

解決策 の検証済みのシナリオ
 変更を提案
変更を提案
FlexPod Datacenter SM-BC 解決策 は、さまざまな単一点障害のシナリオやサイト障害に対するデータサービスを保護します。各サイトに実装された冗長設計は高可用性を提供し、サイト間で同期データレプリケーションを行う SM-BC 実装は、サイト規模の災害からデータサービスを保護します。導入した解決策 は、目的の解決策 機能や、解決策 が保護対象として設計されたさまざまな障害シナリオに対して検証されます。
解決策 関数の検証
解決策 の機能を検証し、部分的および完全なサイト障害シナリオをシミュレートするために、さまざまなテストケースが使用されます。シスコ検証済み設計プログラムの既存の FlexPod データセンターソリューションですでに実行されているテストで重複を最小限に抑えるため、このレポートでは、解決策 の SM-BC 関連の側面に焦点を当てています。実践者が実装検証に使用する一般的な FlexPod 検証が含まれています。
解決策 の検証では、両方のサイトのすべての ESXi ホストに、 ESXi ホストごとに 1 台の Windows 10 仮想マシンが作成されました。IOMeter ツールがインストールされ、共有ローカル iSCSI データストアからマッピングされた 2 つの仮想データディスクへの I/O を生成するために使用されました。IOMeter ワークロードパラメータは、 8 KB の I/O 、 75% の読み取り、 50% のランダムで、各データディスクに 8 つの未処理 I/O コマンドを設定しました。実行されたテストシナリオのほとんどでは、 IOMeter I/O の継続は、シナリオがデータサービスの停止を原因 しなかったことを示すものです。
SM-BC はデータベース・サーバなどのビジネス・アプリケーションにとって重要であるため ' Windows Server 2022 仮想マシン上の Microsoft SQL Server 2019 インスタンスもテストの一環として提供されました。ローカルサイトのストレージが使用できず、アプリケーションがない状態でリモートサイトのストレージでデータサービスが再開される場合に、アプリケーションの実行が継続されることを確認しました 中断:
ESXi ホスト iSCSI SAN ブートテスト
解決策 内の ESXi ホストは、 iSCSI SAN からブートするように設定されます。SAN ブートを使用すると、サーバを交換する際のサーバ管理が簡素化されます。これは、サーバのサービスプロファイルを新しいサーバに関連付けて、サーバが起動するために追加の設定変更を行う必要がないためです。
サイトにある ESXi ホストをローカルの iSCSI ブート LUN からブートする以外に、ローカルのストレージコントローラがテイクオーバー状態のときやローカルのストレージクラスタが完全に使用できないときに ESXi ホストをブートするテストも実施しました。これらの検証シナリオでは、 ESXi ホストが設計に従って適切に構成されており、ストレージのメンテナンス時やディザスタリカバリの際にブートしてビジネス継続性を実現できることを確認します。
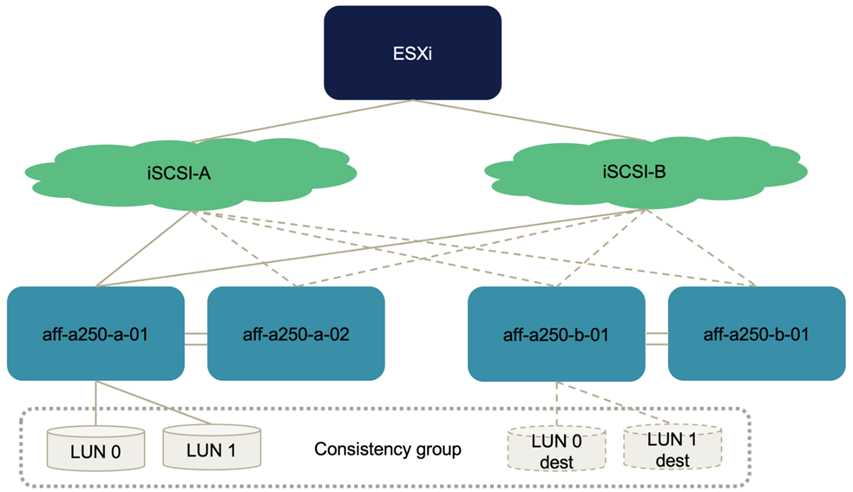
SM-BC 整合グループ関係を設定する前に、ストレージコントローラ HA ペアでホストされる iSCSI LUN には、ベストプラクティスの実装に基づいて、各 iSCSI ファブリックに 2 つずつ、合計 4 つのパスがあります。ホストは、 2 つの iSCSI VLAN / ファブリック経由で LUN にアクセスでき、 LUN ホスティングコントローラやコントローラのハイアベイラビリティパートナー経由で LUN にアクセスできます。
SM-BC 整合グループ関係を設定し、ミラーリングされた LUN をイニシエータに適切にマッピングすると、 LUN のパス数は 2 倍になります。この実装では、 2 つのアクティブ / 最適化パスと 2 つのアクティブ / 非最適化パスがあることから、 2 つのアクティブ / 最適化パスと 6 つのアクティブ / 非最適化パスがあることになります。
次の図は、 LUN 0 など、 ESXi ホストから LUN にアクセスするためのパスを示しています。LUN はサイト A のコントローラ 01 に接続されているため、そのコントローラを介して LUN に直接アクセスする 2 つのパスのみがアクティブ / 最適化され、残りの 6 つのパスはすべてアクティブ / 非最適化されます。
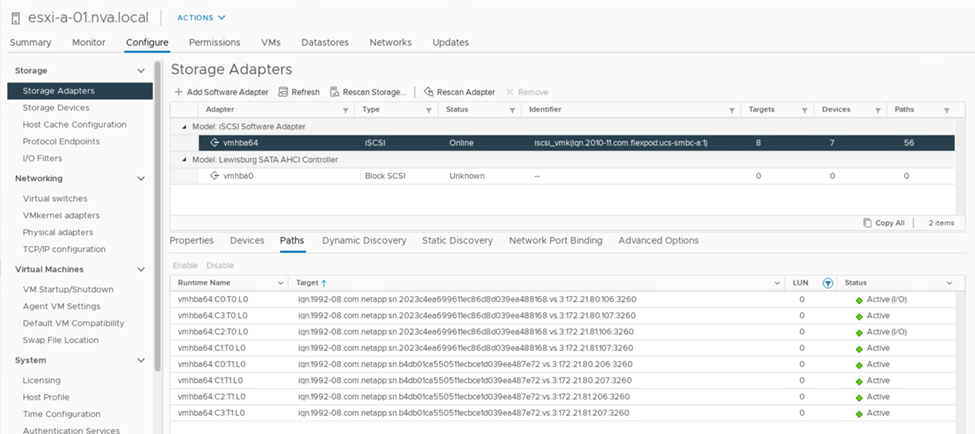
次のスクリーンショットは、 ESXi ホストが 2 種類のデバイスパスを認識する方法を示しています。2 つのアクティブ / 最適化されたパスは ' アクティブ (I/O) パスステータスであると表示されます一方 ' アクティブ / 非最適化パスはアクティブパスとしてのみ表示されますまた、 Target 列には、ターゲットに到達するための 2 つの iSCSI ターゲットとそれぞれの iSCSI LIF の IP アドレスが表示されます。
メンテナンスやアップグレードのために一方のストレージコントローラが停止した場合、停止しているコントローラに到達する 2 つのパスは使用できなくなり、パスステータスが「 dead 」と表示されます。
手動フェイルオーバーテストまたは自動ディザスタフェイルオーバーのために、プライマリストレージクラスタで整合性グループのフェイルオーバーが発生した場合、セカンダリストレージクラスタは引き続き、 SM-BC 整合グループ内の LUN にデータサービスを提供します。LUN ID が保持され、データが同期的にレプリケートされているため、 SM-BC 整合グループで保護された ESXi ホストブート LUN は、すべてリモートストレージクラスタから引き続き使用できます。
VMware vMotion と VM とホストのアフィニティテスト
汎用の FlexPod VMware Datacenter 解決策 は、 FC 、 iSCSI 、 NVMe 、 NFS などのマルチプロトコルをサポートしていますが、 FlexPod SM-BC 解決策 機能は、一般にビジネスクリティカルなソリューションに使用される FC および iSCSI SAN プロトコルをサポートしています。この検証で使用されるのは、 iSCSI プロトコルベースのデータストアと iSCSI SAN ブートのみです。
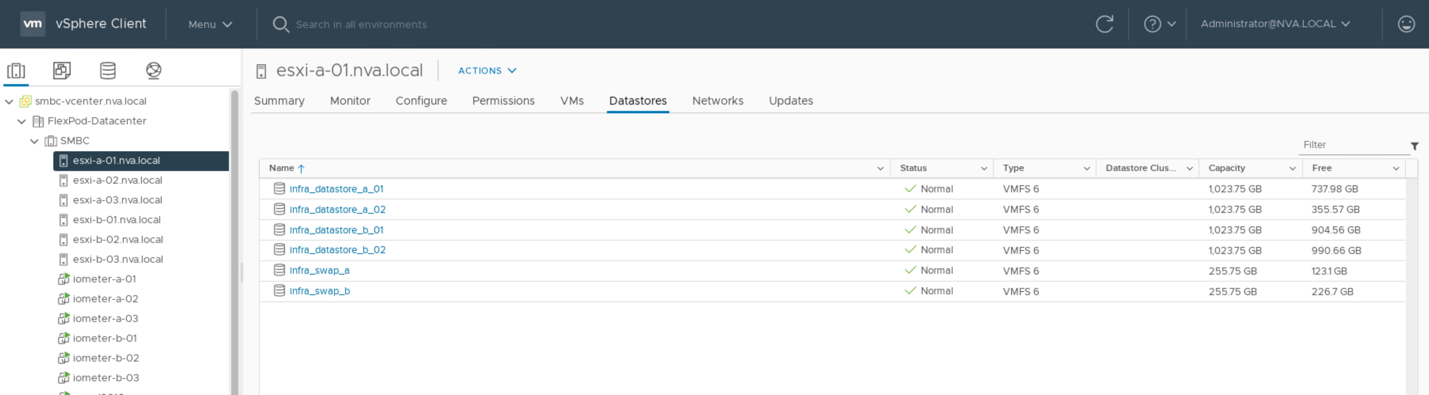
いずれかの SM-BC サイトのストレージサービスを仮想マシンで使用できるようにするには、 2 つのサイト間で仮想マシンを移行したり、災害時のフェイルオーバー・シナリオに備えて、両方のサイトの iSCSI データストアをクラスタ内のすべてのホストにマウントする必要があります。
サイト間での SM-BC 整合グループ保護を必要としない仮想インフラ上で実行されるアプリケーションの場合は、 NFS プロトコルと NFS データストアも使用できます。その場合、ビジネス継続性を確保するために、ビジネスクリティカルなアプリケーションが SM-BC 整合グループで保護された SAN データストアを適切に使用しているように、 VM にストレージを割り当てるときは注意が必要です。
次のスクリーンショットは、両方のサイトの iSCSI データストアをマウントするようにホストが設定されていることを示しています。
次の図に示すように、両方のサイトの使用可能な iSCSI データストア間で仮想マシンディスクを移行することもできます。パフォーマンスに関する考慮事項としては、ディスク I/O レイテンシを低減するために、ローカルストレージクラスタのストレージを使用する仮想マシンを用意することを推奨します。これは、 2 つのサイトが距離を隔てた場所にある場合に特に該当します。これは、距離が 100km ごとに約 1 ミリ秒という物理的なラウンドトリップ距離によるレイテンシによるものです。
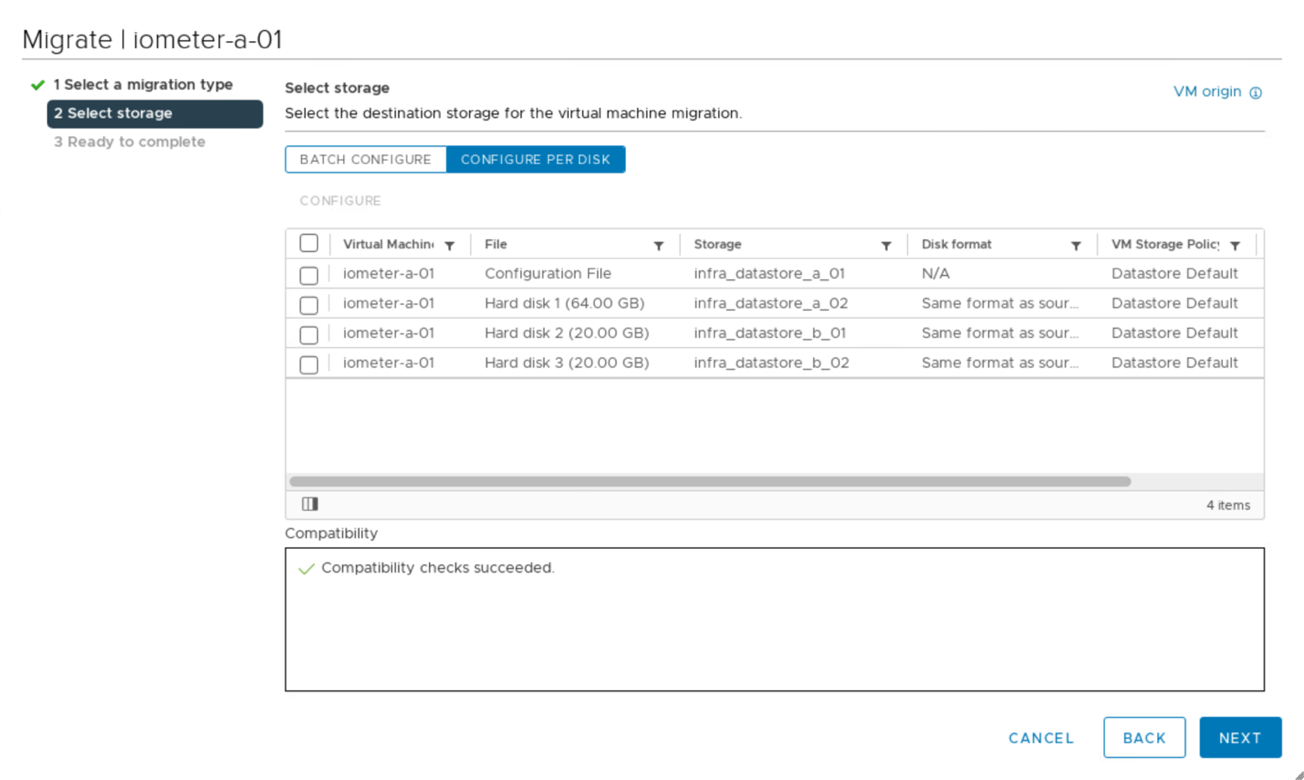
同じサイトにある別のホスト、およびサイト間で仮想マシンの vMotion をテストし、正常に実行された。サイト間で仮想マシンを手動で移行すると、 VM とホストのアフィニティルールがアクティブになり、仮想マシンが通常の状態にあるグループに移行されます。
ストレージのフェイルオーバーを計画
ストレージフェイルオーバー後に解決策 が適切に機能しているかどうかを確認するには、初期設定後に解決策 で計画的なストレージフェイルオーバー処理を実行する必要があります。このテストは、 I/O の停止を招く可能性のある接続や構成の問題を特定するのに役立ちます。接続や設定の問題を定期的にテストして解決することで、実際のサイトで障害が発生してもデータサービスを中断なく提供できます。計画的ストレージフェイルオーバーは、スケジュールされたストレージメンテナンスアクティビティの前にも使用できます。これにより、影響を受けないサイトからデータサービスを提供できます。
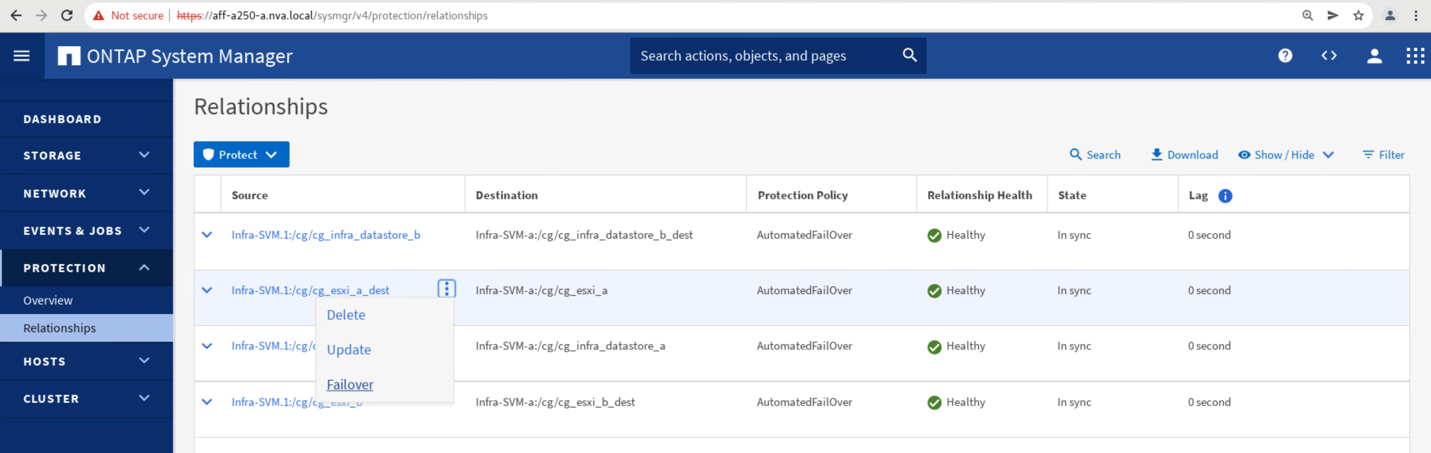
サイト A のストレージデータサービスをサイト B に手動でフェイルオーバーするには、サイト B の ONTAP システムマネージャを使用して処理を実行します。
-
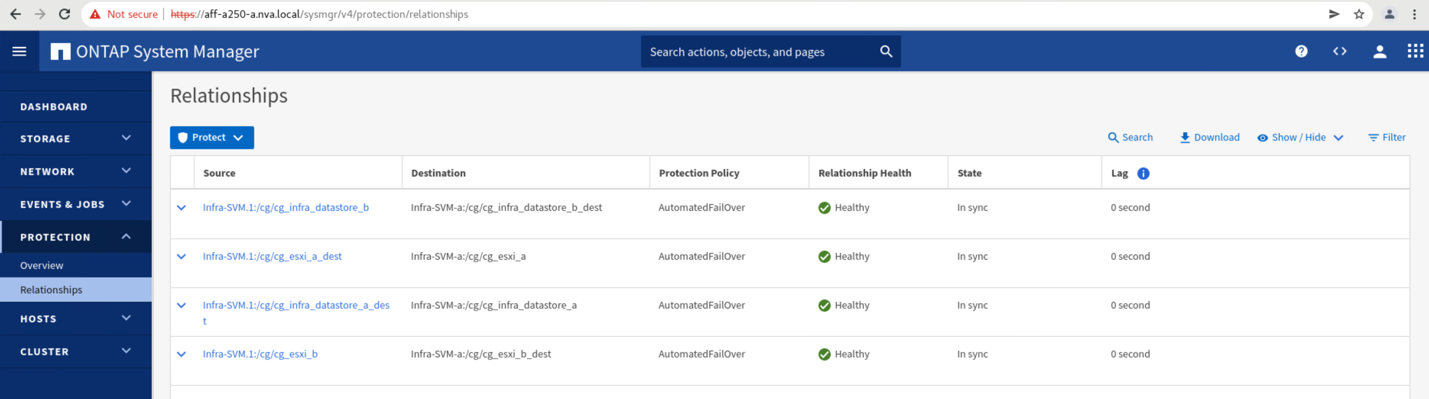
Protection > Relationships 画面に移動して ' コンシステンシ・グループの関係状態が In Sync' であることを確認しますまだ「同期中」状態の場合は、状態が「同期中」になるまで待ってからフェイルオーバーを実行します。
-
ソース名の横にあるドットを展開し、フェイルオーバーをクリックします。
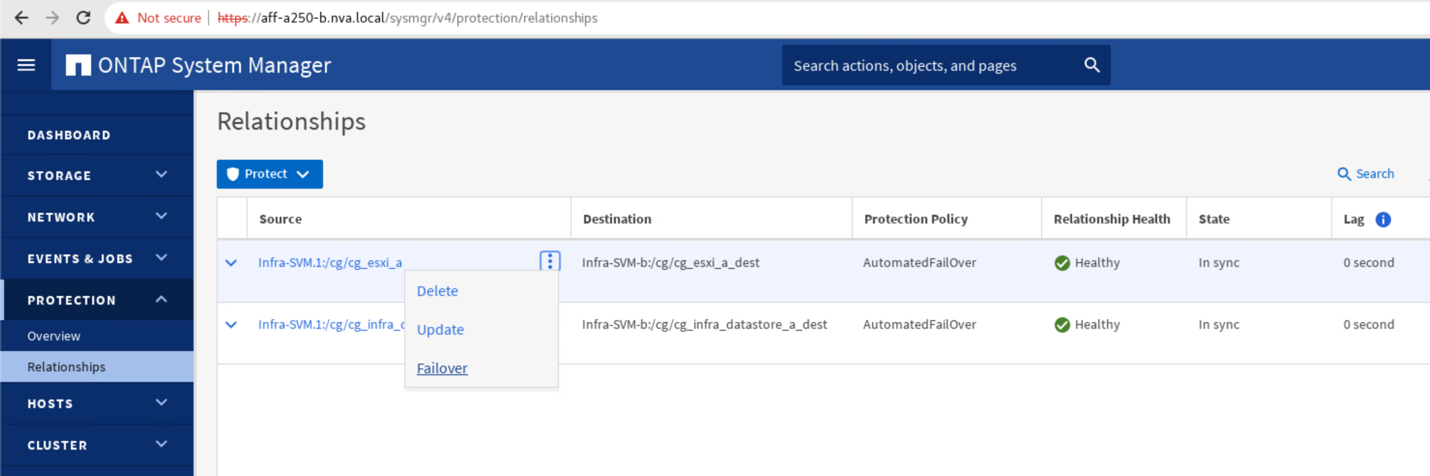
-
処理を開始するには、フェイルオーバーを確認してください。
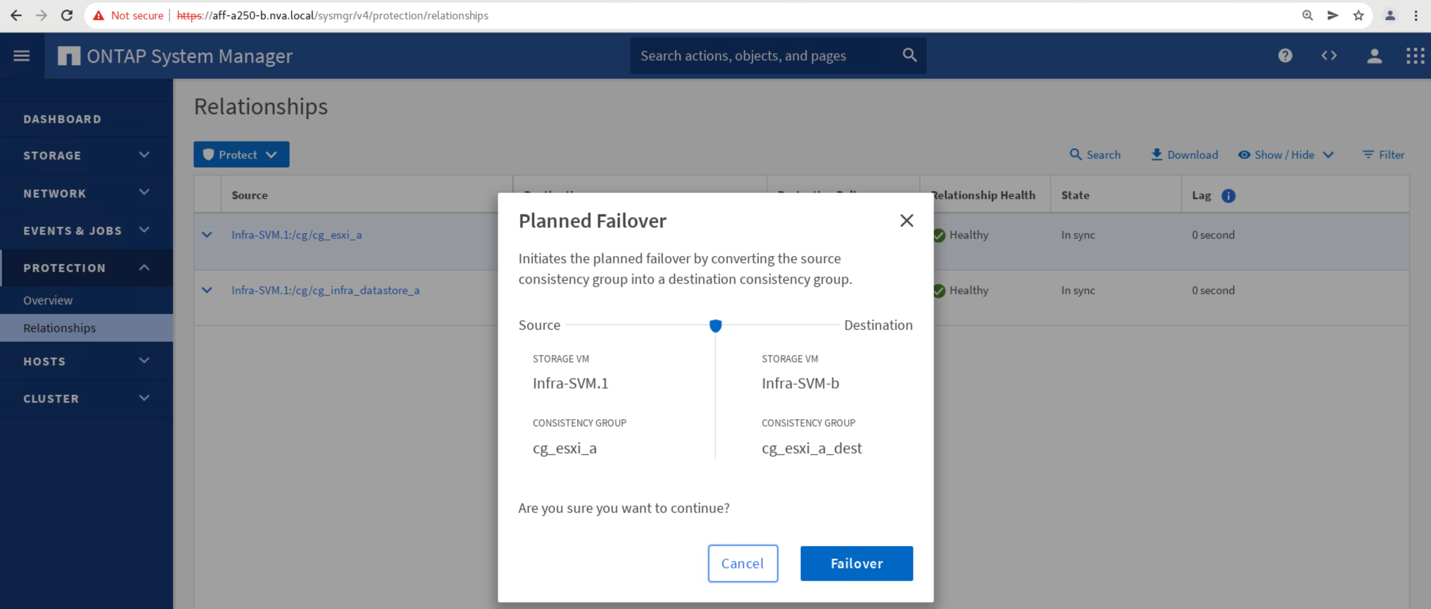
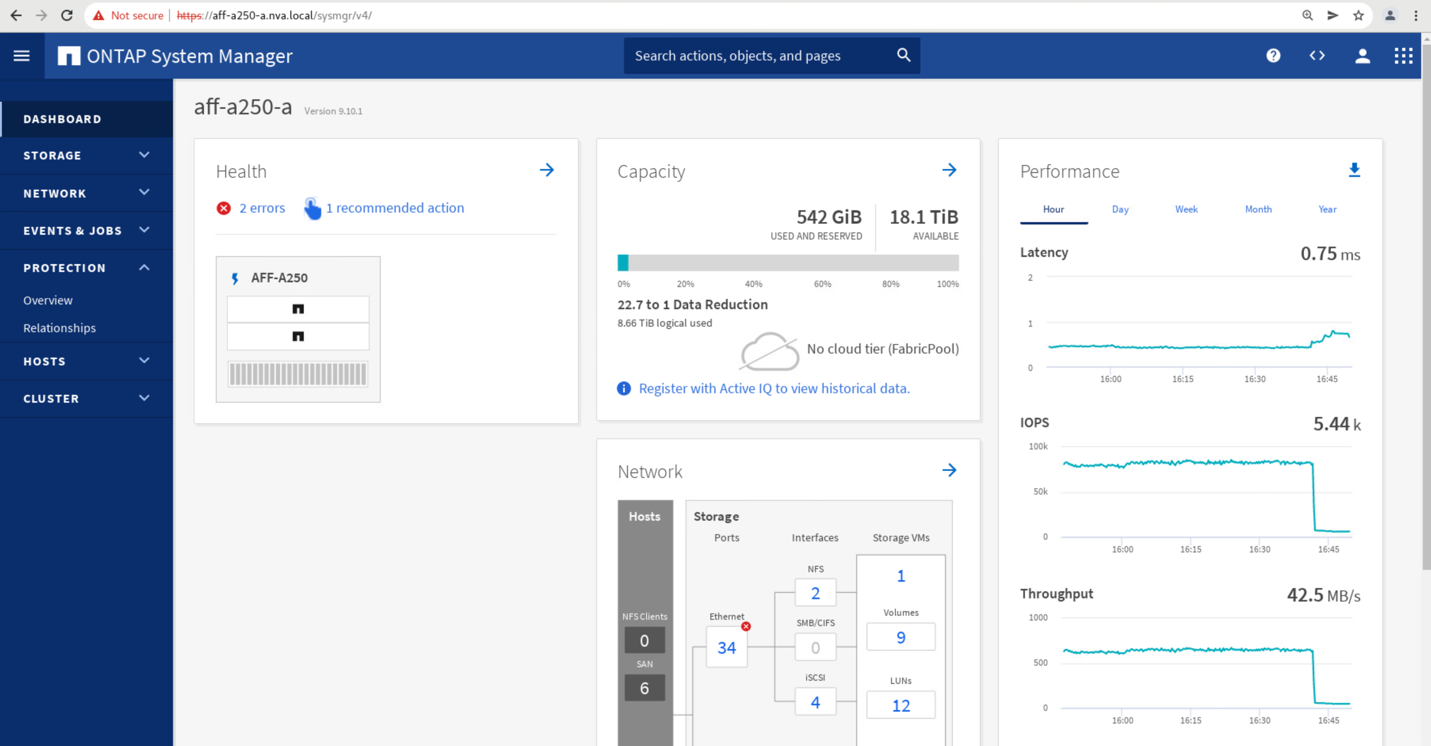
2 つのコンシステンシグループ「 cg_esxi_a 」および「 cg_infra_datastore_a 」のフェイルオーバーがサイト B の System Manager GUI で開始された直後に、これら 2 つのコンシステンシグループを処理するサイト A の I/O がサイト B に移動されましたそのため、サイト A の System Manager のパフォーマンスペインでは、サイト A の I/O が大幅に削減されました。
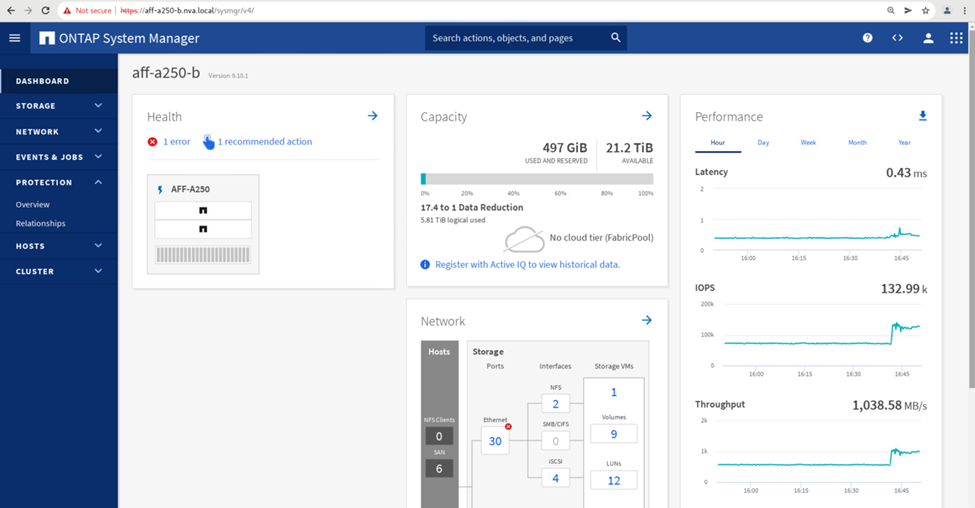
一方、サイト B の System Manager ダッシュボードの Performance ペインでは、サイト A から約 130K IOPS に移動された追加の I/O を処理するため、 IOPS が大幅に増加しています。 1 ミリ秒未満の I/O レイテンシを維持したまま、約 1GB/s のスループットを実現しました。
I/O をサイト A からサイト B に透過的に移行することで、計画的なメンテナンスのためにサイト A のストレージコントローラを停止できるようになります。メンテナンス作業またはテストが完了し ' サイト A のストレージ・クラスタが稼働状態に戻ったら ' フェイルオーバーを実行してサイト B からサイト A へのフェイルオーバー I/O を返す前に ' コンシステンシ・グループの保護状態が同期状態に戻るまでチェックして待機しますメンテナンスまたはテストのためにサイトが停止される時間が長くなると ' データが同期されるまでの時間が長くなり ' コンシステンシ・グループは同期状態に戻ります
ストレージの計画外フェイルオーバー
実際に災害が発生した場合や災害シミュレーション中に、計画外のストレージフェイルオーバーが発生することがあります。たとえば、次の図では、サイト A のストレージシステムで停電が発生し、計画外のストレージフェイルオーバーがトリガーされたあと、サイト A の LUN が SM-BC 関係で保護されている場合、サイト B から続行します
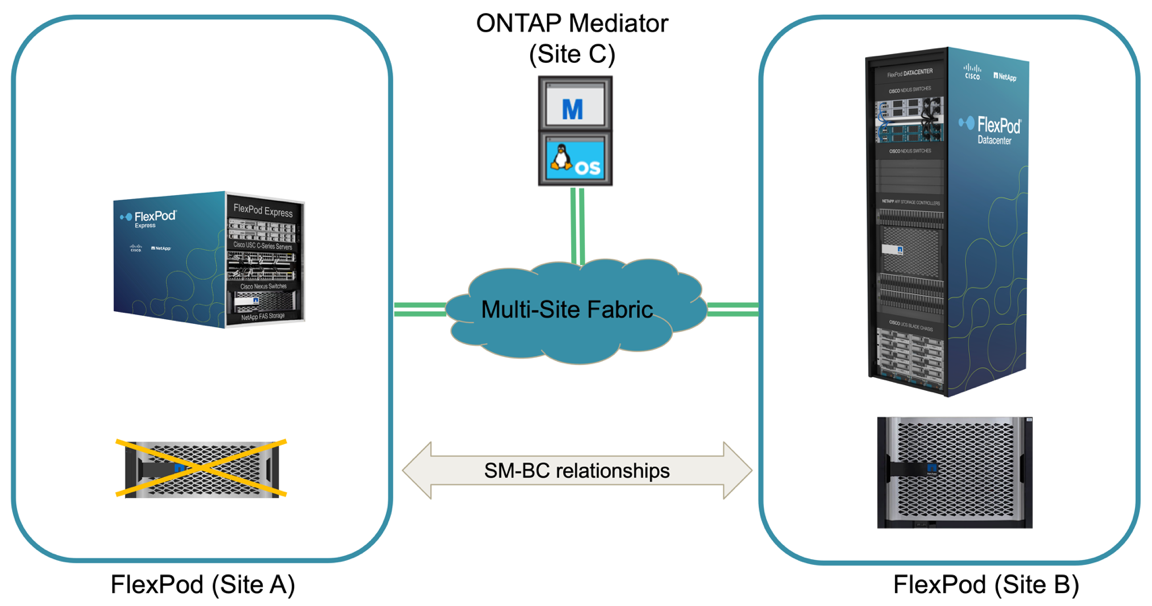
サイト A でストレージ災害をシミュレートするために、サイト A の両方のストレージコントローラの電源スイッチを物理的にオフにしてコントローラへの電源供給を停止することで、両方のコントローラの電源をオフにできます。 または、ストレージコントローラのサービスプロセッサの system power management コマンドを使用してコントローラの電源をオフにします。
サイト A のストレージクラスタが電力を喪失した場合は、サイト A のストレージクラスタが提供するデータサービスが突然停止します。次に、第 3 のサイトから SM-BC 解決策 を監視する ONTAP メディエーターが、サイト A のストレージ障害状態を検出し、 SM-BC 解決策 で自動計画外フェイルオーバーを実行できるようにします。これにより、サイト B のストレージコントローラは、サイト A との SM-BC 整合グループ関係で設定された LUN のデータサービスを継続できます
アプリケーション側では、オペレーティングシステムが LUN のパスステータスを確認し、稼働しているサイト B のストレージコントローラへの利用可能なパスで I/O を再開する間、データサービスは一時的に停止します。
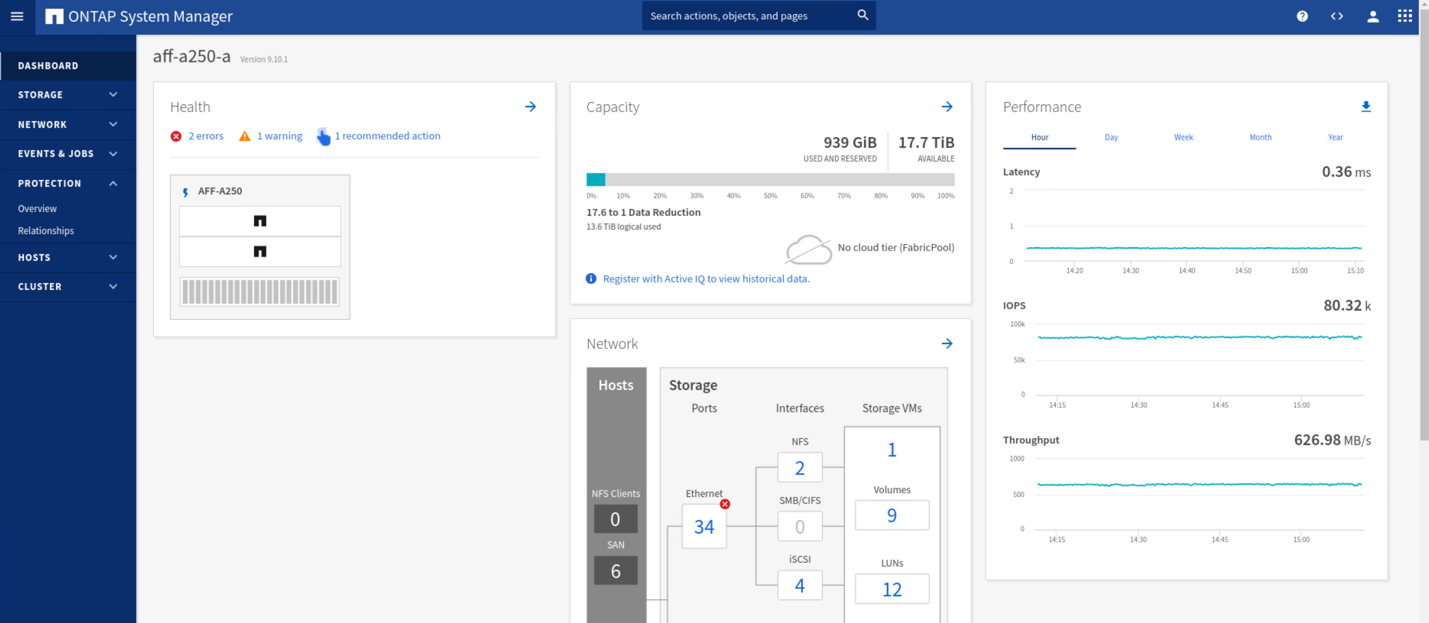
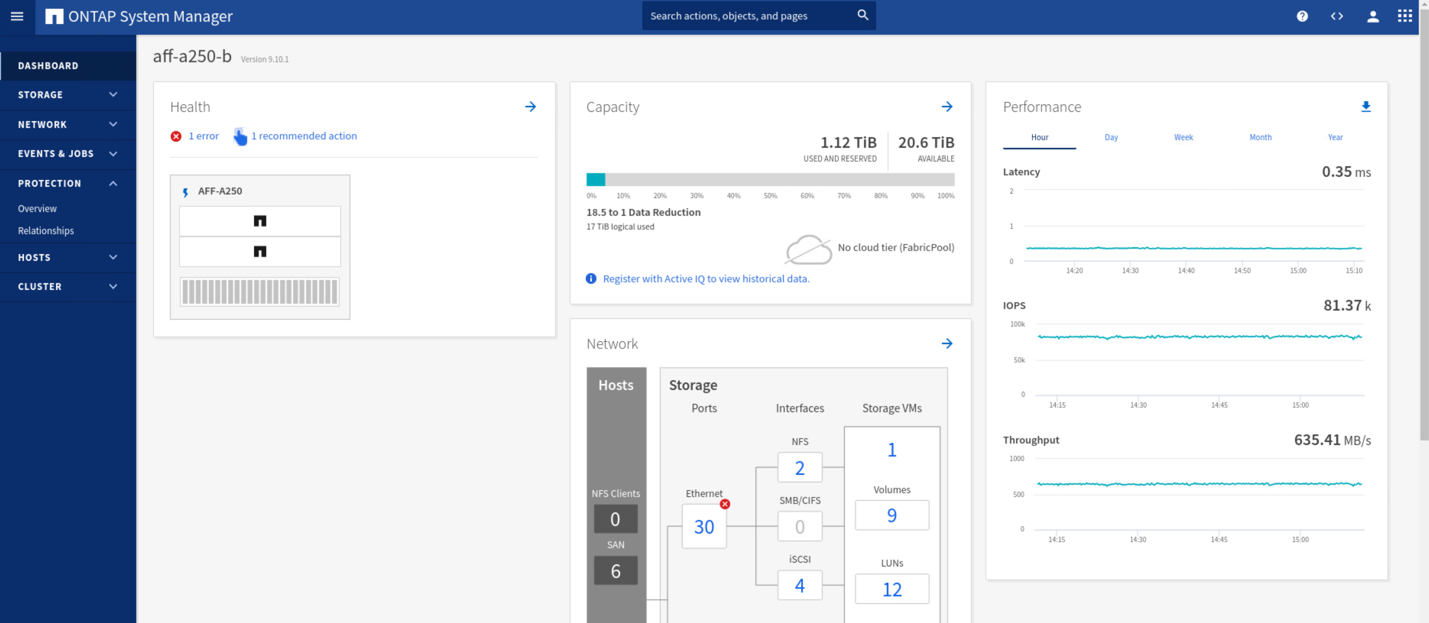
検証テストでは、両方のサイトの VM の IOMeter ツールがローカルデータストアへの I/O を生成します。サイト A のクラスタの電源をオフにすると、 I/O が一時停止してから再開されます。災害発生前は、サイト A とサイト B のストレージクラスタのダッシュボードについて、次の 2 つの図をそれぞれ参照してください。各サイトでの約 80 、 000 IOPS と 600 MB/ 秒のスループットを示しています。
サイト A のストレージコントローラの電源をオフにしたあと、サイト A に代わって追加のデータサービスを提供するために、サイト B のストレージコントローラの I/O が大幅に増加したことを視覚的に確認できます(次の図を参照)。また、 IOMeter VM の GUI には、サイト A のストレージクラスタが停止しても I/O が継続することが示されました。SM-BC 関係で保護されていない LUN から作成されたデータストアがほかにもある場合、ストレージ災害の発生時にこれらのデータストアにアクセスできなくなります。そのため、さまざまなアプリケーションデータのビジネスニーズを評価し、ビジネス継続性を確保するために、 SM-BC 関係で保護されたデータストアに適切に配置することが重要です。
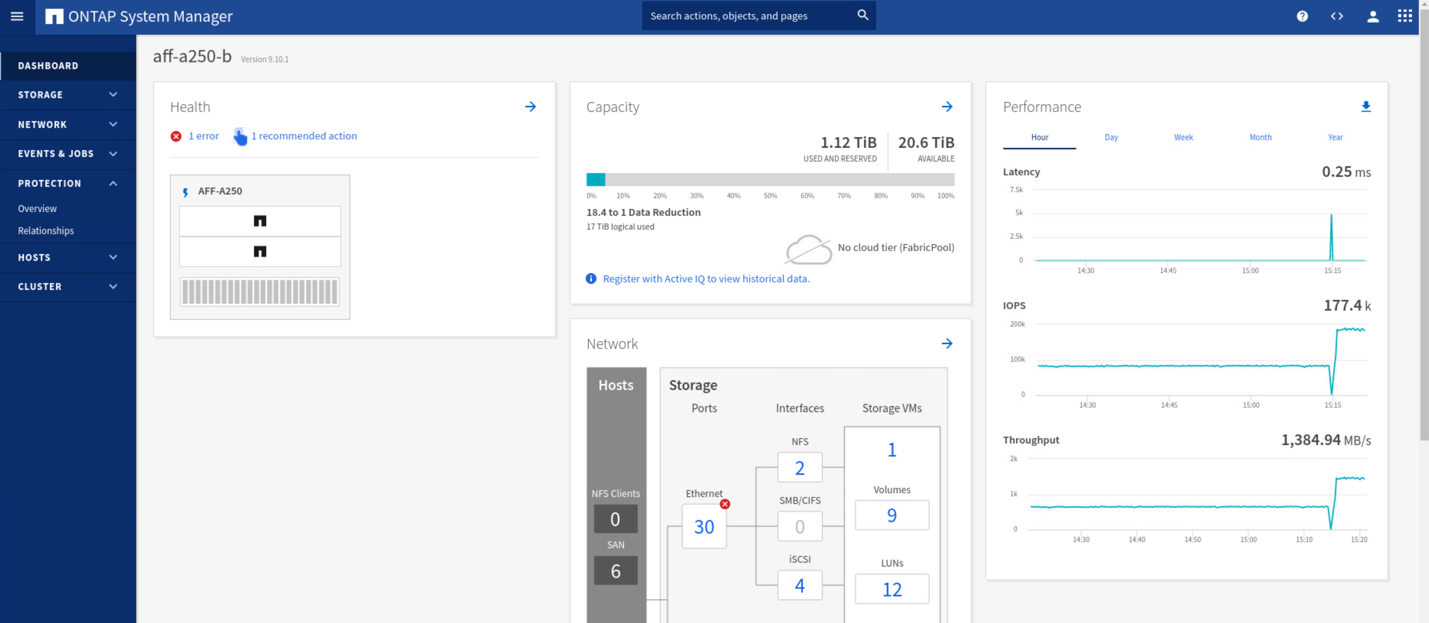
次の図に示すように ' サイト A のクラスタがダウンしている間 ' 整合性のあるグループの関係のステータスは非同期状態になりますサイト A のストレージコントローラの電源をオンに戻すと、ストレージクラスタがブートし、サイト A とサイト B の間のデータ同期が自動的に実行されます。
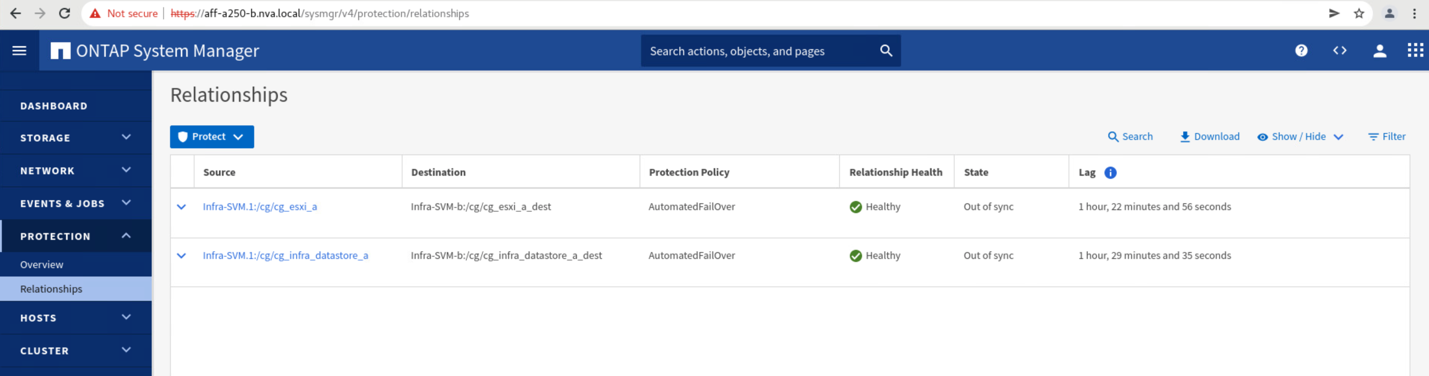
サイト B からサイト A にデータサービスを戻す前に、サイト A の System Manager を調べて、 SM-BC 関係がキャッチされ、ステータスが同期されていることを確認する必要があります。整合グループが同期されていることを確認したら、手動のフェイルオーバー処理を開始して、整合グループ関係のデータサービスをサイト A に戻すことができます
サイトのメンテナンスやサイト障害が発生したときの対処
サイトのメンテナンスや停電が発生したり、ハリケーンや地震などの自然災害によって影響が及ぶ可能性があります。そのため、計画的および計画外のサイト障害シナリオを実施して、 FlexPod SM-BC 解決策 が、ビジネスクリティカルなすべてのアプリケーションおよびデータサービスでこのような障害が発生しても運用を継続できるように適切に設定されていることを確認することが重要です。検証されたサイト関連のシナリオは次のとおりです。
-
仮想マシンと重要なデータサービスをもう一方のサイトに移行することで、サイトの計画的なメンテナンスシナリオを実施します
-
ディザスタシミュレーション用にサーバとストレージコントローラの電源をオフにして、サイトが計画外停止になる状況です
サイトを計画的なサイトメンテナンスにするには、影響を受けた仮想マシンを vMotion と組み合わせてサイトから移行し、 SM-BC 整合グループ関係を手動でフェイルオーバーして、仮想マシンと重要なデータサービスを代替サイトに移行する必要があります。テストは、まず vMotion 、次に SM-BC フェイルオーバーと SM-BC フェイルオーバー、続いて vMotion という 2 つの順序で実行され、仮想マシンが引き続き実行され、データサービスが中断されないことを確認します。
計画的な移行を実行する前に、 VM とホストのアフィニティルールを更新して、サイトで現在実行されている VM がメンテナンス中のサイトから自動的に移行されるようにします。次のスクリーンショットは、サイト A の VM とホストのアフィニティルールを変更し、サイト A からサイト B に VM を自動的に移行する例を示しています。VM をサイト B で実行するように指定する代わりに、アフィニティルールを一時的に無効にして VM を手動で移行することもできます。
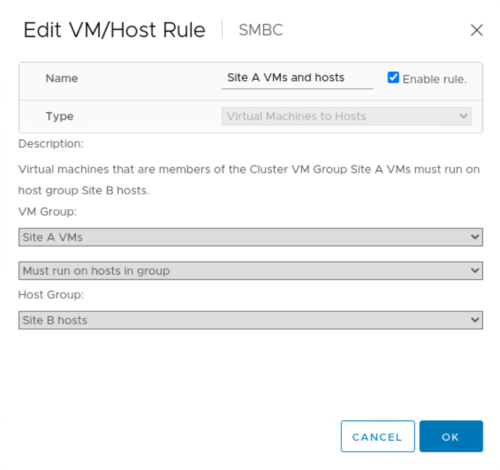
仮想マシンとストレージサービスの移行が完了したら、サーバ、ストレージコントローラ、ディスクシェルフ、およびスイッチの電源をオフにし、必要なサイトのメンテナンス作業を実行できます。サイトのメンテナンスが完了し、 FlexPod インスタンスが稼働状態に戻ったら、 VM のホストグループのアフィニティを変更して元のサイトに戻すことができます。その後、「グループ内のホストで実行する必要があります」 VM/ ホストサイトアフィニティルールを「グループ内のホストで実行する必要があります」に戻して、災害が発生した場合に、他のサイトのホストで仮想マシンを実行できるようにします。検証テストでは、すべての仮想マシンがもう一方のサイトに正常に移行され、データサービスは SM-BC 関係のフェイルオーバーの実行後も問題なく継続されました。
計画外のサイトディザスタシミュレーションでは、サイト障害をシミュレーションするためにサーバとストレージコントローラの電源をオフにしました。VMware HA 機能は、停止した仮想マシンを検出し、サバイバーサイトでその仮想マシンを再起動します。さらに、第 3 のサイトで実行されている ONTAP メディエーターでサイト障害が検出されると、サバイバーサイトがフェイルオーバーを開始して、想定どおりに停止しているサイトのデータサービスの提供を開始します。
次のスクリーンショットは、ストレージコントローラのサービスプロセッサ CLI を使用して、サイト A のストレージ障害をシミュレートするために、クラスターの電源を突然オフにしたことを示しています。
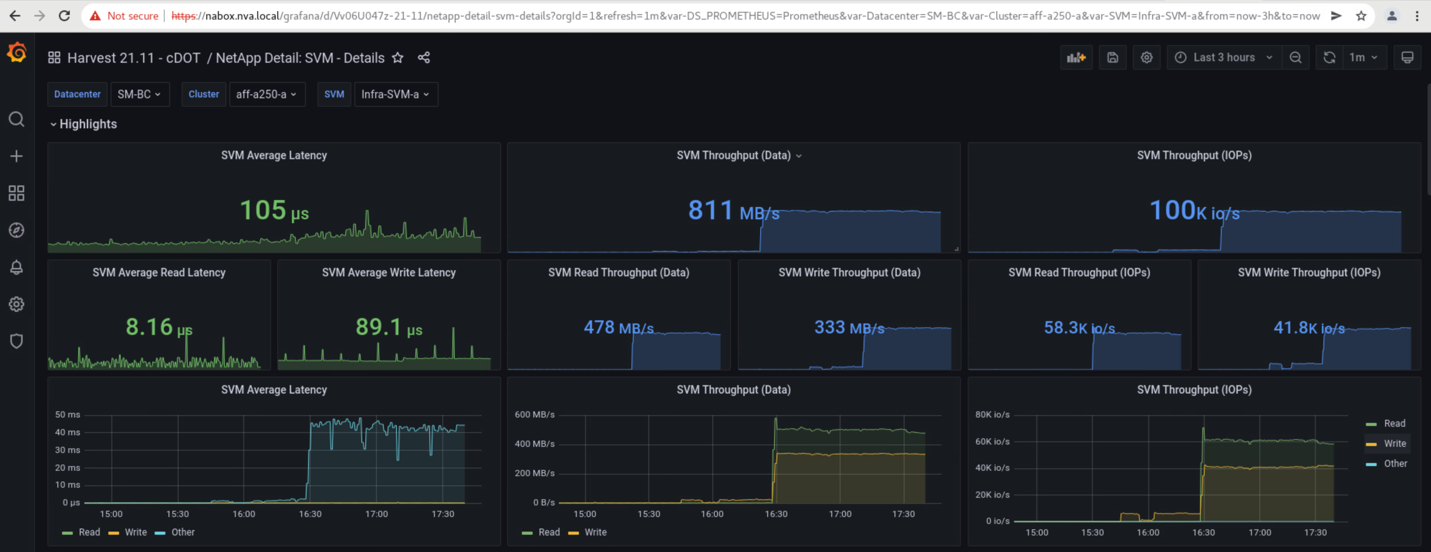
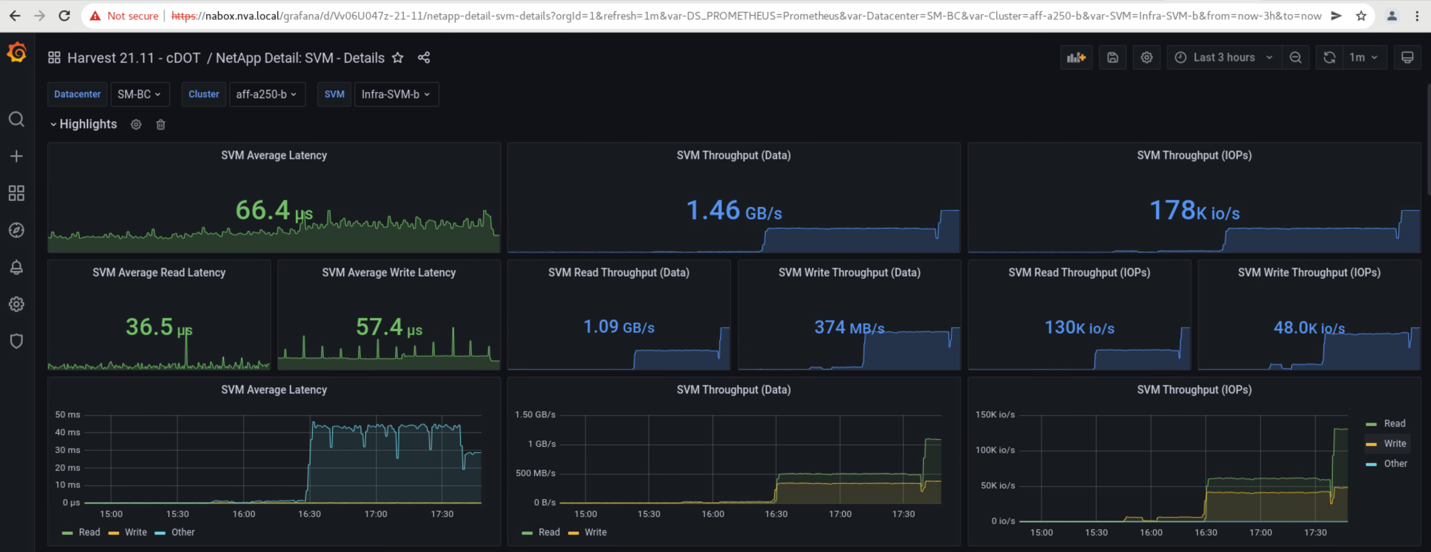
NetApp Harvest データ収集ツールでキャプチャされ、 NAbox 監視ツールで Grafana ダッシュボードに表示されるストレージクラスタの Storage Virtual Machine ダッシュボードは、次の 2 つのスクリーンショットで示されています。IOPS グラフとスループットグラフの右側にあるように、サイト B のクラスタは、サイト A のクラスタが停止したあとすぐにクラスタ A のストレージワークロードを取得します。
Microsoft SQL Server の場合
Microsoft SQL Server は、エンタープライズ IT に広く採用され、導入されているデータベースプラットフォームです。Microsoft SQL Server 2019 リリースでは、リレーショナルエンジンと分析エンジンに多数の新機能と機能拡張が導入されています。オンプレミス、クラウド、ハイブリッド環境で実行されているアプリケーションのワークロードをサポートし、この 2 つを組み合わせて使用できます。また、 Windows 、 Linux 、コンテナなど、複数のプラットフォームに導入することもできます。
FlexPod SM-BC 解決策 のビジネスクリティカルなワークロード検証の一環として、 Windows Server 2022 VM にインストールされた Microsoft SQL Server 2019 が、 SM-BC が計画的および計画外のストレージフェイルオーバーテスト用の IOMeter VM に含まれています。Windows Server 2022 VM に SQL Server Management Studio をインストールして、 SQL Server を管理します。テストには、 HammerDB データベースツールを使用してデータベーストランザクションが生成されます。
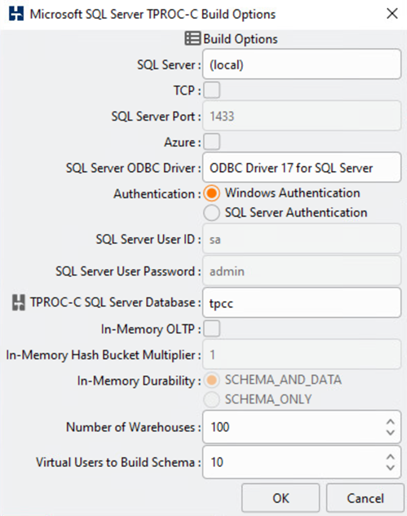
HammerDB データベーステストツールは、 Microsoft SQL Server TPROC-C ワークロードでのテスト用に設定されました。スキーマビルドの構成では、次のスクリーンショットに示すように、オプションが更新され、 10 人の仮想ユーザを持つ 100 個のウェアハウスが使用されるようになりました。
スキーマビルドオプションが更新された後、スキーマビルドプロセスが開始されました。数分後に、 system processor CLI コマンドを使用して、 2 ノード AFF A250 ストレージクラスタの両方のノードの電源をほぼ同時にオフにすることで、サイト B の予期しないシミュレートのストレージクラスタ障害が導入されました。
データベーストランザクションが短時間中断されると、災害対策の自動フェイルオーバーが開始され、トランザクションが再開されます。次のスクリーンショットは、 HammerDB トランザクションカウンタのスクリーンショットです。通常、 Microsoft SQL Server のデータベースはサイト B のストレージクラスタにあるため、サイト B のストレージが停止したときにトランザクションが一時停止され、自動フェイルオーバーの発生後に再開されます。
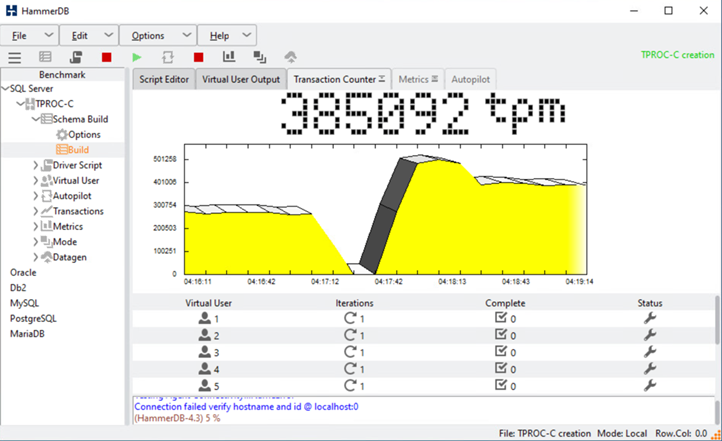
ストレージクラスタの指標は、 NetApp Harvest 監視ツールがインストールされた NAbox ツールを使用して収集しました。結果は、 Storage Virtual Machine とその他のストレージオブジェクトに対応した事前定義された Grafana ダッシュボードに表示されます。このダッシュボードでは、レイテンシ、スループット、 IOPS 、およびその他の詳細情報が、サイト B とサイト A の両方で分けて表示されます
このスクリーンショットは、サイト B のストレージクラスタ用の NABox Grafana パフォーマンスダッシュボードを示しています。
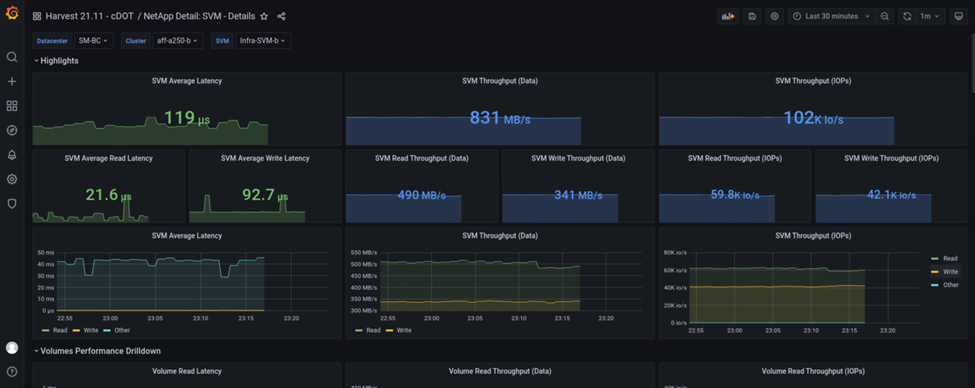
サイト B のストレージクラスタの IOPS は、災害発生前は約 10 万 IOPS でした。その後、災害によってグラフの右側にパフォーマンス指標の値が急激にゼロまで減少しました。サイト B のストレージクラスタが停止しているため、災害発生後にサイト B のクラスタから何も収集できませんでした。
一方、サイト A のストレージクラスタの IOPS は、自動フェイルオーバー後にサイト B から追加のワークロードを受け取りました。次のスクリーンショットでは、 IOPS およびスループットのグラフの右側に、追加のワークロードが簡単に表示されています。このスクリーンショットは、サイト A のストレージクラスタの NAbox Grafana パフォーマンスダッシュボードを示しています。
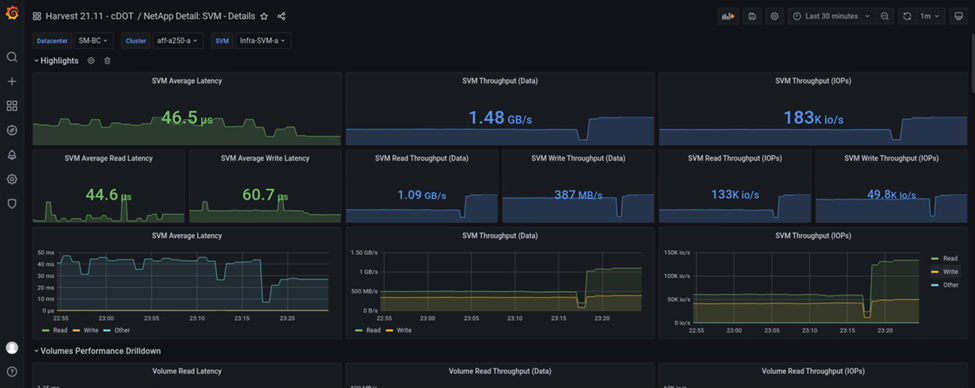
上記のストレージディザスタテストのシナリオでは、データベースが配置されたサイト B で Microsoft SQL Server ワークロードのストレージクラスタが完全に停止しても運用が継続できることが確認されました。アプリケーションは、災害の検出とフェイルオーバーの発生後、サイト A のストレージクラスタが提供するデータサービスを透過的に使用しました。
コンピューティングレイヤでは、特定のサイトで稼働している VM にホスト障害が発生すると、 VMware HA 機能によって自動的に再起動するように設計されています。サイト全体が停止した場合、 VM とホストのアフィニティルールを使用して、サバイバーサイトで VM を再起動できます。ただし、ビジネスクリティカルなアプリケーションで中断のないサービスを提供するには、アプリケーションのダウンタイムを回避するために、 Microsoft Failover Cluster や Kubernetes コンテナベースのアプリケーションアーキテクチャなどのアプリケーションベースのクラスタリングが必要です。アプリケーションベースのクラスタリングの実装については、このテクニカルレポートでは説明していません。関連するドキュメントを参照してください。