

TR-4955: Azure NetApp Files (ANF) と Azure VMware Solution (AVS) を使用した災害復旧
 変更を提案
変更を提案
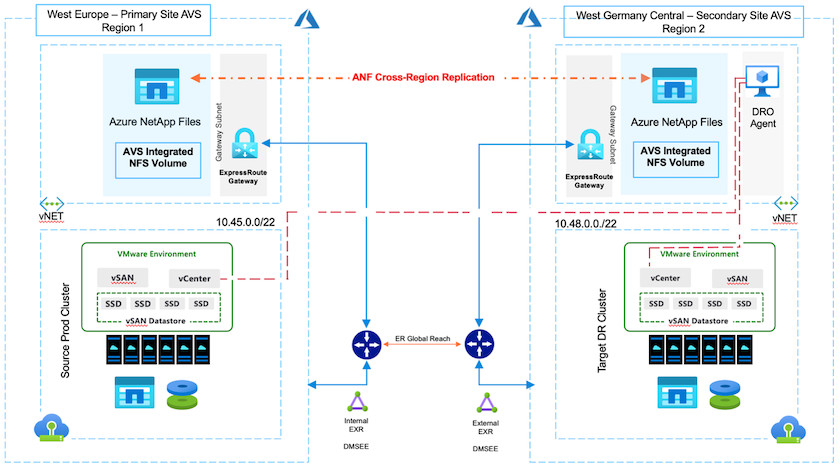
クラウド内のリージョン間でブロックレベルのレプリケーションを使用する災害復旧は、サイトの停止やデータ破損イベント (ランサムウェアなど) からワークロードを保護する、回復力がありコスト効率に優れた方法です。
概要
Azure NetAppファイル (ANF) のリージョン間ボリューム レプリケーションを使用すると、プライマリ AVS サイトで NFS データストアとして Azure NetAppファイル ボリュームを使用している Azure VMware Solution (AVS) SDDC サイトで実行されている VMware ワークロードを、ターゲット回復リージョン内の指定されたセカンダリ AVS サイトにレプリケートできます。
ディザスタ リカバリ オーケストレータ (DRO) (UI を備えたスクリプト ソリューション) を使用すると、ある AVS SDDC から別の AVS SDDC に複製されたワークロードをシームレスにリカバリできます。 DRO は、レプリケーション ピアリングを切断し、宛先ボリュームをデータストアとしてマウントし、AVS への VM 登録を通じて NSX-T (すべての AVS プライベート クラウドに含まれています) 上のネットワーク マッピングに直接マウントすることで、リカバリを自動化します。
前提条件と一般的な推奨事項
-
レプリケーション ピアリングを作成して、リージョン間レプリケーションが有効になっていることを確認します。見る "Azure NetApp Filesのボリューム レプリケーションを作成する"。
-
ソースとターゲットの Azure VMware Solution プライベート クラウド間に ExpressRoute Global Reach を構成する必要があります。
-
リソースにアクセスできるサービス プリンシパルが必要です。
-
プライマリ AVS サイトからセカンダリ AVS サイトへのトポロジがサポートされています。
-
設定する "複製"ビジネスニーズとデータ変更率に基づいて、各ボリュームのスケジュールを適切に設定します。

|
カスケードおよびファンイン/ファンアウト トポロジはサポートされていません。 |
開始
Azure VMware ソリューションをデプロイする
その "Azure VMware ソリューション"(AVS) は、Microsoft Azure パブリック クラウド内で完全に機能する VMware SDDC を提供するハイブリッド クラウド サービスです。 AVS は、Microsoft によって完全に管理およびサポートされ、Azure インフラストラクチャを使用する VMware によって検証されたファーストパーティ ソリューションです。そのため、お客様は、コンピューティング仮想化用の VMware ESXi、ハイパーコンバージド ストレージ用の vSAN、ネットワークとセキュリティ用の NSX を利用できると同時に、Microsoft Azure のグローバルな展開、クラス最高のデータセンター設備、ネイティブ Azure サービスとソリューションの豊富なエコシステムへの近接性を活用できます。 Azure VMware Solution SDDC とAzure NetApp Files を組み合わせることで、最小限のネットワーク待機時間で最高のパフォーマンスが得られます。
AzureでAVSプライベートクラウドを構成するには、次の手順に従ってください。"リンク" NetAppのドキュメントとこの "リンク"Microsoft ドキュメント。最小限の構成でセットアップされたパイロットライト環境は、DR の目的で使用できます。このセットアップには、重要なアプリケーションをサポートするためのコア コンポーネントのみが含まれており、フェイルオーバーが発生した場合には、スケールアウトしてより多くのホストを生成し、負荷の大部分を処理できます。
|
|
最初のリリースでは、DRO は既存の AVS SDDC クラスターをサポートします。オンデマンド SDDC 作成は、今後のリリースで利用可能になります。 |
Azure NetApp Files のプロビジョニングと構成
"Azure NetApp Files"は、高性能でエンタープライズ クラスの従量制ファイル ストレージ サービスです。この手順に従ってください "リンク"Azure NetApp Files をNFS データストアとしてプロビジョニングおよび構成し、AVS プライベート クラウドの展開を最適化します。
Azure NetApp Filesを利用したデータストア ボリュームのボリューム レプリケーションを作成する
最初のステップは、適切な頻度と保持期間で、AVS プライマリ サイトから AVS セカンダリ サイトへの目的のデータストア ボリュームのクロスリージョン レプリケーションを設定することです。

この手順に従ってください "リンク"レプリケーション ピアリングを作成してリージョン間レプリケーションを設定します。宛先容量プールのサービス レベルは、ソース容量プールのサービス レベルと一致できます。ただし、この特定のユースケースでは、標準のサービスレベルを選択してから、 "サービスレベルを変更する"実際の災害や DR シミュレーションの場合に使用します。
|
|
リージョン間のレプリケーション関係は前提条件であり、事前に作成する必要があります。 |
DROのインストール
DRO を開始するには、指定された Azure 仮想マシンで Ubuntu オペレーティング システムを使用し、前提条件を満たしていることを確認します。次にパッケージをインストールします。
前提条件:
-
リソースにアクセスできるサービス プリンシパル。
-
ソースと宛先の SDDC およびAzure NetApp Filesインスタンスへの適切な接続が存在することを確認します。
-
DNS 名を使用している場合は、DNS 解決を実施する必要があります。それ以外の場合は、vCenter の IP アドレスを使用します。
OS要件:
-
Ubuntu Focal 20.04 (LTS) 指定されたエージェント仮想マシンに次のパッケージをインストールする必要があります。
-
Docker
-
Docker-compose
-
JqChange
docker.sock`この新しい権限に: `sudo chmod 666 /var/run/docker.sock。
|
|
その `deploy.sh`スクリプトは必要なすべての前提条件を実行します。 |
手順は次のとおりです。
-
指定された仮想マシンにインストール パッケージをダウンロードします。
git clone https://github.com/NetApp/DRO-Azure.git
エージェントは、セカンダリ AVS サイト リージョンまたは SDDC とは別の AZ 内のプライマリ AVS サイト リージョンにインストールする必要があります。 -
パッケージを解凍し、デプロイメントスクリプトを実行して、ホストIPを入力します(例:
10.10.10.10)。tar xvf draas_package.tar Navigate to the directory and run the deploy script as below: sudo sh deploy.sh
-
次の資格情報を使用して UI にアクセスします。
-
ユーザー名:
admin -
パスワード:
admin
-
DRO構成
Azure NetApp Filesと AVS が適切に構成されたら、プライマリ AVS サイトからセカンダリ AVS サイトへのワークロードの回復を自動化するための DRO の構成を開始できます。 NetApp、DRO エージェントをセカンダリ AVS サイトに展開し、ExpressRoute ゲートウェイ接続を構成して、DRO エージェントが適切な AVS およびAzure NetApp Filesコンポーネントとネットワーク経由で通信できるようにすることをお勧めします。
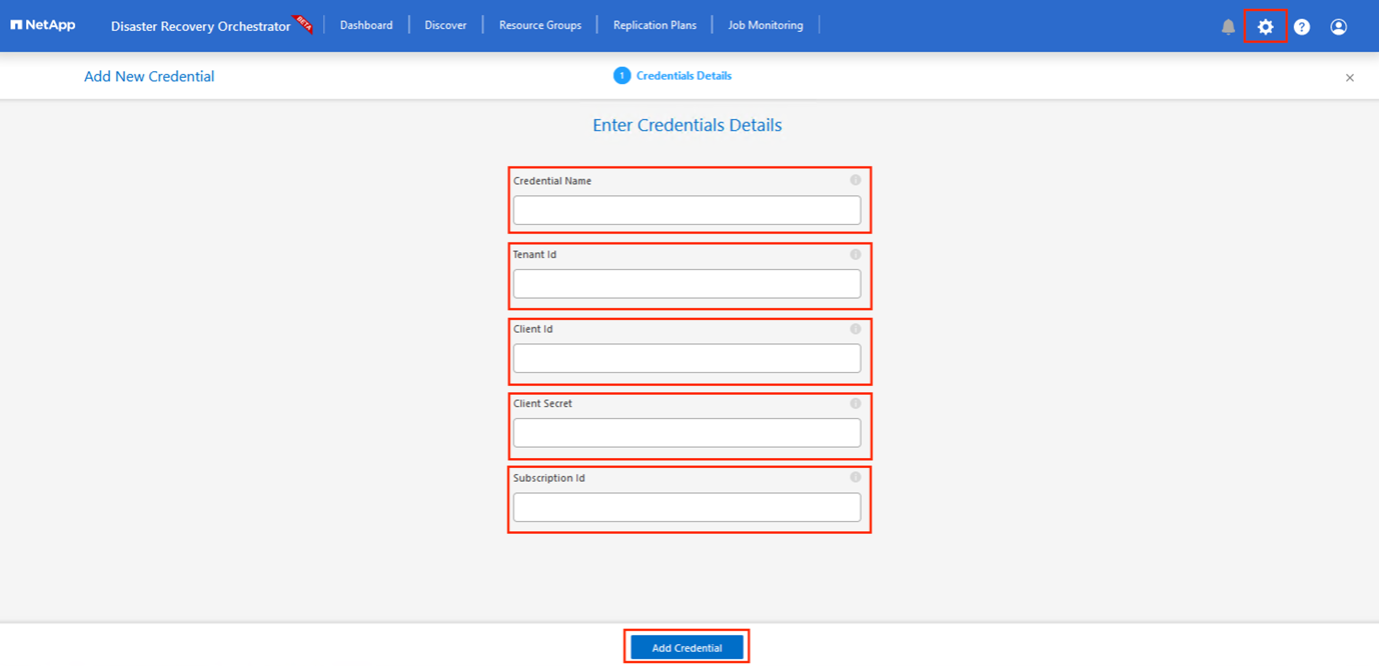
最初のステップは資格情報を追加することです。 DRO には、Azure NetApp Filesと Azure VMware Solution を検出するためのアクセス許可が必要です。 Azure Active Directory (AD) アプリケーションを作成して設定し、DRO に必要な Azure 資格情報を取得することで、Azure アカウントに必要な権限を付与できます。サービス プリンシパルを Azure サブスクリプションにバインドし、関連する必要なアクセス許可を持つカスタム ロールを割り当てる必要があります。ソース環境と宛先環境を追加すると、サービス プリンシパルに関連付けられている資格情報を選択するように求められます。 「新しいサイトの追加」をクリックする前に、これらの資格情報を DRO に追加する必要があります。
この操作を実行するには、次の手順を実行します。
-
サポートされているブラウザでDROを開き、デフォルトのユーザー名とパスワードを使用します。/
admin/admin)。最初のログイン後に、「パスワードの変更」オプションを使用してパスワードをリセットできます。 -
DRO コンソールの右上にある 設定 アイコンをクリックし、資格情報 を選択します。
-
「新しい資格情報の追加」をクリックし、ウィザードの手順に従います。
-
資格情報を定義するには、必要なアクセス許可を付与する Azure Active Directory サービス プリンシパルに関する情報を入力します。
-
資格情報名
-
テナントID
-
クライアントID
-
Client secret
-
サブスクリプション ID
AD アプリケーションを作成したときに、この情報を取得しておく必要があります。
-
-
新しい資格情報の詳細を確認し、「資格情報の追加」をクリックします。
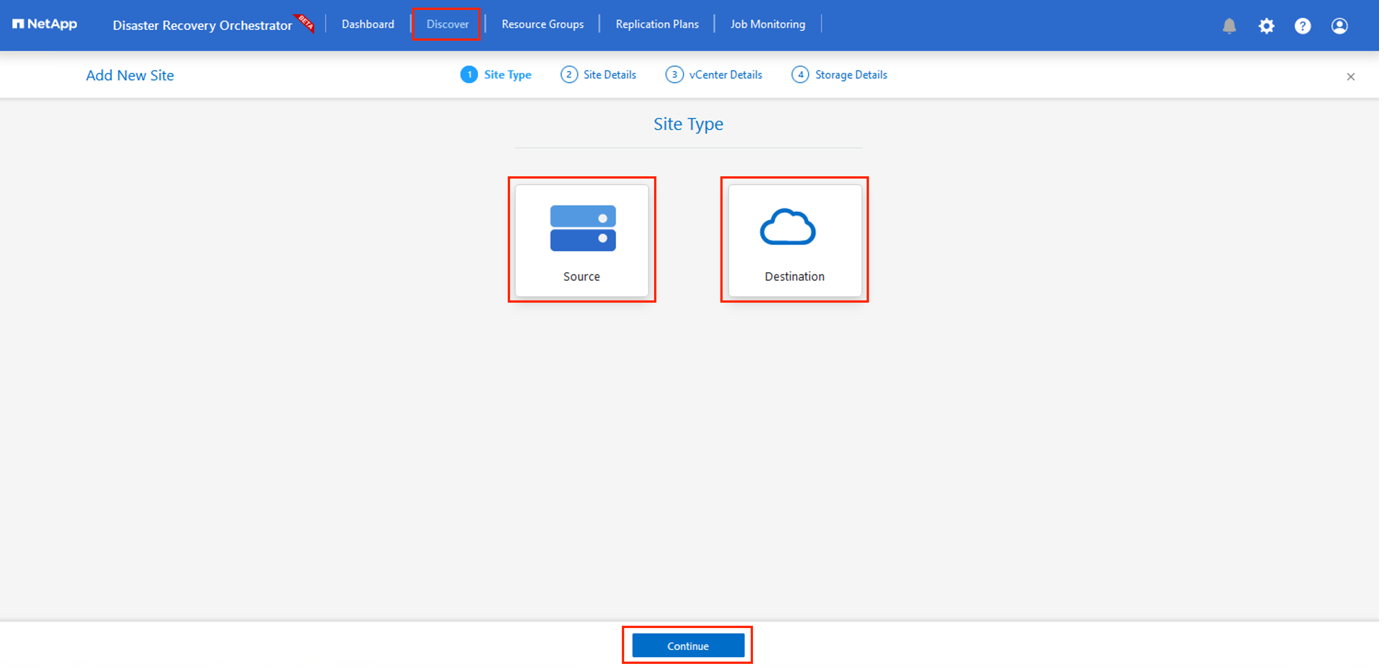
資格情報を追加したら、プライマリおよびセカンダリ AVS サイト (vCenter と Azure NetAppファイル ストレージ アカウントの両方) を検出して DRO に追加します。ソースサイトと宛先サイトを追加するには、次の手順を実行します。
-
*Discover*タブに移動します。
-
*新しいサイトを追加*をクリックします。
-
次のプライマリ AVS サイトを追加します (コンソールでは ソース として指定されます)。
-
SDDC vCenter
-
Azure NetApp Filesストレージ アカウント
-
-
次のセカンダリ AVS サイトを追加します (コンソールで Destination として指定)。
-
SDDC vCenter
-
Azure NetApp Filesストレージ アカウント
-
-
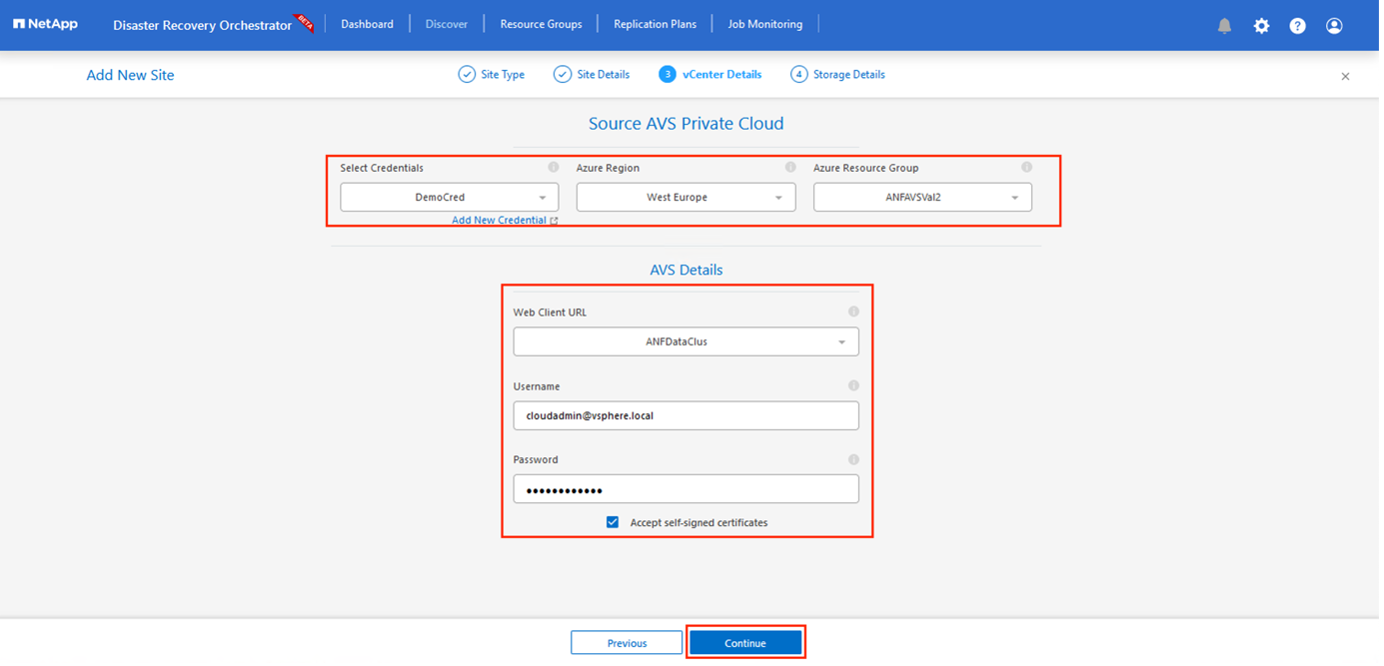
ソース をクリックし、わかりやすいサイト名を入力してコネクタを選択し、サイトの詳細を追加します。次に、[続行] をクリックします。
このドキュメントでは、デモンストレーションの目的で、ソース サイトの追加について説明します。 -
vCenter の詳細を更新します。これを行うには、プライマリ AVS SDDC のドロップダウンから資格情報、Azure リージョン、リソース グループを選択します。
-
DRO には、リージョン内で利用可能なすべての SDDC が一覧表示されます。ドロップダウンから指定されたプライベート クラウド URL を選択します。
-
入力してください `cloudadmin@vsphere.local`ユーザー資格情報。 Azure Portal からアクセスできます。この手順に従う "リンク"。完了したら、[続行] をクリックします。
-
Azure リソース グループとNetAppアカウントを選択して、ソース ストレージの詳細 (ANF) を選択します。
-
*サイトの作成*をクリックします。
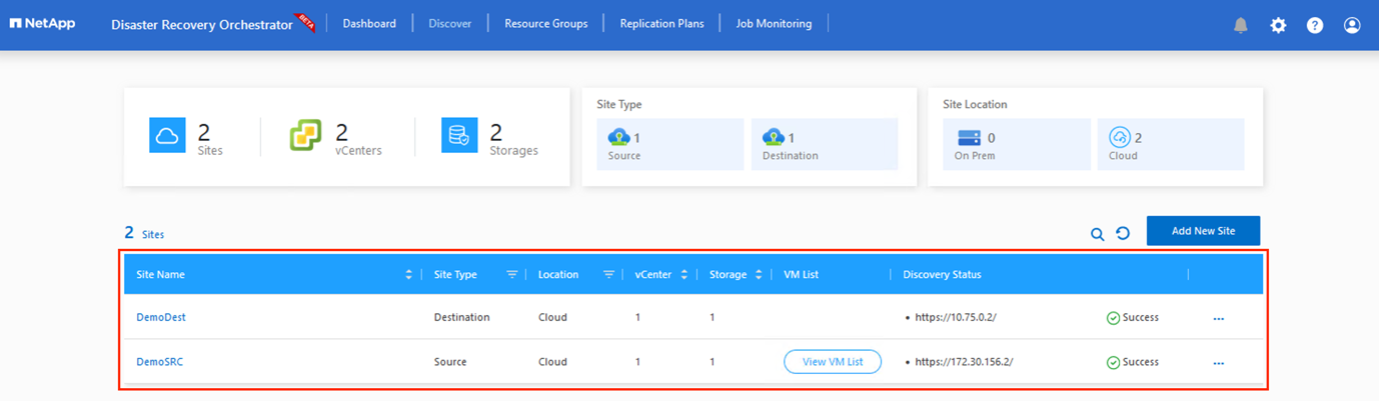
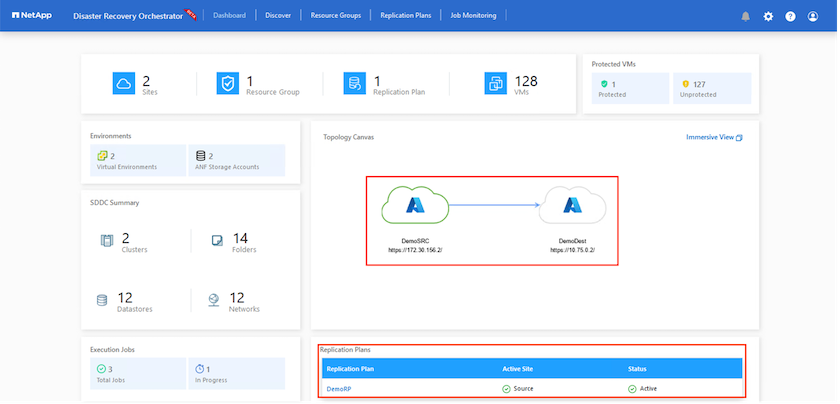
追加されると、DRO は自動検出を実行し、ソース サイトから宛先サイトへの対応するクロスリージョン レプリカを持つ VM を表示します。 DRO は、VM が使用するネットワークとセグメントを自動的に検出し、それらを入力します。
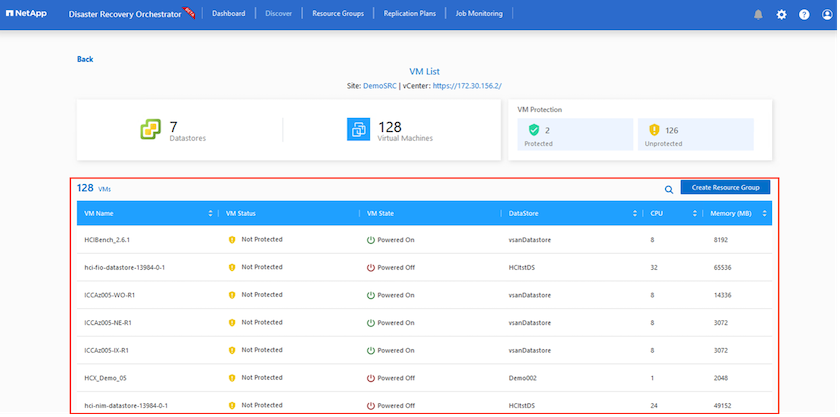
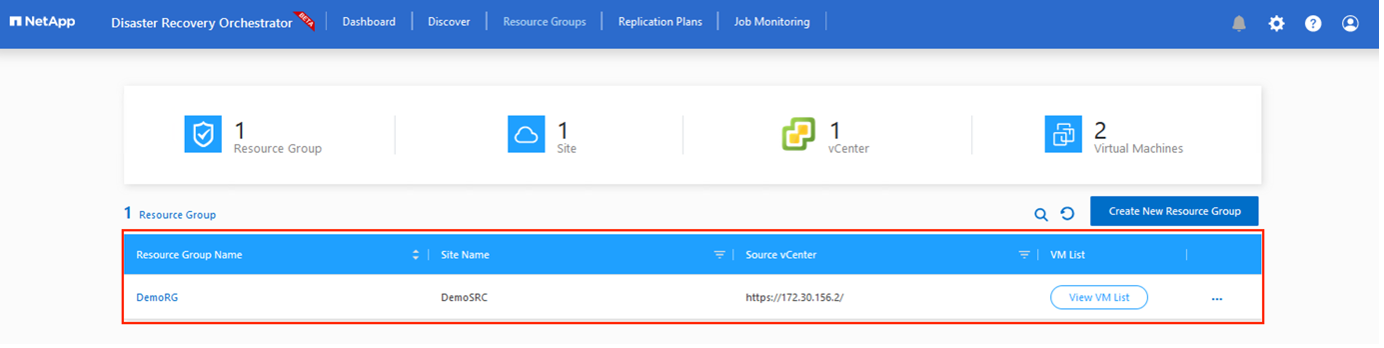
次のステップは、必要な VM をリソース グループとして機能グループにグループ化することです。
リソースのグループ化
プラットフォームを追加したら、回復する VM をリソース グループにグループ化します。 DRO リソース グループを使用すると、依存する VM のセットを、ブート順序、ブート遅延、および回復時に実行できるオプションのアプリケーション検証を含む論理グループにグループ化できます。
リソース グループの作成を開始するには、[新しいリソース グループの作成] メニュー項目をクリックします。
-
*リソース グループ*にアクセスし、*新しいリソース グループの作成*をクリックします。
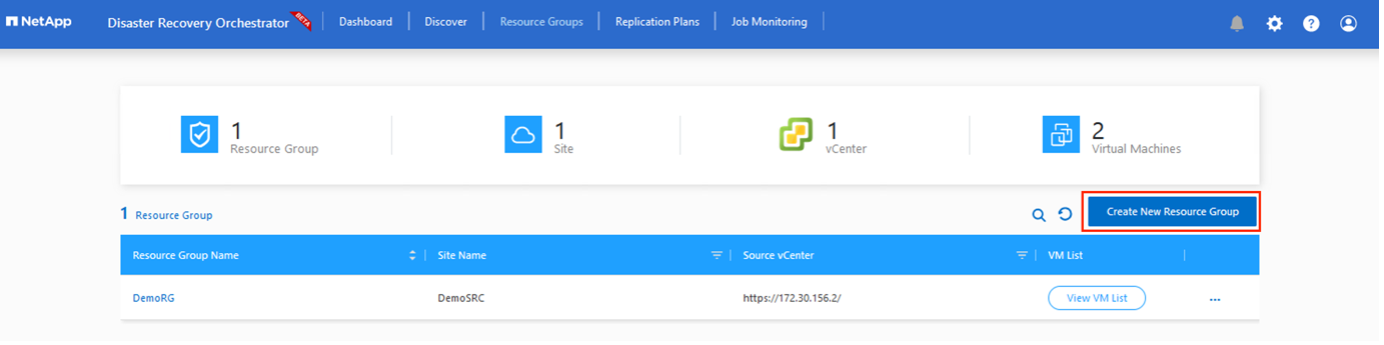
-
[新しいリソース グループ] の下で、ドロップダウンからソース サイトを選択し、[作成] をクリックします。
-
リソース グループの詳細を入力し、[続行] をクリックします。
-
検索オプションを使用して適切な VM を選択します。
-
選択したすべての VM の ブート順序 と ブート遅延 (秒) を選択します。各仮想マシンを選択し、その優先順位を設定することで、電源オンシーケンスの順序を設定します。すべての仮想マシンのデフォルト値は 3 です。オプションは次のとおりです。
-
最初に電源を入れる仮想マシン
-
デフォルト
-
最後に電源をオンにした仮想マシン
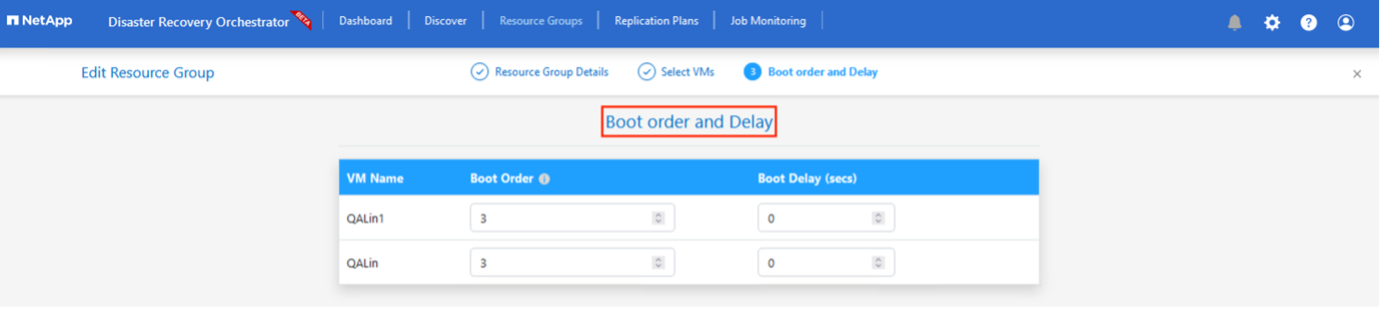
-
-
*リソース グループの作成*をクリックします。
レプリケーションプラン
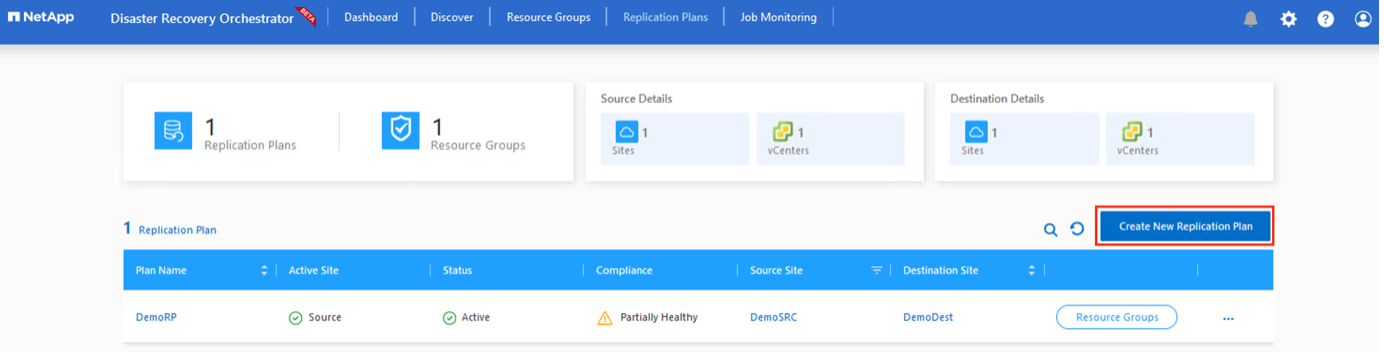
災害が発生した場合にアプリケーションを回復するための計画が必要です。ドロップダウンからソースとターゲットの vCenter プラットフォームを選択し、このプランに含めるリソース グループを選択します。また、アプリケーションを復元してパワーオンする方法のグループ化も含めます (たとえば、ドメイン コントローラ、Tier-1、Tier-2 など)。計画は青写真とも呼ばれることがあります。リカバリ プランを定義するには、[レプリケーション プラン] タブに移動し、[新しいレプリケーション プラン] をクリックします。
レプリケーション プランの作成を開始するには、次の手順を実行します。
-
レプリケーション プラン に移動し、新しいレプリケーション プランの作成 をクリックします。
-
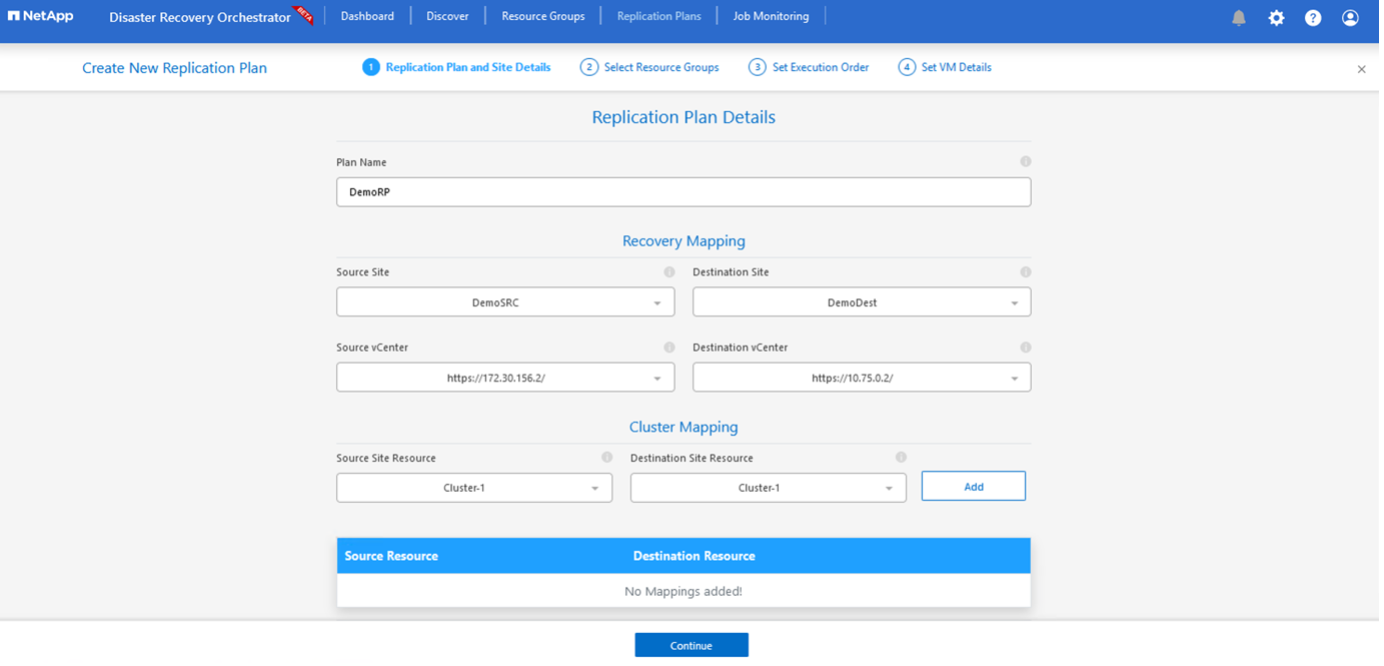
新しいレプリケーション プラン で、プランの名前を指定し、ソース サイト、関連する vCenter、宛先サイト、および関連する vCenter を選択してリカバリ マッピングを追加します。
-
リカバリ マッピングが完了したら、クラスター マッピング を選択します。
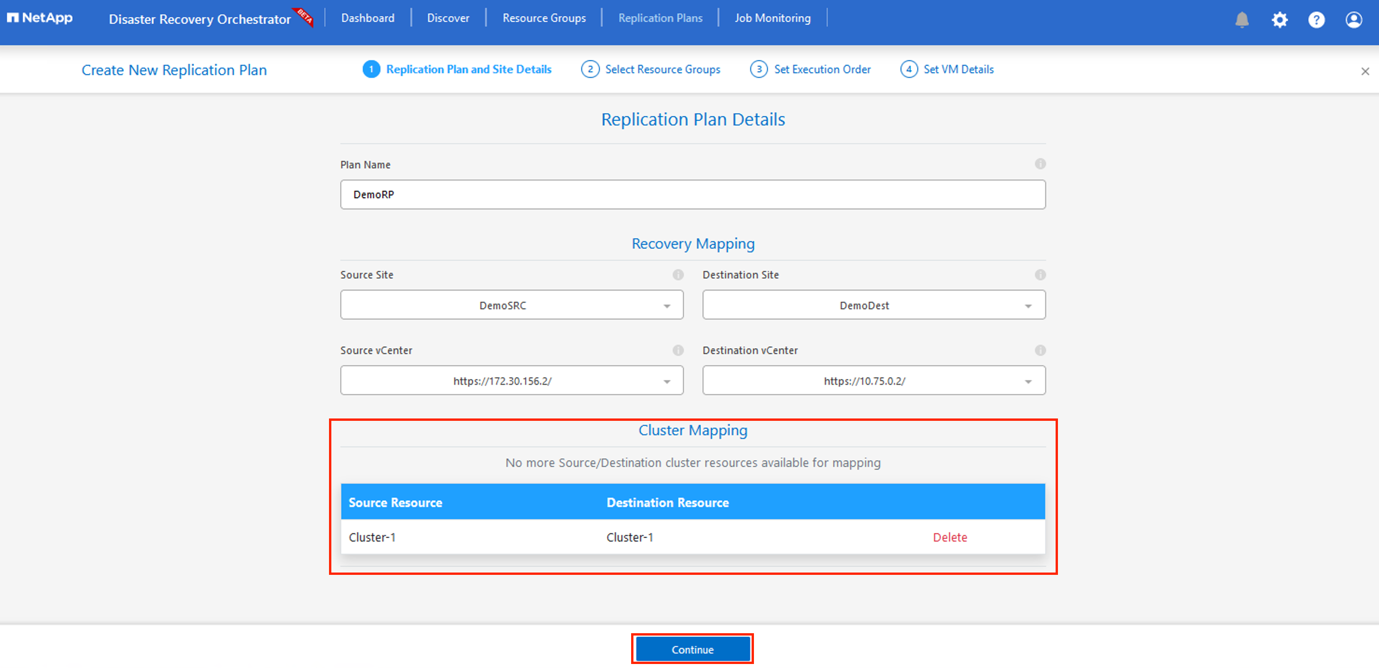
-
*リソース グループの詳細*を選択し、*続行*をクリックします。
-
リソース グループの実行順序を設定します。このオプションを使用すると、複数のリソース グループが存在する場合に操作のシーケンスを選択できます。
-
完了したら、ネットワーク マッピングを適切なセグメントに設定します。セグメントはすでにセカンダリ AVS クラスターにプロビジョニングされているはずなので、VM をそれらにマップするには適切なセグメントを選択します。
-
データストア マッピングは、VM の選択に基づいて自動的に選択されます。
クロスリージョンレプリケーション (CRR) はボリューム レベルで行われます。したがって、それぞれのボリュームに存在するすべての VM が CRR の宛先に複製されます。レプリケーション プランの一部である仮想マシンのみが処理されるため、データストアの一部であるすべての仮想マシンを選択してください。 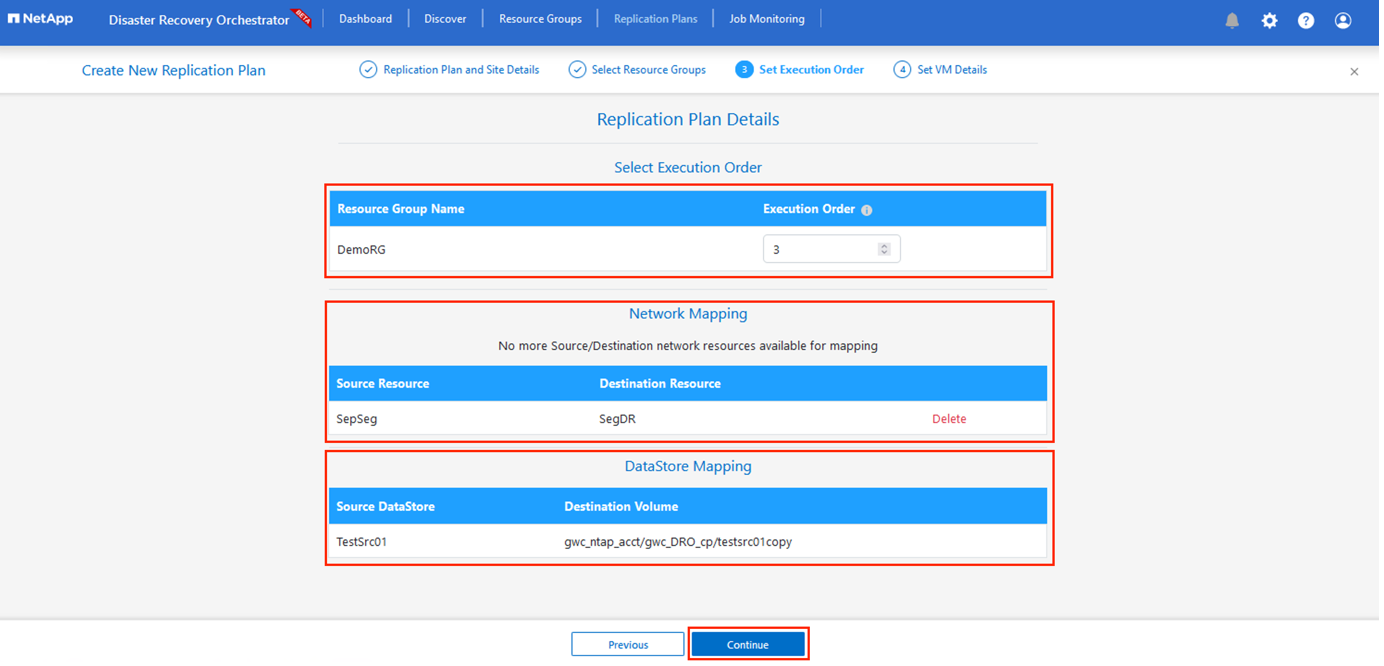
-
VM の詳細では、オプションで VM の CPU および RAM パラメータのサイズを変更できます。これは、大規模な環境を小規模なターゲット クラスターにリカバリする場合や、1 対 1 の物理 VMware インフラストラクチャをプロビジョニングせずに DR テストを実施する場合に非常に役立ちます。また、リソース グループ全体で選択したすべての VM のブート順序とブート遅延 (秒) を変更します。リソース グループのブート順序の選択時に選択した内容を変更する必要がある場合は、ブート順序を変更するための追加オプションがあります。デフォルトでは、リソース グループの選択時に選択されたブート順序が使用されますが、この段階で変更を実行することもできます。
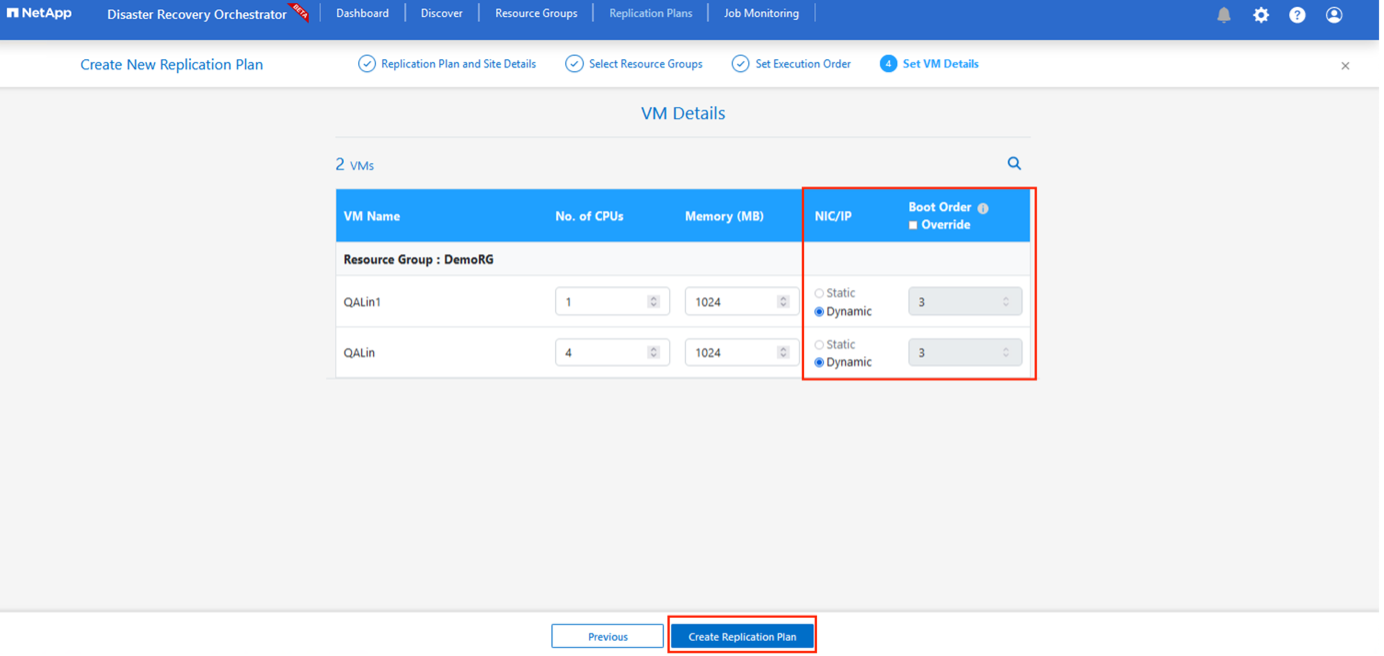
-
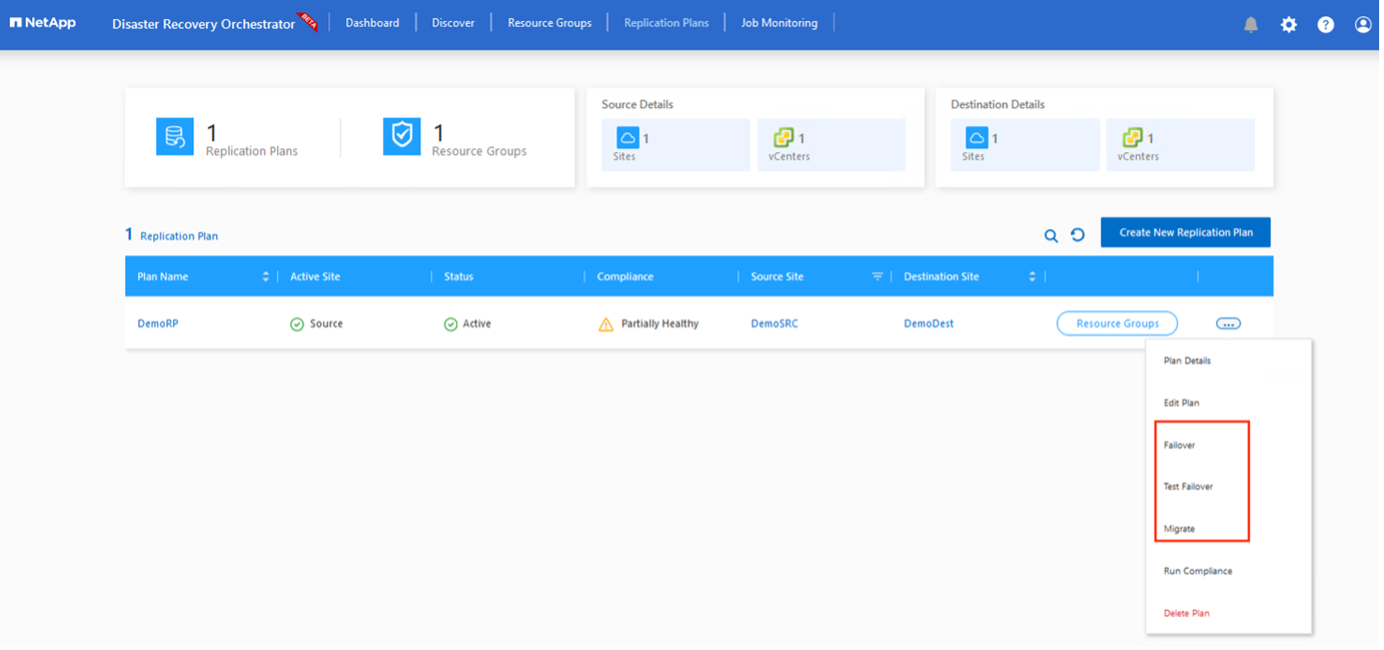
*レプリケーション プランの作成*をクリックします。レプリケーション プランが作成されたら、要件に応じてフェールオーバーを実行したり、フェールオーバーをテストしたり、オプションを移行したりできます。
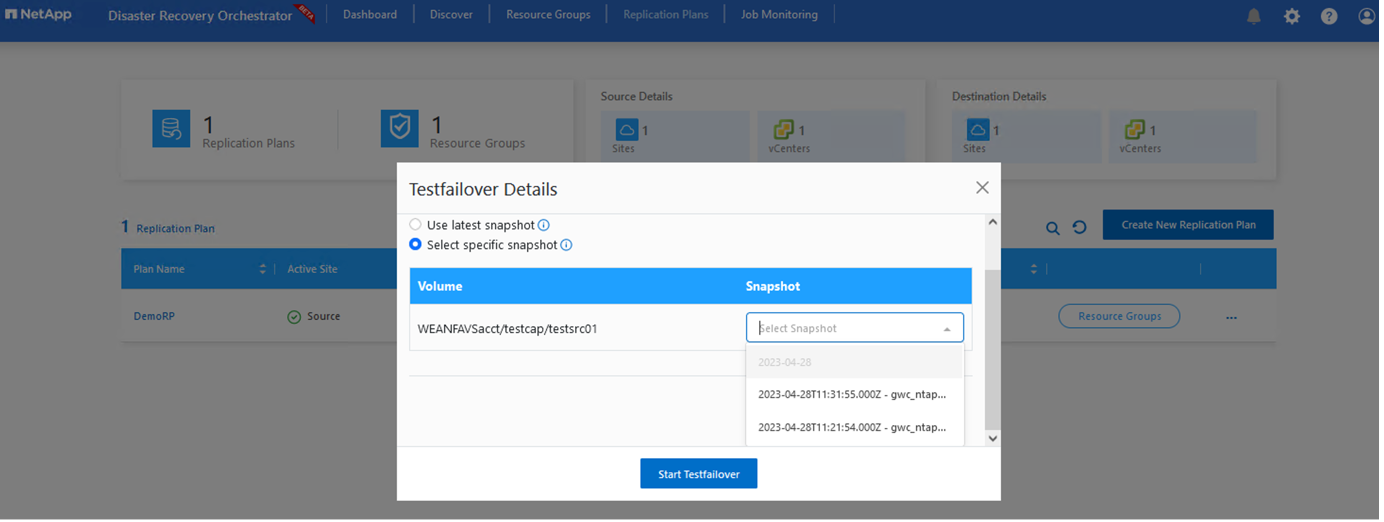
フェールオーバーおよびテスト フェールオーバーのオプションでは、最新のスナップショットが使用されるか、または特定の時点のスナップショットから特定のスナップショットを選択することもできます。最新のレプリカがすでに侵害または暗号化されているランサムウェアなどの破損イベントに直面している場合、ポイントインタイム オプションは非常に役立ちます。 DRO は利用可能なすべての時点を表示します。
レプリケーション プランで指定された構成でフェイルオーバーをトリガーするか、フェイルオーバーをテストするには、フェイルオーバー または フェイルオーバーのテスト をクリックします。タスク メニューでレプリケーション プランを監視できます。
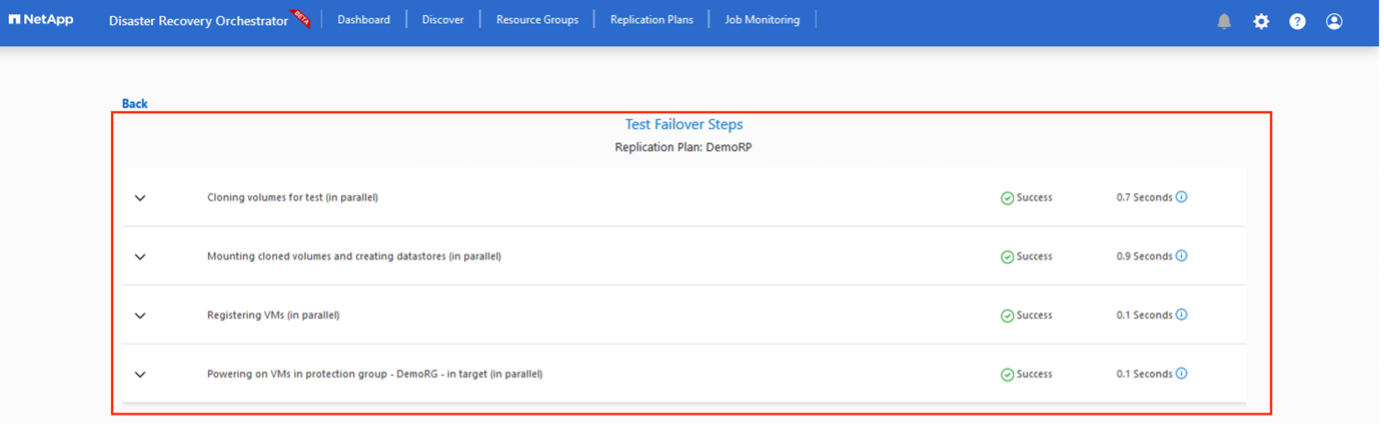
フェイルオーバーがトリガーされると、回復されたアイテムがセカンダリ サイトの AVS SDDC vCenter (VM、ネットワーク、データストア) に表示されます。デフォルトでは、VM はワークロード フォルダーに回復されます。
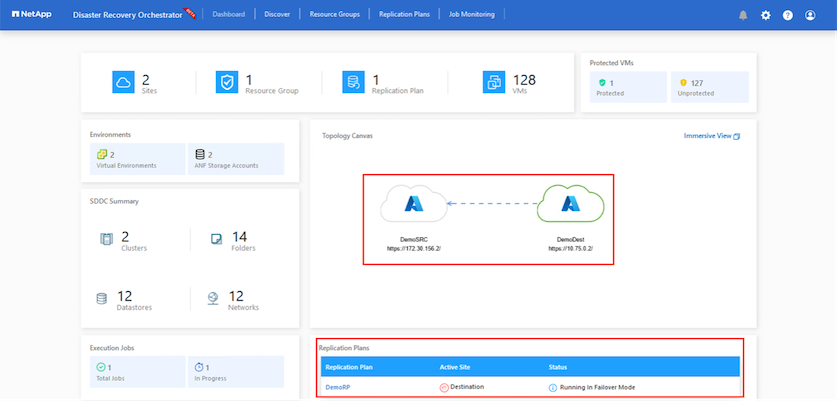
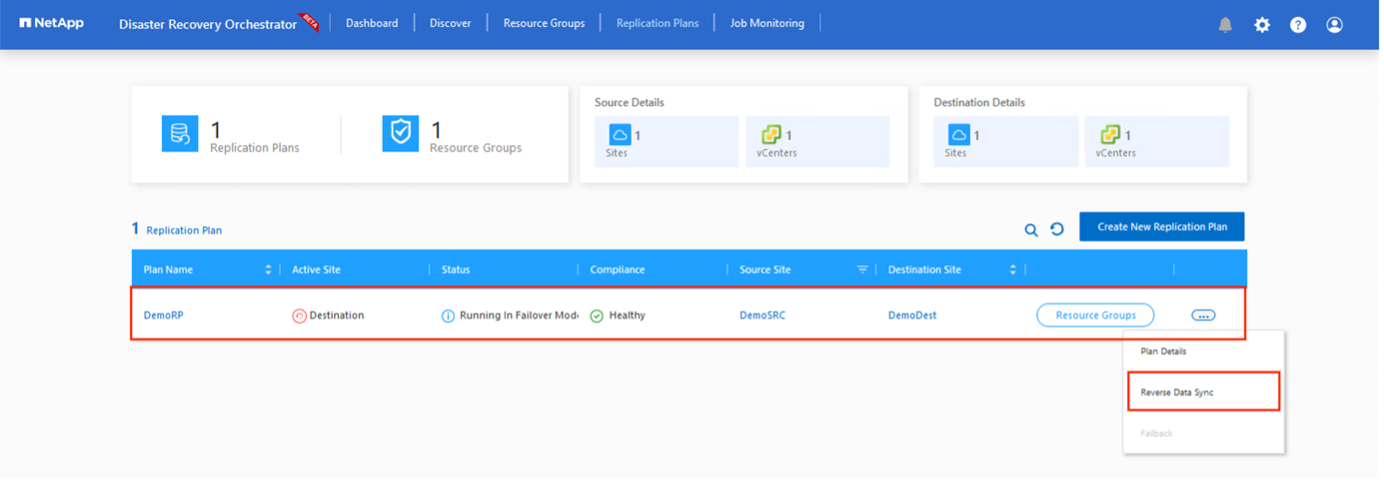
フェイルバックはレプリケーション プラン レベルでトリガーできます。テストフェイルオーバーの場合、ティアダウン オプションを使用して変更をロールバックし、新しく作成されたボリュームを削除できます。フェイルオーバーに関連するフェイルバックは 2 段階のプロセスです。レプリケーション プランを選択し、逆データ同期 を選択します。
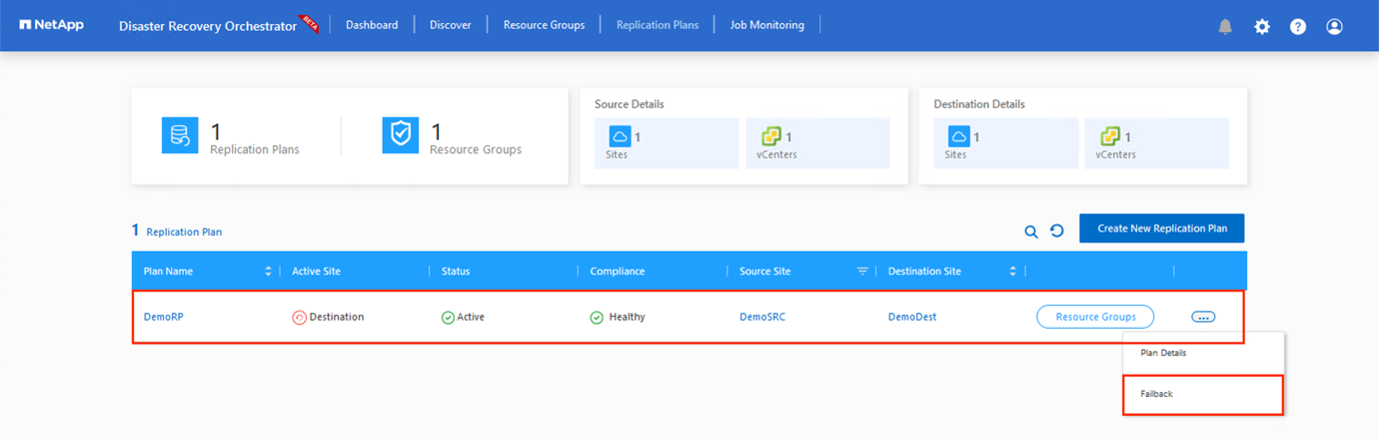
この手順が完了したら、フェイルバックをトリガーしてプライマリ AVS サイトに戻ります。
Azure ポータルから、セカンダリ サイトの AVS SDDC に読み取り/書き込みボリュームとしてマップされた適切なボリュームのレプリケーションの正常性が失われていることがわかります。テスト フェイルオーバー中、DRO は宛先ボリュームまたはレプリカ ボリュームをマップしません。代わりに、必要なリージョン間レプリケーション スナップショットの新しいボリュームを作成し、そのボリュームをデータストアとして公開します。これにより、容量プールから追加の物理容量が消費され、ソース ボリュームが変更されないようになります。特に、レプリケーション ジョブは DR テスト中またはトリアージ ワークフロー中でも継続できます。さらに、このプロセスにより、エラーが発生したり破損したデータが回復されたりした場合にレプリカが破壊されるリスクなしに、回復をクリーンアップできるようになります。
ランサムウェアからの回復
ランサムウェアからの回復は困難な作業になる可能性があります。具体的には、IT 組織にとって、安全な復帰ポイントがどこなのかを正確に特定することが困難になる可能性があり、また、それが決定された後、回復したワークロードが再発する攻撃 (たとえば、休眠中のマルウェアや脆弱なアプリケーションによるもの) から確実に保護されるようにする方法も困難になります。
DRO は、組織が利用可能な任意の時点から回復できるようにすることで、これらの懸念に対処します。その後、ワークロードは機能的でありながら分離されたネットワークに回復され、アプリケーションは機能し相互に通信できるようになりますが、南北トラフィックにはさらされません。このプロセスにより、セキュリティ チームは安全な場所でフォレンジックを実施し、隠れたマルウェアや潜伏中のマルウェアを特定できるようになります。
まとめ
Azure NetApp Filesと Azure VMware ディザスター リカバリー ソリューションには、次の利点があります。
-
効率的で回復力のあるAzure NetApp Files のリージョン間レプリケーションを活用します。
-
スナップショット保持により、利用可能な任意の時点に回復します。
-
ストレージ、コンピューティング、ネットワーク、アプリケーションの検証手順から数百から数千の VM を回復するために必要なすべての手順を完全に自動化します。
-
ワークロードのリカバリでは、複製されたボリュームを操作しない「最新のスナップショットから新しいボリュームを作成する」プロセスが活用されます。
-
ボリュームまたはスナップショット上のデータ破損のリスクを回避します。
-
DR テスト ワークフロー中のレプリケーションの中断を回避します。
-
開発/テスト、セキュリティ テスト、パッチおよびアップグレード テスト、修復テストなど、DR 以外のワークフローに DR データとクラウド コンピューティング リソースを活用します。
-
CPU と RAM の最適化により、より小規模なコンピューティング クラスターへのリカバリが可能になり、クラウド コストを削減できます。
詳細情報の入手方法
このドキュメントに記載されている情報の詳細については、次のドキュメントや Web サイトを参照してください。
-
Azure NetApp Filesのボリューム レプリケーションを作成する
-
Azure NetApp Filesボリュームのリージョン間レプリケーション
-
Azure に仮想化環境を展開して構成する
-
Azure VMware Solution のデプロイと構成