

顧客ユースケース
 変更を提案
変更を提案
NetApp ActiveIQ のユースケース
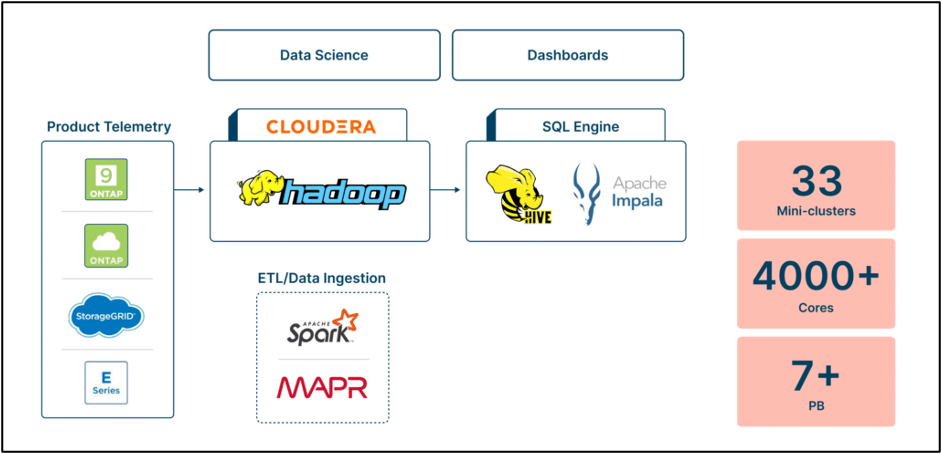
課題: 当初は多数のユースケースをサポートするために設計された NetApp 独自の社内Active IQソリューションは、社内ユーザーと顧客の両方に包括的なサービスを提供するソリューションへと進化しました。しかし、基盤となる Hadoop/MapR ベースのバックエンド インフラストラクチャでは、データの急速な増加と効率的なデータ アクセスの必要性により、コストとパフォーマンスに関する課題が生じていました。ストレージを拡張すると、不要なコンピューティング リソースが追加され、コストが増加します。
さらに、Hadoop クラスターの管理には時間がかかり、専門知識が必要でした。データのパフォーマンスと管理の問題により状況はさらに複雑になり、クエリには平均 45 分かかり、誤った構成によりリソースが不足するようになりました。これらの課題に対処するため、 NetApp は既存のレガシー Hadoop 環境に代わる手段を模索し、Dremio 上に構築された新しい最新ソリューションによってコストが削減され、ストレージとコンピューティングが分離され、パフォーマンスが向上し、データ管理が簡素化され、きめ細かな制御が可能になり、災害復旧機能も提供されると判断しました。
解決: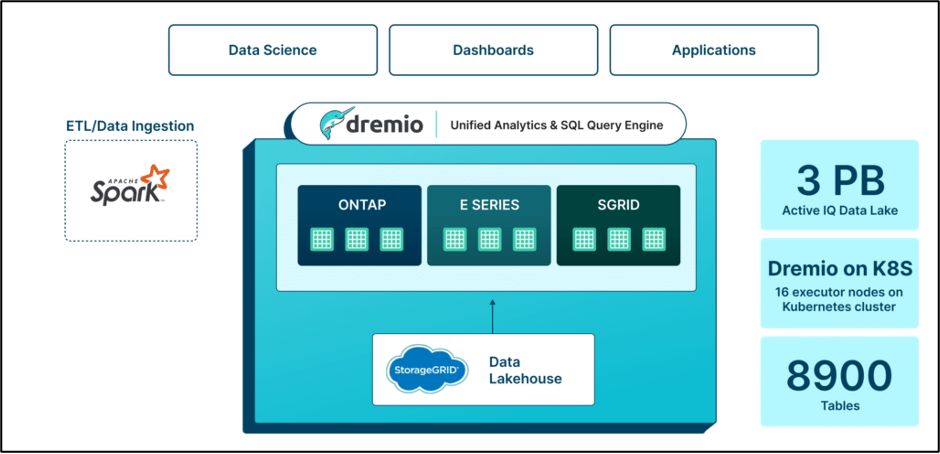 Dremio により、 NetApp は段階的なアプローチで Hadoop ベースのデータ インフラストラクチャを最新化し、統合分析のロードマップを提供できるようになりました。データ処理に大幅な変更を必要とする他のベンダーとは異なり、Dremio は既存のパイプラインとシームレスに統合し、移行時の時間と費用を節約しました。 NetApp は、完全にコンテナ化された環境に移行することで、管理オーバーヘッドを削減し、セキュリティを強化し、耐障害性を強化しました。 Dremio は、Apache Iceberg や Arrow などのオープン エコシステムを採用することで、将来性、透明性、拡張性を確保しました。
Dremio により、 NetApp は段階的なアプローチで Hadoop ベースのデータ インフラストラクチャを最新化し、統合分析のロードマップを提供できるようになりました。データ処理に大幅な変更を必要とする他のベンダーとは異なり、Dremio は既存のパイプラインとシームレスに統合し、移行時の時間と費用を節約しました。 NetApp は、完全にコンテナ化された環境に移行することで、管理オーバーヘッドを削減し、セキュリティを強化し、耐障害性を強化しました。 Dremio は、Apache Iceberg や Arrow などのオープン エコシステムを採用することで、将来性、透明性、拡張性を確保しました。
Dremio は、Hadoop/Hive インフラストラクチャの代替として、セマンティック レイヤーを通じて二次的なユース ケース向けの機能を提供しました。既存の Spark ベースの ETL およびデータ取り込みメカニズムはそのままに、Dremio は、重複のないデータの検出と探索を容易にする統合アクセス レイヤーを提供しました。このアプローチにより、データ複製係数が大幅に削減され、ストレージとコンピューティングが分離されました。
メリット: Dremio を使用することで、 NetApp はデータ環境におけるコンピューティング消費とディスク容量要件を最小限に抑え、大幅なコスト削減を実現しました。新しいActive IQデータ レイクは、3 ペタバイトのデータを保持する 8,900 個のテーブルで構成されています。以前のインフラストラクチャでは、7 ペタバイト以上でした。 Dremio への移行には、33 個のミニ クラスターと 4,000 個のコアから Kubernetes クラスター上の 16 個のエグゼキューター ノードへの移行も含まれていました。コンピューティング リソースが大幅に減少したにもかかわらず、 NetApp はパフォーマンスの顕著な向上を実現しました。 Dremio を介してデータに直接アクセスすることで、クエリの実行時間が 45 分から 2 分に短縮され、予測メンテナンスと最適化のための洞察を得るまでの時間が 95% 高速化されました。この移行により、コンピューティング コストが 60% 以上削減され、クエリが 20 倍以上高速化され、総所有コスト (TCO) が 30% 以上節約されました。
自動車部品販売の顧客ユースケース。
課題: この世界的な自動車部品販売会社では、経営陣と企業財務計画および分析グループが販売レポートの統合ビューを取得できず、個々の事業ラインの販売指標レポートを読み取って統合するしかありませんでした。その結果、顧客は少なくとも 1 日前のデータに基づいて意思決定を行うようになりました。新しい分析情報を取得するには、通常 4 週間以上かかります。データ パイプラインのトラブルシューティングにはさらに多くの時間が必要となり、すでに長いタイムラインにさらに 3 日以上が追加されます。レポート開発プロセスとレポートのパフォーマンスが遅いため、アナリスト コミュニティは、新しいビジネス インサイトを見つけたり、新しいビジネス行動を推進したりするのではなく、データの処理または読み込みが完了するまで継続的に待機する必要がありました。これらの問題のある環境は、さまざまな事業部門の多数の異なるデータベースで構成されており、多数のデータ サイロが発生していました。遅くて断片化された環境では、アナリストが単一の真実のソースではなく独自の真実を導き出す方法が多すぎるため、データ ガバナンスが複雑になりました。このアプローチでは、データ プラットフォームと人件費で 190 万ドル以上かかりました。レガシー プラットフォームを維持し、データ要求に応えるには、年間 7 人のフィールド テクニカル エンジニア (FTE) が必要でした。データ要求の増加に伴い、データ インテリジェンス チームは、将来のニーズに合わせてレガシー環境を拡張することができませんでした。
ソリューション: NetApp Object Store で大規模な Iceberg テーブルをコスト効率よく保存および管理します。 Dremio のセマンティック レイヤーを使用してデータ ドメインを構築し、ビジネス ユーザーがデータ製品を簡単に作成、検索、共有できるようにします。
顧客へのメリット: • 既存のデータアーキテクチャを改善および最適化し、洞察を得るまでの時間を4週間から数時間に短縮 • トラブルシューティング時間を3日から数時間に短縮 • データプラットフォームと管理コストを38万ドル以上削減 • 年間2 FTEのデータインテリジェンス作業を削減