

ベクターデータベースのユースケース
 変更を提案
変更を提案
このセクションでは、 NetAppベクトル データベース ソリューションの使用例の概要を説明します。
ベクターデータベースのユースケース
このセクションでは、大規模言語モデルを使用した検索拡張生成とNetApp IT チャットボットなどの 2 つのユースケースについて説明します。
大規模言語モデル(LLM)を用いた検索拡張生成(RAG)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
NVIDIA Enterprise RAG LLM Operator は、企業内で RAG を実装するための便利なツールです。このオペレーターは、完全な RAG パイプラインをデプロイするために使用できます。 RAG パイプラインは、知識ベースの埋め込みを格納するためのベクター データベースとして Milvus または pgvecto のいずれかを利用するようにカスタマイズできます。詳細についてはドキュメントを参照してください。
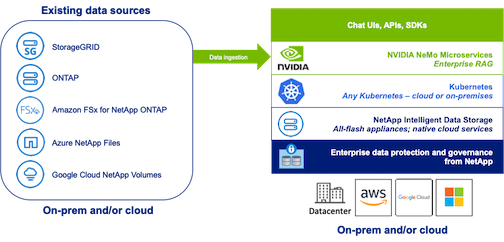
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
図1) NVIDIA NeMo MicroservicesとNetAppを搭載したエンタープライズRAG
NetApp IT チャットボットのユースケース
NetApp のチャットボットは、ベクター データベースのもう 1 つのリアルタイム使用例として機能します。この例では、 NetApp Private OpenAI Sandbox は、NetApp の社内ユーザーからのクエリを管理するための効果的で安全かつ効率的なプラットフォームを提供します。厳格なセキュリティ プロトコル、効率的なデータ管理システム、高度な AI 処理機能を組み込むことで、SSO 認証を通じて組織内の役割と責任に基づいて、ユーザーへの高品質で正確な応答を保証します。このアーキテクチャは、高度なテクノロジーを統合してユーザー中心のインテリジェントなシステムを作成する可能性を強調しています。
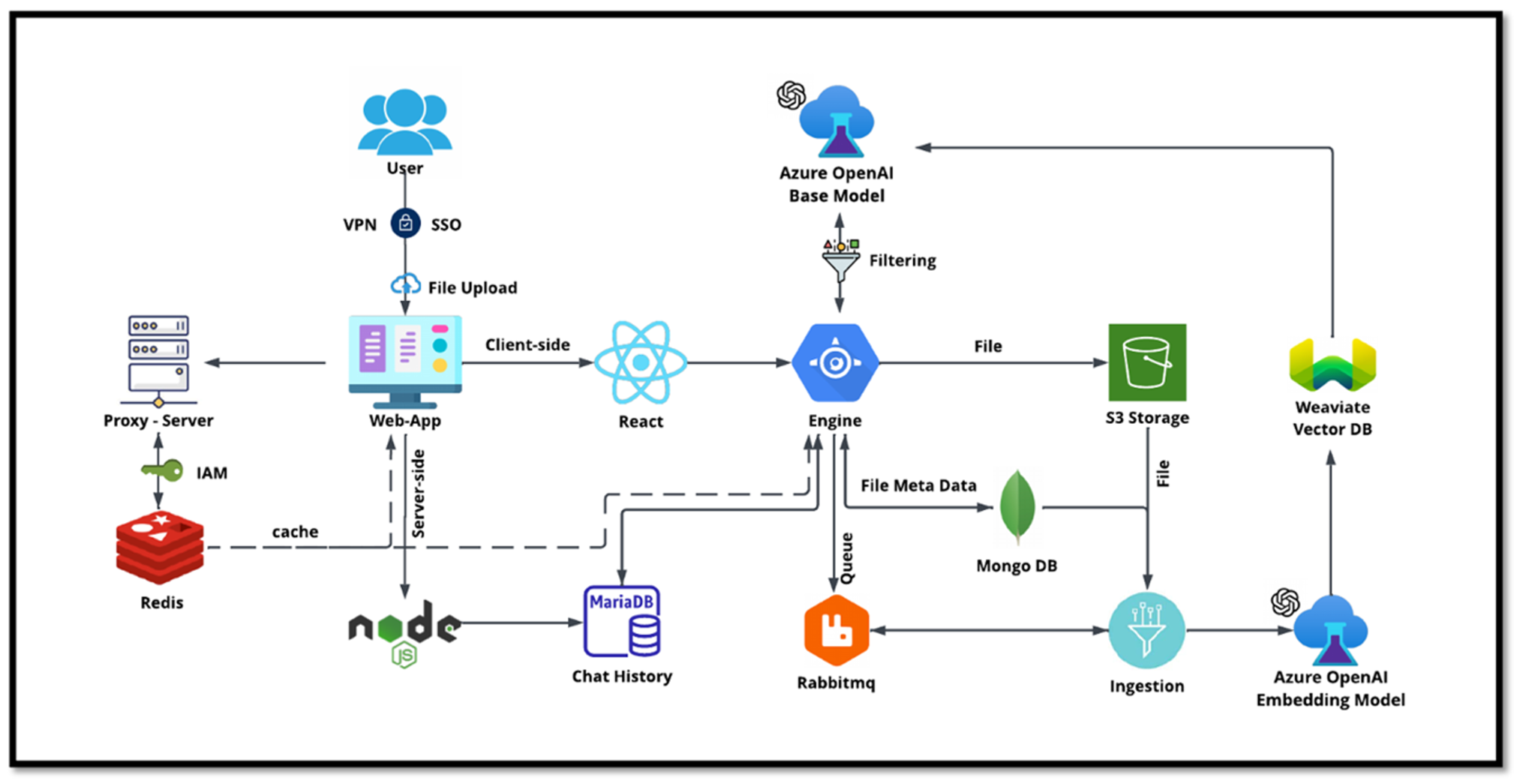
ユースケースは主に 4 つのセクションに分けられます。
ユーザー認証と検証:
-
ユーザー クエリは、まずNetAppシングル サインオン (SSO) プロセスを経て、ユーザーの ID を確認します。
-
認証が成功すると、システムは VPN 接続をチェックし、安全なデータ転送を確保します。
データの転送と処理:
-
VPN が検証されると、データは NetAIChat または NetAICreate Web アプリケーションを通じて MariaDB に送信されます。 MariaDB は、ユーザー データを管理および保存するために使用される高速で効率的なデータベース システムです。
-
その後、MariaDB は情報をNetApp Azure インスタンスに送信し、NetApp Azure インスタンスはユーザー データを AI 処理ユニットに接続します。
OpenAIとコンテンツフィルタリングとの相互作用:
-
Azure インスタンスは、ユーザーの質問をコンテンツ フィルタリング システムに送信します。このシステムはクエリをクリーンアップし、処理の準備をします。
-
クリーンアップされた入力は Azure OpenAI ベース モデルに送信され、入力に基づいて応答が生成されます。
レスポンスの生成とモデレーション:
-
まず、ベース モデルからの応答がチェックされ、正確であり、コンテンツ標準を満たしているかどうかが確認されます。
-
チェックに合格すると、応答がユーザーに返されます。このプロセスにより、ユーザーは質問に対して明確かつ正確で適切な回答を受け取ることができます。