ユースケース3: 既存のHadoopデータでDevTestを有効にする
 変更を提案
変更を提案
このユースケースでは、顧客の要件は、同じデータセンターとリモート ロケーションで、DevTest とレポート作成の目的で大量の分析データを含む既存の Hadoop クラスターに基づいて、新しい Hadoop/Spark クラスターを迅速かつ効率的に構築することです。
シナリオ
このシナリオでは、オンプレミスおよび災害復旧場所の大規模な Hadoop データ レイク実装から複数の Spark/Hadoop クラスターが構築されます。
要件と課題
このユースケースの主な要件と課題は次のとおりです。
-
DevTest、QA、または同じ本番データへのアクセスが必要なその他の目的のために、複数の Hadoop クラスターを作成します。ここでの課題は、非常に大規模な Hadoop クラスターを、瞬時に、かつ非常にスペース効率の高い方法で複数回複製することです。
-
運用効率を高めるために、Hadoop データを DevTest およびレポート チームと同期します。
-
同じ資格情報を使用して、本番環境と新しいクラスター全体で Hadoop データを分散します。
-
スケジュールされたポリシーを使用して、本番クラスターに影響を与えずに QA クラスターを効率的に作成します。
解決策
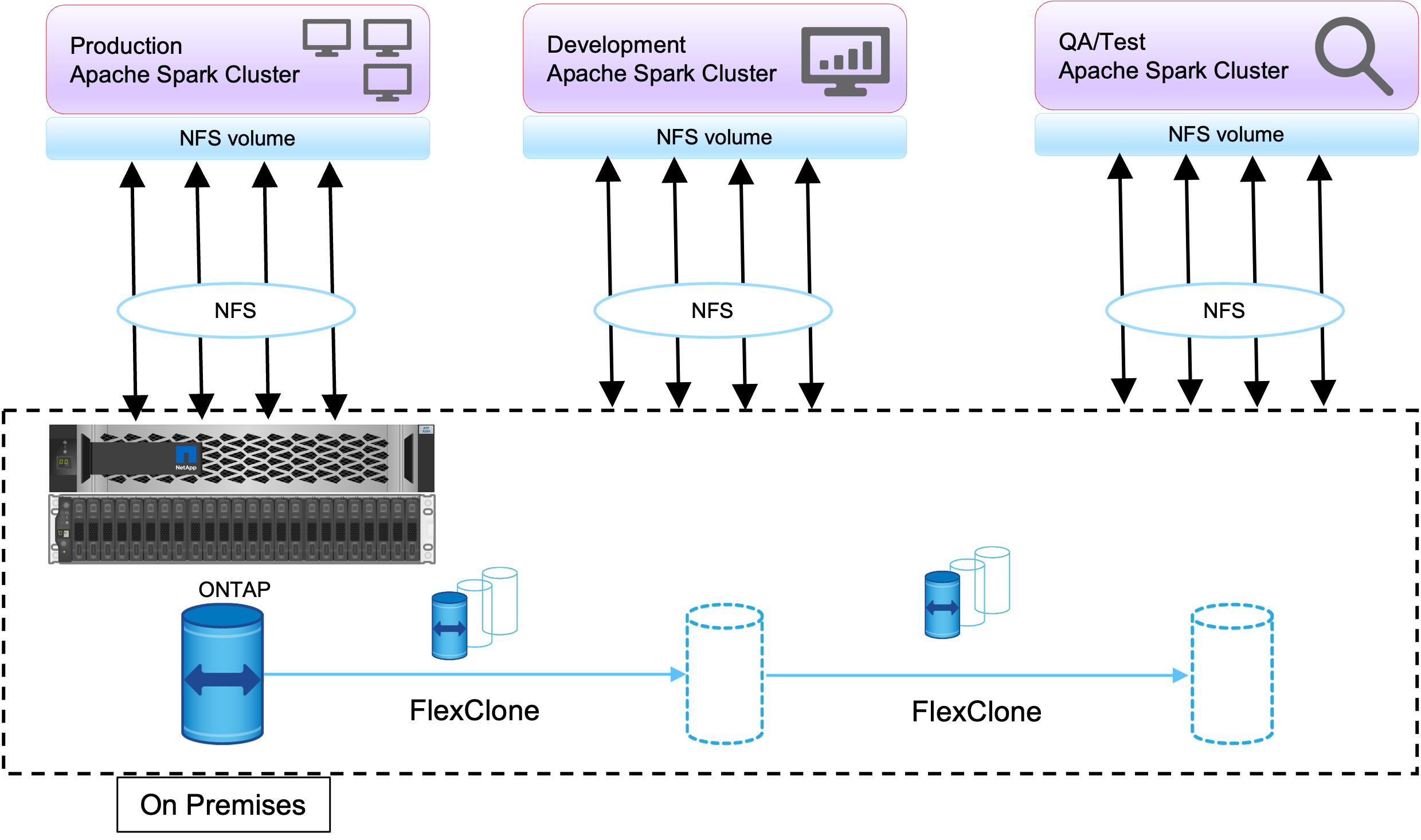
FlexCloneテクノロジーは、前述の要件に応えるために使用されます。 FlexCloneテクノロジーは、スナップショット コピーの読み取り/書き込みコピーです。親スナップショット コピー データからデータを読み取り、新しいブロックまたは変更されたブロックに対してのみ追加のスペースを消費します。高速かつスペース効率に優れています。
まず、 NetApp整合性グループを使用して、既存のクラスターのスナップショット コピーを作成しました。
NetApp System Manager またはストレージ管理プロンプト内のスナップショット コピー。整合性グループのスナップショット コピーは、アプリケーション整合性グループのスナップショット コピーであり、 FlexCloneボリュームは整合性グループのスナップショット コピーに基づいて作成されます。 FlexCloneボリュームは親ボリュームの NFS エクスポート ポリシーを継承することに注意してください。スナップショット コピーが作成された後、次の図に示すように、DevTest とレポート作成の目的で新しい Hadoop クラスターをインストールする必要があります。新しい Hadoop クラスターからクローンされた NFS ボリュームは NFS データにアクセスします。
この画像は、DevTest の Hadoop クラスターを示しています。