

ユースケース1: Hadoopデータのバックアップ
 変更を提案
変更を提案
このシナリオでは、顧客はオンプレミスの大規模な Hadoop リポジトリを所有しており、災害復旧のためにそれをバックアップしたいと考えています。しかし、顧客の現在のバックアップ ソリューションはコストが高く、バックアップ ウィンドウが 24 時間を超える長い時間を要するという問題がありました。
要件と課題
このユースケースの主な要件と課題は次のとおりです。
-
ソフトウェアの下位互換性:
-
提案される代替バックアップ ソリューションは、実稼働 Hadoop クラスターで使用されている現在実行中のソフトウェア バージョンと互換性がある必要があります。
-
-
約束された SLA を満たすには、提案された代替ソリューションでは非常に低い RPO と RTO を実現する必要があります。
-
NetAppバックアップ ソリューションによって作成されたバックアップは、データセンターにローカルに構築された Hadoop クラスターだけでなく、リモート サイトの災害復旧場所で稼働している Hadoop クラスターでも使用できます。
-
提案されるソリューションはコスト効率がよいものでなければなりません。
-
提案されたソリューションは、バックアップ時間中に、現在実行中の本番環境の分析ジョブに対するパフォーマンスの影響を軽減する必要があります。
顧客の既存のバックアップソリューションx
下の図は、元の Hadoop ネイティブ バックアップ ソリューションを示しています。
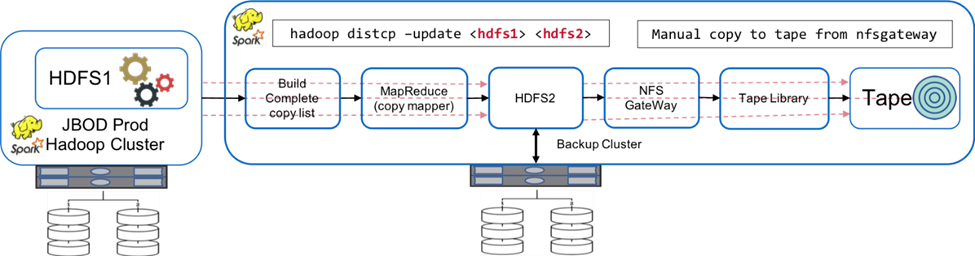
実稼働データは中間バックアップ クラスターを通じてテープに対して保護されます。
-
HDFS1のデータは、以下のコマンドを実行することでHDFS2にコピーされます。 `hadoop distcp -update <hdfs1> <hdfs2>`指示。
-
バックアップクラスタはNFSゲートウェイとして機能し、データはLinux経由で手動でテープにコピーされます。 `cp`テープライブラリを介してコマンドを実行します。
オリジナルの Hadoop ネイティブ バックアップ ソリューションの利点は次のとおりです。
-
このソリューションは Hadoop ネイティブ コマンドに基づいているため、ユーザーは新しい手順を学習する必要がありません。
-
このソリューションは、業界標準のアーキテクチャとハードウェアを活用します。
オリジナルの Hadoop ネイティブ バックアップ ソリューションの欠点は次のとおりです。
-
長いバックアップウィンドウの時間が 24 時間を超えると、運用データが脆弱になります。
-
バックアップ時間中にクラスターのパフォーマンスが大幅に低下します。
-
テープへのコピーは手動で行います。
-
バックアップ ソリューションは、必要なハードウェアと手動プロセスに必要な人的時間の点で高価です。
バックアップソリューション
これらの課題と要件に基づき、既存のバックアップ システムを考慮して、3 つのバックアップ ソリューションが提案されました。次のサブセクションでは、ソリューション A からソリューション C までの 3 つの異なるバックアップ ソリューションのそれぞれについて説明します。
解決策A
ソリューション A では、バックアップ Hadoop クラスターがセカンダリ バックアップをNetApp NFS ストレージ システムに送信するため、下の図に示すように、テープは不要になります。
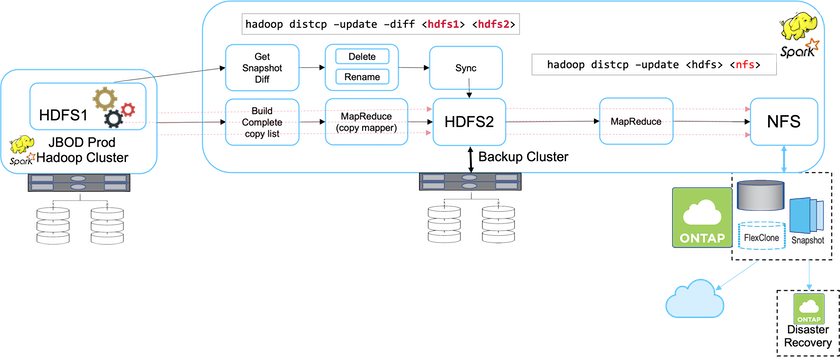
ソリューション A の詳細なタスクは次のとおりです。
-
実稼働 Hadoop クラスターには、保護が必要な顧客の分析データが HDFS 内にあります。
-
HDFS を使用したバックアップ Hadoop クラスターは、データの中間場所として機能します。 JBOD (Just a Bunch of Disks) は、本番環境とバックアップ環境の両方の Hadoop クラスターで HDFS のストレージを提供します。
-
Hadoopの本番データは、本番クラスタのHDFSからバックアップクラスタのHDFSまで、以下のコマンドを実行することで保護されます。 `Hadoop distcp –update –diff <hdfs1> <hdfs2>`指示。

|
Hadoop スナップショットは、本番環境からバックアップ Hadoop クラスターまでのデータを保護するために使用されます。 |
-
NetApp ONTAPストレージ コントローラは、バックアップ Hadoop クラスターにプロビジョニングされる NFS エクスポート ボリュームを提供します。
-
実行することで `Hadoop distcp`MapReduce と複数のマッパーを活用したコマンドにより、分析データはバックアップ Hadoop クラスターから NFS に保護されます。
データがNetAppストレージ システム上の NFS に保存された後、必要に応じてNetApp Snapshot、 SnapRestore、 FlexCloneテクノロジを使用して Hadoop データのバックアップ、復元、複製が行われます。
|
|
SnapMirrorテクノロジーを使用すると、Hadoop データをクラウドや災害復旧場所まで保護できます。 |
ソリューション A の利点は次のとおりです。
-
Hadoop 実稼働データはバックアップ クラスターから保護されます。
-
HDFS データは NFS を通じて保護され、クラウドおよび災害復旧場所への保護が可能になります。
-
バックアップ操作をバックアップ クラスターにオフロードすることでパフォーマンスが向上します。
-
手動のテープ操作を排除
-
NetAppツールを通じてエンタープライズ管理機能を実現します。
-
既存の環境への変更は最小限で済みます。
-
コスト効率の高いソリューションです。
このソリューションの欠点は、パフォーマンスを向上させるためにバックアップ クラスターと追加のマッパーが必要になることです。
顧客は最近、シンプルさ、コスト、全体的なパフォーマンスを理由にソリューション A を導入しました。
このソリューションでは、JBOD の代わりにONTAPの SAN ディスクを使用できます。このオプションは、バックアップ クラスタ ストレージの負荷をONTAPにオフロードしますが、SAN ファブリック スイッチが必要になるという欠点があります。
解決策B
ソリューション B は、本番 Hadoop クラスターに NFS ボリュームを追加し、下の図に示すように、バックアップ Hadoop クラスターの必要性を排除します。
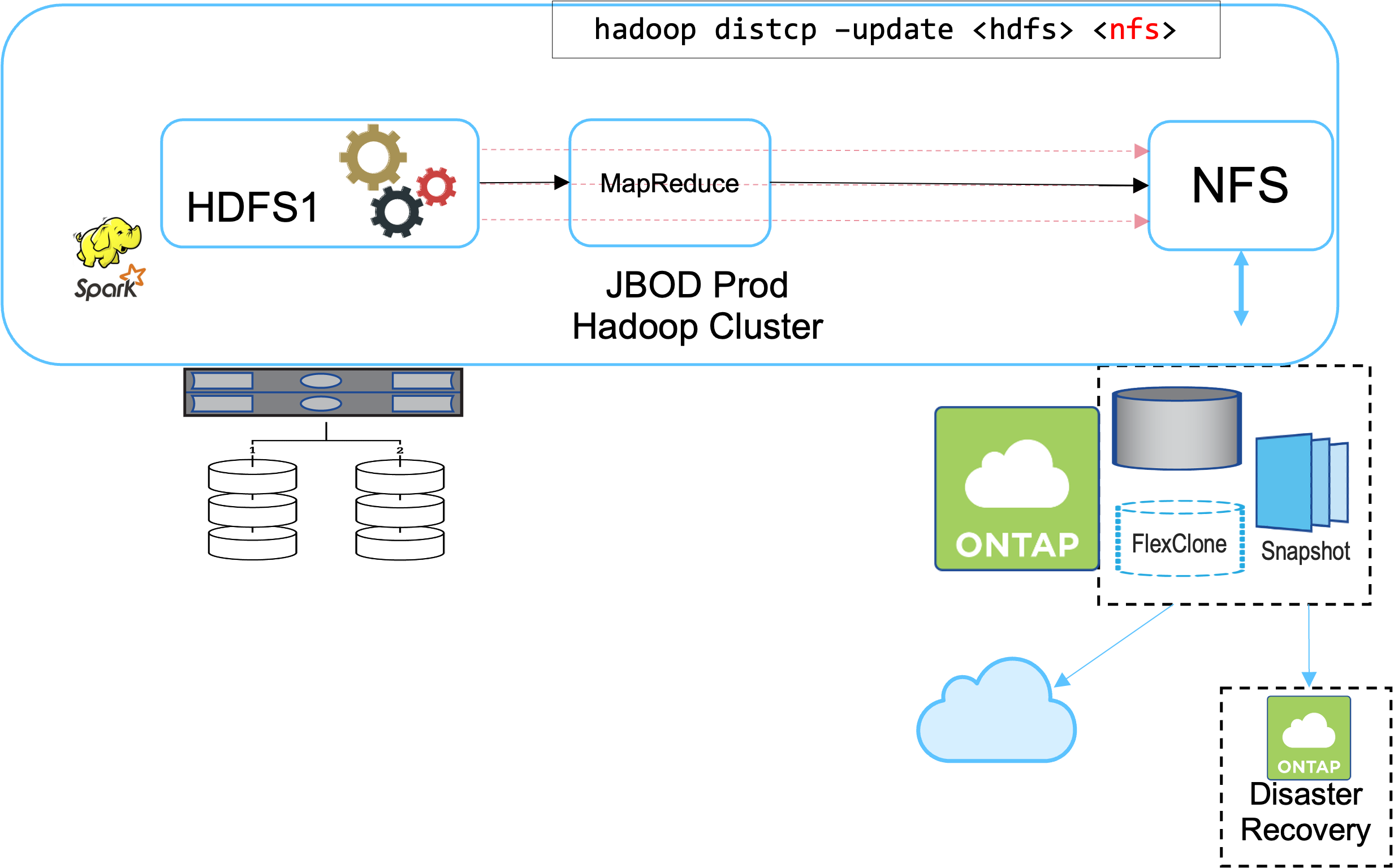
ソリューション B の詳細なタスクは次のとおりです。
-
NetApp ONTAPストレージ コントローラは、本番 Hadoop クラスターに NFS エクスポートをプロビジョニングします。
Hadoopネイティブ `hadoop distcp`コマンドは、本番クラスターの HDFS から NFS への Hadoop データを保護します。
-
データがNetAppストレージ システム上の NFS に保存された後、必要に応じて Snapshot、 SnapRestore、 FlexCloneテクノロジを使用して Hadoop データのバックアップ、復元、複製が行われます。
ソリューション B の利点は次のとおりです。
-
運用クラスターはバックアップ ソリューション用にわずかに変更されており、実装が簡素化され、追加のインフラストラクチャ コストが削減されます。
-
バックアップ操作用のバックアップ クラスターは必要ありません。
-
HDFS 実稼働データは、NFS データへの変換中に保護されます。
-
このソリューションは、 NetAppツールを通じてエンタープライズ管理機能を実現します。
このソリューションの欠点は、本番クラスターに実装されるため、本番クラスターに追加の管理者タスクが追加される可能性があることです。
解決策C
ソリューション C では、下の図に示すように、 NetApp SAN ボリュームが HDFS ストレージの Hadoop 本番クラスターに直接プロビジョニングされます。
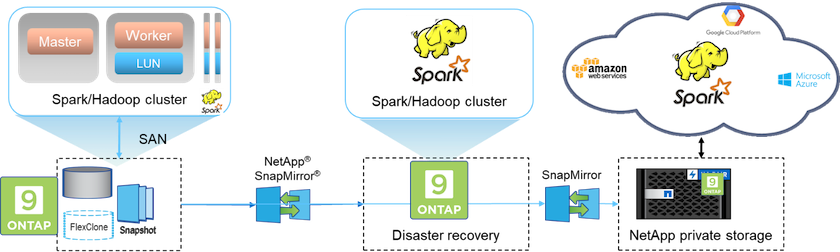
ソリューション C の詳細な手順は次のとおりです。
-
NetApp ONTAP SAN ストレージは、HDFS データ ストレージ用に本番 Hadoop クラスターにプロビジョニングされます。
-
NetApp Snapshot およびSnapMirrorテクノロジーは、実稼働 Hadoop クラスターから HDFS データをバックアップするために使用されます。
-
バックアップはストレージ レイヤーで行われるため、スナップショット コピーのバックアップ プロセス中に Hadoop/Spark クラスターの運用パフォーマンスに影響はありません。
|
|
スナップショット テクノロジーは、データのサイズに関係なく、数秒で完了するバックアップを提供します。 |
ソリューション C の利点は次のとおりです。
-
スナップショット テクノロジーを使用することで、スペース効率の高いバックアップを作成できます。
-
NetAppツールを通じてエンタープライズ管理機能を実現します。