

使用例 - TensorFlow トレーニングジョブ
 変更を提案
変更を提案
このセクションでは、 NVIDIA AI Enterprise 環境内で TensorFlow トレーニング ジョブを実行するために実行する必要があるタスクについて説明します。
前提条件
このセクションで説明する手順を実行する前に、ゲストVMテンプレートが、"セットアップ"ページ。
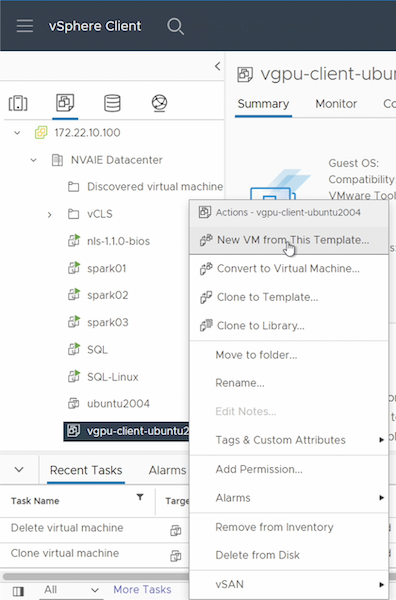
テンプレートからゲストVMを作成する
まず、前のセクションで作成したテンプレートから新しいゲスト VM を作成する必要があります。テンプレートから新しいゲスト VM を作成するには、VMware vSphere にログインし、テンプレート名を右クリックして、「このテンプレートから新しい VM を作成…」を選択し、ウィザードに従います。
データボリュームの作成とマウント
次に、トレーニング データセットを保存する新しいデータ ボリュームを作成する必要があります。 NetApp DataOps Toolkit を使用すると、新しいデータ ボリュームをすばやく作成できます。次の例のコマンドは、容量が 2 TB の「imagenet」という名前のボリュームの作成を示しています。
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
データ ボリュームにデータを入力する前に、それをゲスト VM 内にマウントする必要があります。 NetApp DataOps Toolkit を使用して、データ ボリュームをすばやくマウントできます。次のサンプルコマンドは、前の手順で作成されたボリュームのマウントを示しています。
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
データボリュームを入力する
新しいボリュームがプロビジョニングされマウントされたら、トレーニング データセットをソースの場所から取得し、新しいボリュームに配置できます。これには通常、S3 または Hadoop データ レイクからデータを取得することが含まれ、場合によってはデータ エンジニアの支援が必要になることもあります。
TensorFlowトレーニングジョブを実行する
これで、TensorFlow トレーニング ジョブを実行する準備が整いました。 TensorFlow トレーニング ジョブを実行するには、次のタスクを実行します。
-
NVIDIA NGC エンタープライズ TensorFlow コンテナー イメージをプルします。
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
NVIDIA NGC エンタープライズ TensorFlow コンテナのインスタンスを起動します。 '-v' オプションを使用して、データ ボリュームをコンテナーに接続します。
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
コンテナ内で TensorFlow トレーニング プログラムを実行します。次のサンプル コマンドは、コンテナ イメージに含まれているサンプル ResNet-50 トレーニング プログラムの実行を示しています。
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data