

VMFS データストア向けBlueXP DRaaS を使用した DR
 変更を提案
変更を提案
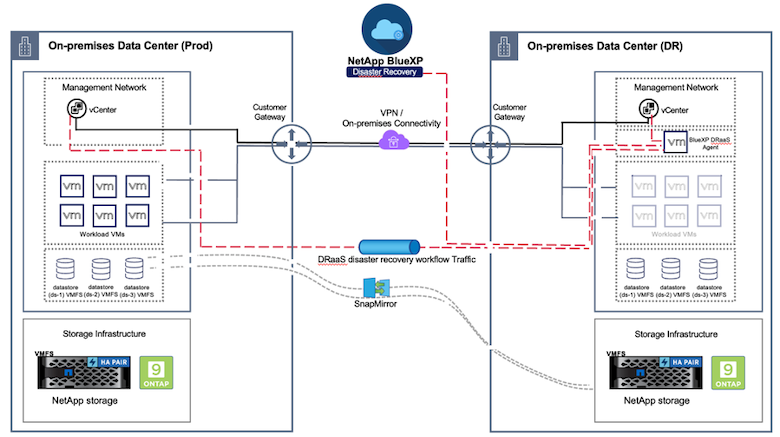
運用サイトから災害復旧サイトへのブロックレベルのレプリケーションを使用した災害復旧は、サイトの停止やランサムウェア攻撃などのデータ破損イベントからワークロードを保護する、回復力がありコスト効率に優れた方法です。 NetApp SnapMirrorレプリケーションを使用すると、VMFSデータストアを使用してオンプレミスのONTAPシステムで実行されているVMwareワークロードを、VMwareが存在する指定されたリカバリデータセンター内の別のONTAPストレージシステムに複製できます。
このドキュメントのセクションでは、オンプレミスの VMware VM の災害復旧を別の指定サイトに設定するためのBlueXP DRaaS の構成について説明します。このセットアップの一部として、 BlueXPアカウント、 BlueXPコネクタ、VMware vCenter からONTAPストレージへの通信を可能にするために必要なONTAPアレイがBlueXPワークスペース内に追加されます。さらに、このドキュメントでは、サイト間のレプリケーションを構成する方法と、リカバリ プランを設定およびテストする方法についても詳しく説明します。最後のセクションでは、サイト全体のフェールオーバーを実行する手順と、プライマリ サイトが回復されオンラインで購入されたときにフェールバックする方法について説明します。
NetApp BlueXPコンソールに統合されているBlueXP disaster recoveryサービスを使用すると、顧客はオンプレミスの VMware vCenter とONTAPストレージを検出し、リソース グループを作成し、ディザスタ リカバリ プランを作成してリソース グループに関連付け、フェイルオーバーとフェイルバックをテストまたは実行できます。 SnapMirror は、ストレージ レベルのブロック レプリケーションを提供し、2 つのサイトを増分変更で最新の状態に保ち、RPO を最大 5 分に抑えます。また、本番環境や複製されたデータストアに影響を与えたり、追加のストレージ コストを発生させたりすることなく、定期的な訓練として DR 手順をシミュレートすることもできます。 BlueXP disaster recoveryは、 ONTAP のFlexCloneテクノロジーを活用して、DR サイトで最後に複製されたスナップショットから VMFS データストアのスペース効率の高いコピーを作成します。 DR テストが完了すると、顧客はテスト環境を削除するだけで済み、実際の複製された本番リソースには影響しません。実際のフェイルオーバー (計画的または計画外) が必要な場合、数回クリックするだけで、 BlueXP disaster recoveryサービスが、指定された災害復旧サイトで保護された仮想マシンを自動的に起動するために必要なすべての手順を調整します。このサービスは、必要に応じて、プライマリ サイトへのSnapMirror関係を逆転させ、フェイルバック操作のためにセカンダリ サイトからプライマリ サイトへの変更を複製します。これらすべては、他のよく知られている代替手段に比べて、ほんのわずかなコストで実現できます。
開始
BlueXP disaster recoveryを開始するには、 BlueXPコンソールを使用してサービスにアクセスします。
-
BlueXPにログインします。
-
BlueXP の左側のナビゲーションから、[保護] > [災害復旧] を選択します。
-
BlueXP disaster recoveryダッシュボードが表示されます。
災害復旧計画を構成する前に、次の前提条件が満たされていることを確認してください。
-
BlueXPコネクタはNetApp BlueXPに設定されます。コネクタは AWS VPC にデプロイする必要があります。
-
BlueXPコネクタ インスタンスは、ソースおよびターゲットの vCenter およびストレージ システムに接続できます。
-
VMware 用の VMFS データストアをホストするオンプレミスのNetAppストレージ システムがBlueXPに追加されます。
-
DNS 名を使用する場合は、DNS 解決を実施する必要があります。それ以外の場合は、vCenter の IP アドレスを使用します。
-
指定された VMFS ベースのデータストア ボリュームに対してSnapMirrorレプリケーションが構成されます。
ソース サイトと宛先サイト間の接続が確立されたら、構成手順に進みます。これには約 3 ~ 5 分かかります。

|
NetApp、実際の障害や自然災害の発生時にBlueXPコネクタがネットワークを介してソース リソースおよび宛先リソースと通信できるように、災害復旧サイトまたは第 3 のサイトにBlueXPコネクタを導入することを推奨しています。 |
|
|
このドキュメントの執筆時点では、オンプレミスからオンプレミスへの VMFS データストアのサポートはテクノロジー プレビュー段階です。この機能は、FC および ISCSI プロトコル ベースの VMFS データストアの両方でサポートされます。 |
BlueXP disaster recovery構成
災害復旧の準備の最初のステップは、オンプレミスの vCenter とストレージ リソースを検出し、 BlueXP disaster recoveryに追加することです。
|
|
ONTAPストレージ システムがキャンバス内の作業環境に追加されていることを確認します。 BlueXPコンソールを開き、左側のナビゲーションから 保護 > 災害復旧 を選択します。 vCenter サーバーの検出 を選択するか、トップ メニューを使用して サイト > 追加 > vCenter の追加 を選択します。 |
次のプラットフォームを追加します。
-
ソース。オンプレミスの vCenter。
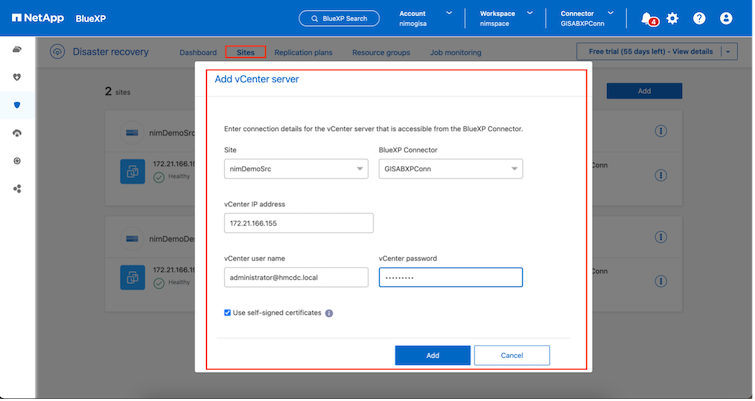
-
行き先。 VMC SDDC vCenter。
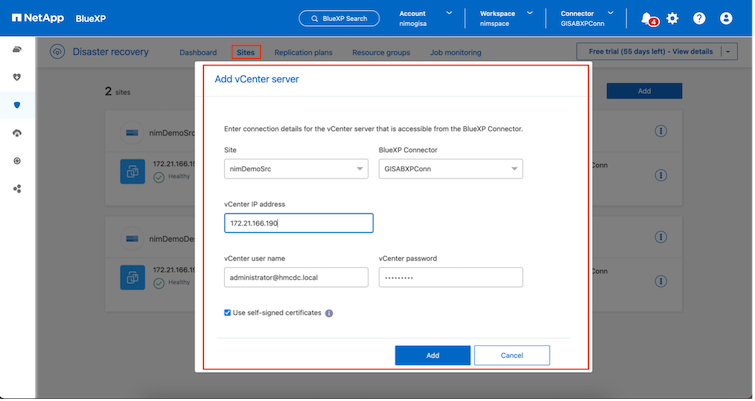
vCenter が追加されると、自動検出がトリガーされます。
ソースサイトと宛先サイト間のストレージレプリケーションの構成
SnapMirror はONTAPスナップショットを利用して、ある場所から別の場所へのデータの転送を管理します。最初に、ソース ボリュームのスナップショットに基づく完全なコピーが宛先にコピーされ、ベースライン同期が実行されます。ソースでデータの変更が発生すると、新しいスナップショットが作成され、ベースライン スナップショットと比較されます。変更されたと判明したブロックは宛先に複製され、新しいスナップショットが現在のベースライン、つまり最新の共通スナップショットになります。これにより、プロセスを繰り返し、増分更新を宛先に送信できるようになります。
SnapMirror関係が確立されると、宛先ボリュームはオンライン読み取り専用状態になり、引き続きアクセス可能になります。 SnapMirror は、ファイルやその他の論理レベルではなく、ストレージの物理ブロックで動作します。つまり、複製先ボリュームは、スナップショット、ボリューム設定などを含め、複製元ボリュームと同一のレプリカになります。データ圧縮やデータ重複排除などのONTAPスペース効率機能が複製元ボリュームで使用されている場合、複製されたボリュームではこれらの最適化が保持されます。
SnapMirror関係を解除すると、宛先ボリュームが書き込み可能になり、通常はSnapMirrorを使用して DR 環境にデータを同期しているときにフェイルオーバーを実行するために使用されます。 SnapMirror は非常に洗練されており、フェイルオーバー サイトで変更されたデータをプライマリ システムに効率的に再同期し、プライマリ システムが後でオンラインに戻ったときに、元のSnapMirror関係を再確立することができます。
VMware Disaster Recoveryの設定方法
SnapMirrorレプリケーションを作成するプロセスは、どのアプリケーションでも同じです。このプロセスは手動でも自動でも実行できます。最も簡単な方法は、 BlueXPを利用して、環境内のソースONTAPシステムを宛先にドラッグ アンド ドロップするだけでSnapMirrorレプリケーションを構成し、残りのプロセスをガイドするウィザードを起動することです。
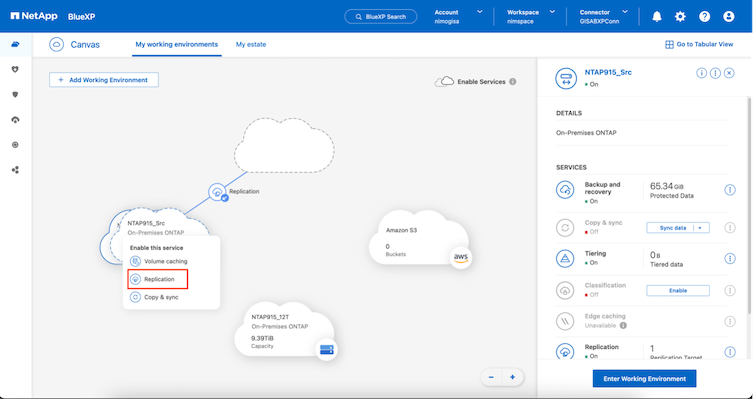
BlueXP DRaaS では、次の 2 つの条件が満たされている場合、同じことを自動化することもできます。
-
ソース クラスターと宛先クラスターにはピア関係があります。
-
ソース SVM と宛先 SVM にはピア関係があります。
|
|
CLI 経由でボリュームにSnapMirror関係がすでに設定されている場合、 BlueXP DRaaS はその関係を取得し、残りのワークフロー操作を続行します。 |
|
|
上記の方法以外にも、 SnapMirrorレプリケーションはONTAP CLI または System Manager 経由で作成することもできます。 SnapMirrorを使用してデータを同期するために使用されるアプローチに関係なく、 BlueXP DRaaS は、シームレスで効率的な災害復旧操作のワークフローを調整します。 |
BlueXP disaster recoveryは何を実現できるのでしょうか?
ソース サイトと宛先サイトが追加されると、 BlueXP disaster recoveryは自動的に詳細な検出を実行し、VM と関連メタデータを表示します。 BlueXP disaster recoveryでは、VM で使用されるネットワークとポート グループも自動的に検出し、それらを入力します。
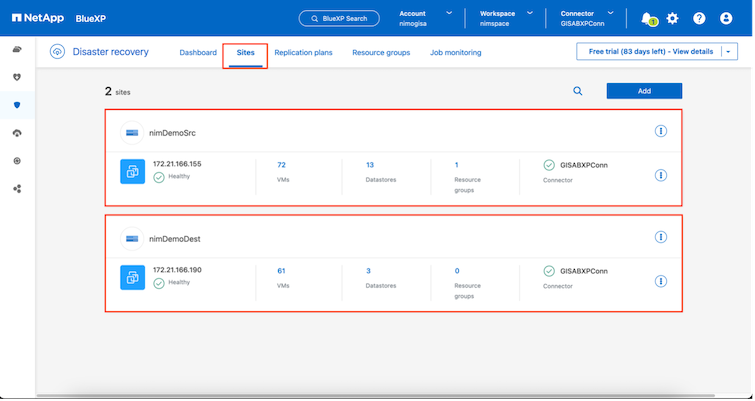
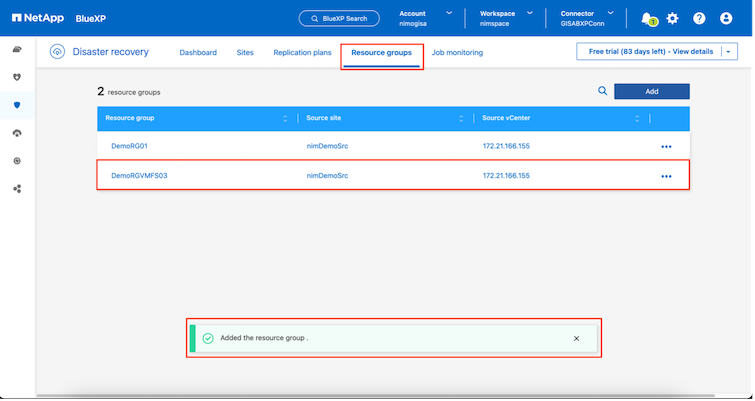
サイトを追加した後、VM をリソース グループにグループ化できます。 BlueXP disaster recoveryリソース グループを使用すると、依存する VM のセットを、復旧時に実行できるブート順序とブート遅延を含む論理グループにグループ化できます。リソース グループの作成を開始するには、[リソース グループ] に移動し、[新しいリソース グループの作成] をクリックします。
|
|
レプリケーション プランの作成時にリソース グループを作成することもできます。 |
VM のブート順序は、リソース グループの作成中に、簡単なドラッグ アンド ドロップ メカニズムを使用して定義または変更できます。
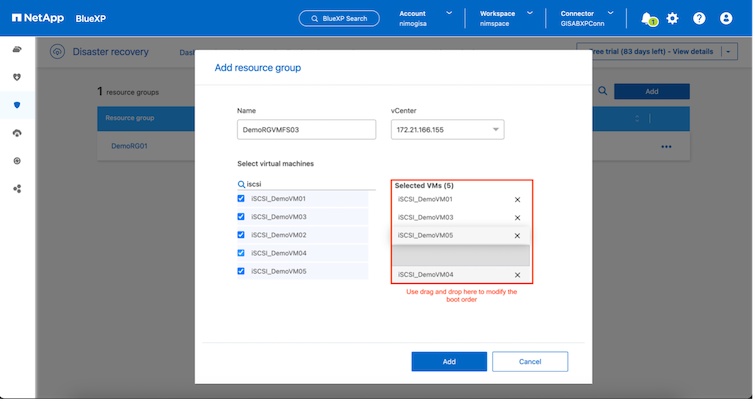
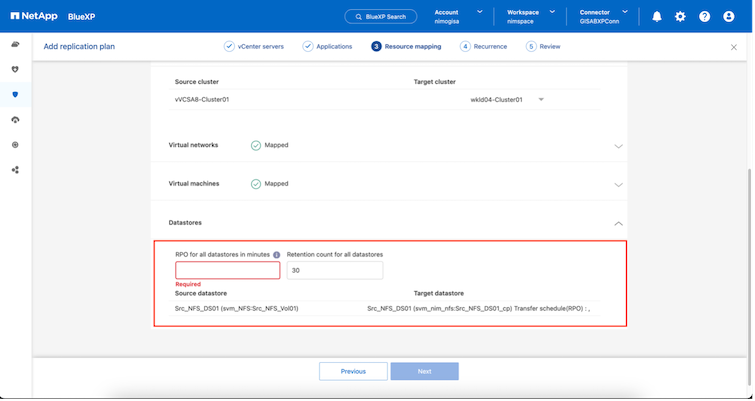
リソース グループを作成したら、次のステップは、災害発生時に仮想マシンとアプリケーションを復旧するための実行ブループリントまたは計画を作成することです。前提条件で述べたように、 SnapMirrorレプリケーションは事前に構成することも、レプリケーション プランの作成時に指定された RPO と保持数を使用して DRaaS で構成することもできます。
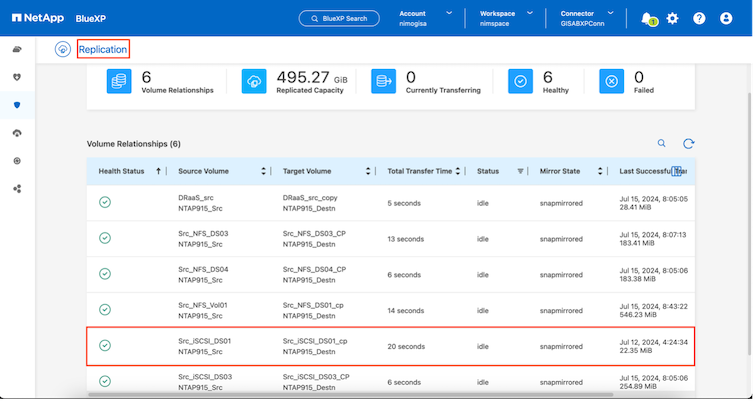
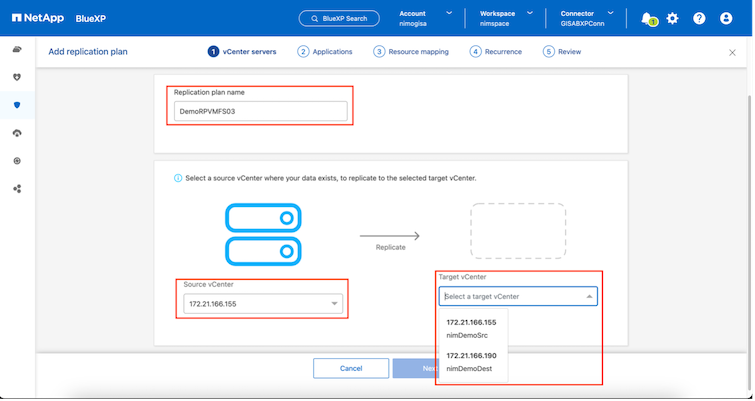
ドロップダウンからソースと宛先の vCenter プラットフォームを選択してレプリケーション プランを構成し、プランに含めるリソース グループ、アプリケーションの復元方法と電源オン方法のグループ化、およびクラスタとネットワークのマッピングを選択します。リカバリ プランを定義するには、[レプリケーション プラン] タブに移動し、[プランの追加] をクリックします。
まず、ソース vCenter を選択し、次に宛先 vCenter を選択します。
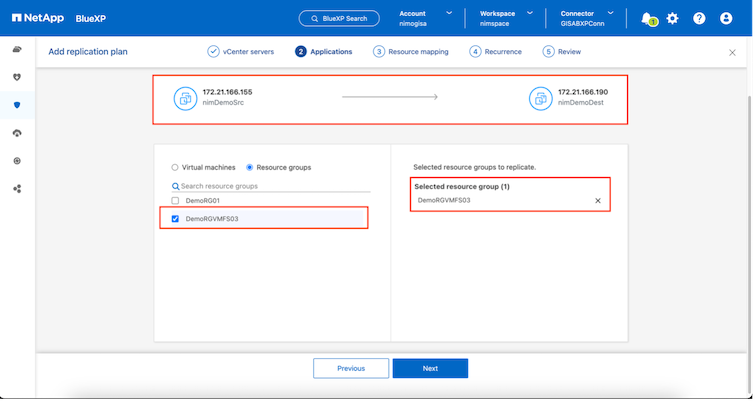
次のステップは、既存のリソース グループを選択することです。リソース グループが作成されていない場合、ウィザードは、回復目標に基づいて必要な仮想マシンをグループ化します (基本的には機能リソース グループを作成します)。これは、アプリケーション仮想マシンを復元する操作シーケンスを定義するのにも役立ちます。
|
|
リソース グループでは、ドラッグ アンド ドロップ機能を使用してブート順序を設定できます。これを使用すると、リカバリプロセス中に VM の電源がオンになる順序を簡単に変更できます。 |
|
|
リソース グループ内の各仮想マシンは、順序に基づいて順番に起動されます。 2 つのリソース グループが並行して開始されます。 |
以下のスクリーンショットは、リソース グループが事前に作成されていない場合に、組織の要件に基づいて仮想マシンまたは特定のデータストアをフィルターするオプションを示しています。
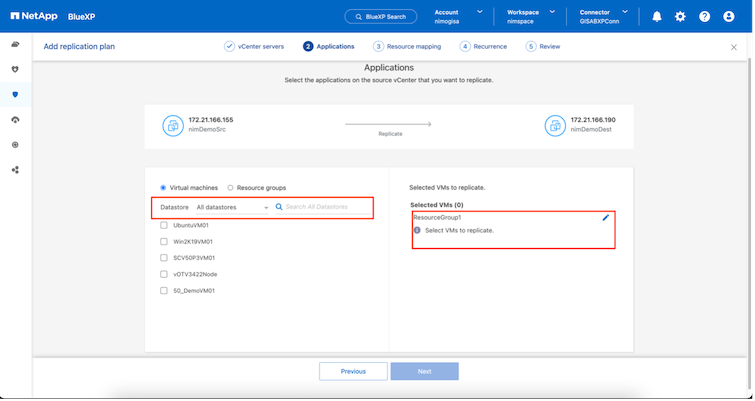
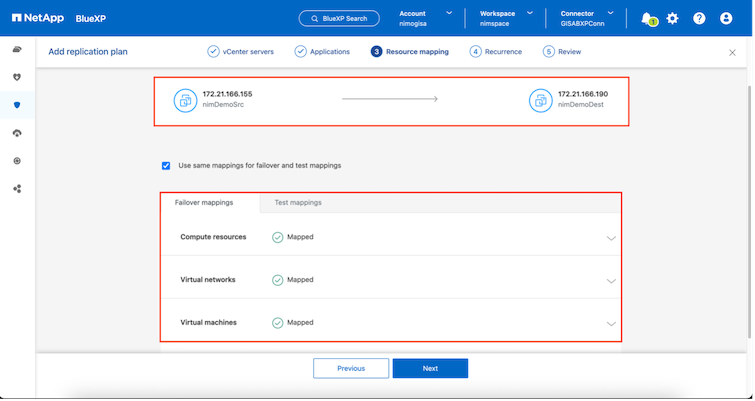
リソース グループを選択したら、フェールオーバー マッピングを作成します。このステップでは、ソース環境のリソースを宛先にどのようにマップするかを指定します。これには、コンピューティング リソース、仮想ネットワークが含まれます。 IP カスタマイズ、事前スクリプトと事後スクリプト、ブート遅延、アプリケーションの一貫性など。詳細については、"レプリケーションプランを作成する" 。
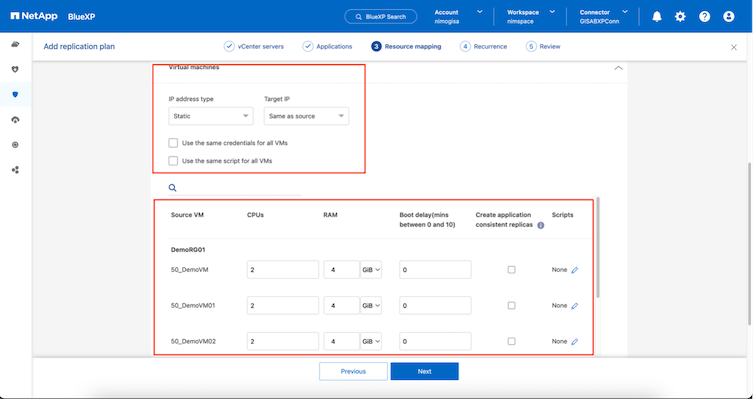
|
|
デフォルトでは、テスト操作とフェイルオーバー操作の両方に同じマッピング パラメータが使用されます。テスト環境に異なるマッピングを適用するには、以下に示すようにチェックボックスをオフにした後、テスト マッピング オプションを選択します。 |
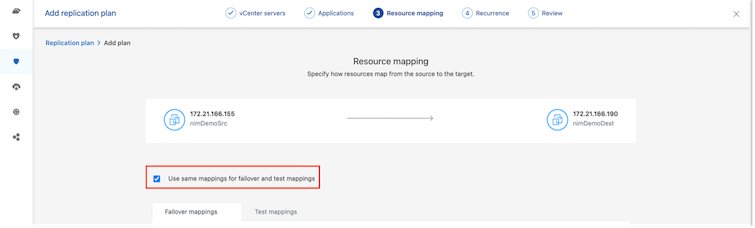
リソース マッピングが完了したら、[次へ] をクリックします。
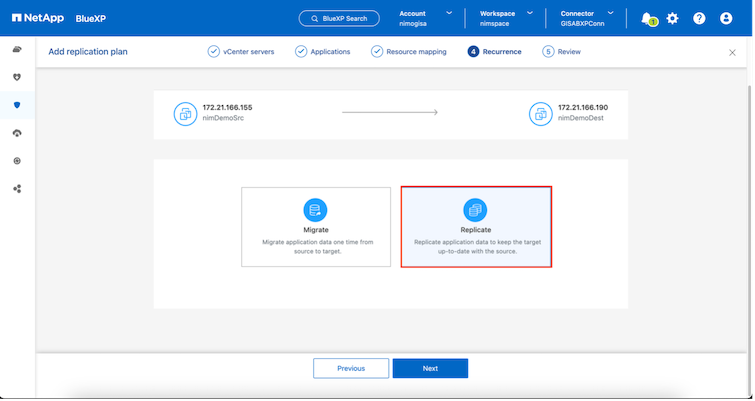
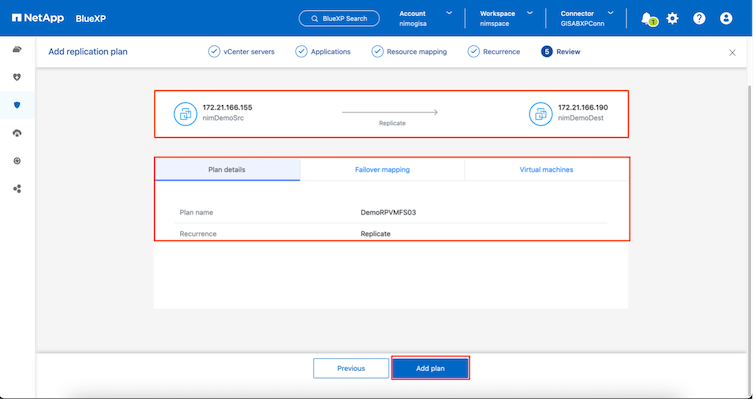
繰り返しタイプを選択します。簡単に言えば、「移行」(フェイルオーバーを使用した 1 回限りの移行)または定期的な連続レプリケーション オプションを選択します。このチュートリアルでは、「複製」オプションが選択されています。
完了したら、作成されたマッピングを確認し、「プランの追加」をクリックします。
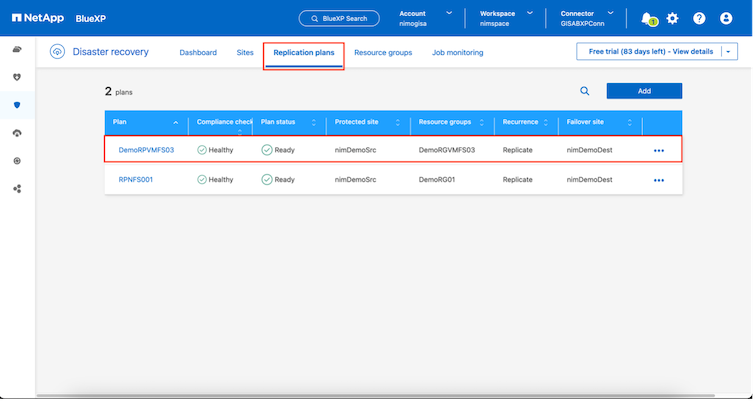
レプリケーション プランが作成されると、フェールオーバー オプション、テスト フェールオーバー オプション、または移行オプションを選択して、要件に応じてフェールオーバーを実行できます。 BlueXP disaster recoveryでは、レプリケーション プロセスが 30 分ごとに計画に従って実行されることが保証されます。フェイルオーバーおよびテストフェイルオーバーのオプションでは、最新のSnapMirror Snapshot コピーを使用することも、ポイントインタイム Snapshot コピーから特定の Snapshot コピーを選択することもできます ( SnapMirrorの保持ポリシーに従って)。ランサムウェアなどの破損イベントが発生し、最新のレプリカがすでに侵害されたり暗号化されたりしている場合、ポイントインタイム オプションは非常に役立ちます。 BlueXP disaster recoveryでは、利用可能なすべての復旧ポイントが表示されます。
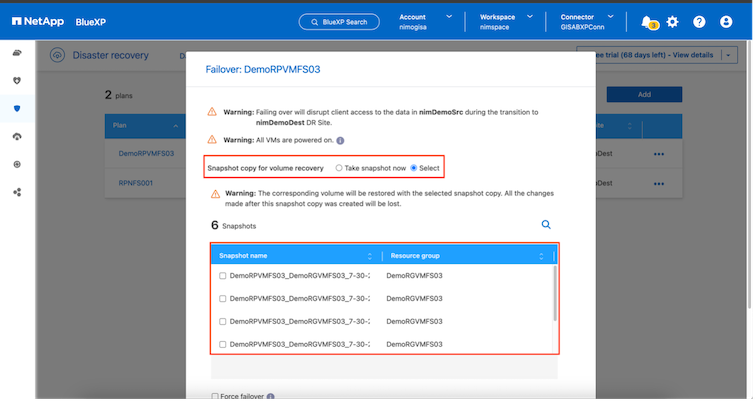
レプリケーション プランで指定された構成でフェイルオーバーまたはテスト フェイルオーバーをトリガーするには、[フェイルオーバー] または [フェイルオーバーのテスト] をクリックします。
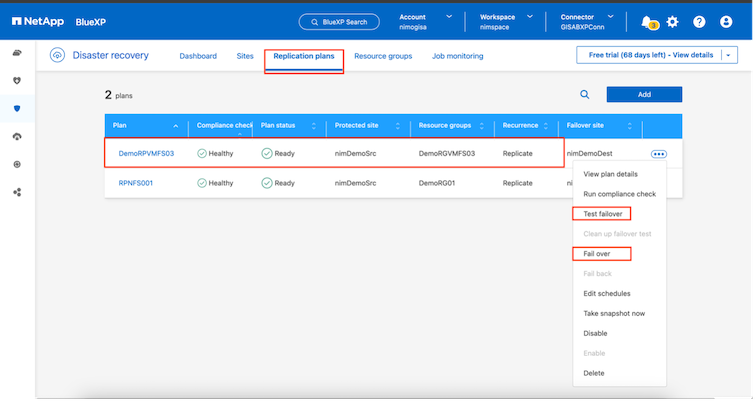
フェイルオーバーまたはテストフェイルオーバー操作中に何が起こりますか?
テスト フェイルオーバー操作中に、 BlueXP disaster recoveryは、最新の Snapshot コピーまたは宛先ボリュームの選択されたスナップショットを使用して、宛先ONTAPストレージ システムにFlexCloneボリュームを作成します。
|
|
テスト フェイルオーバー操作では、宛先のONTAPストレージ システムにクローン ボリュームが作成されます。 |
|
|
テスト リカバリ操作を実行しても、 SnapMirrorレプリケーションには影響しません。 |
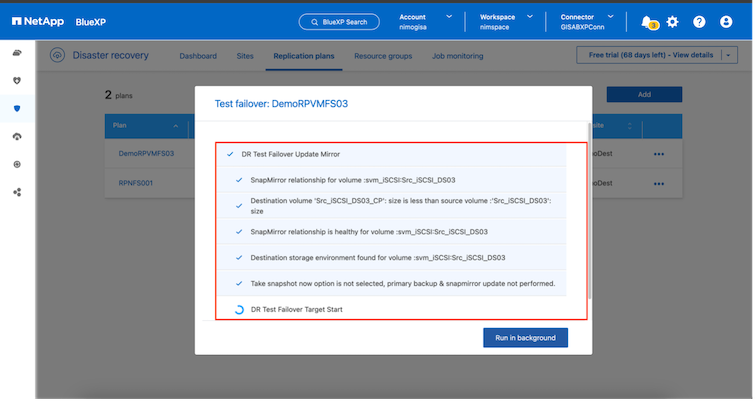
プロセス中、 BlueXP disaster recoveryは元のターゲット ボリュームをマップしません。代わりに、選択したスナップショットから新しいFlexCloneボリュームが作成され、 FlexCloneボリュームをサポートする一時データストアが ESXi ホストにマップされます。
テスト フェイルオーバー操作が完了すると、「クリーンアップ フェイルオーバー テスト」 を使用してクリーンアップ操作をトリガーできます。この操作中、 BlueXP disaster recoveryは、操作で使用されたFlexCloneボリュームを破棄します。
実際の災害が発生した場合、 BlueXP disaster recoveryは次の手順を実行します。
-
サイト間のSnapMirror関係を解除します。
-
再署名後に VMFS データストア ボリュームをマウントし、すぐに使用できるようにします。
-
VMを登録する
-
VMの電源をオンにする
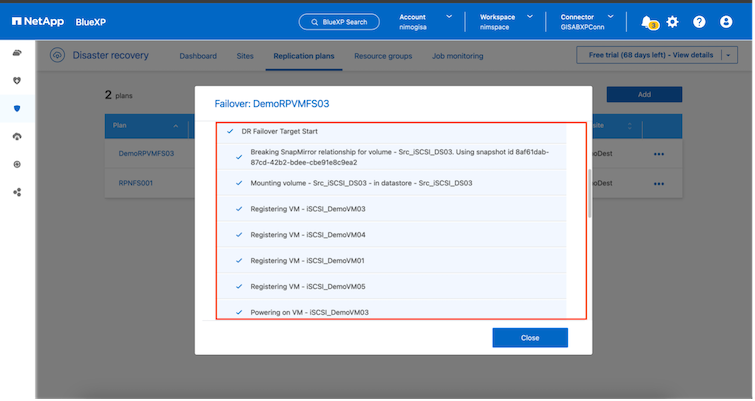
プライマリ サイトが起動すると、 BlueXP disaster recoveryによってSnapMirrorの逆再同期が有効になり、フェイルバックが有効になります。これもボタンをクリックするだけで実行できます。
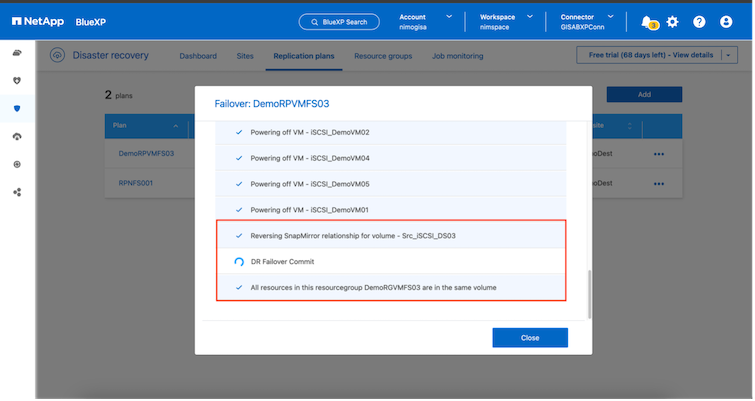
移行オプションを選択した場合は、計画されたフェイルオーバー イベントと見なされます。この場合、ソース サイトの仮想マシンをシャットダウンする追加の手順がトリガーされます。残りの手順はフェイルオーバー イベントと同じままです。
BlueXPまたはONTAP CLI から、適切なデータストア ボリュームのレプリケーションのヘルス ステータスを監視し、ジョブ監視を介してフェイルオーバーまたはテスト フェイルオーバーのステータスを追跡できます。
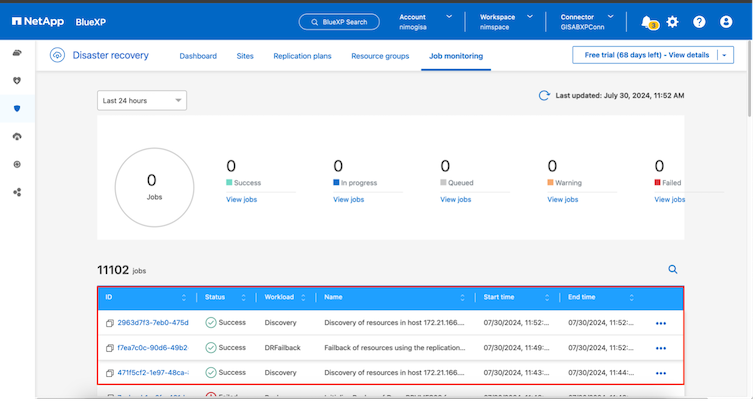
これにより、調整およびカスタマイズされた災害復旧計画を処理するための強力なソリューションが提供されます。フェイルオーバーは、計画されたフェイルオーバーとして実行することも、災害が発生して DR サイトをアクティブ化する決定が下されたときにボタンをクリックするだけでフェイルオーバーを実行することもできます。
このプロセスについて詳しく知りたい場合は、詳細なウォークスルービデオをご覧いただくか、"ソリューションシミュレータ" 。