またはファイル名の完全または一部を入力します。
-
リソースの種類を選択します: ボリューム、ファイル、フォルダー、または*すべて*。
-
[フィルター条件] 領域で、フィルター条件を選択します。たとえば、データが存在するシステムとファイルの種類(.JPEG ファイルなど)を選択できます。または、オブジェクト ストレージ内の利用可能なスナップショットまたはバックアップ ファイル内のみで結果を検索する場合は、バックアップの場所のタイプを選択できます。
-
-
*検索*を選択すると、検索結果領域に、検索に一致するファイル、フォルダー、またはボリュームを持つすべてのリソースが表示されます。
-
復元するデータがあるリソースを見つけて、[すべてのバックアップを表示] を選択し、一致するボリューム、フォルダー、またはファイルを含むすべてのバックアップ ファイルを表示します。
-
データの復元に使用するバックアップ ファイルを見つけて、[復元] を選択します。
結果には、検索したファイルを含むローカル ボリュームのスナップショットとリモートの複製ボリュームが識別されることに注意してください。クラウド バックアップ ファイル、スナップショット、または複製されたボリュームから復元することを選択できます。
-
ボリューム、フォルダー、またはファイルを復元する宛先の場所を選択し、[復元] を選択します。
-
ボリュームの場合、元の宛先システムを選択することも、代替システムを選択することもできます。 FlexGroupボリュームを復元する場合は、複数のアグリゲートを選択する必要があります。
-
フォルダーの場合は、元の場所に復元することも、システム、ボリューム、フォルダーなどの別の場所を選択することもできます。
-
ファイルについては、元の場所へ復元することも、システム、ボリューム、フォルダーなどの別の場所を選択することもできます。元の場所を選択するときに、ソース ファイルを上書きするか、新しいファイルを作成するかを選択できます。
オンプレミスのONTAPシステムを選択し、オブジェクト ストレージへのクラスタ接続をまだ構成していない場合は、追加情報の入力を求められます。
-
Amazon S3 から復元する場合は、宛先ボリュームが存在するONTAPクラスター内の IPspace を選択し、作成したユーザーのアクセス キーとシークレット キーを入力してONTAPクラスターに S3 バケットへのアクセス権を付与し、オプションで安全なデータ転送のためにプライベート VPC エンドポイントを選択します。"これらの要件の詳細については、こちらをご覧ください。"。
-
Azure Blob から復元する場合は、宛先ボリュームが存在するONTAPクラスター内の IPspace を選択し、オプションで VNet とサブネットを選択して、安全なデータ転送のためのプライベート エンドポイントを選択します。"これらの要件の詳細については、こちらをご覧ください。"。
-
Google Cloud Storage から復元する場合は、宛先ボリュームが存在するONTAPクラスター内の IPspace と、オブジェクト ストレージにアクセスするためのアクセス キーとシークレット キーを選択します。"これらの要件の詳細については、こちらをご覧ください。"。
-
StorageGRIDから復元する場合は、 StorageGRIDサーバーの FQDN と、 ONTAP がStorageGRIDとの HTTPS 通信に使用するポートを入力し、オブジェクト ストレージにアクセスするために必要なアクセス キーとシークレット キー、および宛先ボリュームが存在するONTAPクラスタ内の IPspace を入力します。"これらの要件の詳細については、こちらをご覧ください。"。
-
ONTAP S3 からリストアする場合は、 ONTAP S3 サーバーの FQDN と、 ONTAP がONTAP S3 との HTTPS 通信に使用するポートを入力し、オブジェクト ストレージにアクセスするために必要なアクセス キーとシークレット キー、および宛先ボリュームが存在するONTAPクラスター内の IPspace を選択します。"これらの要件の詳細については、こちらをご覧ください。"。
-
-
ボリューム、フォルダー、またはファイルが復元され、復元ダッシュボードに戻り、復元操作の進行状況を確認できます。また、*ジョブ監視*タブを選択して、復元の進行状況を確認することもできます。見る"ジョブモニターページ"。