TR-4920 :『 FlexPod Datacenter with NetApp SnapMirror Business Continuity and ONTAP 9.10 』
 変更を提案
変更を提案
Jyh - ネットアップの陳氏をたたきます
はじめに
FlexPod 解決策
FlexPod は、 Cisco とネットアップが提供する次のコンポーネントで構成される、統合インフラのベストプラクティスデータセンターアーキテクチャです。
-
Cisco Unified Computing System ( Cisco UCS )
-
Cisco Nexus および MDS ファミリーのスイッチ
-
NetApp FAS 、 NetApp AFF 、ネットアップオール SAN アレイ( ASA )システム
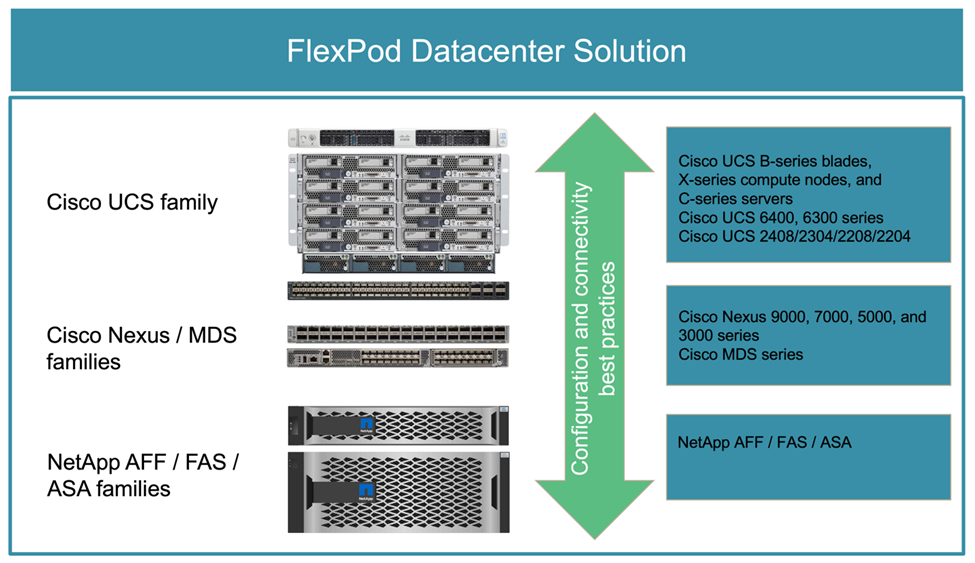
次の図は、 FlexPod ソリューションの作成に使用するコンポーネントの一部を示しています。これらのコンポーネントは、 Cisco とネットアップの両方のベストプラクティスに従って接続および構成されており、さまざまなエンタープライズワークロードを確実に実行するための理想的なプラットフォームを提供します。
Cisco Validated Design ( CVD )や NetApp Verified Architectures ( NVA )が幅広く用意されています。これらの CVD と NVA は、主要なデータセンターワークロードをすべてカバーしており、ネットアップと Cisco on FlexPod ソリューションとの間で継続的なコラボレーションやイノベーションの成果です。
作成プロセスに広範なテストと検証を組み込むことで、 FlexPod CVD と NVA は、解決策 アーキテクチャのリファレンス設計と段階的な導入ガイドを提供し、パートナー様やお客様が FlexPod ソリューションを導入して採用できるよう支援します。これらの CVD と NVA を設計と実装のガイドとして使用することで、リスクを軽減し、解決策 のダウンタイムを短縮し、導入する FlexPod ソリューションの可用性、拡張性、柔軟性、セキュリティを向上させることができます。
ここに示す FlexPod コンポーネントファミリー( Cisco UCS 、 Cisco Nexus / MDS スイッチ、ネットアップストレージ)には、インフラをスケールアップまたはスケールダウンするためのプラットフォームオプションとリソースオプションが用意されており、 FlexPod の設定と接続のベストプラクティスに基づいて必要な機能がサポートされています。FlexPod は、複数の一貫した導入が必要な環境でも、追加の FlexPod スタックをロールアウトしてスケールアウトすることができます。
ディザスタリカバリとビジネス継続性
企業がアプリケーションとデータサービスを災害から迅速にリカバリできるようにするためには、さまざまな方法を採用できます。ディザスタリカバリ( DR )とビジネス継続性( BC )を計画し、ビジネス目標を達成する解決策 を実装し、災害シナリオを定期的にテストすることで、企業は災害からのリカバリが可能となり、災害発生後も重要なビジネスサービスを継続できます。
アプリケーションやデータサービスの種類によって、 DR や BC の要件が異なる場合があります。緊急時や災害時には必要としないアプリケーションやデータもあれば、ビジネス要件に対応するために継続的な可用性が必要となるアプリケーションやデータもあります。
ミッションクリティカルなアプリケーションやデータサービスを利用できない場合は、ビジネスで考慮すべきメンテナンスや災害のシナリオなど、回答 の質問に対して慎重な評価が必要です。 災害発生時にどの程度のデータ損失を許容できるか、リカバリをどのくらいの時間で実施できるか。
収益創出のためにデータサービスに依存解決策 している企業では、さまざまな単一点障害のシナリオに耐えられるだけでなく、継続的なビジネス運用を可能にするためにサイト障害のシナリオによってデータサービスを保護する必要があります。
目標復旧時点と目標復旧時間
Recovery Point Objective ( RPO ;目標復旧時点)は、損失やデータのリカバリ先となるデータの量を、時間の観点から測定します。日々のバックアップ計画では、企業が 1 日分のデータを失うことがあります。これは、前回のバックアップ以降に行われたデータの変更が災害で失われる可能性があるためです。ビジネスクリティカルなデータサービスやミッションクリティカルなデータサービスの場合、 RPO ゼロ、およびデータ損失ゼロの関連計画とインフラが求められることがあります。
Recovery Time Objective ( RTO ;目標復旧時間)は、データを使用できない時間、またはデータサービスを復旧するまでにどれくらいの時間がかかるかを測定します。たとえば、バックアップとリカバリを実装しており、サイズによっては特定のデータセットに対して従来のテープを使用する場合があります。このため、バックアップテープからデータをリストアするには、数時間かかる場合もあれば、インフラに障害が発生している場合は数日かかる場合もあります。時間の考慮事項には、データのリストアに加えて、インフラをバックアップする時間も考慮する必要があります。ミッションクリティカルなデータサービスの場合、 RTO が非常に低く、ビジネスの継続性を維持するためにデータサービスを迅速にオンラインに戻すために数秒から数分のフェイルオーバー時間しか許容されないことがあります。
SM-BC です
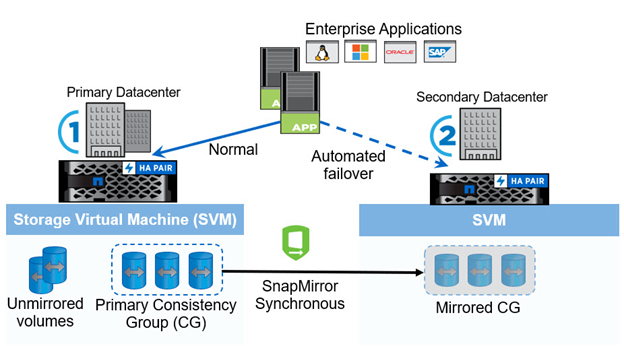
ONTAP 9.8 以降では、 NetApp SM-BC を使用して、 SAN ワークロードを保護して透過的なアプリケーションフェイルオーバーを実現できます。データレプリケーション用に 2 つの AFF クラスタ間または 2 つの ASA クラスタ間に整合グループ関係を作成することで、 RPO をゼロ、 RTO をほぼゼロにすることができます。
SM-BC 解決策 は、 IP ネットワーク上で SnapMirror Synchronous テクノロジを使用してデータを複製します。アプリケーションレベルのきめ細かさと自動フェイルオーバー機能を提供し、 iSCSI または FC プロトコルベースの SAN LUN を使用して、 Microsoft SQL Server や Oracle などのビジネスクリティカルなデータサービスを保護します。3 番目のサイトに導入された ONTAP メディエーターは、 SM-BC 解決策 を監視し、サイト障害時の自動フェイルオーバーを有効にします。
整合グループ( CG )は、アプリケーションワークロードに対して書き込み順序の整合性が保証される FlexVol ボリュームの集まりで、ビジネス継続性のために保護する必要があります。一度に複数のボリュームについて、 crash-consistent Snapshot コピーを同時に作成できます。SnapMirror 関係は、 CG 関係とも呼ばれ、ソース CG とデスティネーション CG の間に確立されます。CG に属するボリュームグループを、アプリケーションインスタンス、アプリケーションインスタンスのグループ、または解決策 全体にマッピングできます。また、ビジネス要件や変更に基づいて、 SM-BC 整合グループ関係をオンデマンドで作成または削除できます。
次の図に示すように、整合グループ内のデータは、ディザスタリカバリとビジネス継続性のために 2 つ目の ONTAP クラスタにレプリケートされます。アプリケーションは両方の ONTAP クラスタ内の LUN に接続されています。通常はプライマリクラスタが I/O を処理し、プライマリで災害が発生するとセカンダリクラスタから自動的に再開します。SM-BC 解決策 を設計する場合は、サポートされる制限を超えないように、 CG 関係でサポートされるオブジェクト数(最大 20 個の CG 、最大 200 個のエンドポイントなど)を確認する必要があります。